ElasticSearch分页查询缓慢问题记录
ES 分页查询缓慢或全量查询慢问题
背景
前段时间因为数据量越来越大,导致数据库的查询压力越来越大。所以决定将数据刷入到ES中进行查询,以提高查询速度。想法是好的,测试环境也没有仔细测。心想ES查询总不会慢了。再慢能慢到哪里去。放心大胆的上了生产环境,结果给我好好的上了一课。
因为有全量查询数据的业务,而在我们自己封装的包里只有封装好的分页查询方法。按写SQL的思维形式来想,既然封装好的ES的基础包中没有全量查询数据的方式,那就分页查询呗,直到全部查询完毕。应该也不会太慢。再慢能慢过数据库吗?
一旦喜欢上谁就别无所求,只要每天能见到他就已经觉得很庆幸,一辈子很短,如白驹过隙,转瞬即逝。可这种心情很长,如高山大川,绵延不绝。 ——《武林外传》
发现问题
就在上线之后的第二天。突然有人反馈说用到了全量查询的业务特别的慢。创建好的任务要两三个小时以后才执行。而在此之前,这个任务最多也就是5分钟也开始执行了,我先是心头一紧,心想完了,难道是做了个负优化。难道查询ES 真没有数据库快吗?是不是网络问题?是不是查询语句我写的有问题影响效率了?
定位问题
带着关键字去生产上查了日志。先查到的是一个查询语句的日志。看到以后吃惊了。语句之大,五六屏放不下。吃惊之后就想,会不会是这个查询条件放的太多了?导致查询速率瞬间下降。一方面反思查询的时候不应该这么查询,代码不能这么写。一方面将查询语句拿出来,放到ES Head 里面查一下,看看到底有多慢。
查了以后,结果还是很出乎我的意料的。尽管条件贼老长,可是ES不愧是ES,还是匹配的很快。200ms左右。这结果让我瞬间麻爪,不知该如何继续了。可是日志里面打印的确实是两三分钟之后才返回了查询结果。
突然没了方向。那就先查查ES如何来实现分页或者全量数据的查询。通过 这篇文章 查到了三种方式:
- from size 查询方式
- scroll 深分页查询
- searchAfter 深分页查询
三种方式简单来说一下区别:
| 分页方式 | 特性 |
|---|---|
| from size 查询 | 适合小数据量的情况(10000-50000的数据左右)越往后时间越长,性能越差 |
| scroll 查询 | 能解决深分页问题,但是生成了数据快照,比较耗费资源。由于快照,不支持增量数据查询,不支持跳页 |
| searchAfter查询 | 能解决深分页问题,且能实时反应增删的数据,不支持跳页,数据需要有唯一的标识 |
你是藏在云层里的月亮,也是我穷极一生寻找的宝藏
三种方式的区别大致如此,详细一些,上面的文章 或者 这篇文章 写的还是蛮详细的。
看到这里已经看到了实现方式以及区别,接下来就是看包里封装的分页查询逻辑是如何实现的。
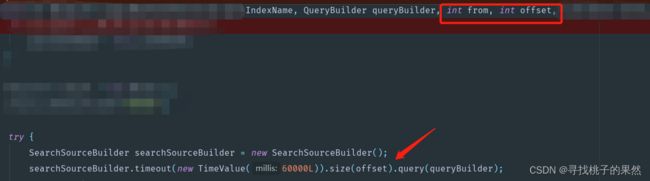
从图中可以看到,参数中的from参数 并没有使用,查询的时候只是设置了 offset参数。那猜测一下,应该是用了 第一种 from size 的查询方式 不过默认from 应该设置了0。这样看的话,选择了性能最差的一种,确实是慢的应该了。继续往下看,

如果有searchAfter 那么,会使用searchAfter查询。否则使用了Scroll查询。看来使用from size 方式 的同时就已经在为scroll方式打基础了。那么我们传入的from参数 是什么时候使用的呢?

继续读代码,发现逻辑是,如果第一次 使用 from size 方式 查询的数据满足偏移量,那么就直接返回,否则使用scroll方式继续查询,直到满足条件为止。
也许是不懂想要的爱,才会一再受到伤害。也许是背负很多次失败,才能妥善的窥见未来。那些被心酸辜负劫走的小幸福,希望他还能认识路,早点回来
破案了
通过上面的分析来看,虽然包里封装的确实是,能通过分页查询到我们需要的数据,但是再来看一下我调用的地方:

为了查询到全部的数据,我是每次查询5000条,然后通过第一次返回的总数,来计算总共要查询多少次,接着就是循环修改 页码并且调用包封装好的方法。结果可想而知,慢的原因就出来了。
- 当我查询第二页的时候,由于第一页的数据已经不满足了,也就是用from size 方式查询的数据不够了,那么就会使用scroll的方式来查询第二页。查到之后满足返回数据
- 当我查询第三页的时候,还是第一页的数据无法满足,那么会使用scroll的方式来查询第二页,第二页不是想要的,也丢弃了,则用scroll的形式查询第三页。
- 当我查询第四页的时候 …
所以时间就是这么变长的。假如说我查询第10页的数据,那么前9次的查询都是无效的,但是确实真实的查询了。而且越到后面无效查询就越多。如果我分页分了几万次,想象一下,那得浪费多少次查询。根本就是指数级的增长浪费。这么来看ES没有挂掉已经是万幸了。
你像风来了又走,我心满了又空。—《半生缘》
解决办法
既然找到了问题所在,那就是打开的方式不对了。所以不能直接使用这样的分页方法。既然想获取全量的数据,那就要么直接使用scroll的方式查询,要么直接使用searchAfter的形式查询。经过上面的对比,我决定使用searchAfter的方式来实现全量数据查询。因为这个看起来性能更好一些。
当使用searchAfter的时候,就不需要传递from属性了,只需要传入偏移量。这样当达到偏移量的时候,返回对应偏移量的ID
if (offset == curHit) {
searchAfterStr = myGson.toJson(hit.getSortValues());
result.setSearchAfter(searchAfterStr);
break;
}
使用searchAftere需要注意的点:
- 查询的数据要有唯一的主键,如果没有业务主键,用ES自己生成的主键也可以。
- 查询的时候要指定排序规则
- 不支持跳页查询
- 查询要返回最后一条记录的排序字段的值
- 下次查询的searchAfter 要带上上次查到的最后一条记录的排序字段的值
示例:(示例并非是我的代码,是从 此文章 复制而来)
TermQueryBuilder queryBuilder = QueryBuilders.termQuery("age", 24);
Object[] objects= new Object[]{"14"};
//第二次请求,携带sort字段的值进行查询。
SearchRequest searchRequest = new SearchRequest();
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(queryBuilder).sort("id",SortOrder.ASC).searchAfter(objects);
searchSourceBuilder.from(0).size(3);
searchRequest.source(searchSourceBuilder);
SearchResponse search = client.search(searchRequest, RequestOptions.DEFAULT);
写在最后
遇到生产问题还是要一步一步的排查。其实最难的是在定位问题,找到问题所在,问题也就自然有了解决的办法。 最后一句话:一般离奇的问题,都是由于小的问题导致的
你知道什么东西最灿烂吗?是你的笑容。
参考文章
- ES(elasticsearch) - 三种姿势进行分页查询
- java实现es的search after查询(三种方式详解)
- ElasticSearch分页search_after和scroll的区别以及用法
- elasticsearch restHighLevelClient 游标查询全量数据示例
- Elasticsearch Search Scroll API 查询全量数据