9.x - 13.0 postgresql 分区表新特性及简单用法
一、 分区表定义与意义
1. 分区表的定义
把一个大的物理表分成若干个小物理表,并使得这些小物理表在逻辑上可以被当成一张表来使用。
- 主表/父表/Master Table
主表是创建子表的模板,是一个正常的普通表,一般主表并不存任何数据。
- 子表/分区表/Chlid Table/Partition Table
子表继承并属于一个主表,与主表是一对多的关系,子表中存储所有的数据
2. 分区表的意义
- 性能提升:特定场景,查询更新转为分区操作提升性能
• 配置表:数据量小,易管理与优化
• 状态表:数据量大,性能问题
• 流水表:有明显的时间变化,每天数据量都很大,定期归档
• 统计表:加载后数据不变,数据量很大,需统计分析- 历史数据:历史数据归档和清理,通过drop分区实现,非常高效
- 存储拆分:单个表只能在一个位置,分区表冷热分离
3. 分区字段和分区策略
- 范围分区
- 列表分区
- 哈希分区
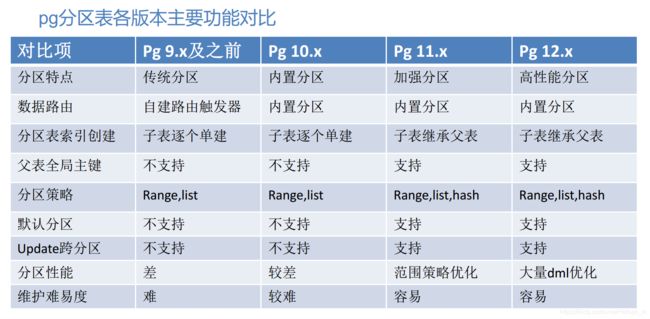
二、 pg各版本分区表实现
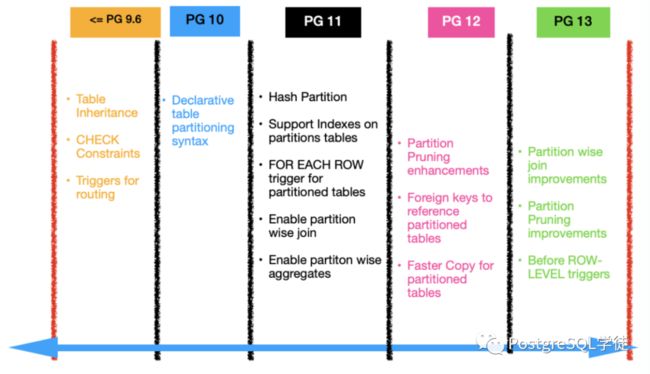
1. pg官方分区表的演进
- postgresql 9.x - 通过trigger实现的复杂传统分区表
- postgresql 10 - 开始支持内置分区表
- postgresql 11 - 主要完善分区表功能
- postgresql 12 - 分区表性能提升
- postgresql 13 - 提升性能及完善复制功能
- postgresql 14 - 提升性能及实现部分操作非阻塞执行
2. 传统分区表 – pg 9.x及之前版本
主表和分区表需分别创建,各自定义,数据不能自动关联
主表和分区表关系:通过继承和触发器实现
创建步骤:
- 定义父表及索引
CREATE TABLE pg_9_tab( id serial,uid int4,username varchar,create_time bigint);
CREATE INDEX idx_pg_9_tab_ctime ON pg_9_tab USING btree (create_time);- 定义子表及子表约束: 用 inherits 创建分区表,子表约束数据对应分区的规则
CREATE TABLE pg_9_tab_p_hisotry(CHECK ( create_time < 1569859200 ) ) INHERITS(pg_9_tab);
CREATE TABLE pg_9_tab_p_201910(CHECK ( create_time >= 1569859200 and create_time < 1572537600 ) ) INHERITS(pg_9_tab);
CREATE TABLE pg_9_tab_p_201911(CHECK ( create_time >= 1572537600 and create_time < 1575129600 ) ) INHERITS(pg_9_tab);
CREATE TABLE pg_9_tab_p_201912(CHECK ( create_time >= 1575129600 and create_time < 1577808000 ) ) INHERITS(pg_9_tab);- 创建子表索引 :子表不会继承父表的索引
CREATE INDEX idx_pg_9_tab_p_hisotry_ctime ON pg_9_tab_p_hisotry USING btree (create_time);
CREATE INDEX idx_pg_9_tab_p_201910_ctime ON pg_9_tab_p_201910 USING btree (create_time);
CREATE INDEX idx_pg_9_tab_p_201911_ctime ON pg_9_tab_p_201911 USING btree (create_time);
CREATE INDEX idx_pg_9_tab_p_201912_ctime ON pg_9_tab_p_201912 USING btree (create_time);- 创建分区插入、修改、删除函数和触发器
CREATE OR REPLACE FUNCTION pg_9_tab_insert_trigger()
RETURNS trigger
LANGUAGE plpgsql
AS $function$
BEGIN
… …
END;
$function$;
CREATE TRIGGER insert_pg_9_tab_trigger BEFORE INSERT ON pg_9_tab FOR EACH ROW EXECUTE PROCEDURE pg_9_tab_insert_trigger();- 启用分区查询参数:设置 constraint_exclusion 参数
set constraint_exclusion = partition;
show constraint_exclusion;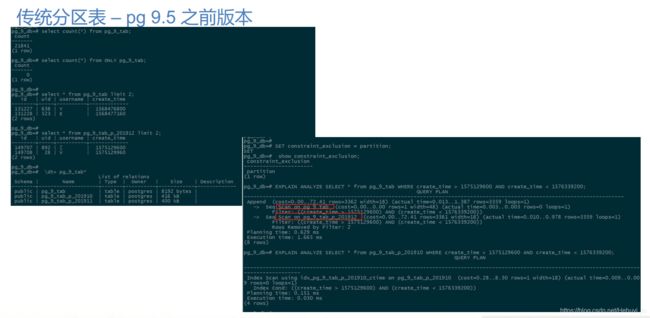
3. 内置分区表 – pg 10 支持版本
Postgresql 10提供了内置分区表,不需要预先在父表上定义触发器,对父表的DML操作也会自动路由到相应分区。
仅支持范围分区和列表分区。
创建步骤:
- 创建主表:指定分区键和分区策略(不能直接在主表建索引)
CREATE TABLE pg_10_tab( id serial, uid int4, username varchar, create_time bigint ) PARTITION BY RANGE(create_time);- 创建分区表:指定分区表的主表和分区键的取值范围,范围不能有重叠
CREATE TABLE pg_10_tab_p_hisotry PARTITION OF pg_10_tab FOR VAlUES FROM (1546272000) TO (1569859200);
CREATE TABLE pg_10_tab_p_201910 PARTITION OF pg_10_tab FOR VAlUES FROM (1569859200) TO (1572537600);
CREATE TABLE pg_10_tab_p_201911 PARTITION OF pg_10_tab FOR VAlUES FROM (1572537600) TO (1575129600);
CREATE TABLE pg_10_tab_p_201912 PARTITION OF pg_10_tab FOR VAlUES FROM (1575129600) TO (1577808000);- 在分区表上创建索引:分区键一般必须创建索引,其他列根据实际场景选择是否场景索引
CREATE INDEX idx_pg_10_tab_p_hisotry_ctime ON pg_10_tab_p_hisotry USING btree (create_time);
CREATE INDEX idx_pg_10_tab_p_201910_ctime ON pg_10_tab_p_201910 USING btree (create_time);
CREATE INDEX idx_pg_10_tab_p_201911_ctime ON pg_10_tab_p_201911 USING btree (create_time);
CREATE INDEX idx_pg_10_tab_p_201912_ctime ON pg_10_tab_p_201912 USING btree (create_time);- 插入数据及插入结果查询
INSERT INTO pg_10_tab(uid,username,create_time) SELECT round(1000*random()),chr(int4(random()*26)+65),generate_series(1568476800,1576339200,360);
