一. 运维
1. Master挂掉,standby重启也失效
Master默认使用512M内存,当集群中运行的任务特别多时,就会挂掉,原因是master会读取每个task的event log日志去生成Spark ui,内存不足自然会OOM,可以在master的运行日志中看到,通过HA启动的master自然也会因为这个原因失败。
解决
-
增加Master的内存占用,在Master节点
spark-env.sh中设置:export SPARK_DAEMON_MEMORY 10g # 根据你的实际情况 -
减少保存在Master内存中的作业信息
spark.ui.retainedJobs 500 # 默认都是1000 spark.ui.retainedStages 500
2. worker挂掉或假死
有时候我们还会在web ui中看到worker节点消失或处于dead状态,在该节点运行的任务则会报各种 lost worker 的错误,引发原因和上述大体相同,worker内存中保存了大量的ui信息导致gc时失去和master之间的心跳。
解决
-
增加Master的内存占用,在Worker节点
spark-env.sh中设置:export SPARK_DAEMON_MEMORY 2g # 根据你的实际情况 -
减少保存在Worker内存中的Driver,Executor信息
spark.worker.ui.retainedExecutors 200 # 默认都是1000 spark.worker.ui.retainedDrivers 200
二. 运行错误
1.shuffle FetchFailedException
Spark Shuffle FetchFailedException解决方案
错误提示
-
missing output location
org.apache.spark.shuffle.MetadataFetchFailedException: Missing an output location for shuffle 0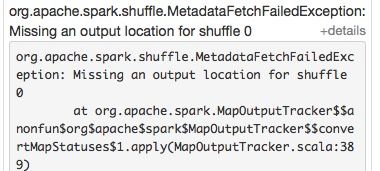
-
shuffle fetch faild
org.apache.spark.shuffle.FetchFailedException: Failed to connect to spark047215/192.168.47.215:50268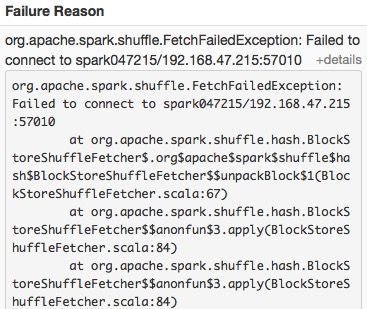
当前的配置为每个executor使用1core,5GRAM,启动了20个executor
解决
这种问题一般发生在有大量shuffle操作的时候,task不断的failed,然后又重执行,一直循环下去,直到application失败。
一般遇到这种问题提高executor内存即可,同时增加每个executor的cpu,这样不会减少task并行度。
- spark.executor.memory 15G
- spark.executor.cores 3
- spark.cores.max 21
启动的execuote数量为:7个
execuoterNum = spark.cores.max/spark.executor.cores
每个executor的配置:
3core,15G RAM
消耗的内存资源为:105G RAM
15G*7=105G
可以发现使用的资源并没有提升,但是同样的任务原来的配置跑几个小时还在卡着,改了配置后几分钟就能完成。
2.Executor&Task Lost
错误提示
-
executor lost
WARN TaskSetManager: Lost task 1.0 in stage 0.0 (TID 1, aa.local): ExecutorLostFailure (executor lost) -
task lost
WARN TaskSetManager: Lost task 69.2 in stage 7.0 (TID 1145, 192.168.47.217): java.io.IOException: Connection from /192.168.47.217:55483 closed -
各种timeout
java.util.concurrent.TimeoutException: Futures timed out after [120 second] ERROR TransportChannelHandler: Connection to /192.168.47.212:35409 has been quiet for 120000 ms while there are outstanding requests. Assuming connection is dead; please adjust spark.network. timeout if this is wrong
解决
由网络或者gc引起,worker或executor没有接收到executor或task的心跳反馈。
提高 spark.network.timeout 的值,根据情况改成300(5min)或更高。
默认为 120(120s),配置所有网络传输的延时,如果没有主动设置以下参数,默认覆盖其属性
- spark.core.connection.ack.wait.timeout
