GPT-1、GPT-2和GPT-3模型详解及其进化之路
GPT-1
模型原理与结构
OpenAI gpt模型基于Transformer的语言模型,其利用Transformer的decoder结构来进行单向语言模型的训练。GPT的核心思想是先通过无标签的文本去训练生成语言模型,再根据具体的NLP任务(如文本蕴涵、QA、文本分类等),来通过有标签的数据对模型进行fine-tuning。
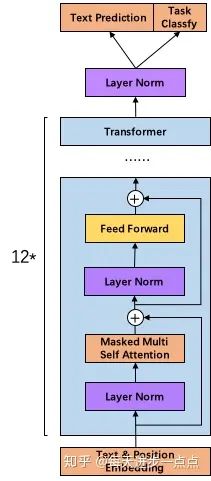
文中所用的网络结构如下:

gpt和bert的异同
基于 transformer 的编码器-解码器结构:
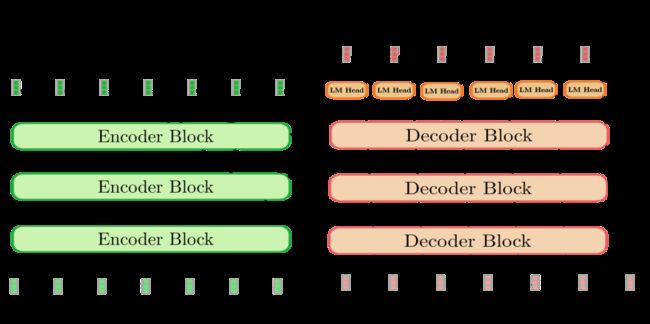
gpt和bert[深度学习:BERT模型]的虽然本质都是基于transformer[深度学习:transformer模型],思想都是先通过在无标签的数据上学习一个预训练的语言模型,然后再根据特定热任务进行微调。
gpt用的是transformer中去掉中间Encoder-Decoder Attention层的decoder(其实也可以等价地说,用到的是encoder层,只是将Multi-Head Attention换成了Masked Multi-Head Attention),即:Masked Self Attention,是单向语言模型,即给定前几个词预测下一个词,更适合自然语言生成的任务;
而bert使用的是transformer的encoder,即:Self Attention,是双向的语言模型,即给定周围上下文的词预测中间被mask的词,更适合自然语言理解的任务。
训练过程
模型的训练过程分为两步:第一步是去在大语料库上学习一个高容量的语言模型。第二步是微调过程,我们将模型应用到一个标记任务上。
1. 无监督预训练Unsupervised pre-training
第一阶段的目标是预训练语言模型,给定tokens的语料  ,目标函数为最大化似然函数:
,目标函数为最大化似然函数:

Note: 这里的 k 是文本上下文窗口的大小。
该模型中应用multi-headed self-attention,并在之后增加position-wise的前向传播层,最后输出一个分布:
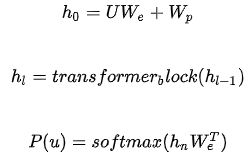
无监督训练的终止条件:通过准确率来评价训练何时停止。训练的时候生成的文本和原文本进行比对,得到准确率,通过准确率是否达到预期值或是准确率是否一直上下波动等来确定是否该停止训练。
2. 有监督微调Supervised fine-tuning
有了预训练的语言模型之后,对于有标签的训练集 C ,给定输入序列 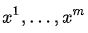 和标签 Y,可以通过语言模型得到
和标签 Y,可以通过语言模型得到  ,经过输出层后对 Y 进行预测:
,经过输出层后对 Y 进行预测:
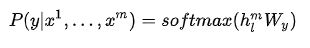
则目标函数为:
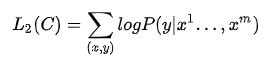
整个任务的目标函数为:
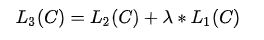
额外地发现将语言模型去作为辅助对象来参与微调可以帮助(a)提升监督模型的一般化(b)加速收敛。
Task-specific input transformation
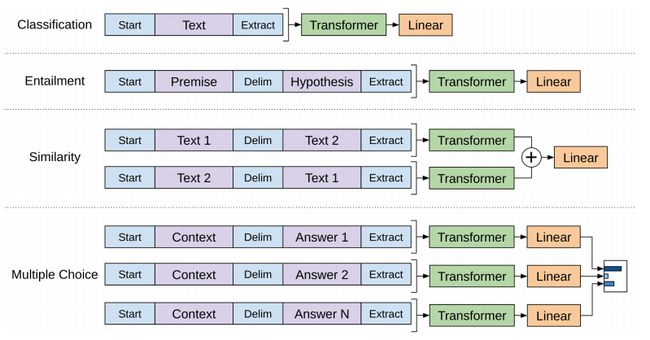
对于不同NLP任务的微调过程:
分类任务:输入就是文本,最后一个词的向量直接作为微调的输入,得到最后的分类结果(可以多分类)
推理任务:输入是 先验+分隔符+假设,最后一个词的向量直接作为微调的输入,得到最后的分类结果,即:是否成立
句子相似性:输入是 两个句子相互颠倒,得到的最后一个词的向量再相加,然后进行Linear,得到最后分类结果,即:是否相似
