Python网页爬虫——数据解析方法
Python网页爬虫的数据解析方法
1、网页爬虫的类型
爬虫的类型可以分为:通用爬虫、聚焦爬虫和增量式爬虫。
1.1 通用爬虫
搜索引擎抓取系统的重要组成部分。抓取的是一整张页面的数据。
通用爬虫的步骤:
step1:指定url
step2:发起网页请求,获取响应
step3:获取响应数据
step4:持久化存储数据
1.2 聚焦爬虫
建立在通用爬虫的基础之上。抓取的是页面中特定的局部内容。
爬取局部的内容需要在通用爬虫获取的网页数据上,对数据进行解析,主要有三种解析方式:正则、bs4、xpath
聚焦爬虫的步骤:
step1:指定url
step2:发起网页请求,获取响应
step3:获取响应数据
step4:数据解析
step5:持久化存储数据
1.3 增量式爬虫
监测网站中数据更新的情况。只会抓取网站中最新更新出来的数据。
2.数据解析
2.1 数据解析的概念
数据解析是一种将一串数据转换为不同类型数据的方法。因此,假设您以原始HTML格式接收数据,解析器将获取HTML并将其转换为可读性更强的数据格式。
数据解析原理概述:我们需要解析的是网页中的数据,即从html中解析出想要的数据。解析的局部文本内容都会在标签之间或者标签对应的属性中进行存储。如果想要拿到数据,只需要定位到具体的指定的标签之后,就可以将标签中存储的文本或者标签中对应属性值所存储的文本数据获取到
所以,解析数据的步骤如下:
Step1:进行指定标签的定位
Step2:对标签或者标签对应的属性中存储的数据进行提取(解析)
2.2 数据解析器
常用的数据解析器有:正则表达式、bs4、xpath。
其中xpath的通用性更强,除了可以在Python中使用,也可以在其他编程语言中使用。
解析器本身与数据格式无关。它是将一种数据格式转换为另一种数据格式的工具,它如何转换以及转换成什么格式取决于解析器的构建方式。
2.3 数据解析器——正则
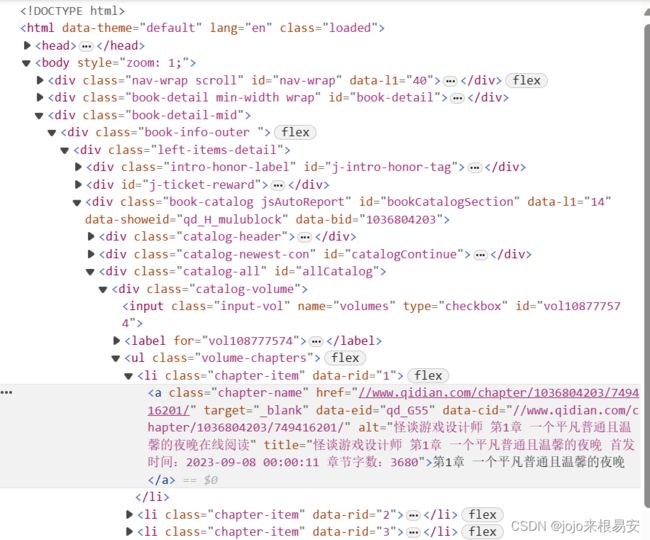
正则在线测试工具:https://regexr-cn.com/
正则练习:https://codejiaonang.com/
正则表达式描述了一种特殊字符串的匹配方法通常用来检查字符串是否和我们设定的规则(正则表达式)相匹配,匹配就可以实现对字符串数据的快速查找和替换
常用正则表达式:
单字符:
. : 除换行以外所有字符
[] : [aoe] [a-w] 匹配集合中任意一个字符
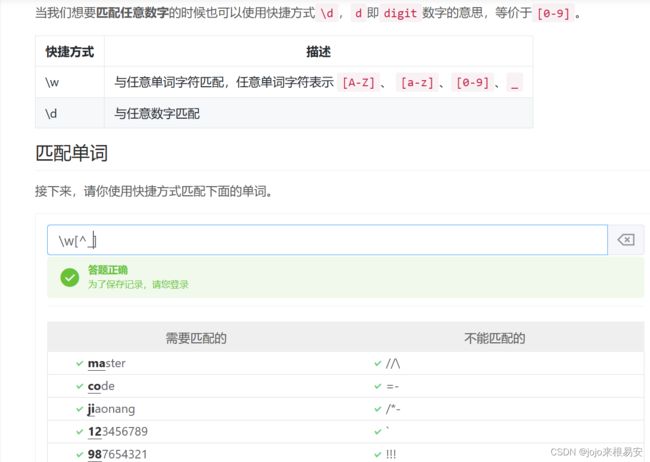
\d : 数字 [0-9]
\D : 非数字
\w : 数字、字母、下划线、中文
\W : 非\w
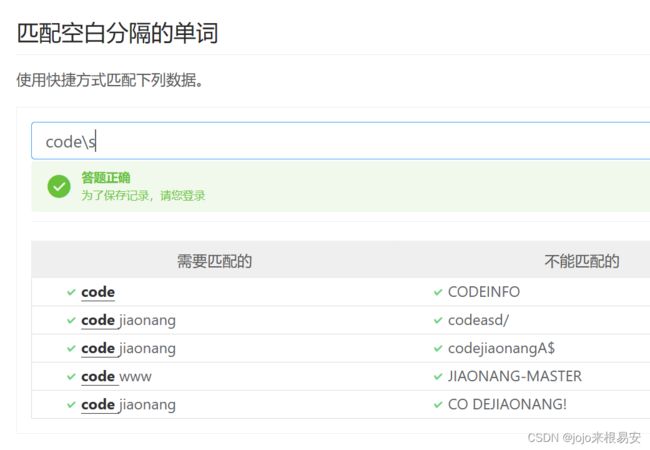
\s : 所有的空白字符,包括空格、制表符、换页符等等。等价于[\f\n\r\t\v]
\S : 非空白
数量修饰:
* : 任意多次 >=0
+ : 至少一次 >=1
? : 可有可无 0次或1次
{m} : 固定m次 hello{3,}
{m,} : 至少m次
{m,n} : m-n次
边界:
$ : 以某某结尾
^ : 以某某开头
分组:
(ab)
贪婪模式:.*
非贪婪(惰性)模式:.*?