SELECT count(*) FROM pg_10_tab;
SELECT count(*) FROM ONLY pg_10_tab;
\dt+ pg_10_tab*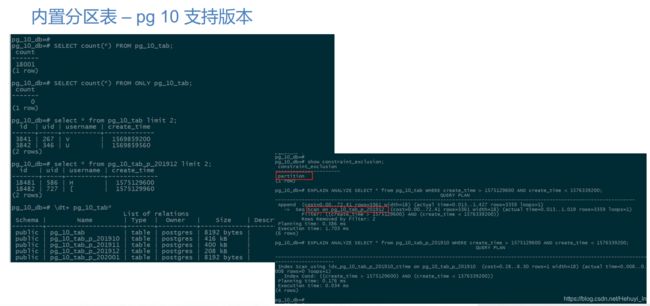

4. 增强分区表 – pg 11 支持版本
功能增强:
- 分区表可以继承主表的字段、索引信息
- 支持hash分区,rang/list 支持默认分区,多级分区
- 分区索引增强,分区主表可以创建主键,可以创建外键,
- DML增强,可以分区间移动行,可以路由到外部分区,
性能方面:
- 数据搜索访问优化,提升分区检索性能
创建步骤:
- 创建主表及相关索引:指定分区键和分区策略
CREATE TABLE pg_11_tab( id serial, uid int4, username varchar, create_time bigint ) PARTITION BY RANGE(create_time);
CREATE INDEX idx_pg_11_tab_ctime ON pg_11_tab USING btree (create_time);- 创建分区表:指定分区表的主表和分区键的取值范围,范围不能有重叠
CREATE TABLE pg_11_tab_p_hisotry PARTITION OF pg_11_tab DEFAULT;
CREATE TABLE pg_11_tab_p_201910 PARTITION OF pg_11_tab FOR VAlUES FROM (1569859200) TO (1572537600);
CREATE TABLE pg_11_tab_p_201911 PARTITION OF pg_11_tab FOR VAlUES FROM (1572537600) TO (1575129600);
CREATE TABLE pg_11_tab_p_201912 PARTITION OF pg_11_tab FOR VAlUES FROM (1575129600) TO (1577808000);
CREATE INDEX idx_pg_11_tab_p_hisotry_ctime ON pg_11_tab_p_hisotry USING btree (create_time); ##不用执行
CREATE INDEX idx_pg_11_tab_p_201910_ctime ON pg_11_tab_p_201910 USING btree (create_time);
CREATE INDEX idx_pg_11_tab_p_201911_ctime ON pg_11_tab_p_201911 USING btree (create_time);
CREATE INDEX idx_pg_11_tab_p_201912_ctime ON pg_11_tab_p_201912 USING btree (create_time); ##不用执行- 插入数据及插入结果查询
INSERT INTO pg_11_tab(uid,username,create_time) SELECT round(1000*random()),chr(int4(random()*26)+65),generate_series( 1568476800, 1576339200, 360);
SELECT count(*) FROM pg_11_tab;
SELECT count(*) FROM ONLY pg_11_tab;
\dt+ pg_11_tab*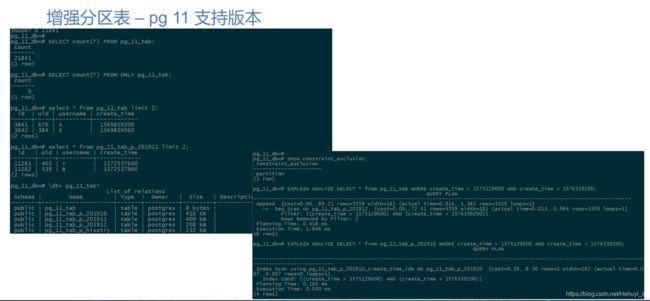

5. 高性能分区表 – pg 12 支持版本
- 功能方面:增加更多查询函数,便于快速查看分区表状态
- 性能方面:分区表的性能得到大幅提升,尤其是在分区表数量非常多时,DML性能提升更加明显
创建步骤:
CREATE TABLE pg_12_tab( id serial, uid int4, username varchar, create_time bigint ) PARTITION BY RANGE(create_time);