问答任务:输入是上下文和问题放在一起与多个回答,中间也是分隔符分隔,对于每个回答构成的句子的最后一个词的向量作为微调的输入,然后进行Linear,将多个Linear的结果进行softmax,得到最后概率最大的
训练细节
无监督的预训练使用BooksCorpus dataset,包含超过7000本来自各种类型的未出版的书籍,包括冒险、幻想和浪漫。至关重要的是,它包含了一长段连续的文本,这使得生成模型能够学习长距离信息。另一个数据集,1B Word Benchmark,大小大致相同,但是在句子层面被打乱了——破坏了长距离结构。在这个语料库中,语言模型达到了18.4的非常低的困惑度。
Model specifications:很大程度上遵循transformer的原始工作。
无监督训练
- 使用字节对编码(byte pair encoding,BPE),共有 40,000 个字节对;使用ftfy库来清理书库中的原始文本,标准化一些标点和空白,并使用spaCy标记器。
- 位置编码的长度是 3,072 ;位置编码也需要学习;序列长度为 512
- 词编码的长度为 768 ;
- 由于层归一化在整个模型中广泛使用,简单的N(0,0.02 )权重初始化就足够了。
- 12 层的transformer,每个transformer块有 12 个头;
- position-wise前馈网络使用了3072维内部状态。
- Attention, 残差,Dropout等机制用来进行正则化,drop比例为 0.1 ;
- 激活函数为GLEU;
- 还采用了[Fixing weight decay regularization in adam]中提出的L2正则化的修改版本,在所有非偏置或增益权重上w = 0.01。
- 使用Adam优化器,最大学习率为2.5e - 4,在最初的2000次更新中,学习率从零线性增加。
- 训练的batchsize为 64 ,序列epoch为 100 ;
- 模型参数数量为 1.17 亿。
有监督微调
- 无监督部分的模型也会用来微调;
- Fine-tuning details:除非指定,否则使用无监督预训练中的超参数设置。
- 训练的epoch为 3 (模型快速微调,三个epoch的训练对大多数情况都足够了),32的批处理,学习率为 6.25e−5 ,这表明模型在无监督部分学到了大量有用的特征。
- 使用线性学习率衰减时间表,训练warmup超过0.2 %。λ设定为0.5。
GPT模型优缺点
优点
1 相对rnn模型Transformer可以捕捉到更长范围的信息。
2 计算速度比循环神经网络更快,易于并行化
3 实验结果显示Transformer的效果比ELMo和LSTM网络更好。
4 GPT采用单向transformer可以解决Bert无法解决的生成文本任务。
缺点
1 对于某些类型的任务需要对输入数据的结构作调整。
2 采用无监督的预训练和有监督的微调可以实现大部分的NLP任务,而且效果显著,但是还是不如Bert的效果好。
[论文:Improving Language Understanding by Generative Pre-Training]
[pt code: https://github.com/huggingface/pytorch-openai-transformer-lm]
[tf code: https://github.com/openai/finetune-transformer-lm]
[https://github.com/karpathy/minGPT]
-柚子皮-
GPT-2
模型原理与结构
GPT-2 的核心思想就是,当模型的容量非常大且数据量足够丰富时,仅仅靠语言模型的学习便可以完成其他有监督学习的任务,不需要在下游任务微调。GPT-2依然沿用GPT-1单向transformer的模式,只不过使用了更多的网络参数和更大的数据集。
语言模型在训练时开发了一套广泛的技能和模式识别能力,然后在推理时使用这些能力快速适应或识别所需的任务。GPT-2试图通过“上下文学习In Context Learning”的方式来实现这一点,使用预训练语言模型的文本输入作为任务规范的一种形式:模型以自然语言指令和/或几个任务演示为条件,然后预期仅通过预测接下来会发生什么来完成更多的任务实例。