re.I : 忽略大小写
re.M : 多行匹配
re.S : 单行匹配
re.sub(正则表达式,替换内容,字符串)
正则表达式常用的场景:
提取短信中的验证码
检查一个字符串是否为电话号码、邮箱、弱密码
修改字符串中的非法字符

2.4 数据解析器——bs4
2.4.1 bs4数据解析的原理
- 实例化一个BeautifulSoup对象,并且将页面源码数据加载到该对象中
- 通过调用BeautifulSoup对象中相关的属性或方法,进行标签定位和数据提取
2.4.2 环境安装
- pip install bs4
- pip install lxml
2.4.3 如何实例化BeautifulSoup对象
1.将本地的html文档中的数据加载到该对象中
fp=open('./test.html','r','encoding='utf-8')
soup=BeautifulSoup(fp,'lxml')
fp.close()
2.将互联网上获取的页面源码加载到该对象中
page_text = response.text
soup = BeautifulSoup(page_text,'lxml')
- 导入模块:
from bs4 import BeautifulSoup
- 对象实例化
- 方式一:将本地的html文档中的数据加载到该对象中
- 方式二:将互联网上获取的页面源码加载到该对象中
# 导包
from bs4 import BeautifulSoup
# 对象实例化——将本地的html文档中的数据加载到该对象中
fp = open('./test.html','r',encoding='utf-8')
soup = BeautifulSoup(fp,'lxml') # 使用lxml解析器进行解析
# 关闭文件
fp.close()
print(soup)
- 提供用于数据解析的方法和属性
bs4数据解析方式是Python独有的数据解析方式,只能被应用在Python中。
本地的html文档test.html内容如下:
DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>测试bs4title>
head>
<body>
<div>
<p>百里守约p>
div>
<div class="song">
<p>李清照p>
<p>王安石p>
<p>苏轼p>
<p>柳宗元p>
<a href="http://www.song.com/" title="赵匡胤" target="_seif">
<span>this is spanspan>
宋朝是最强大的王超,不是军队强大,而是经济很强大,国民都很有钱
a>
<a href="" class="du">总为浮云能蔽日,长安不见使人愁a>
<img src="http://www.baidu.com/meinv.jpg" alt="" />
div>
<div class="tang">
<ul>
<li><a href="http://www.baidu.com/" title="qing">清明时节雨纷纷,路上行人欲断魂a> li>
<li><a href="http://www.163.com/" title="qin">秦时明月汉时关,万里长征人未还a> li>
<li><a href="http://www.126.com/" alt="qi">岐王宅里寻常见,崔九堂前几度闻a> li>
<li><a href="http://www.sina.com/" class="du">杜甫a> li>
<li><a href="http://www.dudu.com/" class="qing">杜牧a> li>
<li><b>杜小月b> li>
<li><i>度蜜月i>li>
<li><a href="http://www.haha.com/" id="feng">凤凰台上凤凰游,凤去台空江自流a> li>
ul>
div>
body>
html>
'''
BeautifulSoup解析网页数据
'''
# 导包
from bs4 import BeautifulSoup
# 对象实例化——将本地的html文档中的数据加载到该对象中
fp = open('./test.html','r',encoding='utf-8')
soup = BeautifulSoup(fp,'lxml') # 使用lxml解析器进行解析
# 关闭文件
fp.close()
# print(soup)
'''soup.tagName返回的是html文档中第一个出现的tagName'''
print(soup.a) # 查找a标签
print(soup.div) # 查找div标签
'''
标签定位:soup.find('tagName')可以直接查找标签名,返回的是文档中第一个出现的tagName,等同于soup.div;
属性定位:soup.find('tagName',attribute_='')
'''
print(soup.find('div'))
print(soup.find('div',class_='song')) # 属性class后要有一个下划线,否则它就不是一个参数名称而是一个关键字
'''soup.findall():可以找到所有符合要求的标签,返回一个列表'''
print(soup.find_all('a'))
'''
soup.select('某种选择器'),选择器可以是标签、属性等等,返回的是一个列表;
层级选择器:soup.select()进行层级定位,用>表示层级的高低,返回值是一个列表,但是在select()中不支持下表索引的方式,只能取到列表之后再取对应的元素
层级选择器中,>表示的是一个层级,空格表示的是多个层级
'''
print(soup.select('.tang')) # 定位到的是含有属性'tang'的标签
print(soup.select('.tang > ul > li > a')) # 取到多个a标签
# 取列表中的第一个a标签
print(soup.select('.tang > ul > li > a')[0])
# 如果要跨层级,则不能使用>,要使用空格,空格表示多个层级
print(soup.select('.tang > ul a')[0])
'''
获取标签之间的文本数据:用上面的方法定位到某个标签之后,可以用.text或者.string或者.get_text()来获取标签中的文本内容。
text/get_text():可以获得指定标签下的所有文本内容,包括其子标签
string:只可以获取指定标签下直系的文本内容,子标签的文本内容不能获取到
!!注意:这三种方法一定要定位到某个标签,不能是一个包含了多个标签的列表
'''
print(soup.a.text) # 它返回的是第一个a标签下包含的文本和a标签下所有子标签包含的文本
print(soup.find('div',class_='song').string)
print(soup.select('.tang > ul > li > a')[0].get_text())
'''
获取标签中属性值,用中括号获取某个标签中对应属性的值
'''
print(soup.select('.tang > ul > li > a')[0]['href'])
print(soup.find_all('div')[1]['class'])
2.5 数据解析器——xpath
xpath解析是最常用且最便捷高效的一种解析方式。xpath解析不仅可以应用到Python编程语言中,还可以应用到其他编程语言中,是通用性最强的数据解析方式。
2.5.1 xpath解析原理
- 实例化一个etree对象,并且需要将被解析的页面源码加载到该对象中。
- 调用etree对象中的xpath方法,结合xpath表达式实现标签的定位和内容的捕获。
2.5.2 环境安装
pip install lxml # lxml是一种解析器
2.5.3 如何实例化etree对象
etree是lxml模块中的一个类,导入etree的代码是:
from lxml import etree
(1)将本地的html文档中的源码数据加载到etree对象中
etree.parse(filePath) # filePath是本地html文档的路径
(2)可以将从互联网上获取的源码数据加载到该对象中
html = response.text # 获取的响应内容
context = etree.HTML(html)
- xpath表达式
- /:表示的从根节点开始定位。表示的是一个层级。
- //:在xpath表达式中间时表示的是多个层级。在开头的话则表示从任意位置开始定位。
- 属性定位:在定位的标签后面加一个中括号,中括号里是 @属性名称,即tag[@attrName=“attrValue”]。如:‘//div[@class=“song”]’
- 索引定位://div[@class=“song”]/p[3] 索引值是从1开始的。
- 取标签中的文本:
- /text():获取相应标签中的直系文本内容,并存储到列表中
- //text():获取相应标签中的全部文本内容,不仅可以获取标签直系的文本内容,还能获取子标签中全部的文本。
- 取标签中的属性值:在定位到的标签后加上 /@ attrName ,如 /img/@src,其中src是img标签中的属性名
使用的本地html文档与bs4解析中的test.html是同一个。
'''
用xpath解析网页数据——导入本地的html文档
'''
# 导入模块
# import requests
from lxml import etree
# 实例化一个etree对象
tree = etree.parse('test.html')
# 调用etree对象中的xpath方法作用到xpath表达式上
# xpath方法只能根据层级关系进行标签定位
# /在开头表示从根节点开始定位,在中间表示一个层级
r1 = tree.xpath('/html/head/title')
print(r1) # 返回的是一个列表,列表中是一个Element类型的数据
r2 = tree.xpath('/html/body/div')
print(r2)
# //在xpath表达式中间表示多个层级
r3 = tree.xpath('/html//div')
print(r3)
# //在开头,表示从任意位置开始定位查找相应标签
r4 = tree.xpath('//div')
print(r4)
# 属性定位:在定位的标签后面加一个中括号,中括号里是 @属性名称
r5 = tree.xpath('//div[@class="song"]')
print(r5)
# 索引定位:索引下标值从1开始
r6 = tree.xpath('//div[@class="song"]/p[3]') # 地位到div标签下的第3个p标签
print(r6)
# 获取标签中的文本值
# /text()表示获取定位到的标签下直系的文本内容
r7 = tree.xpath('//div[@class="tang"]/ul/li[5]/a/text()')
print(r7) # 结果存储在列表中
# //text()表示获取定位到的标签下所有的文本内容,不仅是标签的直系文本内容,还包括其子标签的全部文本
r8 =tree.xpath('//div[@class="tang"]/ul/li[7]//text()')
print(r8)
# 获取标签中的属性值
r9 = tree.xpath('//div[@class="song"]/img/@src')
print(r9)