PELT负载统计原理
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
目录
- 前言
- 一、什么是负载
- 二、算法原理
-
- 2.1 理论公式
- 2.2 关于时间
- 2.3 实际计算
- 2.4 关于衰减因子计算
- 三、code 跟踪
-
- 3.1 核心函数图示
- 3.2 核心结构
- 3.3 decay_load 计算经过n个period衰减的值
- 3.4 __compute_runnable_contrib 计算连续完整period(ps:即上述图示d2)的累加和
- 3.5 __update_load_avg
前言
负载统计算法主要有PELT和WALT,本文主要介绍PELT算法原理。
kernel3.8版本之前的内核CFS调度器在计算CPU load的时候采用的是跟踪每个运行队列上的负载(per-rq load tracking)。这种粗略的负载跟踪算法显然无法为调度算法提供足够的支撑。我们并不知道当前CPU上的负载来自哪些任务,每个任务施加多少负载,当前CPU的算力是否支撑runqueue上的所有任务,是否需要提频或者迁核来解决当前CPU上负载。为了完美的满足上面的所有需求,Linux调度器在3.8版中引入了PELT(Per-entity load tracking)算法。本文将为您分析PELT的设计概念和具体的实现。
PELT (per-entrity load tracing)负载计算特点:
(1)把CPU负载计算细化到每个调度实体(schedule entity),调度实体可以是一个task,也可以是一个task group,这样可以更加精确的进行CPU之间的负载均衡处理;
(2)根据per entity的负载值推测未来需要的CPU算力,以此作为CPU调频调压的依据,这涉及到cpufreq子系统;
(3)开发人员可以根据系统负载情况做其他子系统的优化。
优势:
1、了解每个实体的负载情况,并且知道每个CPU的负载情况,则可以推算出某一个task迁移后的情况是怎样的,即负载均衡措施更加有效;
2、small-task packing patch的目标是将“小”进程收集到系统中的部分CPU上,从而允许系统中的其他处理器进入低功耗模式,利用per-entity load tracking,内核可以知道哪些是小的进程,并将其集中到CPU上
3、可以轻松统计每个CPU的使用情况
一、什么是负载
负载实际上表示的是进程运行对系统的“压力”情况,它和进程消耗CPU时间是两个概念,比如:
10个进程在运行队列runqueue中,和1个进程在runqueue中,虽然在runquque中的进程并没有正在消耗CPU时间,实际上这两种情况下,系统的压力是不同的,此时这些进程并没有在消耗CPU时间,而是在等待,但是依然对负载产生影响。
因此
负载(task load):负载是一个瞬时量,即表示在某一个时间点,runnable状态的task对CPU造成的压力;
瞬时负载 Li = load weight *(t/1024)
CPU使用率(task utility):是一个累积量,表示一段时间内某个task占用总时间片的比例;
Ui = Max CPU capacity *(t/1024)
我们平时看的/proc/loadavg是负载,但是它是计算的一段时间的值,是个趋势变化;
跟踪任务的utility主要是为任务寻找合适算力的CPU。例如在手机平台上4个大核+4个小核的结构。一个任务本身逻辑复杂,需要有很长的执行时间,也就是说其utility比较大,那么需要将其安排到算力和任务utility匹配的CPU上,例如大核CPU上。PELT算法也会跟踪CPU上的utility,根据CPU utility选择提升或者降低该CPU的频率。CPU load和Task load主要用于负载均衡算法,即让系统中的每一个CPU承担和它的算力匹配的任务负载。
二、算法原理
2.1 理论公式
为了做到Per-entity的负载跟踪,时间被分成了1024us的序列,在每一个1024us的周期中,一个entity对系统负载的贡献可以根据该实体处于runnable状态(正在CPU上运行或者等待cpu调度运行)的时间进行计算。任务在1024us的周期窗口内的负载其实就是瞬时负载。如果在该周期内,runnable的时间是t,那么该任务的瞬时负载应该和(t/1024)有正比的关系。类似的概念,任务的瞬时利用率应该通过1024us的周期窗口内的执行时间(不包括runqueue上的等待时间)比率来计算。
当然,不同优先级的任务对系统施加的负载也不同(毕竟在cfs调度算法中,高优先级的任务在一个调度周期中会有更多的执行时间),因此计算任务负载也需要考虑任务优先级,这里引入一个负载权重(load weight)的概念。在PELT算法中,瞬时负载Li等于:
Li = load weight x (runnable time/1024)
利用率和负载不一样,它和任务优先级无关,不过为了能够和CPU算力进行运算,任务的瞬时利用率Ui使用下面的公式计算:
Ui = Max CPU capacity x (running time/1024)
在手机环境中,大核最高频上的算力定义为最高算力,即1024。瞬时运行负载的定义类似utility,如下:
RLi = Max CPU capacity x (runnable time/1024)
