Hadoop3.0大数据处理学习1(Haddop介绍、部署、Hive部署)
Hadoop3.0快速入门
学习步骤:
- 三大组件的基本理论和实际操作
- Hadoop3的使用,实际开发流程
- 结合具体问题,提供排查思路
开发技术栈:
- Linux基础操作、Sehll脚本基础
- JavaSE、Idea操作
- MySQL
Hadoop简介
Hadoop是一个适合海量数据存储与计算的平台。是基于Google的GoogleFS、Map Reduce、BigTable实现的。
分布式存储介绍


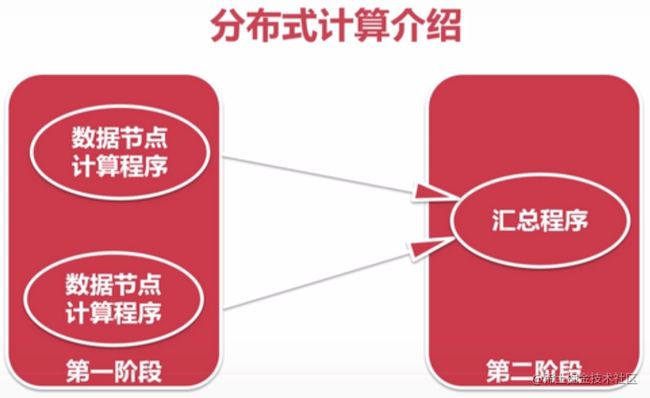
分布式计算介绍
- 移动数据:数据 -> 计算程序
- 移动计算:计算程序 -> 数据
- 分布式计算:各个节点局部计算 -> 第二阶段汇总程序
Hadoop三大核心组件

HDFS(分布式存储系统)
架构分析:
- HDFS负责海量数据的分布式存储。
- 支持主从架构,主节点支持多个NameNode,从节点支持多个DataNode。
- NameNode负责接收用户请求,维护目录系统的目录结构。DataNode主要负责存储数据。
MapReduce(分布式计算框架)
架构分析:
- MapReduce是一个编程模型,主要负责海量数据计算,主要由两个阶段组成:Map和Reduce。
- Map阶段是一个独立的程序,会在很多个节点上同时执行,每个节点处理一部分数据。
- Reduce节点也是一个独立的程序,在这先把Reduce理解为一个单独的聚合程序即可。
Yarn(资源管理与调度)
架构分析:
- 主要负责集权资源的管理和调度,支持主从架构,主节点最多可以有2个,从节点可以有多个。
- 主节点(ResourceManager)进程主要负责集群资源的分配和管理。
- 从节点(NodeManager)主要负责单节点资源管理。
大数据生态圈

Hadoop安装部署
Hadoop发行版介绍
- 官方版本:Apache Hadoop,开源,集群安装维护比较麻烦
- 第三方发行版:Cloudera Hadoop(CDH),商业收费,使用Cloudera Manager安装维护比较方便
- 第三方发行版:HortonWorks(HDP),开源,使用Ambari安装维护比较方便。
伪分布式集群安装部署(使用1台Linux虚拟机安装伪分布式集群)
1. 静态IP设置
192.168.56.101
2. 主机名设置(临时、永久)
cent7-1
3. hosts文件修改(配置IP与主机名映射关系)
cent7-1 localhost
4. 关闭防火墙(临时、永久)
systemctl status firewalld.service
systemctl stop firewalld
systemctl status firewalld.service
5. ssh免密登录
ssh-keygen -t rsa
cd /root
cd .ssh/
cat id_rsa
cat id_rsa.pub >> authorized_keys
ssh cent7-1
6. JDK1.8安装
tar -zxvf jdk-8u191-linux-x64.tar.gz
vi /etc/profile
source /etc/profile
# profile配置内容
export JAVA_HOME=/home/jdk8
export PATH=.:$JAVA_HOME/bin:$PATH
7. Hadoop伪分布式安装
# 解压Hadoop
tar -zxvf hadoop-3.2.4.tar.gz
# 进入配置文件目录
cd /home/hadoop-3.2.4/etc/hadoop
vi core-site.xml
vi hdfs-site.xml
- 配置core-site.xml
<property>
<name>fs.defaultFSname>
<value>hdfs://cent7-1:9000value>
<final>truefinal>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/home/hadoop_repovalue>
property>
- 配置hdfs-site.xml
<property>
<name>dfs.replicationname>
<value>1value>
property>
- 配置hdfs-site.xml
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
