Paddle 模型转 TensorRT加速模型
Paddle 模型转 TensorRT加速模型
概述
NVIDIA TensorRT 是一个高性能的深度学习预测库,可为深度学习推理应用程序提供低延迟和高吞吐量。PaddlePaddle 采用子图的形式对TensorRT进行了集成,即我们可以使用该模块来提升Paddle模型的预测性能。在这篇文章中,我们会介绍如何使用Paddle-TRT子图加速预测。
当模型加载后,神经网络可以表示为由变量和运算节点组成的计算图。如果我们打开TRT子图模式,在图分析阶段,Paddle会对模型图进行分析同时发现图中可以使用TensorRT优化的子图,并使用TensorRT节点替换它们。在模型的推断期间,如果遇到TensorRT节点,Paddle会调用TensorRT库对该节点进行优化,其他的节点调用Paddle的原生实现。TensorRT除了有常见的OP融合以及显存/内存优化外,还针对性的对OP进行了优化加速实现,降低预测延迟,提升推理吞吐。
目前Paddle-TRT支持静态shape模式以及/动态shape模式。在静态shape模式下支持图像分类,分割,检测模型,同时也支持Fp16, Int8的预测加速。在动态shape模式下,除了对动态shape的图像模型(FCN, Faster rcnn)支持外,同时也对NLP的Bert/Ernie模型也进行了支持。
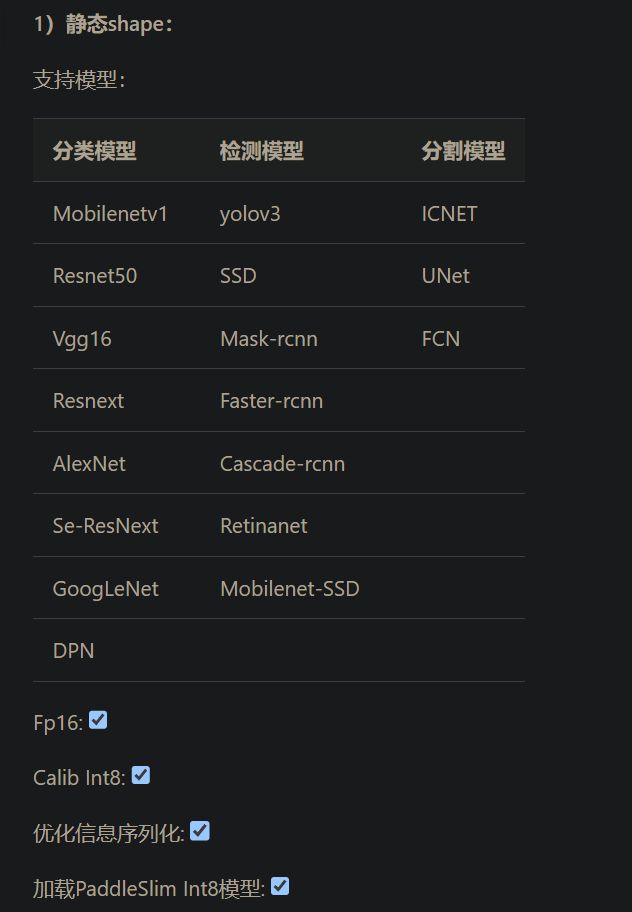
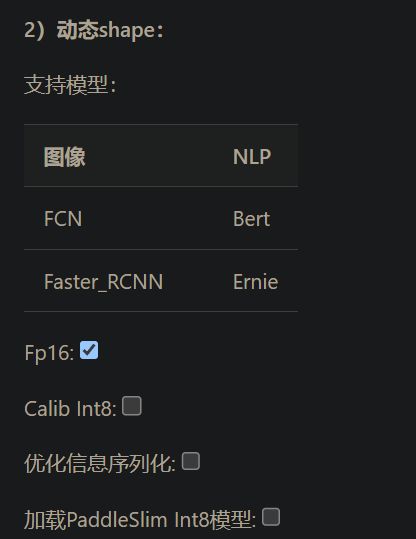
运行原理
当模型加载后,神经网络可以表示为由变量和运算节点组成的计算图。TensorRT在推断期间能够进行Op的横向和纵向融合,过滤掉冗余的Op,并对特定平台下的特定的Op选择合适的kernel等进行优化,能够加快模型的预测速度。
简单演示
转换前的网络:

转换后的网络:
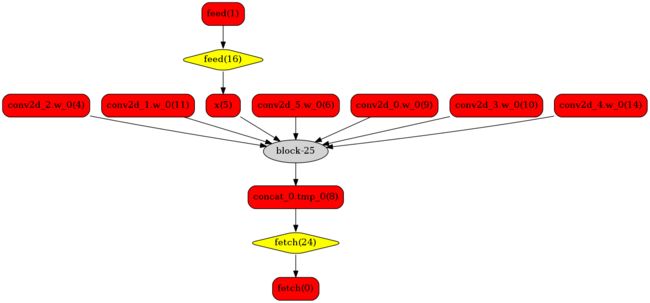
安装
完整方式
1、pip安装
略
2、使用现有的docker镜像
paddle官方提供了整套的环境,可以在docker环境中直接使用
# 拉取镜像,该镜像预装Paddle 2.2 Python环境,并包含c++的预编译库,lib存放在主目录~/ 下。
## docker pull paddlepaddle/paddle:latest-dev-cuda11.0-cudnn8-gcc82 这个版本的镜像不可用 paddle都无法使用
nvidia-docker pull registry.baidubce.com/paddlepaddle/paddle:2.4.1-gpu-cuda11.2-cudnn8.2-trt8.0
sudo nvidia-docker run --name your_name -v $PWD:/paddle --network=host -it registry.baidubce.com/paddlepaddle/paddle:2.4.1-gpu-cuda11.2-cudnn8.2-trt8.0 /bin/bash
3、手动编译
略
验证
paddle官方给了trt的paddle inference的推理demo,这里以yolov3目标检测为例
获取代码仓库
wget https://paddle-inference-dist.bj.bcebos.com/Paddle-Inference-Demo/yolov3_r50vd_dcn_270e_coco.tgz
tar xzf yolov3_r50vd_dcn_270e_coco.tgz
运行run.sh下载预测模型和图片
sh run.sh
其中:
- 文件
utils.py包含了图像的预处理等帮助函数。 - 文件
infer_yolov3.py包含了创建predictor,读取示例图片,预测,获取输出的等功能。
使用原生 GPU 运行样例
python infer_yolov3.py --model_file=yolov3_r50vd_dcn_270e_coco/model.pdmodel --params_file=yolov3_r50vd_dcn_270e_coco/model.pdiparams
使用 Trt Fp32 运行样例
python infer_yolov3.py --model_file=yolov3_r50vd_dcn_270e_coco/model.pdmodel --params_file=yolov3_r50vd_dcn_270e_coco/model.pdiparams --run_mode=trt_fp32
使用 Trt Fp16 运行样例
python infer_yolov3.py --model_file=yolov3_r50vd_dcn_270e_coco/model.pdmodel --params_file=yolov3_r50vd_dcn_270e_coco/model.pdiparams --run_mode=trt_fp16
使用 Trt Int8 运行样例
在使用 Trt In8 运行样例时,相同的运行命令需要执行两次。
生成量化校准表
python infer_yolov3.py --model_file=yolov3_r50vd_dcn_270e_coco/model.pdmodel --params_file=yolov3_r50vd_dcn_270e_coco/model.pdiparams --run_mode=trt_int8
生成校准表的log:
I0623 08:40:49.386909 107053 tensorrt_engine_op.h:159] This process is generating calibration table for Paddle TRT int8...
I0623 08:40:49.387279 107057 tensorrt_engine_op.h:352] Prepare TRT engine (Optimize model structure, Select OP kernel etc). This process may cost a lot of time.
I0623 08:41:13.784473 107053 analysis_predictor.cc:791] Wait for calib threads done.
I0623 08:41:14.419198 107053 analysis_predictor.cc:793] Generating TRT Calibration table data, this may cost a lot of time...
加载校准表执行预测
python infer_yolov3.py --model_file=yolov3_r50vd_dcn_270e_coco/model.pdmodel --params_file=yolov3_r50vd_dcn_270e_coco/model.pdiparams --run_mode=trt_int8
加载校准表预测的log:
I0623 08:40:27.217701 107040 tensorrt_subgraph_pass.cc:258] RUN Paddle TRT int8 calibration mode...
I0623 08:40:27.217834 107040 tensorrt_subgraph_pass.cc:321] Prepare TRT engine (Optimize model structure, Select OP kernel etc). This process may cost a lot of time.
使用 Trt dynamic shape 运行样例(以 Fp32 为例)
python infer_yolov3.py --model_file=yolov3_r50vd_dcn_270e_coco/model.pdmodel --params_file=yolov3_r50vd_dcn_270e_coco/model.pdiparams --run_mode=trt_fp32 --use_dynamic_shape=1
输出结果如下所示:
category id is 0.0, bbox is [216.26059 697.699 268.60815 848.7649 ]
category id is 0.0, bbox is [113.00742 614.51337 164.59525 762.8045 ]
category id is 0.0, bbox is [ 82.81181 507.96368 103.27139 565.0893 ]
category id is 0.0, bbox is [346.4539 485.327 355.62698 502.63412]
category id is 0.0, bbox is [520.77747 502.9539 532.1869 527.12494]
category id is 0.0, bbox is [ 38.75421 510.04153 53.91417 561.62244]
category id is 0.0, bbox is [ 24.630651 528.03186 36.35131 551.4408 ]
category id is 0.0, bbox is [537.8204 516.3991 551.4925 532.4528]
category id is 0.0, bbox is [176.29276 538.46545 192.09549 572.6228 ]
category id is 0.0, bbox is [1207.4629 452.27505 1214.8047 461.21774]
category id is 33.0, bbox is [593.3794 80.178375 668.2346 151.84273 ]
category id is 33.0, bbox is [467.13992 339.5424 484.5012 358.15115]
category id is 33.0, bbox is [278.30582 236.12378 304.95267 280.59497]
category id is 33.0, bbox is [1082.6643 393.12796 1099.5437 421.86935]
category id is 33.0, bbox is [302.35004 376.8052 320.6112 410.01248]
category id is 33.0, bbox is [575.6267 343.2629 601.619 369.2695]

过程中遇到的问题
1、paddle提供的部分docker镜像有问题,使用过程中最好看清楚版本号
2、使用TRT加速时需要在空闲的GPU上,在已经有人使用的GPU 上可能会无法运行
3、预测库默认是打开日志的,只要注释掉config.disable_glog_info()就可以打开日志
4、