“Kotlin“系列: 三、Kotlin协程(上)

前言
很高兴遇见你~
在本系列的上一篇中,我们学习了 Kotlin 泛型,使用泛型能使我们的代码具有可复用性,避免类型转换异常,还没有看过上一篇文章的朋友,建议先去阅读 "Kotlin"系列: 二、Kotlin泛型。接下来我们就进入 Kotlin 协程的学习,在我看来, Kotlin 协程也是属于那种比较难理解的知识点,我会尽量用比较通俗易懂的语言去进行讲解,希望通过我的文章能带领大家攻克 Kotlin 协程
问题
首先还是先抛出一系列的问题,大家搞清楚这些问题后学习 Kotlin 协程可能会轻松一点:
1、什么是并发?什么是并行?
2、什么是多任务?什么是协作式多任务?什么是抢占式多任务?
3、什么是同步?什么是异步?
4、什么是非阻塞式?什么是阻塞式?
5、什么是挂起?
6、什么是非阻塞式挂起?
7、什么是协程?
8、什么是 Kotlin 协程?
9、Kotlin 协程有什么用?
1、什么是并发?什么是并行?
1)、并发就是同一时刻只有一条指令在执行,但是因为 CPU 时间片非常的小,多个指令间能够快速的切换,使得我们看起来拥有同时执行的效果,存在于单核或多核 CPU 系统中
2)、并行就是同一时刻有多条指令同时在执行,存在于多核 CPU 系统中
举个生活中人吃馒头的例子:一个人买了 3 个馒头,那么他同一时刻只能在吃一个馒头,这是并发。而 3 个人每人买了一个馒头,那么同一时刻他们能同时吃馒头,这是并行。并发和并行的区别在于同一时刻是否在同时进行
2、什么是多任务?什么是协作式多任务?什么是抢占式多任务?
1)、多任务就是操作系统能够同时处理多个任务,例如我可以使用笔记本电脑打开 AndroidStudio 和网易云音乐,一边撸码一边听歌
2)、协作式多任务就是一个任务得到了 CPU 时间,除非它自己放弃使用 CPU ,否则将完全霸占 CPU ,所以任务之间需要协作,使用一段时间的 CPU 后,放弃使用,其它的任务也如此,才能保证系统的正常运行。一般出现在早期的操作系统中,如 Windows 3.1
3)、抢占式多任务就是由操作系统来分配每个任务的 CPU 使用时间,在一个任务使用一段时间 CPU 后,操作系统会剥夺当前任务的 CPU 使用权,把它排在询问队列的最后,再去询问下一个任务。一般出现在现在使用的操作系统,如 Window 95及之后的 Windows 版本
协作式多任务和抢占式多任务区别:在协作式多任务中,如果一个任务死锁,则系统也会死锁。而抢占式多任务中,如果一个任务死锁,系统仍能正常运行
3、什么是同步?什么是异步?
计算机领域中的同步和异步和我们平时生活中的同步和异步是不一样的,这就让很多人难以理解
1)、计算机领域中的同步就是当调用者发送一个调用指令,需等待该指令执行完,在继续往下执行,是一种串行的处理方式
2)、计算机领域中的异步就是当调用者发送一个调用指令,无需等待该指令执行完,继续往下执行,是一种并行的处理方式
4、什么是阻塞?什么是非阻塞?
阻塞很简单,就是字面意思,在 Android 中的体现,其实就是阻塞了主线程的运行,那么非阻塞就是没有卡住主线程的运行
5、什么是挂起?
挂起就是保存当前状态,等待恢复执行,在 Android 中的体现,挂起就是不影响主线程的工作,更贴切的说法可以理解为切换到了一个指定的线程,
6、什么是非阻塞式挂起?
通过上面概念的解释,非阻塞式挂起就是不会卡住主线程且将程序切换到另外一个指定的线程去执行
7、什么是协程?
