Power BI 傻瓜入门 8. 制作数据模型
本章内容包含:
- 描述不同的数据建模技术
- 配置属性以满足数据模型要求
- 设计模型以满足性能要求
您可能认为,通过Power BI对数据进行转换后,您将一帆风顺。在某些情况下,这是正确的。当然,当您创建了一个包含许多表的详细模型时,需要做一些工作来完善数据集。数据建模既是一门艺术,也是一门科学,因为你一直在努力塑造数据,以便获得尽可能精确的见解。一旦加载并转换数据,真正的乐趣就开始了——“努力完善它”部分。这就是引入建模的地方。在本章中,将描述模式设计,它为您提供所需的信息,以便设计和开发支持可视化和报告的数据模型。
数据模型导论
数据模型是可视化和报告的构建块。数据模型由一个或多个表和几个关系组成——假设存在不止一个或两个表。精心设计的数据模型可以帮助用户清晰地表达他们的数据,并建立在洞察力的基础上。因此,数据建模需要一些艰苦的工作——它不可能一蹴而就。您首先必须加载数据,然后在PowerBI的帮助下将数据转换为表后,必须定义表之间的关系。
记住,构建模型的最佳时间是在Power BI报告或可视化开发的开始阶段。如果你想创建有效的度量,你可以完善数据模型,强调表和关系管理。
使用数据架构
您已经导入了所有转换为一个或多个表的数据--现在怎么办?您的第一个业务目标是解决如何克服创建复杂数据模型的困难。在Power BI中,可以简化数据建模。
您的第一个目标是从数据模式开始。如果您从那里开始,您可能很快就会意识到您的数据来自一个或多个事务系统。在这种情况下,拥有许多桌子可能会让你不知所措。您不希望数据混乱——您希望组织并简化对数据的理解。这就是模式的用武之地。
使用PowerBI,您可以使用三种方法来设计和简化数据模式:平面模式、雪花模式和星形模式。了解何时使用每种模型类型有助于支持可视化和报告中的数据性能和粒度。接下来的几个部分旨在帮助您获得这种理解。
平面模式
考虑列出销售交易、客户身份或奖励。所有这些有什么共同点?假设您要在Excel电子表格中布置数据。在这种情况下,您可能只需要一个表来显示基本数据。在这种情况下,您会希望使用一个平面模式,即只使用一个表的模式,类似于图8-1中所示的模式。

注意图8-1中的四列。这些数据列中的每一列都可能有一个唯一的标识符:一个特定的时间/日期戳,显示输入客户数据的时间、公司名称、客户ID和公司联系人。这些数据点中的每一个都可以用作查找,以更好地独立评估详细的客户信息。然而,当你看模型时,它可以独立存在。当报告需求是线性和简单的,只需要一个表时,您可以考虑使用平面模式。
提示平面模式的使用价值往往有限。当您希望将电子表格中的信息带入Power BI进行基本分析时——这项任务可能涉及添加一列值或过滤数据——这种方法就足够了。一旦引入了许多表,就必须采用另一种方法。
如果只部署一个表,它可以用于报告,但范围有限。也许您可以过滤数据或提取一两个数据点来构建简化的视觉效果或基本的计算输出。这就是平面模式的有用性结束的地方。
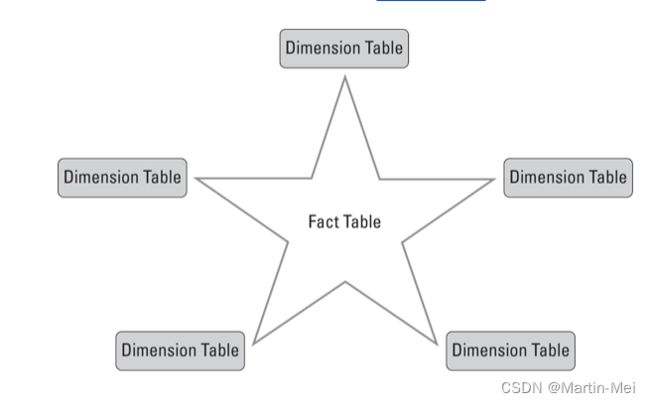
星形模式
大多数组织都有一个代表星形模式方法的模型。您经常会发现模型中有一个或两个称为事实表的大表,然后是一些维度表。当数据建模师规划模型时,通常将表建模为维度或事实。以下是它们的区别:
- 事实表代表观察或事件。考虑诸如销售交易、帐户余额和人员记录之类的模式。事实数据表连接到一个或多个与给定维度相关的维度键列。例如,具有销售交易的交易表(事实表)可能映射到制造商(维度表)。维度键列决定项目的维度--事实表中的详细信息。维度键值提供产品粒度。
- 维度表详细描述了业务实体。这些是产品的属性、人员、地点和概念,是事实表的一部分。将维度视为可以提供更高粒度级别的质量属性.
