概述 - Linux内存管理(一)
内存管理是从单板上电运行uboot启动引导linux并完成文件系统挂载(文件系统管理Nandflash)过程前两个环节都需要完成的重要工作,并且随着程序推进的内存管理也逐渐完善起来。如果一步到位直接编写一个非常完整的内存管理系统,这个过程是相当麻烦且低效的。u-boot做为启动引导程序,其核心功能就是引导内核镜像,所以其内存管理功能并不用像Linux内核中的内存管理一样功能齐全。u-boot中没有内存分配、回收、缓存等功能,内存管理其实只做一件事:虚实地址映射,而且是固定映射。 linux内核中的内存管理支持内存地址映射、内存分配、内存回收、内存碎片管理、页面缓存等众多功能。为实现内核上层的这些功能,linux到目前共有bootmem、memblock、buddy system三种内存管理模型。其中bootmem与memblock是在内存启动阶段使用,buddy system在系统运行过程中使用。
在系统初始化阶段会先启用一个bootmem分配器和memblock分配器,此分配器是专门用于启动阶段的,一个bootmem分配器管理着一个node结点的所有内存,也就是在numa架构中多个node有多个bootmem,他们被链入bdata_list链表中保存。而伙伴系统的初始化就是将bootmem管理的所有物理页框释放到伙伴系统中去,本章的主要是分析下,如何实现bootmem到buddy的过度的整个流程。需要注意一点,从u-boot过度到linux内核初期,使用__create_page_tables创建最简单的一个物理地址到虚拟地址的映射,并在这个基础之上完成bootmem或者memblock的初始化工作。
u-boot内存管理文章:U-Boot内存管理_生活需要深度的博客-CSDN博客。
1. bootmem
bootmem是启动时物理内存的分配器和配置器,在还没有构建完整的页分配机制(page allocator)之前,可以用来实现简单的内存分配和释放操作,之后完整的内存管理系统也是基于bootmem构建的。bootmem是基于首次适应的分配器,它的本质是位图(bitmap),一个比特位代表一个页框,如果比特位置1则表示该页被分配出去了;反之,如果置0表示该页空闲。Linux内核直接管理的内存是1G,所以这个位图需要2^32/4096/8=128KB。
2. memblock
那么,既然已经有了bootmem机制为什么还需要memblock机制呢?那是因为bootmem机制还存在很多问题。bootmem的主要缺点是位图的初始化。要创建这个位图,就必须要了解物理内存配置。位图的正确大小是多少?哪个存储库具有足够的连续物理内存来存储位图?当然,随着内存大小的增加,bootmem位图也随之增加。对于具有32GB的RAM系统来说,位图将需要1MB的内存。而memblock可以被立即使用因为基于静态数组足够大,至少可以容纳最初的内存注册和分配。如果一个添加或者保留更多内存的请求会使得memblock数组溢出,则该数组的大小将增加一倍。有一个基本的假设,即到这种情况发生的时候,足够的内存将添加到内存块中,来维持新数组的分配。
所以目前为了减轻从bootmem到memblock过度的痛苦,引入了一个名为nobootmem的兼容层。nobootmem提供(大多数)与bootmem相同的接口,但是它不是使用位图标记繁忙页面的,而是依靠内存块保留。从v4.17开始,在24种架构中,只有5种仍使用bootmem作为唯一的早期内存分配器。14种将memblock与nobootmem一起使用。其余5种同时使用memblock和bootmem。