协程,英文名 Coroutine,源自 Simula 和 Modula-2 语言,它是一种协作式多任务实现,是一种编程思想,并不局限于特定的语言。协程设计的初衷是为了解决并发问题,让协作式多任务实现起来更加方便
8、什么是 Kotlin 协程?
Kotlin 协程简单来说是一套线程操作框架,详细点说它就是一套基于线程而实现的一套更上层的工具 API,类似于 Java 的线程池,你可以理解 Kotlin 新造了一些概念用来帮助你更好地使用这些 API,仅此而已
9、Kotlin 协程有什么用?
1)、Kotlin 协程可以用看起来同步的方式写出异步的代码,帮你优雅的处理回调地狱
清楚了上面这些问题后,我们接着往下看
一、Kotlin 协程生态和依赖库
Kotlin 并没有把协程纳入标准库中,而是以依赖库的形式提供的,这是一张 Kotlin 协程的生态图:
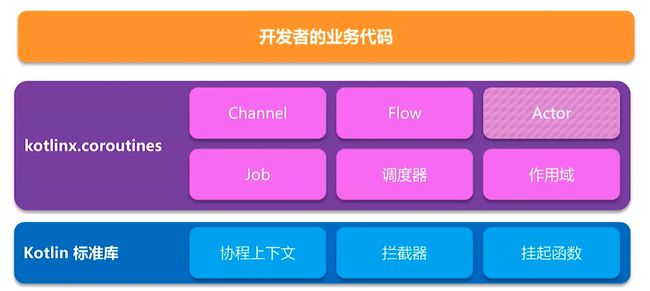
从上图我们可以很清晰的看到,Kotlin 标准库和协程依赖库所提供的东西,在我们创建一个 Kotlin 项目的时候,默认会导入标准库的依赖,因此这里添加如下协程依赖库就可以了,最新协程依赖库版本可以点击传送门查看:
//协程核心库
implementation 'org.jetbrains.kotlinx:kotlinx-coroutines-core:1.4.3'
//这个库在 Android 项目中才会用到
implementation 'org.jetbrains.kotlinx:kotlinx-coroutines-android:1.4.3'
二、使用 GlobalScope.launch 函数创建你的第一个协程
- GlobalScope.launch 函数可以创建一个协程作用域,这样传递给 launch 函数的代码块就是在协程中运行了
- GlobalScope.launch 函数创建的是一个顶级协程,当应用程序运行结束时也会跟着一起结束
- GlobalScope.launch 函数创建的协程和线程有点像,因为线程没有顶级这一说,所以永远都是顶级的
fun main() {
GlobalScope.launch {
println("codes run in coroutine scope")
}
}
上面这段简短的代码就是开启了一个协程,很简单吧,一行代码就实现了,协程也不过如此啊。实际下面这段代码背后包含着成吨的知识点:
1、协程作用域
2、协程作用域的扩展函数
3、协程上下文
4、协程启动模式
可能大家会有点疑惑,区区一行代码,怎么可能会涉及这么多东西?不信我们在点击 launch 函数看下它的源码:
// launch 函数源码
public fun CoroutineScope.launch(
context: CoroutineContext = EmptyCoroutineContext,
start: CoroutineStart = CoroutineStart.DEFAULT,
block: suspend CoroutineScope.() -> Unit
): Job {
//...
}
可以看到,launch 函数是 CoroutineScope 即协程作用域的一个扩展函数,它里面有三个参数:第一个参数: CoroutineContext 即协程上下文,有默认值。第二个参数: CoroutineStart 即协程启动模式,有默认值。第三个参数:函数类型参数,无默认值。因此 launch 函数在实际调用的时候,只需要传入一个 Lambda 表达式就可以了,当然你也可以传参去覆盖默认值
好了,知道它里面涉及到这么多知识点,现在我们来进行各个击破,下面我会讲解协程作用域,其他的在这篇文章分析可能有点枯燥,我们放到下篇文章在来分析
三、协程作用域
回到最开始那段代码,首先我们看到 GlobalScope 这个东东,点进去看一眼它的源码:
public object GlobalScope : CoroutineScope {
/**
* Returns [EmptyCoroutineContext].
