十八、字符串(4)
本章概要
- 扫描输入
- Scanner 分隔符
- 用正则表达式扫描
- StringTokenizer 类
扫描输入
到目前为止,从文件或标准输入读取数据还是一件相当痛苦的事情。一般的解决办法就是读入一行文本,对其进行分词,然后使用 Integer、Double 等类的各种解析方法来解析数据:
import java.io.*;
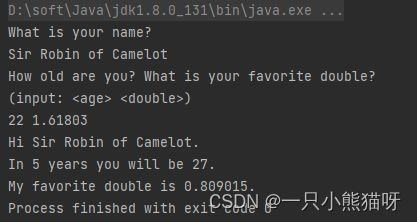
public class SimpleRead {
public static BufferedReader input =
new BufferedReader(new StringReader(
"Sir Robin of Camelot\n22 1.61803"));
public static void main(String[] args) {
try {
System.out.println("What is your name?");
String name = input.readLine();
System.out.println(name);
System.out.println("How old are you? " +
"What is your favorite double?");
System.out.println("(input: )" );
String numbers = input.readLine();
System.out.println(numbers);
String[] numArray = numbers.split(" ");
int age = Integer.parseInt(numArray[0]);
double favorite = Double.parseDouble(numArray[1]);
System.out.format("Hi %s.%n", name);
System.out.format("In 5 years you will be %d.%n", age + 5);
System.out.format("My favorite double is %f.", favorite / 2);
} catch (IOException e) {
System.err.println("I/O exception");
}
}
}
input 字段使用的类来自 java.io,StringReader 将 String 转化为可读的流对象,然后用这个对象来构造 BufferedReader 对象,因为我们要使用 BufferedReader 的 readLine() 方法。最终,我们可以使用 input 对象一次读取一行文本,就像从控制台读入标准输入一样。
readLine() 方法将一行输入转为 String 对象。如果每一行数据正好对应一个输入值,那这个方法也还可行。但是,如果两个输入值在同一行中,事情就不好办了,我们必须分解这个行,才能分别解析所需的输入值。在这个例子中,分解的操作发生在创建 numArray时。
终于,Java SE5 新增了 Scanner 类,它可以大大减轻扫描输入的工作负担:
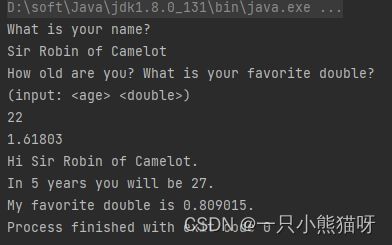
import java.util.*;
public class BetterRead {
public static void main(String[] args) {
Scanner stdin = new Scanner(SimpleRead.input);
System.out.println("What is your name?");
String name = stdin.nextLine();
System.out.println(name);
System.out.println(
"How old are you? What is your favorite double?");
System.out.println("(input: )" );
int age = stdin.nextInt();
double favorite = stdin.nextDouble();
System.out.println(age);
System.out.println(favorite);
System.out.format("Hi %s.%n", name);
System.out.format("In 5 years you will be %d.%n",
age + 5);
System.out.format("My favorite double is %f.",
favorite / 2);
}
}
Scanner 的构造器可以接收任意类型的输入对象,包括 File、InputStream、String 或者像此例中的Readable 实现类。Readable 是 Java SE5 中新加入的一个接口,表示“具有 read() 方法的某种东西”。上一个例子中的 BufferedReader 也归于这一类。
有了 Scanner,所有的输入、分词、以及解析的操作都隐藏在不同类型的 next 方法中。普通的 next() 方法返回下一个 String。所有的基本类型(除 char 之外)都有对应的 next 方法,包括 BigDecimal 和 BigInteger。所有的 next 方法,只有在找到一个完整的分词之后才会返回。Scanner 还有相应的 hasNext 方法,用以判断下一个输入分词是否是所需的类型,如果是则返回 true。