3. buddy system
但众所周知,Linux内存管理的核心是伙伴系统(buddy system)。其实在linux启动的那一刻,内存管理就已经开始了,只不过不是buddy在管理。在buddy system系统建立基本的内存管理,内存管理在模型基础之上进行不同类型分配器的适配。常见的分配器:
- 连续物理内存管理buddy allocator
- 非连续物理内存管理vmalloc allocator
- 小块物理内存管理slab allocator
- 高端物理内存管理kmapper

内存管理子系统的职能:
1、虚拟内存地址与物理内存地址之间的映射
2、物理内存的分配
地址映射管理 模型图:
若系统为32位系统,则对应的虚拟内存的大小为4G
地址映射管理包括两部分:
1、虚拟内存空间分布
2、虚拟地址转化为物理地址
虚拟内存的空间分布:
(地址:0G-3G)用户空间,运行应用程序
(地址:3G-4G)内核空间
内核空间包括:
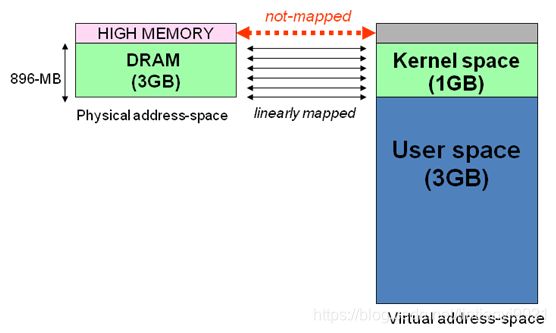
1、3G – 3G+896MB 直接映射区
2、vmalloc区
3、永久映射区
4、固定映射区
虚拟地址转化为物理地址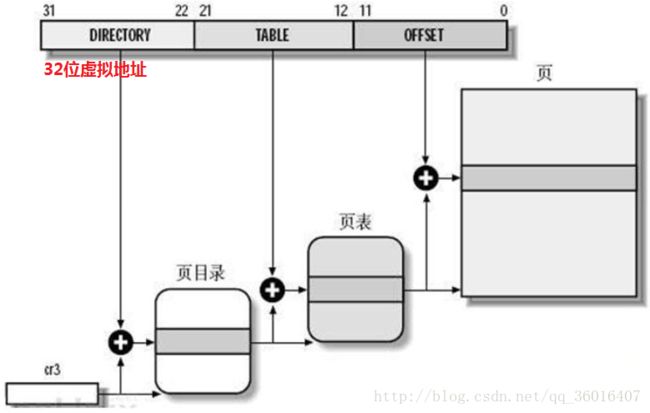
上面讲到的用户空间的四个部分在映射到物理地址时有一定的区别:
1、直接映射区:物理内存中896M以下的位置称为低端内存,以上的区域称为高端内存,在直接映射区中,若虚拟地址为:3G+128,则物理地址就是128。直接映射区虚拟地址=3G+物理地址。
2、vmalloc区:即可访问低端物理地址,也可访问高端地址,没有线性的映射特性。
3、永久映射区:固定用来访问高端物理内存区域。
4、固定映射区:与特殊的寄存器建立映射关系。
物理内存的分配
Linux使用虚拟内存,因此程序中分配的都是虚拟地址,只有访问虚拟地址时,才会为其分配物理内存。
当获取到虚拟地址时,并不会为其分配物理内存。
当调用malloc函数时,只是分配了一个虚拟地址,当向其中写入数据时才会分配物理内存。

当使用 kmalloc 函数时,不仅为其分配虚拟地址,同时还会为其分配物理内存地址。
3. 分段还是分页
分段还是分页要划分内存,我们就要先确定划分的单位是按段还是按页,就像你划分土地要选择按亩还是按平方分割一样。其实分段与分页的优缺点,前面 MMU 相关的课程已经介绍过了。这里我们从内存管理角度,理一理分段与分页的问题。第一点,从表示方式和状态确定角度考虑。段的长度大小不一,用什么数据结构表示一个段,如何确定一个段已经分配还是空闲呢?而页的大小固定,我们只需用位图就能表示页的分配与释放。比方说,位图中第 1 位为 1,表示第一个页已经分配;位图中第 2 位为 0,表示第二个页是空闲,每个页的开始地址和大小都是固定的。第二点,从内存碎片的利用看,由于段的长度大小不一,更容易产生内存碎片,例如内存中有 A 段(内存地址:0~5000)、 B 段(内存地址:5001~8000)、C 段(内存地址:8001~9000),这时释放了 B 段,然后需要给 D 段分配内存空间,且 D 段长度为 5000。你立马就会发现 A 段和 C 段之间的空间(B 段)不能满足,只能从 C 段之后的内存空间开始分配,随着程序运行,这些情况会越来越多。段与段之间存在着不大不小的空闲空间,内存总的空闲空间很多,但是放不下一个新段。