【无标题】
踩坑集合
- err=pq: duplicate key value violates unique constraint "t_origin_asset_pkey"
- time.Time 为空还是全0
- PostgreSQL中正确的多表关联update写法
- Docker容器时间与宿主机时间不一致的问题
- SQL 计数
- pgsql模糊匹配多个字符串,like 与not like
-
- ① 结果包含指定多个字符 like any
- ② 结果排除多个指定字符 not like all
- sql 查询性能,join多表,并且group by 会很影响性能
- XORM执行SQL()之后会忽略之后的筛选其他逻辑
- 批量插入导致主键冲突,需要上锁,duplicate key value violates unique constraint
- go 变量声明初始化、new、make
- string.Split("",",")分割空字符串,得到的字符数组长度是1 不是0!!
- 注意并发是否执行
- 刷数据的接口注意
- sql: 0+null = null
- Left Join之后,数据为何变少了?
- gin 获取param参数、路由参数
- interface转化异常 interface {} is []interface {}, not []string
- XORM Find 方法传递非指针报错
- Xorm update方法
- interface{} 格式强制类型转化出错
- 代码中写sql,忘记给varchar变量加' '导致sql执行失败
- xorm 接收联表查询得到的几个表的数据,extends
- xorm 分页查询重复 order by
- xorm 慎用 or条件,出现了查询条件失效。
- sql查询有了group by字段之后无法增加非group by的字段显示
- 前端传参,但是后端没有正常获取
- 调不通接口
- string与int的相互转换
- 将[]int{1,2,3,4}转化为1,2,3字符串
- 如何关联表进行update
- 多分支并行开发,合并代码问题
- Git误提交、误合并,回退
- &[] 不为空
- go循环引用检测
- Git分支相关标准
- 空指针异常导致后端服务panic
- 局部变量被垃圾回收导致全0结构体为空指针null
- 数据库插入成功,但是没有数据————事务回滚
- json字符串输入如何进行判断输入是否有效
- json unmarshal判断输入是否为空
- 数据库有多条符合条件的结果,需要获取最新一条的数据
- router路径全小写!!!大写不支持!
- 空指针异常
-
- map空指针异常
- 结构体的空指针异常
err=pq: duplicate key value violates unique constraint “t_origin_asset_pkey”
自增id 在insert 操作时报错自增id约束冲突
原因分析:当前最大id与记录的最大id不一致,且最大id>自增id记录值
比如现在数据库 表中现在的id是100,而id自增才增长到95,在添加一条数据的时候,id是96,id为96的这条数据已经有了,所以id就违反了唯一性约束
解决方案:
1.查询这张表中已经存在的id的最大值是多少
Select max(id) from t_device;
2.查询这张表的id的自增序列是多少.
Select nextval(‘t_device_id_seq’);
3 . 如果这张表的id的最大值大于 id的自增序列的值.那就证明添加的时候会出现id被占用,而导致id违反唯一性约束的问题. 我们只需要重新给id的自增序列赋值,赋一个大于现在表中id的最大值就可以了.
SELECT setval('t_device_id_seq', xxx);
4.在重新查询一下,id的自增序列的值是多少,如果和上一步我们设置的值一样的话,就没有问题了.