*/
override val coroutineContext: CoroutineContext
get() = EmptyCoroutineContext
}
上述代码我们可以知道:GlobalScope 是一个单例类,实现了 CoroutineScope 这个东东,并重写了 coroutineContext 这个属性
1、CoroutineScope
接着点进去 CoroutineScope 这个东东看一下:
public interface CoroutineScope {
public val coroutineContext: CoroutineContext
}
1)、源码里面有一段对它的注释,翻译过来大致就是:CoroutineScope 能够定义一个协程作用域,每个协程构建器像 launch, async 都是它的一个扩展。
2)、它是一个接口,里面持有一个 CoroutineContext 即协程上下文,我们可以让类实现它,让该类成为一个协程作用域
2、GlobalScope
现在回到 GlobalScope 这个东东,我们应该可以把它解释清楚了:因为 GlobalScope 是一个单例类,且实现了CoroutineScope,所有它拥有了全局的协程作用域,且在整个 JVM 虚拟机中只有一份对象实例。因为它的生命周期贯穿整个 JVM,所以我们在使用它的时候需要警惕内存泄漏。上面代码中调用的 GlobalScope.launch,实质上是调用了 CoroutineScope 的 launch 扩展函数
3、协程作用域作用
那么这里你心里是否会有个疑问:拥有协程作用域有啥用呢?作用可大了
协程必须在协程作用域中才能启动,协程作用域中定义了一些父子协程的规则,Kotlin 协程通过协程作用域来管控域中的所有协程
协程作用域间可并列或包含,组成一个树状结构,这就是 Kotlin 协程中的结构化并发,规则如下:
4、作用域细分
有下述三种:
1)、顶级作用域:没有父协程的协程所在的作用域
2)、协同作用域:协程中启动新协程(即子协程),此时子协程所在的作用域默认为协同作用域,子协程抛出的未捕获异常都将传递给父协程处理,父协程同时也会被取消;
3)、主从作用域:与协同作用域父子关系一致,区别在于子协程出现未捕获异常时不会向上传递给父协程
5、父子协程间的规则
1)、父协程如果取消或结束了,那么它下面的所有子协程均被取消或结束
2)、父协程需等待子协程执行完毕后才会最终进入完成状态,而不管父协程本身的代码块是否已执行完
3)、子协程会继承父协程上下文中的元素,如果自身有相同 Key 的成员,则覆盖对应 Key,覆盖效果仅在自身范围内有效
好了,到了这里关于协程作用域你是否理解了呢?如果不明白,接着往下看,或许随着学习的深入,你的问题就引刃而解了
四、使用 Delay 函数延迟协程执行
-
delay 函数是一个非阻塞式挂起函数,它可以让当前协程延迟到指定的时间执行,且只能在协程的作用域或者其他挂起函数中调用
-
对比 Thread.sleep() 函数,delay 函数只会挂起当前协程,并不会影响其他协程的运行,而 Thread.sleep() 函数会阻塞当前线程,那么该线程下的所有协程都会被阻塞
fun main() {
GlobalScope.launch {
println("codes run in coroutine scope")
}
}
上述代码你运行一下会发现日志打印不出来,小朋友,你是否有很多问号?
这是因为代码块中的代码还没来得及执行,应用程序就结束了,要解决这个问题,我们可以让程序延迟一段时间在结束,如下:
fun main() {
GlobalScope.launch {
println("codes run in coroutine scope")
}
Thread.sleep(1000)
}
//打印结果
codes run in coroutine scope
上述代码我们让主线程阻塞了 1 秒钟在执行,因此代码块中的代码得到了执行。其实这种写法还是存在一点问题,如果我让代码块中的代码在 1 秒钟内不能运行结束,那么就会被强制中断:
fun main() {
GlobalScope.launch {
println("codes run in coroutine scope")
delay(1500)
println("codes run in coroutine scope finished")
}
Thread.sleep(1000)
}
//打印结果
codes run in coroutine scope
上述代码我们在代码块中加入了一个 delay 函数,并在其之后又打印了一行日志。那么当前协程会挂起 1.5 秒,而主线程却只阻塞了 1 秒,那么重新运行一下程序,新增的这条日志并没有打印出来,因为它还没来得及运行,程序就结束了。
那有办法让协程中所有的代码都执行完了之后在结束吗?️
答:有的,使用 runBlocking 函数
五、使用 runBlocking 函数创建一个能阻塞当前线程的协程作用域
- runBlocking 函数可以保证在协程作用域内的所有代码和子协程没有全部执行完之前一直阻塞当前线程
注意:runBlocking 函数通常只能在测试环境中使用,在正式环境中使用会容易产生一些性能上的问题
fun main() {
runBlocking {
println("codes run in coroutine scope")
delay(1500)
println("codes run in coroutine scope finished")
}
}
//打印结果
codes run in coroutine scope
codes run in coroutine scope finished
上述代码我们使用了 runBlocking 函数,可以看到两条日志都能够正常打印出来了。到了这里我心里会有一个疑问:上面的代码都是跑在同一个协程中,我能不能创建多个协程同时跑呢?
答:可以的,使用 launch 函数
六、使用 launch 函数在当前的协程作用域下创建子协程
上面我们讲到过,launch 函数是 CoroutineScope 的一个扩展函数,因此只要拥有协程作用域,就可以调用 launch 函数
- 单独使用 launch 函数和我们刚才使用的 GlobalScope.launch 函数不同, GlobalScope.launch 创建的是一个顶级协程,而 launch 函数创建的是子协程
fun main() {
runBlocking {
launch {
println("launch1")
delay(1000)
println("launch1 finished")
}
launch {
println("launch2")
delay(1000)
println("launch2 finished")
}
}
}
//打印结果
launch1
launch2
launch1 finished
launch2 finished
上述代码我们调用了两次 launch 函数,也就是创建了两个子协程,运行之后我们可以看到两个子协程的日志是交替打印的,这一现象表明他们像是多线程那样并发运行的。然而这两个子协程实际上是运行在同一个线程中,只是由编程语言来决定如何在多个协程之间进行调度,让谁运行,让谁挂起。调度的过程完全不需要操作系统参与,这也就使得协程的并发效率出奇的高
目前 launch 函数中的逻辑是比较简单的,那么随着逻辑越来越多,我们可能需要将部分代码提取到一个单独的函数中,如下:
fun performLogistics(){
//处理成吨的逻辑代码
//...
//这句代码编译器会报错,因为 delay 函数只能在协程作用域或者其他挂起函数中调用
delay(1500)
//...
}
上面这段代码报错了,因为提取到一个单独的函数中就没有协程作用域了,那么 delay 函数就调用不了了,蛋疼,有没有其他办法呢?
仔细分析一下,我们知道 delay 函数只能在协程作用域或者其他挂起函数中调用,现在提取出来的单独函数没有协程作用域了,那么是否可以把它声明成一个挂起函数呢?
答:可以的,使用 suspend 关键字将一个函数声明成挂起函数,挂起函数之间是可以相互调用的
七、使用 suspend 关键字将一个函数声明成挂起函数
- suspend 关键字能将一个函数声明成挂起函数
- 挂起函数必须在协程或者另一个挂起函数里被调用
那么上面代码我们加个关键字修饰一下就 ok 了,如下:
suspend fun performLogistics(){
//处理成吨的逻辑代码
//...
delay(1500)
//...
}
现在问题又来了,如果我想在这个挂起函数中调用 launch 函数可以么?如下:
suspend fun performLogistics(){
//处理成吨的逻辑代码
//...
delay(1500)
//...