综上,与GPT-1核心区别lz认为应该是in context learning,其次是网络参数和更大的数据集。
模型结构上的改变
1. GPT-2去掉了fine-tuning层:不再针对不同任务分别进行微调建模,而是不定义这个模型应该做什么任务,模型会自动识别出来需要做什么任务。fine-tuning去掉后,引入大量的训练文本,效果就非常好,这也说明只要训练文本够大,网络够大,模型是可以自己根据输入内容判断需要做的任务是什么的。当然GPT-2的输入也会加入提示词,比如:“TL;DR:”,GPT-2模型就会知道是做摘要工作了,是不是有点prompt-learning/In Context Learning的感觉了。
作者认为,当一个语言模型的容量足够大时,它就足以覆盖所有的有监督任务,也就是说所有的有监督学习都是无监督语言模型的一个子集。例如当模型训练完“Micheal Jordan is the best basketball player in the history”语料的语言模型之后,便也学会了(question:“who is the best basketball player in the history ?”,answer:“Micheal Jordan”)的Q&A任务。GPT-2的核心思想概括为:任何有监督任务都是语言模型的一个子集,当模型的容量非常大且数据量足够丰富时,仅仅靠训练语言模型的学习便可以完成其他有监督学习的任务。
2. 调整transformer:将layer normalization放到每个sub-block之前 [即为了降低训练难度将post-norm改成了pre-norm:LLM:大模型的正则化],并在最后一个Self-attention后再增加一个layer normalization。
训练细节
GPT-2主推zero-shot,而GPT-1为pre-train+fine-tuning;
GPT-2的数据集
GPT-2的文章取自于Reddit上高赞的文章,命名为WebText。数据集共有约800万篇文章,累计体积约40G。为了避免和测试集的冲突,WebText移除了涉及Wikipedia的文章。
模型参数
- 同样使用了使用字节对编码构建字典,但字典大小增加为 50,257 ;
- 滑动窗口的大小增加为 1,024 ;
- batchsize的大小增加为 512 ;
- 将残差层的初始化值用 1/sqrt(N)进行缩放,其中 N 是残差层的个数。
- 增加网络参数:将Transformer堆叠层数增加到48层,隐层的维度增至1600,参数量达15亿。
GPT-2的评价和性能
- 在8个语言模型任务中,仅仅通过zero-shot学习,GPT-2就有7个超过了state-of-the-art的方法;
- 在“Children's Book Test”数据集上的命名实体识别任务中,GPT-2超过了state-of-the-art的方法约7%;
- “LAMBADA”是测试模型捕捉长期依赖的能力的数据集,GPT-2将困惑度从99.8降到了8.6;
- 在阅读理解数据中,GPT-2超过了4个baseline模型中的三个;
- 在法译英任务中,GPT-2在zero-shot学习的基础上,超过了大多数的无监督方法,但是比有监督的state-of-the-art模型要差;
- GPT-2在文本总结的表现不理想,但是它的效果也和有监督的模型非常接近。
[gpt-2详细图解The Illustrated GPT-2 (Visualizing Transformer Language Models)]
[论文:Language Models are Unsupervised Multitask Learners]
[代码:openai/gpt-2]
[GPT2-Chinese: Chinese version of GPT2 training code, using BERT tokenizer.]