Select nextval(‘t_device_id_seq’);
time.Time 为空还是全0
nilTime := time.Time{}
fmt.Println(nilTime.IsZero()) //true
fmt.Println(nilTime) //0001-01-01 00:00:00 +0000 UTC
PostgreSQL中正确的多表关联update写法
在update语句中不应该通过join来进行多表关联,而是要通过from来多表关联,如下:
update a
set value = 'test'
from b,c
where
a.b_id = b.id
and b.c_id = c.id
and a.key = 'test'
and c.value = 'test';
通过from来多表关联,而关联条件则是放到了where中,这样就可以达到我们想要的效果了。另外补充一句,对于set xxx = 'xxx'这个update的部分,是不可以在column字段前加上表前缀的,比如下边的写法就是有语法错误的:
update a
set a.value = 'test';
Docker容器时间与宿主机时间不一致的问题
通过date命令查看时间
# 查看主机时间
[root@localhost ~]# date2016年 07月 27日 星期三 22:42:44 CST
# 查看容器时间
root@b43340ecf5ef:/# date Wed Jul 27 14:43:31 UTC 2016
可以发现,他们相隔了8小时。
CST应该是指(China Shanghai Time,东八区时间)
UTC应该是指(Coordinated Universal Time,标准时间)
解决方案,参考文档:https://segmentfault.com/a/1190000023624052
SQL 计数
计算状态为5的个数
select sum(case when t.status = 5 then 1 else 0 end) as pass_count,
pgsql模糊匹配多个字符串,like 与not like
① 结果包含指定多个字符 like any
需求:筛选出姓名中包含:王、赵、孙任意姓氏的数据
select * from zhong_ods.t_ods_exam_student where u_name like any (array['%王%', '%张%', '%孙%']);
② 结果排除多个指定字符 not like all
需求:筛选出姓名中不包含:王、赵、孙任意姓氏的数据。
select * from zhong_ods.t_ods_exam_student where u_name not like all (array['%王%', '%张%', '%孙%']);
sql 查询性能,join多表,并且group by 会很影响性能
利用case when 去进行不同状态的计数
耗时60ms
select sum(case when status = 1 then 1 else 0 end) as count,
对比关联多表,耗时1.5s
select * from t
left join (select id, count(distinct id) as count
from t_test
where status = 1
group by id) as a on t.test_id = a.id
XORM执行SQL()之后会忽略之后的筛选其他逻辑
使用func (*xorm.Session).SQL(query interface{}, args ...interface{}) *xorm.Session或者func (*xorm.Engine).SQL(query interface{}, args ...interface{}) *xorm.Session
都仅会执行.SQL()里面的statement
若再对session执行func (session *Session) And(query interface{}, args ...interface{}) *Session或者func (session *Session) Where(query interface{}, args ...interface{}) *Session等其他条件都不会产生作用
func TestSQL(t *testing.T) {
session.SQL("select * from host").Where("id=?", 1).Find(&hosts)
fmt.Println(hosts) // 会把id不是1的也查出来,说明Where无效
}
批量插入导致主键冲突,需要上锁,duplicate key value violates unique constraint
两个同时插入,导致主键冲突,从而报错,在频繁的批量插入时容易出现这种情况,两次插入冲突了
1、定义全局锁,不能放在方法里面
2、
//插入时频繁调用,同时转化可能耗时,定义一个全局锁
var mutex sync.Mutex
func test(){
mutex.Lock()
defer mutex.Unlock()
do something()
}
go 变量声明初始化、new、make
- nil 只能赋值给指针类型的变量,实际上nil就是是指针类型变量的零值。值类型的变量有各自的零值 比如 int 是 0 string 是 “”
- 变量的声明,无论是值类型还是指针类型的变量,声明之后,变量都会占有一块内存,并且被初始化为一个零值,被初始化的内容只跟变量的类型有关
- 避免使用
new(),除非你需要一个指针变量
type Person struct {
name string
age int
}
func main() {
var p1 Person
fmt.Println(p.age) //0,Person初始化了
var p2 *Person //声明一个*Person类型的指针p,说明p初始化的内容就是指针的默认值,就是nil 了。
fmt.Println(p2) //所以在查询数据库的时候,如果要查是否存在
//GetOriginAssetByOriginId 查询原始资产瓦片信息
func GetOriginById(id string) (*entity.Origin, error) {
origin := entity.Origin{}
has, err := db.Engine.Where("origin_id = ?", id).Get(&origin)
if err != nil {
return nil, err
}
return &origin, nil
}
// 判断返回的是否存在
test = GetOriginById("123")
if test!=nil{
...
}
实际上test返回的永远都不会是nil,正确的应该如此处理
//GetOriginAssetByOriginId 查询原始资产瓦片信息
func GetOriginById(id string) (*entity.Origin, error) {
origin := entity.Origin{}
has, err := db.Engine.Where("origin_id = ?", id).Get(&origin)
if err != nil {
return nil, err
}
if !has {
return nil, nil
}
return &origin, nil
}
string.Split(“”,“,”)分割空字符串,得到的字符数组长度是1 不是0!!