CREATE INDEX idx_pg_12_tab_ctime ON pg_11_tab USING btree (create_time);
CREATE TABLE pg_12_tab_p_hisotry PARTITION OF pg_12_tab DEFAULT;
CREATE TABLE pg_12_tab_p_201910 PARTITION OF pg_12_tab FOR VAlUES FROM (1569859200) TO (1572537600);
CREATE TABLE pg_12_tab_p_201911 PARTITION OF pg_12_tab FOR VAlUES FROM (1572537600) TO (1575129600);
CREATE TABLE pg_12_tab_p_201912 PARTITION OF pg_12_tab FOR VAlUES FROM (1575129600) TO (1577808000);
INSERT INTO pg_12_tab(uid,username,create_time)
SELECT round(1000*random()),chr(int4(random()*26)+65),generate_series( 1568476800, 1576339200, 360);
SELECT count(*) FROM pg_12_tab;
SELECT count(*) FROM ONLY pg_12_tab;
\dt+ pg_12_tab*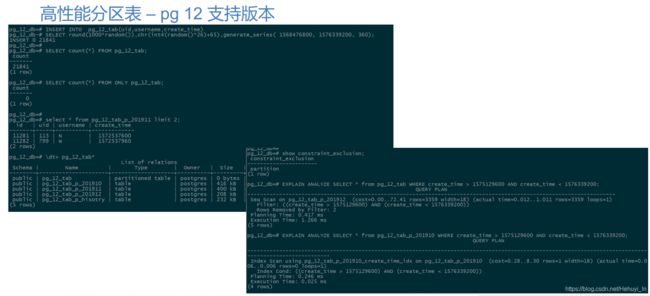

6. pg 13分区新特性
- 增强分区裁剪功能,可使用场景增多
- 增强智能分区join(partitionwise joins)
- 支持对分区表创建before row trigger(但不允许改变插入数据的目标分区)
- 之前只能把分区表的各个分区单独做为复制源,现在可以把分区表直接做为复制源。
- 先前订阅者只能把数据同步到非分区表,现在可以把数据同步到分区表
- 支持异构分区表逻辑复制: http://www.postgres.cn/v2/news/viewone/1/604
- Allow whole-row variables (that is,
table.*) to be used in partitioning expressions (Amit Langote)
案例参考: https://mp.weixin.qq.com/s/MbkdarHRrVGm3faiN7SOpw
PostgreSQL: Documentation: 13: E.5. Release 13
7. pg 14分区新特性
-
更新和删除可以定位到更精细的分区,性能提高,节省内存
-
Autovacuum现在支持analyze分区表,并将行统计信息反馈到父表,另外可以通过调整maintenance_io_concurrency异步IO参数调优。
-
支持非阻塞的ALTER TABLE ... DETACH PARTITION ... CONCURRENTLY
-
所有分区子表支持 reindex,pg 14还新增了pg_amcheck工具用于检查数据是否损坏
三、 分区表实践与问题(2019.11)
1. 分区后性能降低问题
- 业务表修改为分区表后,查询不走分区键,性能会下降很多
- 所有的查询都需要包含分区键,分区键兼顾性能与归档
- 如果表不是非常大,使用分区表性能降低太多,可不用分区表
2. 数据传输问题
- 开发数据同步传输通道
- DTS数据同步,不同版本传输性能的不同
3. 使用规范问题
- 所有有关pg的操作,都建立在pg体系结构之上
- 按照pg的设计和特点来使用pg
参考
《斗鱼 PostgreSQL分区表实践与思考_zhaofx_v1.5_20191122》
PostgreSQL表分区演进
关于分区表的方方面面