GPT-3
模型原理
最近的研究表明,在 pretrain+finetune 模型中,当模型适应了下游任务的训练集后,往往会失去对下游任务的 OOD(out-of-distribution)泛化能力,这种能力也被称为Zero-shot能力。由于训练集不可能涵盖整个真实分布,而且预测数据的分布也随时间变化而变化,因此模型需要具备 OOD 的能力。通过构建 OOD 测试集,并与 IID(Independent Identically Distribution 指训练集和测试集是同分布但是互相独立)上的表现进行比较,进行了一些实验研究:1. 传统 NN 衰减很大,甚至只有 30%,而 PTM(pre-training model) 衰减很小;2. 更大 size 的 PTM,并不一定表现更好;3. PTM 使用的训练数据的规模越大、多样性越强,表现越好,这点在ChatGPT的训练集构建中也体现出来了。
从理论上讲GPT-3也是支持fine-tuning的,但是fine-tuning需要利用海量的标注数据进行训练才能获得比较好的效果,但是这样也会造成对其它未训练过的任务上表现差,所以GPT-3并没有尝试fine-tuning。(所以后续模型就换成了Instruction-tuning来做差不多的事情了)
关于GPT-3中的In-context learning[3.1 In-context learning]
GPT-3仅仅需要zero-shot或者few-shot,就可以在下游任务表现的非常。这些强大的能力依赖于疯狂的 1,750 亿的参数量, 45 TB的训练数据以及高达 1,200 万美元的训练费用。
模型结构
模型结构上,GPT3和GPT-1 GPT-2的区别主要在于使用了稀疏的自注意力,具体叫局部带状稀疏注意力locally banded sparse attention[ Generating Long Sequences with Sparse Transformers]。
[为节约而生:从标准Attention到稀疏Attention]
sparse attention
sparse attention 与传统 self-attention(称为 dense attention) 的区别在于:
dense attention:每个 token 之间两两计算 attention,复杂度 O(n²)。 sparse attention:每个 token 只与其他 token 的一个子集计算 attention,复杂度 O(n*logn)。
具体来说,sparse attention 除了相对距离不超过 k 以及相对距离为 k,2k,3k,... 的 token,其他所有 token 的注意力都设为 0,如下图所示:
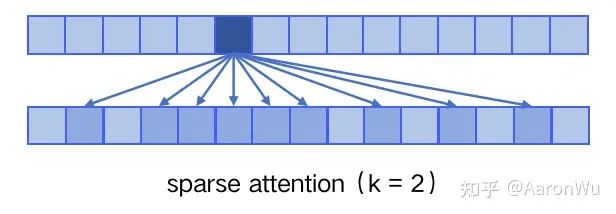
使用 sparse attention 的好处:1. 减少注意力层的计算复杂度,节约显存和耗时,从而能够处理更长的输入序列;2. 具有“局部紧密相关和远程稀疏相关”的特性,对于距离较近的上下文关注更多,对于距离较远的上下文关注较少。但是批判性的角度来讲,肯定是有缺点的,NLP语言中内容都是有上下文关系的,如此依赖必定会对长文本建模的效果变差。
GPT-3的预训练方法(包括模型、数据和训练过程)类似于GPT-2,但是扩大了模型大小、数据集大小和多样性以及训练长度。上下文学习方法也类似于GPT-2,但系统地探索了不同的上下文学习设置。
GPT-3在网络容量上的提升:
- GPT-3采用了 96 层的多头transformer,头的个数为 96 ;
- 词向量的长度是 12,888 ;
- 上下文划窗的窗口大小提升至 2,048 个token;
训练细节
1750亿的参数,31个分工明确的作者,超强算力的计算机( 285,000 个CPU, 10,000 个GPU),1200万的训练费用,45TB的训练数据(维基百科的全部数据只相当于其中的 0.6% )。
模型参数

数据集
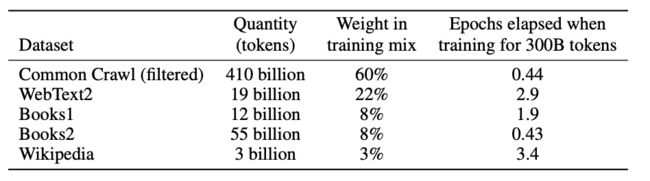
GPT-3的训练数据包括低质量的(近万亿个单词的)Common Crawl(从2016年到2019年的41个月的CommonCrawl分片中下载的,压缩后的纯文本大小为45TB,过滤后为570GB,相当于大约4000亿个字节对编码的token),高质量的WebText2,两个基于互联网的书籍语料库Books1、Books2和英文维基百科Wikipedia。GPT-3根据数据集的不同的质量赋予了不同的权值,权值越高的在训练的时候越容易抽样到。