在 BetterRead.java 中没有用 try 区块捕获IOException。因为,Scanner 有一个假设,在输入结束时会抛出 IOException,所以 Scanner 会把 IOException 吞掉。不过,通过 ioException() 方法,你可以找到最近发生的异常,因此,你可以在必要时检查它。
Scanner 分隔符
默认情况下,Scanner 根据空白字符对输入进行分词,但是你可以用正则表达式指定自己所需的分隔符:
import java.util.*;
public class ScannerDelimiter {
public static void main(String[] args) {
Scanner scanner = new Scanner("12, 42, 78, 99, 42");
scanner.useDelimiter("\\s*,\\s*");
while (scanner.hasNextInt()) {
System.out.println(scanner.nextInt());
}
}
}

这个例子使用逗号(包括逗号前后任意的空白字符)作为分隔符,同样的技术也可以用来读取逗号分隔的文件。我们可以用 useDelimiter() 来设置分隔符,同时,还有一个 delimiter() 方法,用来返回当前正在作为分隔符使用的 Pattern 对象。
用正则表达式扫描
除了能够扫描基本类型之外,你还可以使用自定义的正则表达式进行扫描,这在扫描复杂数据时非常有用。下面的例子将扫描一个防火墙日志文件中的威胁数据:
import java.util.regex.*;
import java.util.*;
public class ThreatAnalyzer {
static String threatData =
"58.27.82.161@08/10/2015\n" +
"204.45.234.40@08/11/2015\n" +
"58.27.82.161@08/11/2015\n" +
"58.27.82.161@08/12/2015\n" +
"58.27.82.161@08/12/2015\n" +
"[Next log section with different data format]";
public static void main(String[] args) {
Scanner scanner = new Scanner(threatData);
String pattern = "(\\d+[.]\\d+[.]\\d+[.]\\d+)@" +
"(\\d{2}/\\d{2}/\\d{4})";
while (scanner.hasNext(pattern)) {
scanner.next(pattern);
MatchResult match = scanner.match();
String ip = match.group(1);
String date = match.group(2);
System.out.format(
"Threat on %s from %s%n", date, ip);
}
}
}
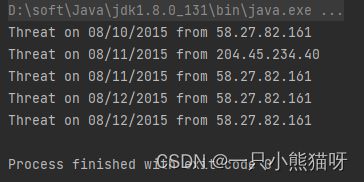
当 next() 方法配合指定的正则表达式使用时,将找到下一个匹配该模式的输入部分,调用 match() 方法就可以获得匹配的结果。如上所示,它的工作方式与之前看到的正则表达式匹配相似。
在配合正则表达式使用扫描时,有一点需要注意:它仅仅针对下一个输入分词进行匹配,如果你的正则表达式中含有分隔符,那永远不可能匹配成功。
StringTokenizer类
在 Java 引入正则表达式(J2SE1.4)和 Scanner 类(Java SE5)之前,分割字符串的唯一方法是使用 StringTokenizer 来分词。不过,现在有了正则表达式和 Scanner,我们可以使用更加简单、更加简洁的方式来完成同样的工作了。下面的例子中,我们将 StringTokenizer 与另外两种技术简单地做了一个比较:
import java.util.*;
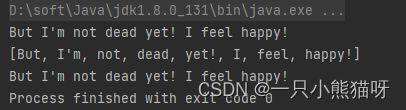
public class ReplacingStringTokenizer {
public static void main(String[] args) {
String input = "But I'm not dead yet! I feel happy!";
StringTokenizer stoke = new StringTokenizer(input);
while (stoke.hasMoreElements()) {
System.out.print(stoke.nextToken() + " ");
}
System.out.println();
System.out.println(Arrays.toString(input.split(" ")));
Scanner scanner = new Scanner(input);
while (scanner.hasNext()) {
System.out.print(scanner.next() + " ");
}
}
}
使用正则表达式或 Scanner 对象,我们能够以更加复杂的模式来分割一个字符串,而这对于 StringTokenizer 来说就很困难了。基本上,我们可以放心地说,StringTokenizer 已经可以废弃不用了。