任务的瞬时负载和瞬时利用率都是一个快速变化的计算量,但是它们并不适合直接调整调度算法,因为调度器期望的是一段时间内保持平稳而不是疲于奔命。例如,在迁移算法中,在上一个1024us窗口中,是满窗运行,瞬时利用率是1024,立刻将任务迁移到大核,下一个窗口,任务有3/4时间在阻塞状态,利用率急速下降,调度器会将其迁移到小核上执行。从这个例子可以看出,用瞬时量来推动调度器的算法不适合,任务会不断在大核小核之间跳来跳去,迁移的开销会急剧加大。为此,我们需要对瞬时负载进行滑动平均的计算,得到平均负载。一个调度实体的平均负载可以表示为:
L = L0 + L1y + L2y2 + L3*y3 + …
Li表示在周期pi中的瞬时负载,对于过去的负载我们在计算的时候需要乘一个衰减因子y。在目前的内核代码中,y是确定值:y ^32等于0.5。这样选定的y值,一个调度实体的负荷贡献经过32个窗口(32 x 1024us)后,对当前时间的的符合贡献值会衰减一半。
通过上面的公式可以看出:
(1)调度实体对系统负荷的贡献值是一个序列之和组成
(2)过去的负荷也会被累计,但是是以递减的方式来影响负载计算。
(3)最近时间点的负荷值拥有最大的权重1,随着时间的推移,权重指数衰减
使用这样序列的好处是计算简单,我们不需要使用数组来记录过去的负荷贡献,只要把上次的总负荷的贡献值乘以y再加上新的L0负荷值就OK了。utility和runnable load的计算也是类似的,不再赘述。

通过这个公式来看,由于我们是累加各个周期中的负载贡献值,所以一个实体在一个计算周期内的负载可能会超过1024us。内核中通过这种公式计算出runnable_avg_sum和runnable_avg_period,然后两者runnable_avg_sum/runnable_avg_period可以作为对系统平均负载贡献的描述。
2.2 关于时间
| 成员 | 描述 |
|---|---|
| u64 clock | 基于sched clock的时间,通过update_rq_clock函数不断驱动这个timeline向前推进 |
| u64 clock_task | clock_task这个timeline类似上面的clock,只不过当执行irq的时候,clock_task会停掉,因此,这个clock只会随着任务的执行而不断向前推进。具体clock task更新的方法可以参考update_rq_clock_task函数 |
| u64 clock_pelt | PELT用于计算负载的timeline,这个时间是归一化后的时间(上面两个都是未归一化的物理时间)。当CPU idle的时候,clock_pelt会同步到clock_task上去。 |
对于CPU而言,算力处于比较低的水平的时候,同样的任务量要比高算力状态下花费更多的时间。这样,同样的任务量在不同CPU算力的情况下,PELT会跟踪到不同的结果。为了能达到一致性的评估效果,PELT的时间采用归一化时间,即把执行时间归一化到超大核最高频率上去。不过由于归一化,cpu idle的时间被压缩了(一般而言,归一化后的时间会小一些,实际运行时间会长一些),为了解决这个问题,pelt clock在cpu处于idle状态的时候会同步到clock task上去。
归一化的代码如下(update_rq_clock_pelt):
delta = cap_scale(delta, arch_scale_cpu_capacity(cpu_of(rq)));
delta = cap_scale(delta, arch_scale_freq_capacity(cpu_of(rq)));
rq->clock_pelt += delta;
实际的任务执行时间delta,通过cpu scale和freq scale,归一化到了系统最大算力的CPU上去。
2.3 实际计算
static inline void __update_task_entity_contrib(struct sched_entity *se)
{
u32 contrib;
/* avoid overflowing a 32-bit type w/ SCHED_LOAD_SCALE */
contrib = se->avg.runnable_avg_sum * scale_load_down(se->load.weight);
contrib /= (se->avg.runnable_avg_period + 1);
se->avg.load_avg_contrib = scale_load(contrib);
}
从代码中来看,最终代表调度实体负载的是load_avg_contrib,一个runqueue中所有进程负载贡献值相加最后就得到该runqueue的负载,也就是该CPU上的负载。从上面的代码来看,load_avg_contrib的计算,简单的来说就是通过
runnable_avg_sum * weight / (runnable_avg_period + 1)
其中
weight:是进程的权重
runnable_avg_sum:通过衰减因子计算得到的进程runnable时间
runnable_avg_period:通过衰减因子计算得到的总的period时间
从这个计算公式来看,一个进程的最大负载也不会超过该进程的权重值weight。