请记住,维度表通常具有有限数量的行,因为这些行是广泛使用的描述符。事实表可以容纳许多行,并且随着时间的推移而增长,因为这些行是事务记录。考虑一下,维度表是过滤和分组的一个很好的工具,而事实表是摘要的一个例子。
每当生成Power BI报告可视化时,您都会注意到会针对Power BI模型(也称为数据集)生成查询。查询用于筛选、分组和汇总模型数据。您的主要目标是创建一个能够满足这些特定业务目标的模型。图8-2展示了事实与维度表的概念,而图8-3展示了原型星形模式。
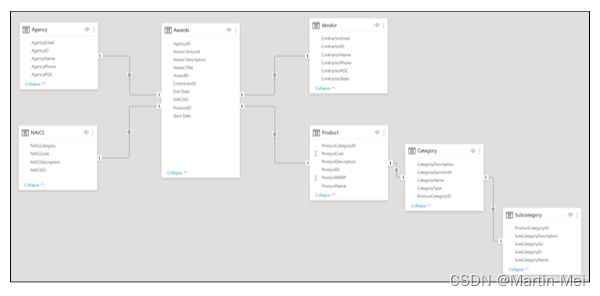
记住,对于星形模式,不存在将表分类为事实或维度的属性。关系本身决定了模型行为。在两个实体之间建立模型关系,并在实体内维护属性。
基数——换句话说,关系的性质--确定表格类型。常见的关系是一对一、一对多或多对多。一边总是维度表,而另一边总是事实表。然而,很少在星形模式中找到一对一的关系,因为事实表往往会多次重复维度。
提示:使用数据建模,结构良好的模型设计包括维度类型或事实类型的不同表。不要混合表类型来创建一个表。如果创建一个表,您很快就会意识到现有的数据格式不好。这就是为什么你应该评估你的数据,以确保你有适当数量的表和正确的关系。
记住,好的数据建模设计既是一门艺术,也是一门科学。你试着遵守所有的规则,但有时你的数据不允许你成为一个完美主义者。尽量坚持到底,尽最大努力创建最纯粹的数据模型。
雪花模式
另一种类型的模式是雪花模式,它是星形模式的扩展,其中有一组针对单个业务实体进行深入研究的规范化表。规范化数据有助于减少数据冗余并提高数据完整性。假设您的每个产品都属于一个类别或子类别。从单一的商业实体产品到相关类别和子类别的向外分支让一些人想起了雪花。(好吧,在它的雪花般变得明显之前,你必须斜视它几分钟——试试图8-4。)

使用度量值存储值
一般来说,度量是一种可以用于存储汇总值的事实表列。当您使用Power BI模型时,度量具有类似的定义。您正在使用DAX创建一个公式来实现摘要列。DAX中经常使用的度量与聚合函数(如SUM、MIN、MAX和AVERAGE)相关联,以便在数据查询时生成值。
然而,还有第二种方法可以实现摘要。任何数字列都可以通过报表和仪表板或问答(Q&a)中表示的可视化进行汇总。第二种类型的度量是隐式度量。您可以创建一个以多种方式汇总数据的列,而不必创建多个聚合类型。
那么,你什么时候会使用度量,即使是基本的专栏摘要?以下是一些完全合理的情况:
- 当报告作者打算通过使用多维表达式(MDX)查询模型时:这些模型需要显式度量,这需要使用DAX。
- 当报告作者使用MDX查询设计创建Power BI分页报告时:模型需要包括显式度量。
- 当报告作者必须使用Power BI对原始数据集进行分析时。作者必须使用MDX查询设计器
- 当数据汇总必须以特定方式完成时:例如,当您使用Power BI中可用的聚合功能时,可以使用度量值。
要实现度量,最简单的方法是单击功能区“计算”区域中的“快速度量”图标。(当您处于“数据”视图中时,该区域位于Ribbon的“主页”选项卡上,如图8-5所示。)

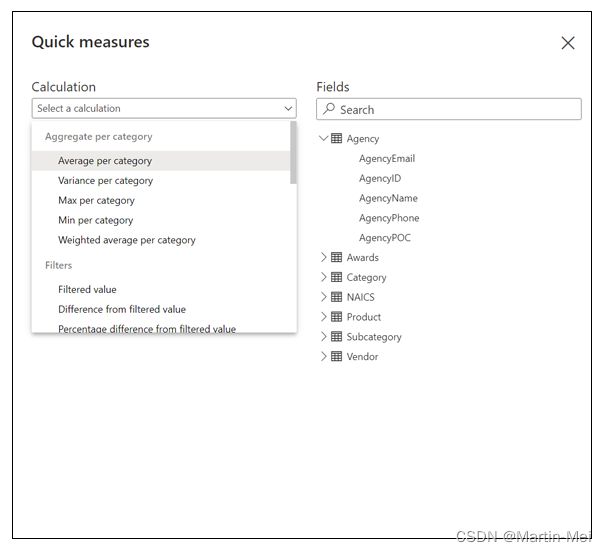
您可以使用“快速测量”部署各种计算,包括使用预定义计算构建的公式。以下是计算类别:
- 每类聚合
- 筛选
- 数学运算
- 文本
- 时间智能
- 总计
图8-6列出了Aggregate Per Category标题和Filters标题下的一些选项。
另一种选择是使用“新度量”创建自己的公式。要创建新度量值,请执行以下步骤:
- 在“数据”选项卡下,右键单击列,或单击字段窗格中的省略号,然后从显示的菜单中选择“新建度量值”。
选择“新建度量值”可以使用新的预定义公式启动新度量值。(默认情况下,NewMeasure以Measure=开头。)一些数据可能会预先填充在公式栏上,如图8-7所示。
- 将“Measure=”替换为新列的名称和等号,然后添加预构建的DAX公式。(将在第15章中对此进行详细介绍。)
一个示例措施可以是TotalBid = Sum(Awards[Bids].
如果使用“新度量”,则生成的产品是基于DAX的公式。否则,公式栏将生成代码。
使用维度和事实数据表(再次)
使用Power BI,在准备数据模型时,您会注意到一个主题:您经常将实体(如Product、Manufacturer或Company)称为维度表。这些表连接到一个事实数据表,例如Customer、Sales或Invoices。现在,维度是描述数据的一种定性方式,但事实表本质上主要是定量的,在这里你可以执行数学函数。在前面的模型中,如图8-2所示,您注意到一个事实表和许多维度表。每个维度表(通常称为一个维度)都有许多描述性字段,但只有几行。事实数据表的情况并非如此,您会发现该表的字段很少,但行却很多。
在规划数据模型的设计时,在创建维度数据时有几种方法。表8-1描述了每种方法
| 方法 | 描述 |
| 缓慢变化维度 | 管理尺寸随时间的变化。 |
| 角色模仿维度 | 根据许多标准筛选事实。 |
| 杂项维度 | 当您有多个维度而属性很少时,适合考虑。值也很少,这使得数据可能受到限制。例子可能包括性别和年龄组。 |
| 退化维度 | 需要筛选所需的事实数据表的属性。在这种情况下,主键就是一个例子。 |
| 非事实型事实 | 不包含度量值,只包含维度键。 |
展平层次结构
层次结构是一组字段,其中一个级别是其他级别的父级。父级别的值可以向下钻取到较低级别类别。父子层次结构显示零售环境中有关帐户、客户或销售人员的数据。层次结构基于可变深度。例如,在描述业务领域时,您可能会根据国家、州或街道来说明数据。一个组织也可能与一个地区联系在一起。在这种情况下,您有一个四级层次结构。
Power BI中的一种常见做法是使层次结构变平——换句话说,使层次结构成为一个级别——这样,一个规则的层次结构就由层次结构的一列组成。每个节点都表示在一个单独的、不同的列中。在图8-8中,您可以看到产品类别ID是如何与产品名称和产品ID绑定的。这表示一个两级层次结构,因为每个项目都与一个公共因素(产品类别ID)互斥。

创建层次结构时有几个选项。以下指令集是创建父子层次结构的最有效方法--您需要在“报告”视图中才能完成以下一系列操作:
- 在字段上单击鼠标右键,然后从显示的菜单中选择“创建层次”。
将创建一个顶级层次结构。 - 右键单击要添加到新创建的层次结构中的项目的字段,然后从显示的菜单中选择“添加到层次结构”。
- 在显示的列表中,选择要添加的层次结构。在这种情况下,我将ProductsName添加到ProductName Hierarchy中。
要更改层次结构中字段的顺序,请执行以下步骤:
- 在层次结构中的字段上单击鼠标右键。
- 从显示的菜单中选择“上移”或“下移”。
提示:如果还没有现有关系,也可以将字段拖动到所需位置。
创建层次结构的另一种方法是将“数据”视图与“公式”栏结合使用。在本例中,我使用“子类别”表向您展示如何创建层次结构。请执行以下步骤:
- 在Power BI Desktop中,在屏幕左侧的导航窗格中选择“数据视图”。
- 选择“数据”视图后,请选择一个表。
- 从功能区中,选择“计算”选项卡上的“新建列”。
通过添加新列,可以向现有表中添加其他数据,可能是由两个或多个其他列生成的公式。 - 在公式栏中,键入以下行作为一行,然后按Enter键:
Path = PATH (Subcategory[SubcategoryName],Subcategory[ProductCategoryID])您正在使用PATH函数来创建层次结构路径。
- 从功能区中,再次选择“计算”选项卡上的“新建列”。
请记住,您正在将另一个级别添加到已创建的现有层次结构中。 - 在公式栏中,键入以下行,然后按Enter键:
Level 2 = PATHITEM(Subcategory [Path],1)
这里使用的是PATHTITEM函数,它检索层次结构中特定级别的值。在本例中,您有三个级别。是时候添加层次结构的其余两列了。您将重复此操作以创建三级层次结构。每次按Enter键时,都会建立一个新的层次级别。 - 在公式栏中,键入以下行,然后按Enter键:
Level 2 = PATHITEM(Subcategory [Path],2) - 同样,在公式栏中,键入以下行并按Enter键:
Level 3 = PATHITEM(Subcategory [Path],3)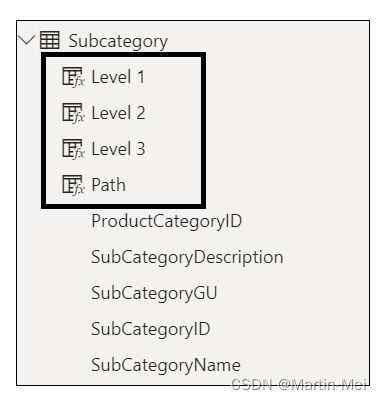
处理表和列属性
在本章的前面,我将简要讨论表和列的设计。一个共同点是用户可以配置许多属性,所有这些属性都可以在Model视图中设置。但是,要查看列或表的属性,首先需要选择一个对象。选择后,对象的特性将在“特性”窗格中可见。
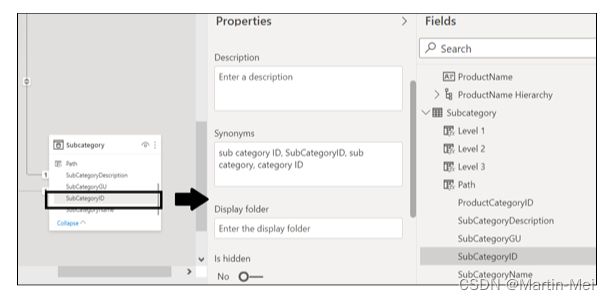
要查看其工作原理,请从Power BI界面左侧的导航栏中选择“模型视图”。在“模型”视图中,单击表特性的对象以查看其特性。如果要查看特定的列属性,请单击表中的列。您可以在图8-10和8-11中看到表和列属性的示例。
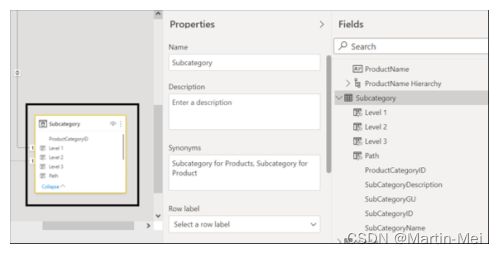
以下是表属性选项:
- 名称
- 描述
- 同义词
- 行标签
- 键列
- 是否隐藏
- 是否特别推荐的表
以下是列属性:
- 名称
- 描述
- 同义词
- 显示文件夹
- 是否隐藏
- 数据类型
- 格式
- 按列排序
- 数据类别
- 汇总依据
- 可为空
管理基数和方向
在本章的前几节中,我简要讨论了字段和表之间的关系。重要的是要记住,无论你是试图建立一对一、一对多、多对一还是多对多的关系,这些都被称为表之间的关系——换句话说,它的基数。要编辑表之间的关系,请单击模型中的关系链接。这样做会显示一个窗口,您可以使用它来更好地设置基数,如Model视图中所示。(图8-12提供了这样一个可编辑关系的示例。)您可以在该页面上更改关系基数。您可以看到每个数据集的预览,以选择成为关系一部分的列。