s := ""
split := strings.Split(s, ",")
fmt.Println(split[0]=="") //true
fmt.Println(len(split)) //1
fmt.Println(split)//[]
注意并发是否执行
函数运行时间和进程的运行时间, 因为go语句是开启一个新的, 刚创建的goroutine去运行这个函数, 但是本身的主进程还会继续运行, 所以, 如果你只写一个go语句, 后面没有可以运行程序的话就会出现一个尴尬的问题, 主进程直接关闭, 对应goroutine也直接关闭,导致函数没有运行
func main() {
go hello("小飞")
go hello("飞啊飞")
// time.Sleep(100 * time.Second) 不加这行代码的话就会出现这种情况
}
刷数据的接口注意
1、数据量比较大时,用异步去跑,因为可能运行实行太长,导致接口超时,返回失败,出问题。直接return,异步执行刷数据
2、刷数据的接口,尽量考虑灵活度,比如指定任务、指定时间范围,因为每一次都是全量的话,太不智能了。
sql: 0+null = null
在进行数据库的查询的时候出现了 A、B、A+B三列求和不一致的情况,数据库字段的运算中,null与任何值运算的结果都是null,
Left Join之后,数据为何变少了?
https://www.modb.pro/db/131794
通过 on 过滤的原理如下:
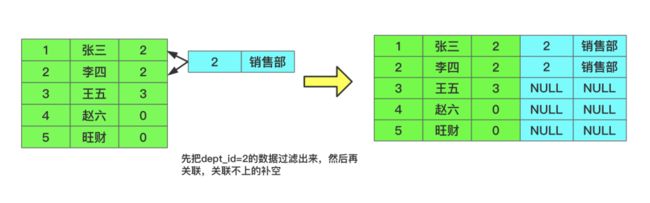
通过 where 过滤的原理如下:

详情:https://www.modb.pro/db/131794
gin 获取param参数、路由参数
参考文档:https://blog.walkbc.com/2019/11/25/gin-lesson-queryParameters/
1、路径规则
- PATH可以包括三种形式:固定路径,必需通配参数“:”,和可选通配参数“*”。
- 通配参数“*”,只能出现一次,并在PATH的最后。
- “*”之后的内容gin会全部解析为通配参数的内容。
path和path/是不同的,如果path/不存在,则会重定向到path。- 参数类型全部按照字符串解析。
2、路径示例
#合法定义
/d1
/d2/:param1
/d3/:param1/:param2
/d4/:param1/:param2/
/d5/:param1/*param2
/d6/:param1/:param2/*param3
参数识别
URL:https://mhost.com/article/:id?tenantId=1
/article/id 是路由(请求PATH),其中由“/”分割的每一部分都可以当作请求参数
* searchBy := c.Param("id")获取
* c.Params获取所有的key-value数组,按照自已意愿处理
tenantId=1 是请求的query,不是路由部分。
//如果参数不存在,或者为空,则返回空字符串
* pSize := c.Query("pageSize")
//如果参数不存在,设置参数的默认值
* pNum := c.DefaultQuery("pageNum","1")
interface转化异常 interface {} is []interface {}, not []string
转化接口返回的信息类型
total====> float64
list ====> []interface {}
"data": {
"total": 11,
"list": [
"NViaS5cM1m",
"CaTx2kLcsN",
"rPQkBsTZTf",
"C7cYOx9fuz",
"oenUAfDeA5",
"GmH0VKqByA",
"6ob3fyv77M",
"I2HY1yaVs4",
"EpIm9aWzTn",
"p6mpcC0cnE",
"sfJsmmfyb2"
]
}
func main() {
foo := []interface{}{"a", "b", "c"}
out := []string{}
for _, v := range foo {
out = append(out, v.(string))
}
fmt.Println(out)//[a b c]
fmt.Println(reflect.TypeOf(out))//[]string
}
XORM Find 方法传递非指针报错
reflect: reflect.Value.Set using unaddressable value
Xorm update方法
情景:某个字段设置了唯一索引,判断当这个索引的数据存在则更新,不存在则新增。
使用Update这个新的结构体,报错,因为
"pq: duplicate key value violates unique constraint \"uidxnk_t_toa_aoi\"",
UPDATE "public"."t_origin_asset"
SET "asset_origin_id" = 'zRoizuT8GU',#唯一索引也被set,就会冲突
interface{} 格式强制类型转化出错
0的初始类型默认是int,如果用0强制类型转换
func test()(int64,err){
return 0.(int64), err
}
代码中写sql,忘记给varchar变量加’ '导致sql执行失败
sql := `
select *
from t
inner join a on a.id = t.aid
where b.deleted = 0
and c.deleted = 0
and t.info= %s ====> and t.info='%s' `
db.Engine.SQL(exeSql).Find()
xorm 接收联表查询得到的几个表的数据,extends
怎么接收多个表的字段,对应的结构体
type Detail struct {
Id int64
UserId int64 `xorm:"index"`
}
// 查询的内容在两个表里面,创建一个新的结构体用于接收值,里面直接加不同的表对应的结构体
type UserDetail struct {
UserInfo User `xorm:"extends"`
UserDetailInfo Detail `xorm:"extends"`
}
// 联表查询,写别名区分不同的表
var users []UserDetail
err := engine.Table("user").Select("user.*, detail.*").