- 配置yarn-site.xml
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.nodemanager.env-whitelistname>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOMEvalue>
property>
- 配置 hadoop-env.sh
export JAVA_HOME=/home/jdk8
export HADOOP_LOG_DIR=/home/hadoop_repo/logs/hadoop
- 初始化hdfs
# 在Hadoop的目录下执行以下命令,
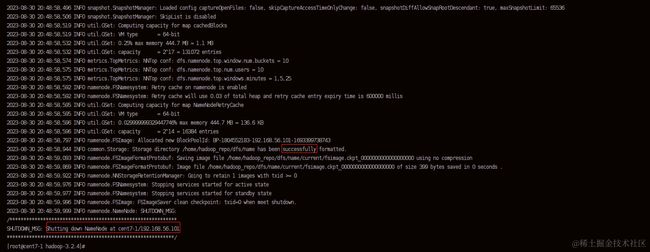
bin/hdfs namenode -format
看到以下内容说明执行成功!注意:hdfs格式化只能执行一次,如果失败需要删除文件夹后再进行格式化。
启动
[root@cent7-1 hadoop-3.2.4]# sbin/start-all.sh
Starting namenodes on [cent7-1]
ERROR: Attempting to operate on hdfs namenode as root
ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation.
Starting datanodes
ERROR: Attempting to operate on hdfs datanode as root
ERROR: but there is no HDFS_DATANODE_USER defined. Aborting operation.
Starting secondary namenodes [cent7-1]
ERROR: Attempting to operate on hdfs secondarynamenode as root
ERROR: but there is no HDFS_SECONDARYNAMENODE_USER defined. Aborting operation.
Starting resourcemanager
ERROR: Attempting to operate on yarn resourcemanager as root
ERROR: but there is no YARN_RESOURCEMANAGER_USER defined. Aborting operation.
Starting nodemanagers
ERROR: Attempting to operate on yarn nodemanager as root
ERROR: but there is no YARN_NODEMANAGER_USER defined. Aborting operation.
# 提示缺少hdfs、yarn的用户信息
- 配置start-dfs.sh、stop-dfs.sh
vi sbin/start-dfs.sh
vi sbin/stop-dfs.sh
#增加配置
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
- 配置
vi sbin/start-yarn.sh
vi sbin/stop-yarn.sh
#增加配置
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
- 再次启动
[root@cent7-1 hadoop-3.2.4]# sbin/start-all.sh
WARNING: HADOOP_SECURE_DN_USER has been replaced by HDFS_DATANODE_SECURE_USER. Using value of HADOOP_SECURE_DN_USER.
Starting namenodes on [cent7-1]
上一次登录:三 8月 30 19:05:12 CST 2023从 192.168.56.1pts/1 上
Starting datanodes
上一次登录:三 8月 30 21:02:51 CST 2023pts/0 上
localhost: Warning: Permanently added 'localhost' (ECDSA) to the list of known hosts.
