TSQL查询内幕::(2.2)编译
批处理是作为一个单元编译的一个或多个T-SQL语句的组合,存储过程就是一个批处理的例子。另一个例子就是在查询管理器中,输入一组语句,GO命令把多条语句分隔为单独的批处理。GO不是一个T-SQL语句,只是SQL Server的企业管理器的一个关键字,企业管理器通过这个关键字来分隔批处理(SQLCMD、OSQL也是使用GO来表示批处理的)。
SQL Server把批处理中的语句编译到一个被称为“执行计划”(execution plan)的可执行单元。在编译期间,编译器展开这些语句,其中包含该语句执行期间需要执行的相关约束、触发器以及级联操作。如果经过编译的批处理包含对其他存储过程或函数的调用,且缓存中没有他们的执行计划,则这些存储过程和函数也将被递归的编译。
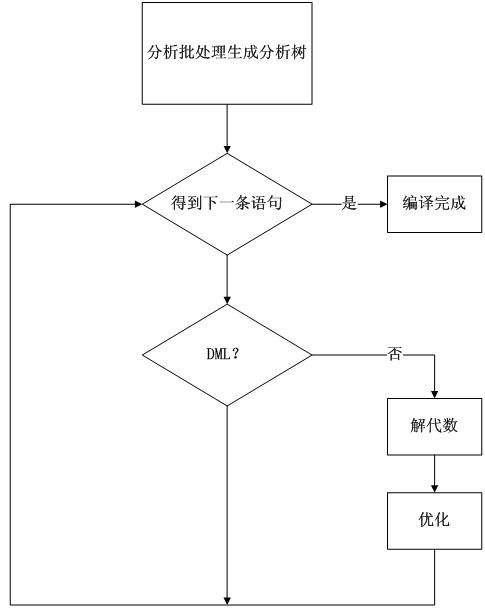
批处理编译的主要步骤:
编译和执行查询处理是两个截然不同的阶段,有可能一个编译需要几个小时,可是执行该查询只需要几毫秒。处理即席查询时缓存中通常不包含其执行计划,因此它被编译后会立即执行。而经常执行的存储过程的已编译计划可能会在过程缓存中保留很长时间。在需要释放存储空间时,SQL Server会从过程缓存中首先移除不常用的计划
当SQL Server准备处理一个批处理时,如果缓存中不存在该批处理的执行计划,则编译该批处理并生成执行计划。
首先,SQL Server执行分析。分析是检查语法并把SQL批处理转换为分析树(parse tree)的过程,如检查表或列明是否以数字开头,但他不会检查WHERE中的列是否存在于FROM子句中所写的表中。
然后,SQL Server进行绑定。绑定过程确定SQL语句所引用对象的特征,他检查请求语义是否有意义,参见下面的Algebrizer。
优化是编译的最后一步。优化器必须把基于几何的非过程SQL语句转换为可以高效执行并返回期望结果的程序。与绑定类似,优化器一次只优化批处理中的一条语句。在编译器为该批处理生成执行计划并存储到过程缓存之后,将执行该计划的执行上下文的一个特殊副本。SQL Server像缓存查询计划一样缓存执行上下文。SQL Server并不优化批处理中的每条语句。它只优化那些访问表而且可能生成多个执行计划的语句。SQL Server优化所有的DML语句(SELECT、INSERT、DELETE、UPDATE)。除了DML ,一些T-SQL语句也会被优化,CREATE INDEX便是其中之一。只有被优化过的语句才会生成查询计划。
Algebrizer
由Algebrizer执行的整个过程称为绑定。
分析阶段输出的分析树,正是Algebrizer的输入。遍历几次分析树后,Algebrizer生成查询处理器树(query processor tree),用于查询优化。
运算符平展:
Algebrizer展开二元运算符UNION、AND和OR。
在分析阶段,分析器把这些逻辑运算符都看作是二元的,就像下图左侧的样子。

而分析器之后的所有步骤则会把多个二元运算符组合成一个n元运算符,像右侧所示。这对于非常长的IN列表是非常重要的,分析器会把它转换为一连串的OR运算符。此外,展开运算符还会避免在后续传递中由非常深的树所引起的大部分堆溢出问题。SQL Server内部用于执行运算符展开的代码都尽可能的使用迭代而非递归,这样Algebrizer本身就不容易出现同样的问题。
名称解析:
分析树中的每个表名称和列名称都关联到相应表或列对象的引用。表示相同对象的名称具有相同的引用。Algebrizer检查查询中的每个对象名称是否真的引用了系统目录中已经存在的有效表或列,以及是否在特定的查询范围内可见。然后,Algebrizer把目录中的信息关联到该对象的名称。
其中,对视图的名称解析使用视图树替换视图引用的过程。如果试图还引用了其他视图,他们将被递归地进行解析。
类型派生:
T-SQL中的数据类型是静态确定的,Algebrizer负责确定分析树中每个节点的类型。
聚合绑定:
首先看一个查询,T1和T2是两个表,T1有c1,c2两列,T2只有x一列。其中,T1.c2列与T2.x列具有同样的数据类型。
SELECT c1 FROM dbo.T1
GROUP BY c1
HAVING EXISTS
(SELECT * FROM dbo.T2
WHERE T2.x > MAX(T1.c2));
对于上面这个查询,SQL Server会在外层查询SELECT c1 FROM dbo.T1 GROUP BY c1时计算MAX聚合。MAX不是在内部查询中进行的吗?为什么不是在子查询中计算呢?因为每个聚合都需要绑定到他的宿主查询,这样才可以正确的计算聚合。
分组绑定:
看一个查询,T1是一个表,包含了c1、c2、c3列。
SELECT c1 + c2, MAX(c3) FROM dbo.T1 GROUP BY c1 + c2;
这个表达式是合法的,但如果只在SELECT列表中使用c1,则不合法。因为分组查询与非分组查询有不同的语义。