Join("INNER", "detail", "detail.user_id = user.id").
Where("user.name = ?", name).Limit(10, 0).
Find(&users)
// SELECT user.*, detail.* FROM user INNER JOIN detail WHERE user.name = ? limit 10 offset 0
此时如果表中有重复的字段的话,会出现xorm值对应错误,此时必须按照联表的顺序接收值
比如 A,B ,C三个表都有id字段,查询的时候为 A inner join B,C,接收的时候 必须 A.Id,B.Id,C.Id,这样进行接收,也不能只接收部分表的Id,还是会出现映射错误
xorm 分页查询重复 order by
当我使用 order by create_time进行分页查询排序时,发现不同页码会反复出现一些内容,但是有些内容却找不到
原因分析:
order by的字段重复(创建时间一样),这个时候排序不稳定
优化器在遇到order by x limit m,n语句的时使用priority queue进行了优化,优先队列排序priority queue使用了堆排序的排序方法,而堆排序是一个不稳定的排序方法,也就是相同的值可能排序出来的结果和读出来的数据顺序不一致。
参考:https://juejin.cn/post/6943089541200740360
分页重复数据是否出现与排序字段数据唯一性有关,与排序字段是否有序无关,换句话说,只要排序字段的数据能够保证唯一性(如主键、唯一索引、不重复的普通字段),那么分页就不会存在重复数据,否则会有可能出现重复数据在不同分页中
解决方案:
结合使用数据唯一的字段,将原本不唯一的排序条件变成组合唯一的排序条件,因此可以解决分页数据重复的问题
SELECT * FROM account_info order by id LIMIT 0,5
SELECT * FROM account_info order by amount,id LIMIT 0,5 # 多个字段组合保证唯一性
xorm 慎用 or条件,出现了查询条件失效。
因为xorm在执行OR 等各种条件相当于加(),而我们习惯使用时认为关系型运算符优先级高到低为:NOT >AND >OR,如果where 后面有OR条件的话,则OR自动会把左右的查询条件分开,而导致了不一致
xorm执行顺序:
select * from student
(where id=1)
(and grade=1)
(or class=2)
(and subject='math')
我们以为的顺序:
select * from student where id=1 and grade=1 or (class=2 and subject='math')
sql查询有了group by字段之后无法增加非group by的字段显示
此时可以先用查询该字段的语句结果作为一个新表,进行内联查询,这样层层嵌套,直至满足条件
select t1.id from t_tile_basic t1
inner join (select tile_code, max(version) as ver
from t_tile_basic
where t_tile_basic.task_manage_id = 0
group by tile_code) t2 on t1.tile_code = t2.tile_code and t1.version = t2.ver
Where task_manage_id = 0);
前端传参,但是后端没有正常获取
1、前后端参数名称是否一致,有没有未关联上
2、注意POST和GET的方法对应Option是否有对应格式的注释,否则无法绑定

// gin 框架的绑定前端传参方法
func (c *Context) ShouldBind(obj any) error {
b := binding.Default(c.Request.Method, c.ContentType())
return c.ShouldBindWith(obj, b)
}
// 如果是GET方法,默认使用form表单进行绑定参数
func Default(method, contentType string) Binding {
if method == http.MethodGet {
return Form
}
...