Starting secondary namenodes [cent7-1]
上一次登录:三 8月 30 21:02:56 CST 2023pts/0 上
Starting resourcemanager
上一次登录:三 8月 30 21:03:49 CST 2023从 192.168.56.1pts/3 上
Starting nodemanagers
上一次登录:三 8月 30 21:04:13 CST 2023pts/0 上
[root@cent7-1 hadoop-3.2.4]# jps
10146 NameNode
10386 DataNode
10883 SecondaryNameNode
11833 ResourceManager
12954 Jps
12155 NodeManager
# 展示除了jps外的五个Hadoop组件进程表示启动成功
- 浏览器确认启动成功
- 访问HDFS:http://192.168.56.101:9870/
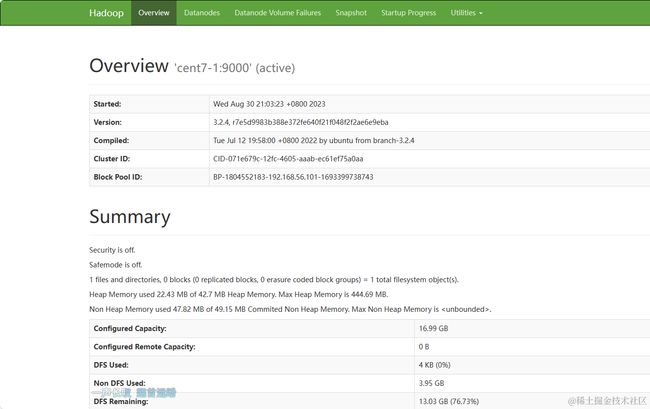
- 访问Hadoop:http://192.168.56.101:8088/

- 访问HDFS:http://192.168.56.101:9870/
停止
sbin/stop-all.sh
分布式集群安装部署(使用3台Linux虚拟机安装分布式集群)
客户端节点安装介绍
HIVE安装部署
mysql安装部署
yum install mysql
hive下载与部署
apache-hive-hive-3.1.3安装包下载_开源镜像站-阿里云 (aliyun.com)
source /etc/profile
export HIVE_HOME=/home/hive
export PATH=$HIVE_HOME/bin:$PATH
配置hive/conf/hive-site.xml文件
<configuration>
<property>
<name>javax.jdo.option.ConnectionURLname>
<value>jdbc:mysql://cent7-1:3306/hive?createDatabaseIfNotExist=true&useSSL=falsevalue>
property>
<property>
<name>javax.jdo.option.ConnectionDriverNamename>
<value>com.mysql.jdbc.Drivervalue>
property>
<property>
<name>javax.jdo.option.ConnectionUserNamename>
<value>hdpvalue>
property>
<property>
<name>javax.jdo.option.ConnectionPasswordname>
<value>adminvalue>
property>
<property>
<name>hive.server2.authenticationname>
<value>CUSTOMvalue>
property>
<property>
<name>hive.server2.custom.authentication.classname>
<value>com.ylw.CustomHiveServer2Authvalue>
property>
<property>
<name>hive.server2.custom.authentication.filename>
<value>/home/hive/user.pwd.confvalue>
property>
<property>
<name>hive.jdbc_passwd.auth.rootname>
<value>adminvalue>
property>
<property>
<name>hive.metastore.portname>
<value>9083value>
<description>Hive metastore listener portdescription>
property>
<property>
<name>hive.server2.thrift.portname>
<value>10000value>
<description>Port number of HiveServer2 Thrift interface when hive.server2.transport.mode is 'binary'.description>
property>
<property>
<name>hive.server2.thrift.max.worker.threadsname>
<value>200value>
property>
<property>
<name>hive.metastore.localname>
<value>falsevalue>
<description>controls whether to connect to remote metastore server or open a new metastore server in Hive Client JVMdescription>
property>
<property>
<name>hive.server2.transport.modename>
<value>binaryvalue>
<description>
Expects one of [binary, http].
Transport mode of HiveServer2.
description>
property>
configuration>
启动与停止hive
nohup hive --server metastore &
nohup hive --service hiveserver2 &
jps
#看到是否有两个runJar ,如果有说明启动成功
# 查看端口占用
netstat -anop |grep 10000
ps -aux|grep hive