而页的大小固定,分配最小单位是页,页也会产生碎片,比如我需要请求分配 4 个页,但在内存中从第 1~3 个页是空闲的,第 4 个页是分配出去了,第 5 个页是空闲的。这种情况下,我们通过修改页表的方式,就能让连续的虚拟页面映射到非连续的物理页面。第三点,从内存和硬盘的数据交换效率考虑,当内存不足时,操作系统希望把内存中的一部分数据写回硬盘,来释放内存。这就涉及到内存和硬盘交换数据,交换单位是段还是页?如果是段的话,其大小不一,A 段有 50MB,B 段有 1KB,A、B 段写回硬盘的时间也不同,有的段需要时间长,有的段需要时间短,硬盘的空间分配也会有上面第二点同样的问题,这样会导致系统性能抖动。如果每次交换一个页,则没有这些问题。还有最后一点,段最大的问题是使得虚拟内存地址空间,难于实施。(后面的课还会展开讲)综上,我们自然选择分页模式来管理内存,其实现在所有的商用操作系统都使用了分页模式管理内存。我们用 4KB 作为页大小,这也正好对应 x86 CPU 长模式下 MMU 4KB 的分页方式。如何表示一个页我们使用分页模型来管理内存。首先是把物理内存空间分成 4KB 大小页
一、 简介
-
Linux操作系统和驱动程序运行在内核空间,应用程序运行在用户空间。两者不能简单地使用指针传递数据,因为Linux使用的虚拟内存机制,用户空间的数据可能被换出,当内核空间使用用户空间指针时,对应的数据可能不在内存中。用户空间的内存映射采用段页式,而内核空间有自己的规则;本文旨在探讨内核空间的地址映射。
-
os分配给每个进程一个独立的、连续的、虚拟内存空间。该大小一般是4G(32位操作系统,即2的32次方),其中将高地址值的内存空间分配给os占用,linux os占用1G,window os占用2G;其余内存地址空间分配给进程使用。
-
通常32位Linux内核虚拟地址空间划分0~3G为用户空间,3~4G为内核空间(注意,内核可以使用的线性地址只有1G)。注意这里是32位内核地址空间划分,64位内核地址空间划分是不同的。

- 进程寻址空间0~4G
- 进程在用户态只能访问0~3G,只有进入内核态才能访问3G~4G
- 每个进程虚拟空间的3G~4G部分是相同的
- 进程从用户态进入内核态不会引起CR3的改变但会引起堆栈的改变
ZONE_DMA:范围是0 ~ 16M,该区域的物理页面专门供I/O设备的DMA使用。之所以需要单独管理DMA的物理页面,是因为DMA使用物理地址访问内存,不经过MMU,并且需要连续的缓冲区,所以为了能够提供物理上连续的缓冲区,必须从物理地址空间专门划分一段区域用于DMA
常见问题:
1、用户空间(进程)是否有高端内存概念?
用户进程没有高端内存概念。只有在内核空间才存在高端内存。用户进程最多只可以访问3G物理内存,而内核进程可以访问所有物理内存。
2、64位内核中有高端内存吗?
目前现实中,64位Linux内核不存在高端内存,因为64位内核可以支持超过512GB内存。若机器安装的物理内存超过内核地址空间范围,就会存在高端内存。
3、用户进程能访问多少物理内存?内核代码能访问多少物理内存?
32位系统用户进程最大可以访问3GB,内核代码可以访问所有物理内存。
64位系统用户进程最大可以访问超过512GB,内核代码可以访问所有物理内存。
4、高端内存和物理地址、逻辑地址、线性地址的关系?
高端内存只和逻辑地址有关系,和逻辑地址、物理地址没有直接关系。
5、为什么不把所有的地址空间都分配给内核?
若把所有地址空间都给内存,那么用户进程怎么使用内存?怎么保证内核使用内存和用户进程不起冲突?