//这句代码编译器会报错,因为没有协程作用域
launch{
}
}
上面这段代码又报错了,因为没有协程作用域,那么如果我想这样调用,能实现么?
答:可以的,借助 coroutineScope 函数来解决
八、使用 coroutineScope 函数创建一个协程作用域
- coroutineScope 函数会继承外部的协程作用域并创建一个子作用域
- coroutineScope 函数也是一个挂起函数,因此我们可以在任何其他挂起函数中调用
suspend fun printDot() = coroutineScope {
println(".")
delay(1000)
launch {
}
}
上述代码调用 launch 函数就不会报错了。
另外, coroutineScope 函数和 runBlocking 函数有点类似,它可以保证其作用域内的所有代码和子协程在全部执行完之前,一直阻塞当前协程。而 runBlocking 是一直阻塞当前线程,我们来做个验证:
fun main() {
runBlocking {
coroutineScope {
launch {
for (i in 1..5) {
println(i)
}
}
}
println("coroutineScope finished")
}
println("runBlocking finished")
}
//打印结果
1
2
3
4
5
coroutineScope finished
runBlocking finished
从打印结果,我们就可以验证上面这一结论
九、使用 async 函数创建一个子协程并获取执行结果
从上面的学习我们可以知道 launch 函数可以创建一个子协程,但是 launch 函数只能用于执行一段逻辑,却不能获取执行的结果,因为它的返回值永远是一个 Job 对象,那么如果我们想创建一个子协程并获取它的执行结果,我们可以使用 async 函数
- async 函数必须在协程作用域下才能调用
- async 函数会创建一个子协程并返回一个 Deferred 对象,如果需要获取 async 函数代码块中的执行结果,只需要调用 Deferred 对象的 await() 方法即可
- async 函数在调用后会立刻执行,当调用 await() 方法时,如果代码块中的代码还没执行完,那么 await() 方法会将当前协程阻塞住,直到可以获取 async 函数中的执行结果
fun main() {
runBlocking {
val start = System.currentTimeMillis()
val result1 = async {
delay(1000)
5 + 5
}.await()
val result2 = async {
delay(1000)
4 + 6
}.await()
println("result is ${result1 + result2}")
val end = System.currentTimeMillis()
println("cost: ${end - start} ms.")
}
}
//打印结果
result is 20
cost: 2017 ms.
上述代码连续使用了两个 async 函数来执行任务,并在代码块中进行 1 秒的延迟,按照刚才上面说的,await() 方法在 async 函数代码块中的代码执行完之前会一直将当前协程阻塞住。整段代码的执行耗时是 2017 ms,说明这里的两个 async 函数确实是一种串行的关系,前一个执行完了下一个才能执行。很明显这种写法是比较低效的,因为两个 async 完全可以异步去执行,而现在却被整成了同步,我们改造一下上面的写法:
fun main() {
runBlocking {
val start = System.currentTimeMillis()
val deferred1 = async {
delay(1000)
5 + 5
}
val deferred2 = async {
delay(1000)
4 + 6
}
println("result is ${deferred1.await() + deferred2.await()}")
val end = System.currentTimeMillis()
println("cost: ${end - start} ms.")
}
}
//打印结果
result is 20
cost: 1020 ms.
上面的写法我们没有在每次调用 async 函数之后就立刻使用 await() 方法获取结果了,而是仅在需要用到 async 函数的执行结果时才调用 await() 方法进行获取,这样 async 函数就变成了一种异步关系了,可以看到打印结果也验证了这一点
我是个喜欢偷懒的人, async 函数每次都要调用 await() 方法才能获取结果,比较繁琐,那我就会想:有没有类似 async 函数并且不需要每次都去调用 await() 方法获取结果的函数呢?