- spark.akka.timeout
- spark.storage.blockManagerSlaveTimeoutMs
- spark.shuffle.io.connectionTimeout
- spark.rpc.askTimeout or spark.rpc.lookupTimeout
3.倾斜
错误提示
-
数据倾斜
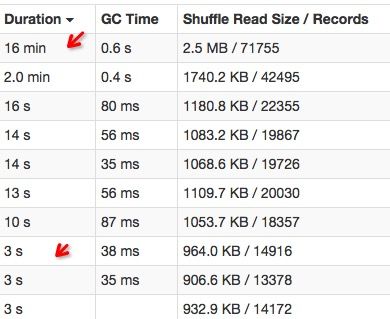
-
任务倾斜
差距不大的几个task,有的运行速度特别慢。
解决
大多数任务都完成了,还有那么一两个任务怎么都跑不完或者跑的很慢,分为数据倾斜和task倾斜两种。
-
数据倾斜
数据倾斜大多数情况是由于大量的无效数据引起,比如null或者”“,也有可能是一些异常数据,比如统计用户登录情况时,出现某用户登录过千万次的情况,无效数据在计算前需要过滤掉。
数据处理有一个原则,多使用filter,这样你真正需要分析的数据量就越少,处理速度就越快。sqlContext.sql("...where col is not null and col != ''")具体可参考:
解决spark中遇到的数据倾斜问题 -
任务倾斜
task倾斜原因比较多,网络io,cpu,mem都有可能造成这个节点上的任务执行缓慢,可以去看该节点的性能监控来分析原因。以前遇到过同事在spark的一台worker上跑R的任务导致该节点spark task运行缓慢。
或者可以开启spark的推测机制,开启推测机制后如果某一台机器的几个task特别慢,推测机制会将任务分配到其他机器执行,最后Spark会选取最快的作为最终结果。- spark.speculation true
- spark.speculation.interval 100 - 检测周期,单位毫秒;
- spark.speculation.quantile 0.75 - 完成task的百分比时启动推测
- spark.speculation.multiplier 1.5 - 比其他的慢多少倍时启动推测。
4.OOM
错误提示
堆内存溢出
java.lang.OutOfMemoryError: Java heap space
解决
内存不够,数据太多就会抛出OOM的Exeception,主要有driver OOM和executor OOM两种
-
driver OOM
一般是使用了collect操作将所有executor的数据聚合到driver导致。尽量不要使用collect操作即可。 -
executor OOM
可以按下面的内存优化的方法增加code使用内存空间- 增加executor内存总量,也就是说增加
spark.executor.memory的值 - 增加任务并行度(大任务就被分成小任务了),参考下面优化并行度的方法
- 增加executor内存总量,也就是说增加
5.task not serializable
错误提示
org.apache.spark.SparkException: Job aborted due to stage failure:
Task not serializable: java.io.NotSerializableException: ...
解决
如果你在worker中调用了driver中定义的一些变量,Spark就会将这些变量传递给Worker,这些变量并没有被序列化,所以就会看到如上提示的错误了。
val x = new X() //在driver中定义的变量
dd.map{r => x.doSomething(r) }.collect //map中的代码在worker(executor)中执行- 1
- 2
- 1
- 2
除了上文的map,还有filter,foreach,foreachPartition等操作,还有一个典型例子就是在foreachPartition中使用数据库创建连接方法。这些变量没有序列化导致的任务报错。
下面提供三种解决方法:
- 将所有调用到的外部变量直接放入到以上所说的这些算子中,这种情况最好使用foreachPartition减少创建变量的消耗。
- 将需要使用的外部变量包括
sparkConf,SparkContext,都用@transent进行注解,表示这些变量不需要被序列化 - 将外部变量放到某个class中对类进行序列化。
6.driver.maxResultSize太小
错误提示
Caused by: org.apache.spark.SparkException:
Job aborted due to stage failure: Total size of serialized
results of 374 tasks (1026.0 MB) is bigger than
spark.driver.maxResultSize (1024.0 MB)
解决
spark.driver.maxResultSize默认大小为1G 每个Spark action(如collect)所有分区的序列化结果的总大小限制,简而言之就是executor给driver返回的结果过大,报这个错说明需要提高这个值或者避免使用类似的方法,比如countByValue,countByKey等。
将值调大即可
spark.driver.maxResultSize 2g