二、Linux内核高端内存
1、由来
当内核模块代码或线程访问内存时,代码中的内存地址都为逻辑地址,而对应到真正的物理内存地址,需要地址一对一的映射,如逻辑地址0xC0000003对应的物理地址为0x00000003,0xC0000004对应的物理地址为0x00000004,… …,逻辑地址与物理地址对应的关系为
物理地址 = 逻辑地址 – 0xC0000000:这是内核地址空间的地址转换关系,注意内核的虚拟地址在“高端”,但是它映射的物理内存地址在低端。
| 逻辑地址 | 物理地址 |
|---|---|
| 0xc0000000 | 0x00000000 |
| 0xc0000001 | 0x00000001 |
| 0xc0000002 | 0x00000002 |
| … | … |
| 0xe0000000 | 0x20000000 |
| … | … |
| 0xffffffff | 0x40000000 |
假设按照上述简单的地址映射关系,那么内核逻辑地址空间访问为0xc0000000 ~ 0xffffffff,那么对应的物理内存范围就为0x00000000 ~ 0x40000000,即只能访问1G物理内存。若机器中安装8G物理内存,那么内核就只能访问前1G物理内存,后面7G物理内存将会无法访问,因为内核 的地址空间已经全部映射到物理内存地址范围0x00000000 ~ 0x40000000。即使安装了8G物理内存,那么物理地址为0×40000001的内存,内核该怎么去访问呢?代码中必须要有内存逻辑地址 的,0xc0000000 ~ 0xffffffff的地址空间已经被用完了,所以无法访问物理地址0x40000000以后的内存。
显然不能将内核地址空间0xc0000000 ~ 0xfffffff全部用来简单的地址映射。因此x86架构中将内核地址空间划分三部分:
- ZONE_DMA
- ZONE_NORMAL
- ZONE_HIGHMEM
ZONE_HIGHMEM即为高端内存,这就是内存高端内存概念的由来。
在x86结构中,三种类型的区域(从3G开始计算)如下:
- ZONE_DMA 内存开始的16MB
- ZONE_NORMAL 16MB~896MB
- ZONE_HIGHMEM 896MB ~ 结束(1G)
2、理解
前 面我们解释了高端内存的由来。 Linux将内核地址空间划分为三部分ZONE_DMA、ZONE_NORMAL和ZONE_HIGHMEM,高端内存HIGH_MEM地址空间范围为 0xF8000000 ~ 0xFFFFFFFF(896MB~1024MB)。那么如内核是如何借助128MB高端内存地址空间是如何实现访问可以所有物理内存?
当内核想访问高于896MB物理地址内存时,从0xF8000000 ~ 0xFFFFFFFF地址空间范围内找一段相应大小空闲的逻辑地址空间,借用一会。借用这段逻辑地址空间,建立映射到想访问的那段物理内存(即填充内核PTE页面表),临时用一会,用完后归还。这样别人也可以借用这段地址空间访问其他物理内存,实现了使用有限的地址空间,访问所有所有物理内存。如下图。
例 如内核想访问2G开始的一段大小为1MB的物理内存,即物理地址范围为0x80000000 ~ 0x800FFFFF。访问之前先找到一段1MB大小的空闲地址空间,假设找到的空闲地址空间为0xF8700000 ~ 0xF87FFFFF,用这1MB的逻辑地址空间映射到物理地址空间0x80000000 ~ 0x800FFFFF的内存。映射关系如下:
| 逻辑地址 | 物理内存地址 |
|---|---|
| 0xF8700000 | 0x80000000 |
| 0xF8700001 | 0x80000001 |
| 0xF8700002 | 0x80000002 |
| … | … |
| 0xF87FFFFF | 0x800FFFFF |
当内核访问完0x80000000 ~ 0x800FFFFF物理内存后,就将0xF8700000 ~ 0xF87FFFFF内核线性空间释放。这样其他进程或代码也可以使用0xF8700000 ~ 0xF87FFFFF这段地址访问其他物理内存。
从上面的描述,我们可以知道高端内存的最基本思想:借一段地址空间,建立临时地址映射,用完后释放,达到这段地址空间可以循环使用,访问所有物理内存。
看到这里,不禁有人会问:万一有内核进程或模块一直占用某段逻辑地址空间不释放,怎么办?若真的出现的这种情况,则内核的高端内存地址空间越来越紧张,若都被占用不释放,则没有建立映射到物理内存都无法访问了。
3、 划分
内核将高端内存划分为3部分:
- VMALLOC_START~VMALLOC_END
- KMAP_BASE~FIXADDR_START
- FIXADDR_START~4G
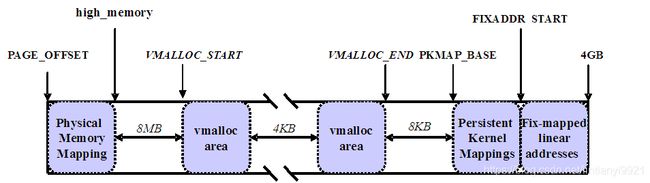 对 于高端内存,可以通过 alloc_page() 或者其它函数获得对应的 page,但是要想访问实际物理内存,还得把 page 转为线性地址才行(为什么?想想 MMU 是如何访问物理内存的),也就是说,我们需要为高端内存对应的 page 找一个线性空间,这个过程称为高端内存映射。
对 于高端内存,可以通过 alloc_page() 或者其它函数获得对应的 page,但是要想访问实际物理内存,还得把 page 转为线性地址才行(为什么?想想 MMU 是如何访问物理内存的),也就是说,我们需要为高端内存对应的 page 找一个线性空间,这个过程称为高端内存映射。
对应高端内存的3部分,高端内存映射有三种方式:
-
映射到”内核动态映射空间”(noncontiguous memory allocation)
这种方式很简单,因为通过 vmalloc() ,在”内核动态映射空间”申请内存的时候,就可能从高端内存获得页面(参看 vmalloc 的实现),因此说高端内存有可能映射到”内核动态映射空间”中。 -
持久内核映射(permanent kernel mapping)
如果是通过 alloc_page() 获得了高端内存对应的 page,如何给它找个线性空间?