其中未经过滤的Common Crawl版本质量较低,因此采取了三个步骤提高数据集质量:1. 使用高质量数据作为正例,训练LR分类算法,对 CommonCrawl 的所有文档做初步过滤;2. 利用公开的算法做文档去重,减少冗余数据;
性能评估
测试上下文学习能力
GPT-3的体量非常庞大,因此在下游任务中进行fine-tune的成本很高。为了解决这个问题,GPT-3使用了“In-Context Learning”的方式,在不进行梯度更新或fine-tune的情况下,直接在上下文中进行学习。

具体来说,在二十多个NLP数据集以及几个设计用来测试快速适应不太可能直接包含在训练集中的任务的新任务上评估GPT-3。对于每个任务,在以下3种条件下评估GPT-3:
- 少样本学习(few-shot learning),即上下文学习,允许尽可能多的演示适应模型的上下文窗口(通常为10到100);
- 单样本学习(one-shot learning),只允许一个演示;
- 零样本学习(zero-shot learning),不允许演示,只给模型提供自然语言指令。
其中 Few-shot 也被称为 in-context learning,虽然它与 fine-tuning 一样都需要一些有监督标注数据,但是两者的区别是:1. fine-tuning 基于标注数据对模型参数进行更新,而 in-context learning 使用标注数据时不做任何的梯度回传,模型参数不更新;2. in-context learning 依赖的数据量(10~100)远远小于 fine-tuning 一般的数据量。
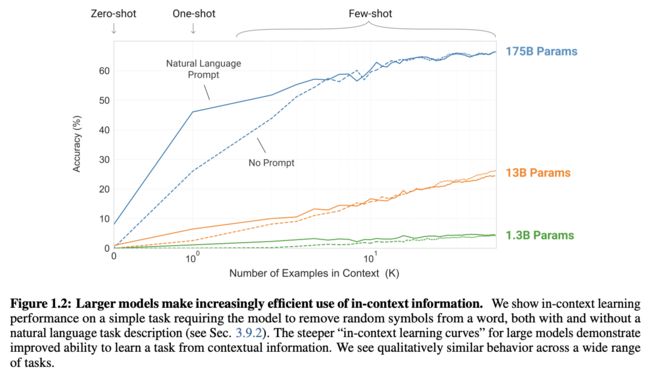
这张图显示了随着测试案例数量的增加,模型大小对最终效果的影响。虚线代表没有使用Prompt(自然语言描述)。可以看到,模型越大,测试案例数量越多,最终效果越好。当测试案例很多时,Prompt变得不那么重要,因为从案例中也可以推断出任务类型。大型模型的更陡峭的“上下文学习曲线”表明从上下文信息中学习任务的能力有所提高,模型越大,上下文信息的使用效率就越高。
总体来看,在所有三种情况下,对于大多数任务,作者发现模型容量与性能之间存在相对平滑的关系;一个值得注意的模式是,零样本、单样本和少样本的性能差距通常随着模型容量的增加而增大,这可能表明更大的模型更擅长元学习。
具体测试结果参考原论文或者[结果]。
评价
作者讨论了GPT-3在few-shot learning上存在的一些局限性和挑战,包括以下几个方面:
- 在文本合成和NLP任务方面取得了显著改进,但仍有缺陷。它的样本有时会重复语义,失去连贯性,自相矛盾,并偶尔包含非续句或段落。它在“常识物理”方面也有困难。
- 在需要双向性能的任务上表现较差,如填空、比较内容片段和生成简短答案等任务。
- 大型预训练语言模型没有在其他领域(如视频或现实世界物理交互)中建立基础,因此缺少大量关于世界的背景。由于所有这些原因,纯粹自我监督预测的扩展可能会达到极限,并且需要使用不同方法进行增强。在这方面有前途的未来方向可能包括从人类那里学习目标函数、用强化学习进行微调或添加其他模式(如图像)以提供基础并更好地建模世界。
- 预训练期间的样本效率较低。改进预训练样本效率是未来工作的重要方向,可能来自于在物理世界中进行基础以提供额外信息,或者来自算法改进。
- 与GPT-3中的少样本学习相关的一个局限性或不确定性是关于少量样本学习是否在推理时“从头”学习新任务,还是仅仅识别并确定它在训练期间学到的任务。
- 在推理时既昂贵又不方便,这可能会给模型在当前形式下的实际应用带来挑战。一种可能的未来方向是将大型模型通过蒸馏缩小到特定任务可管理的大小。
- 决策不容易解释,在对新输入的预测中不一定很好地校准,因为在标准基准测试中观察到的性能方差比人类高得多,并且它保留了训练数据中的偏见。
缺点:
- 对于一些命题没有意义的问题,GPT-3不会判断命题有效与否,而是拟合一个没有意义的答案出来;
- 由于40TB海量数据的存在,很难保证GPT-3生成的文章不包含一些非常敏感的内容,例如种族歧视,性别歧视,宗教偏见等;
- 受限于transformer的建模能力,GPT-3并不能保证生成的一篇长文章或者一本书籍的连贯性,存在下文不停重复上文的问题。
[论文:Language Models are Few-Shot Learners]
from: -柚子皮-
ref: [OpenAI · GitHub]