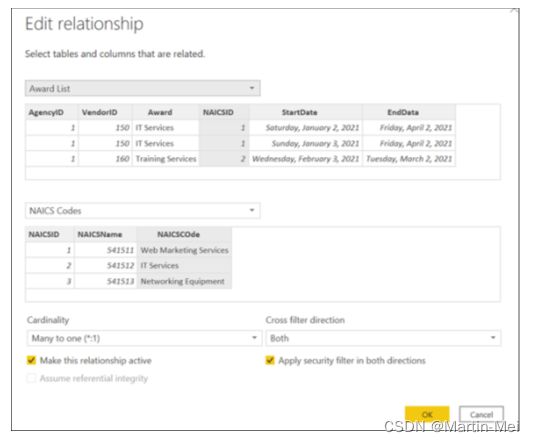
若要确保关系处于活动状态,请确保选中“使此关系处于活动”复选框。(再次参见图8-12。)两个表之间只能有一个活动关系。此外,如果选择使用直接查询,则应选中“假定引用完整性”复选框。(引用完整性有助于提高查询性能。)
基数
两张表之间的关系有四种类型:一对一、一对多、多对一或多对多。大多数情况下,使用Power BI,您可以使用多对一关系来实现数据模型的各个部分。表8-2描述了四种关系类型之间的差异。
交叉过滤器方向
仅仅因为在两个表之间设置了关系类型,并不意味着数据将按照您想要的方式流动。事实上,如果您回头看图8-12,您还会注意到屏幕右下角的Cross Filter Direction下拉菜单。设置关系时,还可以显示过滤器的流动方向。对于一对多或多对一,您可以选择“单个”或“两个”。
| 关系类型 | 描述 |
| 一对一(1:1) | 键数据在两个表中只显示一次。 |
| 一对多(1:M) | 许多是指一个键可能在选择列中出现多次。一种是指键值在选定的表中只出现一次。当您有1:M关系时,关系左侧的一个键充当唯一标识符,而右侧的许多项可以匹配。 |
| 多对一(M:1) | 类似于一对多(1:M)关系,许多项目通常可以绑定到单个键。唯一的区别是关键数据的方向和顺序。 |
| 多对多(M:M) | 两个表之间存在关系;但是,两个表之间可能没有唯一的值。 |
那么,Single和Both到底是什么意思呢?以下是一条线索:
- Single:将数据从“一侧”的表过滤为“多侧”的表数据。一个箭头指向“模型”视图中的关系线。
- Both:从两个表双向筛选。这些关系是双向的。“模型”视图中的关系线中会出现两个箭头。
为“应用交叉过滤器方向”选择“两者”时,也可以选择“应用安全过滤器”。添加这样的功能引入了行级安全性,这是一种基于行访问对数据进行限制的方法。
在图8-13中,注意NAICS代码表和奖励列表表之间的双向性。另一方面,在Agency Contacts表和Award List表之间存在多对一的关系,因此只有一个交叉过滤方向。这意味着许多机构联系人可以绑定到一个获奖名单条目。两个表之间的记录数量各不相同,给定1:M或M:1(有双向性和无双向性)。
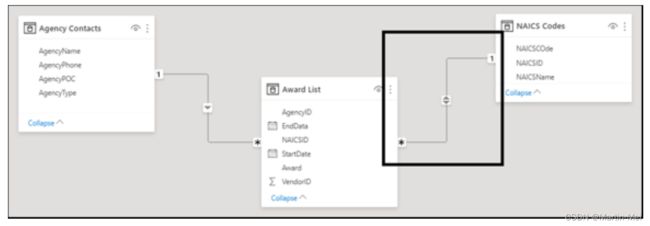
数据颗粒
数据背后的细节很重要。这就是为什么数据粒度——数据的特殊性--
重要。再看一下图8-13所示的奖励列表表。您可以看到,该示例提供了NAICS代码ID来处理奖励的精细分类。按粒度较低的字段(如StartDate或EndDate)筛选数据可能会有所帮助。尽管如此,它并没有提供一个明确的结果集。响应范围很广,如图8-14所示。根据与NAICS代码表的关系,按NAICS代码ID进行筛选提供了更精细的数据集。
并非所有数据集都能达到您想要的粒度级别。需要细化数据的示例(包括引入新列时)很常见。在某些情况下,即使是不受支持的表也可以进行筛选,但结果并不能得到您想要的结果。在第15章和第16章中所讨论的,当试图更好地评估数据粒度时,ISFILTERED函数的使用非常方便。