内核专门为此留出一块线性空间,从 PKMAP_BASE 到 FIXADDR_START ,用于映射高端内存。在 2.6内核上,这个地址范围是 4G-8M 到 4G-4M 之间。这个空间起叫”内核永久映射空间”或者”永久内核映射空间”。这个空间和其它空间使用同样的页目录表,对于内核来说,就是 swapper_pg_dir,对普通进程来说,通过 CR3 寄存器指向。通常情况下,这个空间是 4M 大小,因此仅仅需要一个页表即可,内核通过来 pkmap_page_table 寻找这个页表。通过 kmap(),可以把一个 page 映射到这个空间来。由于这个空间是 4M 大小,最多能同时映射 1024 个 page。因此,对于不使用的的 page,及应该时从这个空间释放掉(也就是解除映射关系),通过 kunmap() ,可以把一个 page 对应的线性地址从这个空间释放出来。 -
临时映射(temporary kernel mapping)
内核在 FIXADDR_START 到 FIXADDR_TOP 之间保留了一些线性空间用于特殊需求。这个空间称为”固定映射空间”在这个空间中,有一部分用于高端内存的临时映射。
这块空间具有如下特点:
- 每个 CPU 占用一块空间
- 在每个 CPU 占用的那块空间中,又分为多个小空间,每个小空间大小是 1 个 page,每个小空间用于一个目的,这些目的定义在
kmap_types.h 中的 km_type 中。
当要进行一次临时映射的时候,需要指定映射的目的,根据映射目的,可以找到对应的小空间,然后把这个空间的地址作为映射地址。这意味着一次临时映射会导致以前的映射被覆盖。通过 kmap_atomic() 可实现临时映射。
三、 其他
1、用户空间(进程)是否有高端内存概念?
- 用户进程没有高端内存概念。只有在内核空间才存在高端内存。用户进程最多只可以访问3G物理内存,而内核进程可以访问所有物理内存。
2、64位内核中有高端内存吗?
- 目前现实中,64位Linux内核不存在高端内存,因为64位内核可以支持超过512GB内存。若机器安装的物理内存超过内核地址空间范围,就会存在高端内存。
3、用户进程能访问多少物理内存?内核代码能访问多少物理内存?
- 32位系统用户进程最大可以访问3GB,内核代码可以访问所有物理内存。
- 64位系统用户进程最大可以访问超过512GB,内核代码可以访问所有物理内存。
4、高端内存和物理地址、逻辑地址、线性地址的关系?
- 高端内存只和逻辑地址有关系,和逻辑地址、物理地址没有直接关系。
Linux 操作系统是采用段页式内存管理方式:
页式存储管理能有效地提高内存利用率(解决内存碎片),而分段存储管理能反映程序的逻辑结构并有利于段的共享。将这两种存储管理方法结合起来,就形成了段页式存储管理方式。
段页式存储管理方式即先将用户程序分成若干个段,再把每个段分成若干个页,并为每一个段赋予一个段名。在段页式系统中,为了实现从逻辑地址到物理地址的转换,系统中需要同时配置段表和页表,利用段表和页表进行从用户地址空间到物理内存空间的映射。
系统为每一个进程建立一张段表,每个分段有一张页表。段表表项中至少包括段号、页表长度和页表始址,页表表项中至少包括页号和块号。在进行地址转换时,首先通过段表查到页表始址,然后通过页表找到页帧号,最终形成物理地址。