答:有的,使用 withContext 函数
10、使用 withContext 函数构建一个简化版的 async 函数
- withContext 函数是一个挂起函数,并且强制要求我们指定一个协程上下文参数,这个调度器其实就是指定协程具体的运行线程
- withContext 函数在调用后会立刻执行,它可以保证其作用域内的所有代码和子协程在全部执行完之前,一直阻塞当前协程
- withContext 函数会创建一个子协程并将最后一行的执行结果作为返回值
fun main() {
runBlocking {
val result = withContext(Dispatchers.Default) {
5 + 5
}
println(result)
}
}
//打印结果
10
11、使用 suspendCoroutine 函数简化回调的写法
在日常工作中,我们通常会通过异步回调机制去获取网络响应数据,不知你有没有发现,这种回调机制基本上是依靠匿名内部类来实现的,比如如下代码:
sendHttpRequest(object : OnHttpCallBackListener{
override fun onSuccess(response: String) {
}
override fun onError(exception: Exception) {
}
})
那么在多少地方发起网络请求,就需要编写多少次这样的匿名内部类去实现,这样会显得特别繁琐。在我们学习 Kotin 协程之前,可能确实是没有啥更简单的写法了,不过现在,我们就可以借助 Kotlin 协程里面的 suspendCoroutine 函数来简化回调的写法:
- suspendCoroutine 函数必须在协程作用域或者挂起函数中调用,它接收一个 Lambda 表达式,主要作用是将当前协程立即挂起,然后在一个普通线程中去执行 Lambda 表达式中的代码
- suspendCoroutine 函数的 Lambda 表达式参数列表会传入一个 Contination 参数,调用它的 resume() 或 resumeWithException() 方法可以让协程恢复执行
//定义成功和失败的接口
interface OnHttpCallBackListener{
fun onSuccess(response: String)
fun onError(exception: Exception)
}
//模拟发送一个网络请求
fun sendHttpRequest(url: String, httpCallBack: OnHttpCallBackListener){
}
//对发送的网络请求回调使用 suspendCoroutine 函数进行封装
suspend fun request(url: String): String{
return suspendCoroutine { continuation ->
sendHttpRequest(url,object : OnHttpCallBackListener{
override fun onSuccess(response: String) {
continuation.resume(response)
}
override fun onError(exception: Exception) {
continuation.resumeWithException(exception)
}
})
}
}
//具体使用
suspend fun getBaiduResponse(){
try {
val request = request("https://www.baidu.com/")
} catch (e: Exception) {
//对异常情况进行处理
}
}
上述代码中:
1、我们在 request 函数内部使用了刚刚介绍的 suspendCoroutine 函数,这样当前协程会立刻被挂起,而 Lambda 表达式中的代码则会在普通线程中执行。接着我们在 Lambda 表达式中调用了 sendHttpRequest() 方法发起网络请求,并通过传统回调的方式监听请求结果
2、如果请求成功就调用 Continuation 的 resume() 方法恢复被挂起的协程,并传入服务器响应的数据,该值会成为 suspendCoroutine 函数的返回值
3、如果请求失败,就调用 Continuation 的 resumeWithException() 方法恢复被挂起的协程,并传入具体的异常原因
4、最后在 getBaiduResponse() 中进行了具体使用,有没有觉得这里的代码清爽了很多?由于 getBaiduResponse() 是一个挂起函数,当 getBaiduResponse() 调用了 request() 函数时,当前协程会立刻挂起,然后等待网络请求成功或者失败后,当前协程才能恢复运行
5、如果请求成功,我们就能获得异步网络请求的响应数据,如果请求失败,则会直接进入 catch 语句中
到这里其实又会产生一个问题:getBaiduResponse() 函数被声明成了一个挂起函数,因此它只能在协程作用域或其他挂起函数中调用了,使用起来是不是非常有局限性?