在SELECT列表中,所有非聚合的列或表达式,必须在GROUP BY列表中有直接的对应项。检验是否满足这一规则的过程就叫做分组绑定。
不光如此,根据SQL的规定,只要出现绑定到特定列表的聚合函数,及时没有GROUP BY或HAVING,也会使SELECT列表被分组。
看这个例子:
SELECT c1, MAX(c2) FROM dbo.T1;
这是一个分组SELECT,因为查询中包含了一个MAX聚合,所以因为SELECT中有c1,所以这个查询是不合法的。
再看一个例子:
SELECT c1,
(SELECT T2.y
FROM dbo.T2
WHERE T2.x = MAX(T1.c2))
FROM dbo.T1;
这个查询也不合法,在聚合绑定中,我们知道MAX(T1.c2)是在外部查询中计算的,所以外部查询是一个分组,所以c1在SELECT列表中是非法的。
优化
处理查询时所涉及的最重要最复杂的组件是查询优化器。优化器的任务是为批处理或存储过程中的每个查询生成高校的执行计划。
这里先请查询优化器做一个自我介绍:“我是个基于成本的优化器,我会尝试为每个SQl语句生成成本最低的执行计划,我不会分析所有可能的组合,但会尝试找出成本非常接近理论最小值的一个执行计划”。
这里,查询分析器先生所说的成本,表现为估计的完成查询所需的时间。然而,最低时间成本不一定是最低资源成本。比如,使用多个CPU处理一个查询,有时会减少时间成本,但是却增加了资源成本。
查询分析器这时作出了补充:“我主张使用并行计划,而且如果对该服务器上的负载不会产生负面影响,SQL Server会使用并行计划来执行”。
优化本身包括几个步骤。细微计划优化是第一步。这一步产生的原因,是因为查询优化器做成本优化的本身成本较高。如果SQL Server通过分析该查询发现只有一种可行的计划,他就可以避免查询优化器做成本优化时初始化和执行所需的大量工作。
比如有这样一个情况:带有VALUES子句的INSERT语句,这个插入语句的目标表不参与任何索引视图,那么就只有一个可能的计划。
再比如,执行一个对没有索引的表,进行不带GROUP BY的SELECT查询。
查询优化器生成的这个细微计划的成本很低。
如果优化器没有找到细微计划,SQL Server将进行一些简化,以寻找可以被重新整理的可交换属性和操作,说白了就是对查询语句进行语法转换的简化。
比如,在联接之前计算表的WHERE筛选器就是一个简化的例子。因为在逻辑查询顺序中[见TSQL::(1)逻辑查询处理],筛选器在联接之后计算,但在联接之前计算筛选器也可以得到正确的结果,而且是永远是更高效的,所以在简化这步会做出类似的语法优化。
再比如,看下面这个查询
USE Northwind;
SELECT
[Order Details].OrderID,
[Products].ProductName,
[Order Details].Quantity,
[Order Details].UnitPrice
FROM dbo.[Order Details]
LEFT OUTER JOIN dbo.Products
ON [Order Details].ProductID = Products.ProductID
WHERE Products.UnitPrice > 10;
这个加红的LEFT OUTER,会被简化为INNER,原因大家应该都知道。
下图是简化后的执行计划:
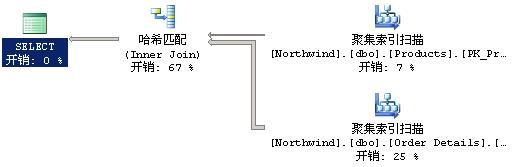
SQL Server做完了简化之后,查询优化器开始启动基于成本的优化过程。
通常,正确的结果都是相同的,但是有些不相同的结果也被认为是正确的。如:
SELECT TOP (10) <select_list> FROM Orders;
如果优化器比较所有可用计划的成本并选择成本最低的一个,优化过程会花费非常长的时间,因为可用的计划数量可能非常大。因此,优化被分成三个搜索阶段。
每个阶段关联一组转换规则。每个阶段之后,SQL Server会得到这个阶段成本最低的查询计划。当在某一个阶段的成本足够低,SQL Server将不再进行下一步的优化,而采用这个满足要求的计划。
阶段0:应用于至少包括4个表的查询。只使用有限的联接顺序数量,只考虑Hash联接和嵌套循环。如果找到成本低于0.2的计划,优化即结束。阶段0产生查询计划的查询通常出现在事务处理应用程序中,所以这个阶段也叫做事务处理阶段。
阶段1(非并行):快速计划优化。他使用更多的转换规则并尝试不同的联接顺序。该阶段完成后,如果最佳计划的成本低于1.0,则优化结束。
阶段1(并行):将再次执行阶段1的并行版本。当阶段1的两个版本都执行之后,将会比较两个版本的最佳计划,然后进入完全优化阶段。
阶段2:完全优化阶段。阶段2包括额外的规则,如:使用Outer Join重新排序并用索引视图自动替换多表视图。
总结以上的步骤,可以画出SQL Server查询优化的流程图:

SQL Server 2005中可以使用DMV(动态管理视图)sys.dm_exec_query_optimizer_info。这个视图提供了从SQL Server启动以来执行的所有优化的累积信息。
使用如下代码进行查询:
SET NOCOUNT ON;
USE Northwind; -- 这里使用你自己的数据库
DBCC FREEPROCCACHE; -- 清空过程缓存
GO
-- 我们将用tempdb..OptStats 表来捕获执行几次
-- sys.dm_exec_query_optimizer_info所得到的信息
IF (OBJECT_ID('tempdb..OptStats') IS NOT NULL)
DROP TABLE tempdb..OptStats;
GO
-- 这条语句用于创建临时表tempdb..OptStats
SELECT 0 AS Run, *
INTO tempdb..OptStats
FROM sys.dm_exec_query_optimizer_info;
GO
-- 该语句的计划将被保存到过程缓存
-- 这样当下一次执行时不产生任何优化器事件
-- 后面的GO用于确保下次执行这段脚本时
-- 可以重用INSERT的计划
GO
INSERT INTO tempdb..OptStats
SELECT 1 AS Run, *
FROM sys.dm_exec_query_optimizer_info;
GO
-- 原因同上,只是用"2"替换"1"
-- 这样我们将得到不同的计划
GO
INSERT INTO tempdb..OptStats
SELECT 2 AS RUN, *
FROM sys.dm_exec_query_optimizer_info;
-- 清空临时表
TRUNCATE TABLE tempdb..OptStats
GO
-- 存储“运行前的”信息
-- 把sys.dm_exec_query_optimizer_info的输出
-- 保存到临时表,RUn列的值为"1"
GO
INSERT INTO tempdb..OptStats
SELECT 1 AS Run, *
FROM sys.dm_exec_query_optimizer_info;
GO
-- 在这里执行你自己的语句或批处理
-- 下面是一个示例
SELECT C.CustomerID, COUNT(O.OrderID) AS NumOrders
FROM dbo.Customers AS C
LEFT OUTER JOIN dbo.Orders AS O
ON C.CustomerID = O.CustomerID
WHERE C.City = 'London'
GROUP BY C.CustomerID
HAVING COUNT(O.OrderID) > 5
ORDER BY NumOrders;
-- 示例结束
GO
-- 存储“运行后的”信息,
-- 把sys.dm_exec_query_optimizer_info的输出
-- 保存到临时表,Run列的值为"2"
GO
INSERT INTO tempdb..OptStats
SELECT 2 AS Run, *
FROM sys.dm_exec_query_optimizer_info;
GO
-- 从临时表中提取出Runs1和Runs2之间
-- OCCURRENCE 或Value值发生变化的所有事件
-- 然后显示执行批处理或查询之前(Run1Occourence和Run1Value)
-- 和之后所有这些事件(Run2Occurrence和Run2Value)
-- 的Occurrence和Value。
WITH X (Run, Counter, Occurrence, Value)
AS
(
SELECT *
FROM tempdb..OptStats WHERE Run=1
),
Y (Run, Counter, Occurrence, Value)
AS
(
SELECT *
FROM tempdb..OptStats
WHERE Run=2
)
SELECT X.Counter, Y.Occurrence-X.Occurrence AS Occurrenc,
CASE (Y.Occurrence-X.Occurrence)
WHEN 0 THEN (Y.Value*Y.Occurrence-x.Value*x.Occurrence)
ELSE (Y.Value*Y.Occurrence-X.Value*X.Occurrence)/(Y.Occurrence-x.Occurrence)
END AS Value
FROM X JOIN Y
ON (X.Counter=Y.Counter
AND (X.Occurrence<>Y.Occurrence OR x.Value<>Y.Value));
GO
-- 删除临时表
DROP TABLE tempdb..OptStats;
GO
执行结果:
