ARM64架构题目答案
1.A64指令集支持64位宽的数据和地址寻址,为什么指令的编码宽度只有32位
答:遵循简单源于规整的原则。
2.下面几条mov指令,哪些能成功,哪些会失败
mov x0, 0x1234
mov x0, 0x1abcd
mov x0, 0x12bc0000
mov x0, 0xffff0000ffff答:armv8体系结构中 mov指令有三种模式:
-
inverted wide immediate
别名为MOVN 将一个立即数左移16/32/48位放入寄存器,通常此指令用于移动位掩码,假设想要将位掩码0xFFFF_FFFF_0000_FFFF移至x0,然后将0xffff移至左侧16位,但是如果取反该值,0xFFFF_FFFF_0000_FFFFF,
例如:
MOVN x0, 0XFFFF, lsl 16 //x0值为0xFFFF_FFFF_0000_FFFFF
-
wide immediate
别名为MOVZ,将立即数(16位)移至寄存器,并且该立即数之外的其他位均设置为0,。可以将立即数向左移0/16/32/48位
-
bitmask immediate
别名为orr(immediate),
所以根据以上三个规则,第二条指令有问题mov x0, 0x1abcd,其他均正常。
3.在下面的示例代码中,X0和X1寄存器的值分别是多少
string1:
.string "Booting at EL"
ldr x0, string1
ldr x1, =string1x0为string1字符串的前8个字节
x1表示string1的地址
4.在下面示例代码中,X0寄存器的值是多少
mov x1, #3
mov x2, #1
sbc x0, x1, x2sbc为带进位的减法指令,指令格式:sub
所以x0 = 1
5.检查数据array[0, index-1]是否越界需要判断两个条件,一是输入值是否大于等于index,二是输入值是否小于0。如下两条指令来实现数组边界检查的功能,其中X0为数组的边界index,X1为输入值input。请解释这两条指令为什么能实现数组越界检查。
subs xzr, x1, x0
b.hs OutofIndexsubs是带进位的减法,x0为数组边界index,x1为输入值input, x1 - x0 => input - index
上边界:b.hs 判断条件是 大于等于 即 input >= index则会出现OutoIndex。
下边界:b.hs还有一个条件是Carry标志位1,input -> 0 => x0 -> 0, input应该是大于0的才对,如果input小于0,进位标志位会被置位。所有跳转OutofIndex
6.在下面的汇编宏中,第2行预编译后的指令是?
.macro kernel_ventry, el, label
b el\()\el\()_\label
.endm\() 表示连接前后的字符,\表示解析宏参数
7.关于链接器,请解释:链接地址、虚拟地址以及加载地址。当一个程序的代码段的链接地址与加载地址不一致时,我们应该怎么做才能让程序正确运行?
链接地址:在编译链接时指定的地址,编程人员设想将来程序要运行的地址。
虚拟地址:对于每个进程来说都是认为自己用于所有的地址空间,这个地址空间就是虚拟地址。
加载地址:代码存储的物理地址。
一开始程序运行在加载地址上,想要程序运行在链接地址上,必须要经过重定位。
8.在ARM64处理器中,异常发生后CPU自动做了哪些事情?软件需要做哪些事情?异常返回时,它是返回到发生异常的指令还是下一条指令?什么是中断现场?对于ARM64处理器来说,中断现场应该保存哪些内容?中断现场保存到什么地方?
-
异常发生:
异常发生后CPU做的事:
-
PSTATE保存到SPSR_ELx
-
返回地址保存ELR_ELx
-
PSTATE寄存器的DAIF域都设置为1,相当于把调试异常、系统错误(SError)、IRQ中断以及FIQ中断都关闭了。
-
更新了ESR_ELx寄存器,里面包含了同步异常发生的原因。
-
SP指向SP_ELx。
-
切换到对应的EL,然后跳转到异常向量表里执行。
软件做的事:
根据异常发生的类型,跳转到合适的异常向量表,异常向量表的每个表项会保存一个异常处理的跳转函数,然后跳转到恰当的异常处理函数并处理异常。
2. 异常返回:
-
操作系统执行一条eret语句。
-
从ELR_ELx寄存器中恢复PC指针。
-
从SPSR_ELx寄存器恢复处理器的状态。
-
-
异常返回地址
-
返回地址
-
x30: 子函数的返回地址。使用ret指令来返回。
-
ELR_ELx:异常返回地址。使用eret指令来返回。
-
-
ELR_ELx寄存器保存了异常返回地址
-
对于异步异常,它的返回地址是中断发生时的下一条指令,或者没有执行的第一条指令。
-
对于不是system call的同步异常,返回的是触发同步异常的那一条指令。
-
对于system call,它是返回svc指令的下一条指令。
-
-

3.中断现场
保存被中断进程的寄存器和cpu状态
4.ARM64中断现场保存的内容
保存x0-x29寄存器、ELR_EL1(PC)、SPSR_EL1(pstate)、如果中断发生在EL0,还会保存sp_el0(sp),如果中断发生在EL1则把当前栈的sp保存起来。其他寄存器还要保存。
5.中断现场保存的地方。
保存在被中断进程的内核栈上。
注意:当中断发生在用户空间时,用户空间的栈指针sp_el0保存起来的,在中断退出时,又重新取出来赋值给sp_el0的,所以在内核空间中sp_el0寄存器是没有被使用的。
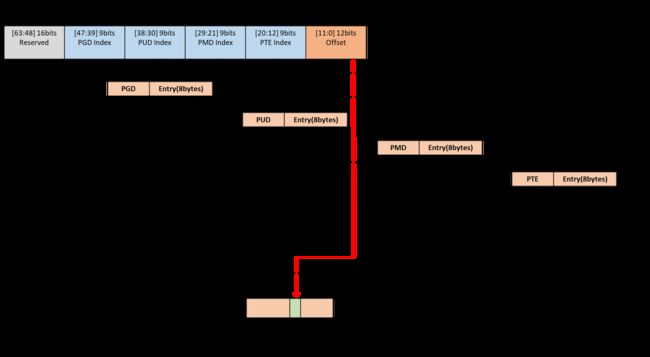
9.为什么页表要设计成多级页表?直接使用一级页表是否可行?多级页表又引入了什么问题?请简述ARM64处理器的四级页表的映射过程,假设页表粒度为4KB,地址宽度为48位。
1.多级页面和一级页表:
现代操作系统都是多进程的系统,并且每个进程都有自己的页表,如果计算机的内存是4GB,每个页的粒度为4KB,采用1级页表,要访问整个4G页面,需要1,048,576个页表项,每个页表项如何占用4字节内存,则会需要4MB的内存,操作系统中有成百上千的进程,这样每个进程都要用4MB的内存来管理页面,实在是浪费内存。
2.多级页表引入了什么问题?
不清楚
3.ARM64处理器4级页表
10.ARMv8架构处理器主要提供两种类型的内存属性,分别是普通类型(normal memory)内存和设备类型(device memory)内存,它们之间有什么区别?
-
普通内存:普通内存是弱一致性的(weakly ordered),没有其他额外的约束,提供最高的内存访问性能。
-
设备内存:处理器访问设备内存会有很多限制,比如不能进行预测访问等。设备内存是严格按照指令顺序来执行的,ARMv8架构定义了多种设备内存的属性。
-
Device-nGnRnE:不支持聚合操作,不支持指令重排,不支持提前写应答。
-
Device-nGnRE:不支持聚合操作,不支持指令重排,支持提前写应答。
-
Device-nGRE:不支持聚合操作,支持指令重排,支持提前写应答。
-
Device-GRE:支持聚合操作,支持指令重排,支持提前写应答。
-
11.在打开MMU时,为什么需要建立恒等映射?
因为指令已经在流水线中,如果没有建立恒等映射,执行重定位的话,在流水线中的指令将会执行失败。
12.请简述直接映射,全映射以及组相联映射的高速缓存的区别。什么是高速缓存的重名问题?什么是高速缓存的同名问题?VIPT类型的高速缓存会产生重名问题吗?
-
直接映射:
根据每个组(set)的高速缓存行数,cache可以分成不同的类。当每个组只有一个行cache line时,称为直接映射高速缓存。

如上图,用一个简单小巧的cache来说明,这个cache只有4行cache line,每行有4个字(word,一个字是4个Byte),总共64Byte。这个cache控制器可以使用两个比特位(bits[3:2])来选择cache line中的字,以及使用另外两个比特位(bits[5:4])作为索引(Index),选择4个cache line中的一个,其余的比特位用于标记值(Tag).
当这个cache中查询,当索引域和标记域的值和查询的地址相等,并且有效位显示这个cache line包含有效的数据时,则发生cache命中,那么可以使用偏移域来寻址cache line中的数据。如果cache line包含有效数据,但是标记域是其他地址的值,那么这个cache line需要被替换。因此,在这个cache中,主存储器中所有bit[5:4]相同值的地址都会映射到同一个cache line中(根据cache line的个数,将内存进行了分组,索引字段相同的是一组,然后每次这组中的一个内存block存储在这个cache中),并且同一时刻只有一个cache line,因为cache line被频繁换入换出,会导致严重的cache颠簸(cache thrashing)。
-
组相联(set associative):
为了解决直接映射高速缓存中的cache颠簸问题,组相联的cache结构在现代处理器中得到广泛应用。
以下是一个组相联示意图

- cache地址编码:处理器访问cache时的地址编码,分成了3个部分,分别是偏移域(offset)、索引域(Index)和标记域(Tag)。
-
Cache Line: cache中最小的访问单元,包含一小段主存储器中的数据,常见的cache line大小是32Byte或64Byte等。
-
索引域(index): cache地址编码的一部分,用于索引和查找是在cache中的哪一行。
-
组(Set):相同索引域(index)的cache line组成一个组。
-
路(Way): 在组相连的cache中,cache被分成大小相同的几个块。
-
标记(Tag): cache地址编码的一部分,用于判断cache line存放的数据是否和处理器想要的一致。
-
偏移量(offset): 查看在cache line中某个部分
-
cache查找过程:
根据index取出每组中的cache line,然后比较取出的每个tag是否是我们需要的,如果某一个cache line是我们需要的,使用offset查找对应的字节。
-
什么是高速缓存同名问题
多个cache组映射到同一个物理地址上。
-
VIPT类型的高速缓存会产生重名问题吗?
采用VIPT方式也有可能导致高速缓存重名问题。在VIPT中,使用虚拟地址的索引域来查找cache组,这时有可能导致多个cache组映射到同一个物理地址上。 它是以4KB大小为一个页面进行管理的,那么对于一个页来说,虚拟地址和物理地址的低12bit(bit(11:0))是一样的。因此,不同的虚拟地址映射到同一个物理地址,这些虚拟地址页面的低12位是一样的。如果索引域位于bit[11:0]范围内,那么就不会发生高速缓存别名。例如,cache line是32Byte,那么数据域偏移offset使用5bit,有128个cache组,那么索引域使用7bit,这种情况下刚好不会发生别名。
13.在ARM64处理器中,什么是内部共享和外部共享的高速缓存?什么是PoU和PoC
-
内部共享:inner attributes 通常是CPU IP集成的caches
-
外部共享:exported on the bus
-
PoU(Point of Unification) 统一的点:表示一个cpu中的指令cache、数据cache还有MMU、TLB等看到的是同一份的内存拷贝。
-
PoU for a PE: 是保证PE看到的I/D cache和MMU是同一份拷贝。大多数情况下,PoU是站在单核系统的角度来观察的。
-
PoU for inner share: 意思是说在inner share里面的所有PE都能看到相同的一份拷贝。
-
-
PoC(Point of Coherency)一致性的点:系统中所有观察者,例如DSP,GPU,CPU,DMA等都能看到同一份内存拷贝。
14.假设系统中4个CPU,每个CPU都有各自的一级高速缓存,处理器内部实现的是MESI协议,它们都想访问相同地址A,大小为64字节,这4个CPU的高速缓存在初始状态下没有缓存数据A。在T0时刻,CPU0访问数据A。在T1时刻,CPU1访问数据A。在T2时刻,CPU2访问数据A。在T3时刻,CPU3想更新数据A的内容。请依次说明,T0-T3时刻,4个CPU中高速缓存行的变化情况。
| T |
C0U0 |
CPU1 |
CPU2 |
CPU3 |
| T0(CPU0读A) |
E |
I |
I |
I |
| T1(CPU1读A) |
S |
S |
I |
I |
| T2(CPU2读A) | S |
S |
S |
I |
| T3(CPU3写A) |
I |
I |
I |
M |
15.DMA和高速缓存容易产生缓存一致性问题。
-
从DMA缓冲器(内存)到设备FIFO搬运数据时,应该如何保证缓存一致性?
-
使用原子操作操作设备FIFO寄存器,例如voliate,外设内存一般是写直通
-
-
从设备FIFO到DMA缓冲区(内存)搬运数据时,应该如何保证缓存一致性?
-
加上写内存屏障,保证cache中的数据写入了内存。
-
16.为什么操作系统在切换(或修改)页表时需要先刷新对应的TLB表项然后再切换页表项?
因为TLB表项缓存的是虚拟地址到物理地址的对应关系,在操作系统修改了切换或者修改了页表后虚拟地址和物理地址的对应关系就发生了变化,如果不刷新TLB表项,将导致获取的物理地址可能是旧的物理地址或者不是切换后进程的对应物理地址。
17.下面是一个无效指令高速缓存的代码片段,请解释为什么在无效指令高速缓存之后要发送一个IPI中断,而且这个IPI中断的回调函数还是空的。
void flush_icache_range(unsigned long start, unsigned long end)
{
flush_icache_range(start, end);
smp_call_function(do_nothing, NULL, 1);
}https://mp.weixin.qq.com/s/PM7EJYHP7PutHBkJ4oCQ9g
18.假设在下面的执行序列中:
CPU0先执行了a=1和b=1,接着CPU1一直循环判断b是否等于1,如果等于1则跳出while循环,最后循环"assert(a==1)"语句来判断a是否等于1
那么assert语句有可能会失败吗?

可能会失败,
修改方法:
CPU0 CPU1
{
A = 1; {
smp_wmb(); while(b == 0) continue;
b = 1; smp_rmb();
} assert(a == 1);
}
19.假设CPU0使用ldrxb/stxrb指令对0x341B0地址进行独占访问操作,CPU1也使用ldrxb/stxrb指令对0x341B4地址进行独占读操作,CPU1能成功独占访问吗?
可以独占。
20.假设函数调用关系为main()->func1()->func2(),请画出ARM64架构的函数栈的布局。
unsigned long func2(unsigned long f2)
{
unsigned long i2 = 2;
f2 += i2;
return f2;
}
unsigned long func1(unsigned long f1)
{
unsigned long i1 = 1;
f1 += i1;
f1 = func2(f1);
return f1;
}
int main()
{
unsigned long m = func1(0);
return m;
}汇编:
000000000000071c :
71c: d10083ff sub sp, sp, #0x20
720: f90007e0 str x0, [sp, #8]
724: d2800040 mov x0, #0x2 // #2
728: f9000fe0 str x0, [sp, #24]
72c: f94007e1 ldr x1, [sp, #8]
730: f9400fe0 ldr x0, [sp, #24]
734: 8b000020 add x0, x1, x0
738: f90007e0 str x0, [sp, #8]
73c: f94007e0 ldr x0, [sp, #8]
740: 910083ff add sp, sp, #0x20
744: d65f03c0 ret
0000000000000748 :
748: a9bd7bfd stp x29, x30, [sp, #-48]!
74c: 910003fd mov x29, sp
750: f9000fe0 str x0, [sp, #24]
754: d2800020 mov x0, #0x1 // #1
758: f90017e0 str x0, [sp, #40]
75c: f9400fe1 ldr x1, [sp, #24]
760: f94017e0 ldr x0, [sp, #40]
764: 8b000020 add x0, x1, x0
768: f9000fe0 str x0, [sp, #24]
76c: f9400fe0 ldr x0, [sp, #24]
770: 97ffffeb bl 71c
774: f9000fe0 str x0, [sp, #24]
778: f9400fe0 ldr x0, [sp, #24]
77c: a8c37bfd ldp x29, x30, [sp], #48
780: d65f03c0 ret
0000000000000784 :
784: a9be7bfd stp x29, x30, [sp, #-32]!
788: 910003fd mov x29, sp
78c: d2800000 mov x0, #0x0 // #0
790: 97ffffee bl 748
794: f9000fe0 str x0, [sp, #24]
798: f9400fe0 ldr x0, [sp, #24]
79c: a8c27bfd ldp x29, x30, [sp], #32
7a0: d65f03c0 ret
7a4: d503201f nop 