7.taskSet too large
错误提示
WARN TaskSetManager: Stage 198 contains a task of very large size (5953 KB). The maximum recommended task size is 100 KB.- 1
- 1
这个WARN可能还会导致ERROR
Caused by: java.lang.RuntimeException: Failed to commit task
Caused by: org.apache.spark.executor.CommitDeniedException: attempt_201603251514_0218_m_000245_0: Not committed because the driver did not authorize commit- 1
- 2
- 3
- 1
- 2
- 3
解决
如果你比较了解spark中的stage是如何划分的,这个问题就比较简单了。
一个Stage中包含的task过大,一般由于你的transform过程太长,因此driver给executor分发的task就会变的很大。
所以解决这个问题我们可以通过拆分stage解决。也就是在执行过程中调用cache.count缓存一些中间数据从而切断过长的stage。
8. driver did not authorize commit
driver did not authorize commit
9. 环境报错
-
driver节点内存不足
driver内存不足导致无法启动application,将driver分配到内存足够的机器上或减少driver-memoryJava HotSpot(TM) 64-Bit Server VM warning: INFO:os::commit_memory(0x0000000680000000, 4294967296, 0) failed;
error=’Cannot allocate memory’ (errno=12) -
hdfs空间不够
hdfs空间不足,event_log无法写入,所以ListenerBus会报错,增加hdfs空间(删除无用数据或增加节点)Caused by: org.apache.hadoop.ipc.RemoteException(java.io.IOException): File /tmp/spark-history/app-20151228095652-0072.inprogress could only be replicated to 0 nodes instead of minReplication (=1) ERROR LiveListenerBus: Listener EventLoggingListener threw an exception java.lang.reflect.InvocationTargetException -
spark编译包与Hadoop版本不一致
下载对应hadoop版本的spark包或自己编译。java.io.InvalidClassException: org.apache.spark.rdd.RDD; local class incompatible: stream classdesc serialVersionUID -
driver机器端口使用过多
在一台机器上没有指定端口的情况下,提交了超过15个任务。16/03/16 16:03:17 ERROR SparkUI: Failed to bind SparkUI java.net.BindException: 地址已在使用: Service 'SparkUI' failed after 16 retries!提交任务时指定app web ui端口号解决:
--conf spark.ui.port=xxxx
三. 一些python错误
1.python版本过低
java.io.UIException: Cannot run program "python2.7": error=2,没有那个文件或目录
spark使用的Python版本为2.7,centOS默认python版本为2.6,升级即可。
2.python权限不够
错误提示
部分节点上有错误提示
java.io.IOExeception: Cannot run program "python2.7": error=13, 权限不够
解决
新加的节点运维装2.7版本的python,python命令是正确的,python2.7却无法调用,只要改改环境变量就好了。
3.pickle使用失败
错误提示
TypeError: ('__cinit__() takes exactly 8 positional arguments (11 given)',
, (10, array([1], dtype=int32), 1,
,
50.0, 2, 1, 0.1, 10, 1, ))
解决
该pickle文件是在0.17版本的scikit-learn下训练出来的,有些机器装的是0.14版本,版本不一致导致,升级可解决,记得将老版本数据清理干净,否则会报各种Cannot import xxx的错误。
四. 一些优化
1. 部分Executor不执行任务
有时候会发现部分executor并没有在执行任务,为什么呢?