答:确实如此,因为 suspendCoroutine 函数本身就是要结合协程一起使用的,这个时候我们就需要通过合理的项目架构设计去解决这个问题
经过上面的步骤,我们使用 suspendCoroutine 函数实现了看似同步的方式写出异步的代码,事实上 suspendCoroutine 函数几乎可以用于简化任何回调的写法,例如我们在实际项目中使用 Retrofit 就可以使用 suspendCoroutine 函数来简化回调
到了这里,相信你对协程有了一定的了解了,接下来,我们分析一点深入的东西
十二、Kotlin 中的挂起操作
挂起算是 Kotlin 协程中的一个黑魔法了,上面我们简单了介绍了下使用 suspend 定义一个挂起函数,下面我们来详细的去剖析一下 Kotlin 中的挂起操作
1、挂起的本质
如下代码:
class MainActivity : AppCompatActivity() {
private val TAG: String = "MainActivity"
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContentView(R.layout.activity_main)
Log.d(TAG, "start... ");
GlobalScope.launch(Dispatchers.Main) {
mockTimeConsume()
Log.d(TAG, "我等挂起函数执行完了在执行");
}
Log.d(TAG, "我在主线程执行了成吨的代码");
}
//模拟挂起函数耗时任务
suspend fun mockTimeConsume() = withContext(Dispatchers.IO){
Log.d(TAG, "紧张的执行耗时任务中... " + + Thread.currentThread().name);
Thread.sleep(3000)
}
}
//打印结果如下
start...
我在主线程执行了成吨的代码
紧张的执行耗时任务中...DefaultDispatcher-worker-2
我等挂起函数执行完了在执行
上述代码步骤:
1、在主线程中创建了一个顶级协程,并指定该协程在主线程中运行
2、在协程中执行 mockTimeConsume 这个方法并打印了一句 Log
现在我们从线程和协程两个角度去分析它:
前面我在回答问题的时候讲到过,挂起就是切换到另外一个指定的线程去执行
线程
线程:那么当执行到协程中的 mockTimeConsume() 这句代码的时候,因为遇到了挂起函数,协程被挂起了,主线程将会跳出这个协程,如果下面还有代码,则继续执行下面的代码,如果没有,则执行它界面刷新的任务
协程
协程:当执行到协程中的 mockTimeConsume() 这句代码的时候,因为遇到了挂起函数,当前协程会被挂起,注意是整个协程被挂起了,意味着 mockTimeConsume() 这句代码下面的代码都不会执行了,需等待我这句代码执行完之后在接着往后执行,接下来会在指定的线程执行挂起函数里面的内容。谁指定的?是当前挂起函数指定的,比如我们这个例子中,函数内部的 withContext 传入的 Dispatchers.IO 所指定的 IO 线程
Dispatchers 调度器,它可以将协程限制在一个特定的线程执行,或者将它分派到一个线程池,或者让它不受限制地运行
常用的 Dispatchers ,有以下三种:
- Dispatchers.Main:Android 中的主线程
- Dispatchers.IO:针对磁盘和网络 IO 进行了优化,适合 IO 密集型的任务,比如:读写文件,操作数据库以及网络请求
- Dispatchers.Default:适合 CPU 密集型的任务,比如计算
当挂起函数执行完之后,协程为我们做的最爽的事就来了:恢复当前协程,把线程从其他线程,切回到了当前的线程。那么接着就会执行协程中 Log.d(TAG, “我等挂起函数执行完了在执行”) 这句代码,整个流程就结束了
通过上面对线程和协程两个角度都分析,我们可以得出一些结论:
1、被 suspend 修饰的挂起函数比普通函数多两个操作:
1)、挂起:暂停当前协程的执行,保存所有的局部变量
2)、恢复:从协程被暂停的地方继续执行协程
2、协程在执行到有 suspend 标记的挂起函数时,会被挂起,而所谓的被挂起,就是切换线程
3、协程被挂起之后需要恢复,而恢复这个操作是协程框架给我们做的
通过结论 3 ,我们引申一下:如果你不在协程里面调用挂起函数,恢复这个功能没法实现,所以也就回答了问题:为什么挂起函数必须在协程或者另一个挂起函数里被调用
再细想下这个逻辑:一个挂起函数要么在协程里被调用,要么在另一个挂起函数里被调用,那么它其实直接或者间接地,总是会在一个协程里被调用的
所以,要求 suspend 函数只能在协程里或者另一个 suspend 函数里被调用,还是为了要让协程能够在挂起函数切换线程之后再切回来
2、是怎么被挂起的?
到这里你心里是否会有另外一个疑问:协程是怎么被挂起的?如果上面那个挂起函数这么写:
suspend fun mockTimeConsume(){
Log.d(TAG, "紧张的执行耗时任务中..." + Thread.currentThread().name);
Thread.sleep(3000)
}
运行后你会发现打印的线程是主线程,那为什么没有切换线程呢?因为它不知道往哪切,需要我们告诉它,之前我们是这么写的:
suspend fun mockTimeConsume() = withContext(Dispatchers.IO){
Log.d(TAG, "紧张的执行耗时任务中... " + + Thread.currentThread().name);
Thread.sleep(3000)
}
我们可以发现不同之处其实在于 withContext 函数。
其实通过 withContext 源码可以知道,它本身就是一个挂起函数,它接收一个 Dispatcher 参数,依赖这个 Dispatcher 参数的指示,你的协程就被挂起了,然后切到别的线程
所以使用 suspend 定义的挂起函数,还不是真正的挂起函数,真正的挂起函数内部需要调用到 Kotlin 协程框架自带的挂起函数
因此我们想要自己写一个挂起函数,仅仅只加上 suspend 关键字是不行的,还需要函数内部直接或间接地调用到 Kotlin 协程框架自带的 挂起函数才行
3、使用 suspend 的意义
通过上面的分析我们知道,使用 suspend 关键字修饰的函数可能还不是一个真正的挂起函数,那它的作用是啥呢?
起到一个提醒的作用,提醒调用者我是一个耗时函数,需要在挂起函数或者协程中调用我
为什么 suspend 关键字并没有实际去操作挂起,但 Kotlin 却把它提供出来?
因为它本来就不是用来操作挂起的。
挂起的操作 —— 也就是切线程,依赖的是挂起函数里面的实际代码,而不是这个关键字
所以这个关键字,只是一个提醒。
suspend fun mockTimeConsume(){
Log.d(TAG, "紧张的执行耗时任务中..." + Thread.currentThread().name);
Thread.sleep(3000)
}
上述这段代码这样做是没有意义的,而且会影响到程序的性能,AndroidStudio 也会提示你 suspend 修饰符是多余的。
4、如何自定义一个挂起函数?
第一步:分析在什么情况下去使用挂起函数?
如果你的某个函数比较耗时,涉及到多线程操作,如:网络请求,I/O 操作,CPU 计算工作等需要等待的操作,那就把它写成 suspend 挂起函数,这是原则
第二步:使用 suspend 关键字修饰你的函数,并在函数内部调用 Kotin 协程框架提供的挂起函数,如下:
suspend fun mockTimeConsume() = withContext(Dispatchers.IO){
Log.d(TAG, "紧张的执行耗时任务中... " + + Thread.currentThread().name);
Thread.sleep(3000)
}
十三、总结
这篇文章讲到了:
1、Kotlin 协程中涉及到的一些基础概念的理解
2、Kotlin 协程的基础使用,以及一些协程作用域构建器
3、Kotlin 协程中关于挂起的一个详细介绍
协程的内容真的挺多的,后续我还会写两篇关于协程的文章,希望能给你带来帮助
感谢你阅读这篇文章
参考和推荐
[第一行代码 Android 第3版]
扔物线 - Kotlin 协程的挂起好神奇好难懂?今天我把它的皮给扒了
全文到此,原创不易,欢迎点赞,收藏,评论和转发,你的认可是我创作的动力
欢迎关注我的 公 众 号,微信搜索 sweetying ,文章更新可第一时间收到