}
// 对于这个option,siza只有json格式的映射,此时前端GET传参json就无法绑定
type PageOptions struct {
Page int `form:"page" json:"page"`
Size int `json:"size"`
}
调不通接口
1、确认是否配置iam接口权限
2、是否正式环境、测试环境token搞错
3、是否get、post请求有误
4、是否url错误,多斜杠、路径错误
string与int的相互转换
//string转成int:
int, err := strconv.Atoi(string)
//string转成int64:
int64, err := strconv.ParseInt(string, 10, 64)
//int转成string:
string := strconv.Itoa(int)
//int64转成string:
string := strconv.FormatInt(int64,10)
将[]int{1,2,3,4}转化为1,2,3字符串
func main() {
intSlice := []int32{1, 2, 3}
strSlice := intSliceToString(intSlice, ",")
fmt.Println("strSlice:", strSlice)
}
// 下述方法里边的3行代码,任意一行都可以实现将int类型切片转化成指定格式的字符串
func intSliceToString(a []int32, delim string) string {
//return strings.Trim(strings.Join(strings.Fields(fmt.Sprint(a)), delim), "[]")
//return strings.Trim(strings.Join(strings.Split(fmt.Sprint(a), " "), delim), "[]")
return strings.Trim(strings.Replace(fmt.Sprint(a), " ", delim, -1), "[]")
}
如何关联表进行update
表的内联join条件在这里并没有意义,因为这种写法本身就是不对的!正确写法
update t_task_statics
set tile_code=t_task.tile_code
from t_task
where t_task_statics.task_id = t_task.id;
多分支并行开发,合并代码问题
遇到的问题:
1、一起修复bug,新建了两个bug修复分支,并行开发,一直往test-for-merge分支合并
2、同时开发了新功能分支,也往test-for-merge合并测试
3、因为修复的两个bug分支有交集,所以单独开发很麻烦,于是合并了三个分支的内容作为开发分支
4、新功能没办法及时上,修复功能需要尽快上,但是开发分支又耦合了三个分支
review:
1、修复代码可以单独建分支,但是如果有交集,最好用同一个分支
2、修复分支不要与新功能分支耦合在一起
3、一定要保持分支各自的独立性,千万不要耦合到test分支的代码!!!
Git误提交、误合并,回退
> git log # 得到你需要回退一次提交的commit id
> git reset --hard XXXXX #回退到某个指定的版本commit id
HEAD is now at XXXXX (commit的描述信息)
> git push origin HEAD --force ## 强制提交一次,之前错误的提交就从远程仓库删除
&[] 不为空
var a *[]int64 // a为指针型,此时指针为空
var b []int64 //切片
t.Log(a == nil) //true,指针型此时没有初始化为空
t.Log(a) // nil
t.Log(b) // []
t.Log(&b == nil) //false,切片数组虽然内容为空,但是有地址
t.Log(b == nil) //true
go循环引用检测
Golang 中可以使用 pprof 库来检测循环引用。pprof 是 Go 语言内置的性能分析工具,可以帮助您诊断程序的性能问题,包括内存泄漏和循环引用。
您可以通过以下步骤使用 pprof 检测循环引用:
- 在代码中导入 “net/http/pprof” 包。
- 将 pprof 库添加到您的 HTTP 引擎中。
- 运行程序,并在浏览器中打开 http://localhost:8080/debug/pprof/goroutine?debug=1。
- 如果存在循环引用,您将看到它们列在页面上。
使用 go tool pprof 命令来获取更多有关程序性能的信息。
Git分支相关标准
- 修复bug分支命名:bugfix/develop/lin.lee/fix-xxx
- 新建功能分支:feature/develop/sommer.liu/xxx
空指针异常导致后端服务panic
panic: runtime error: invalid memory address or nil pointer dereference, 也就是空指针异常
当声明一个指针变量时,指针在内存中的值是 nil,表示这个指针是没有指向一个特定的变量。
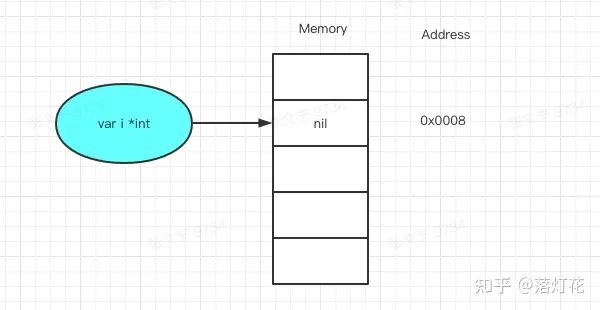
通过 i = 10 赋值时,这种方式会报错,因为 i 表示指针实际指向的值,空指针是没有指向的。
所以我们可以得出结论: 当指针变量没有指向时,也就是为 nil 时,不能对 *point 就行赋值操作,否则会报空指针异常
局部变量被垃圾回收导致全0结构体为空指针null
先修bug,再观察,再补数据
要先修bug,再补数据,补数据前也不能盲目补,而是先观察下有什么共性,先观察、思考
go的GC机制:https://juejin.cn/post/6882206650875248654
// 把局部变量当做参数传递进去赋值,不会产生变量被清理的情况
a := Test{}
b := Test{}
err = MetricString2Object(ctx, options.A, options.B, &a, &b)
// 原先的用法
a, b, err := entity.MetricString2Object(ctx, options.A, options.B)
// MetricString2Object 将字符串转化成对应option数据
func MetricString2Object(ctx context.Context, a string, b string) (*Test, *Test, error) {
// 局部变量在内部,被GC清理,导致返回的不是默认全0的而是null的空指针
a := Test{}
b := Test{}
...