(1) 任务partition数过少,
要知道每个partition只会在一个task上执行任务。改变分区数,可以通过 repartition 方法,即使这样,在 repartition 前还是要从数据源读取数据,此时(读入数据时)的并发度根据不同的数据源受到不同限制,常用的大概有以下几种:
hdfs - block数就是partition数
mysql - 按读入时的分区规则分partition
es - 分区数即为 es 的 分片数(shard)
(2) 数据本地性的副作用
taskSetManager在分发任务之前会先计算数据本地性,优先级依次是:
process(同一个executor) -> node_local(同一个节点) -> rack_local(同一个机架) -> any(任何节点)
Spark会优先执行高优先级的任务,任务完成的速度很快(小于设置的spark.locality.wait时间),则数据本地性下一级别的任务则一直不会启动,这就是Spark的延时调度机制。
举个极端例子:运行一个count任务,如果数据全都堆积在某一台节点上,那将只会有这台机器在长期计算任务,集群中的其他机器则会处于等待状态(等待本地性降级)而不执行任务,造成了大量的资源浪费。
判断的公式为:
curTime – lastLaunchTime >= localityWaits(currentLocalityIndex)
其中 curTime 为系统当前时间,lastLaunchTime 为在某优先级下最后一次启动task的时间
如果满足这个条件则会进入下一个优先级的时间判断,直到 any,不满足则分配当前优先级的任务。
数据本地性任务分配的源码在 taskSetManager.Scala 。
如果存在大量executor处于等待状态,可以降低以下参数的值(也可以设置为0),默认都是3s。
spark.locality.wait
spark.locality.wait.process
spark.locality.wait.node
spark.locality.wait.rack
当你数据本地性很差,可适当提高上述值,当然也可以直接在集群中对数据进行balance。
2. spark task 连续重试失败
有可能哪台worker节点出现了故障,task执行失败后会在该 executor 上不断重试,达到最大重试次数后会导致整个 application 执行失败,我们可以设置失败黑名单(task在该节点运行失败后会换节点重试),可以看到在源码中默认设置的是 0,
private val EXECUTOR_TASK_BLACKLIST_TIMEOUT =
conf.getLong("spark.scheduler.executorTaskBlacklistTime", 0L) - 1
- 2
- 1
- 2
在 spark-default.sh 中设置
spark.scheduler.executorTaskBlacklistTime 30000
当 task 在该 executor 运行失败后会在其它 executor 中启动,同时此 executor 会进入黑名单30s(不会分发任务到该executor)。
3. 内存
如果你的任务shuffle量特别大,同时rdd缓存比较少可以更改下面的参数进一步提高任务运行速度。
spark.storage.memoryFraction - 分配给rdd缓存的比例,默认为0.6(60%),如果缓存的数据较少可以降低该值。 spark.shuffle.memoryFraction - 分配给shuffle数据的内存比例,默认为0.2(20%)
剩下的20%内存空间则是分配给代码生成对象等。
如果任务运行缓慢,jvm进行频繁gc或者内存空间不足,或者可以降低上述的两个值。 "spark.rdd.compress","true" - 默认为false,压缩序列化的RDD分区,消耗一些cpu减少空间的使用
4. 并发
mysql读取并发度优化
spark.default.parallelism
发生shuffle时的并行度,在standalone模式下的数量默认为core的个数,也可手动调整,数量设置太大会造成很多小任务,增加启动任务的开销,太小,运行大数据量的任务时速度缓慢。
spark.sql.shuffle.partitions
sql聚合操作(发生shuffle)时的并行度,默认为200,如果该值太小会导致OOM,executor丢失,任务执行时间过长的问题
相同的两个任务:
spark.sql.shuffle.partitions=300:
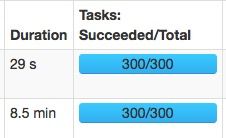
spark.sql.shuffle.partitions=500:
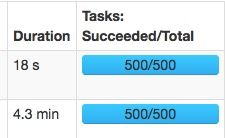
速度变快主要是大量的减少了gc的时间。
但是设置过大会造成性能恶化,过多的碎片task会造成大量无谓的启动关闭task开销,还有可能导致某些task hang住无法执行。

修改map阶段并行度主要是在代码中使用rdd.repartition(partitionNum)来操作。
5. shuffle
spark-sql join优化
map-side-join 关联优化
6. 磁盘
磁盘IO优化
7.序列化
kryo Serialization
8.数据本地性
Spark不同Cluster Manager下的数据本地性表现
spark读取hdfs数据本地性异常
9.代码
编写Spark程序的几个优化点