return &a,&b
}
在 Go 语言中,如果你在执行网络连接时收到一条 “dial tcp: connect: connection refused” 的错误消息,这通常表示无法连接到目标服务器。这可能是由于目标服务器拒绝了你的连接,或者因为目标服务器尚未启动而无法响应连接请求。
如果你正在尝试连接到一台远程服务器,则可以尝试使用其他工具(如 ping 或 traceroute)来检查服务器是否可以到达,并查看是否存在防火墙规则或其他网络配置问题。
如果你正在尝试在本地主机上运行一个服务器,则可能是因为该服务器尚未启动,或者因为该服务器监听的端口已被占用。此时,你可以尝试检查服务器是否已启动,并查看是否存在其他程序正在使用该端口。
数据库插入成功,但是没有数据————事务回滚
session一层一层透传
如果手动打开了session.begin(),那么后续的操作如果没有session.commit(),后面的操作直接close的话就会被回滚,导致数据消失。
json字符串输入如何进行判断输入是否有效
if len(options.WorkMetricChangeOption)>0 && json.Valid([]byte(options.WorkMetricChangeOption)) {
}
json unmarshal判断输入是否为空
// 前端输入结构体的string,后端bind后,如果前端没有传入值,全部都会解析为初始零值
json.unmarshal(byteStr,&school)
test := &School{}
// 输出
school == test //说明输入为空
数据库有多条符合条件的结果,需要获取最新一条的数据
参考链接:https://blog.csdn.net/weixin_45559862/article/details/114630936
方法一:连表查询
SELECT * from user t1
INNER JOIN ( SELECT max ( create_time ) create_time FROM user ) t2 ON t1.create_time = t2.create_time
方法二limit:
SELECT * from user ORDER BY create_time desc limit 1
# xorm的方法
Get()方法只能返回单条记录,其生成的 SQL 语句想当于总是有 LIMIT 1
router路径全小写!!!大写不支持!
api/v1/audit/log/config/bizType [不支持]
api/v1/audit/log/config/biztype [支持]
空指针异常
map空指针异常
func f() (map[int]string,error){
// 一个方法
}
func test(){
// 最好先对res进行初始化 res := make(map[int]string,0),下面再进行调用
res,err := f() // 如果返回的是空的map[int]string
for range res..... //此时没有初始化就会报空指针异常!!
}
// 最好对Map使用的地方做一下容错处理
if entity.IfExistCaseMap != nil {
if value, ok := entity.IfExistCaseMap.Get(tileCodeIn14); ok {
has = value
}
}
结构体的空指针异常
json.Unmarshal并不接受空指针(nil pointer)。在定义前端传参Req时,尽量避免定义指针类型,或者重写这个结构体的unmarsahl方法
var a *School //nil
a := &School{} //初始值全为0值的结构体
a := new(School) //初始值全为0值的结构体
import (
"encoding/json"
"fmt"
)
type Result struct {
Foo string
}
func main() {
content := `{"foo": "bar"}`
res := &Result{}
err := json.Unmarshal([]byte(content), &res)
if err != nil {
panic(err)
}
fmt.Printf("res = %+v\n", res) // 正常返回
res2 := &Result{}
err = json.Unmarshal([]byte(content), res2)
if err != nil {
panic(err)
}
fmt.Printf("res2 = %+v\n", res2) // 正常返回
var res3 *Result
err = json.Unmarshal([]byte(content), &res3)
if err != nil {
panic(err)
}
fmt.Printf("res3 = %+v\n", res3) // 正常返回
var res4 *Result
err = json.Unmarshal([]byte(content), res4)
if err != nil {
panic(err)
}
fmt.Printf("res4 = %+v\n", res4) // panic!!! json: Unmarshal(nil *main.Result)
}