最大衰减累加时间:进程在CPU上运行无限长时,根据 PELT 算法计算出的衰减值。当进程无限运行后,load_avg 总是无限接近进程权重值(load.weight)
对调度实体来说:load_sum=runnable_load_sum, load_avg=runnable_load_avg。对于CFS调度队列来说:load_sum = 整个队列负载 * 整个队列权重。
实际计算时需要考虑不满足一个周期的情况,时间更新包含了几个部分,比如一个典型的时间更新问题:假如当前从last_time更新到current_time,我们需要更新对应的runnable_avg_sum和runnable_avg_period的时间值。则将整体的task running时间划分为三个阶段:d1、d2、d3
- d1 为开始运行时不足一个周期的阶段
- d2 为中间多个完整的周期
- d3 为最新的不足一个周期的阶段
则完整负载sum=d1+d2+d3,如下图:

我们需要在代码中使用算法计算出来上述3段对应的衰减时间,从而计算出current_time时间点的负载。代码如下:
static __always_inline int __update_entity_runnable_avg(u64 now,
struct sched_avg *sa,
int runnable)
{
u64 delta, periods;
u32 runnable_contrib;
int delta_w, decayed = 0;
delta = now - sa->last_runnable_update; //now距离上次更新的时间,单位ns
/*
* This should only happen when time goes backwards, which it
* unfortunately does during sched clock init when we swap over to TSC.
*/
if ((s64)delta < 0) {
sa->last_runnable_update = now;
return 0;
}
/*
* Use 1024ns as the unit of measurement since it's a reasonable
* approximation of 1us and fast to compute.
*/
delta >>= 10; //ns转换为us
if (!delta)
return 0;
sa->last_runnable_update = now;
/* delta_w is the amount already accumulated against our next period */
delta_w = sa->runnable_avg_period % 1024; //上次时间超过一个period剩余的时间,以us为单位
if (delta + delta_w >= 1024) {
/* period roll-over */
decayed = 1;
/*
* Now that we know we're crossing a period boundary, figure
* out how much from delta we need to complete the current
* period and accrue it.
*/
delta_w = 1024 - delta_w;
if (runnable)
sa->runnable_avg_sum += delta_w; //补齐操作
sa->runnable_avg_period += delta_w; //补齐操作
delta -= delta_w;
/* Figure out how many additional periods this update spans */
periods = delta / 1024;
delta %= 1024;
sa->runnable_avg_sum = decay_load(sa->runnable_avg_sum, //补齐上次剩余未满一个Period时间后,相对于现在已经属于旧周期,需要乘以衰减因子重新计算对应的衰减值
periods + 1);
sa->runnable_avg_period = decay_load(sa->runnable_avg_period, //同上
periods + 1);
/* Efficiently calculate \sum (1..n_period) 1024*y^i */
runnable_contrib = __compute_runnable_contrib(periods); //本次更新带入的多个完整Period时间计算出来的衰减值
if (runnable)
sa->runnable_avg_sum += runnable_contrib;
sa->runnable_avg_period += runnable_contrib;
}
/* Remainder of delta accrued against u_0` */
if (runnable)
sa->runnable_avg_sum += delta; //本次更新剩余未满一个Period的值,直接相加,不必做衰减,前面介绍原理时已经说了
sa->runnable_avg_period += delta;
return decayed;
}
2.4 关于衰减因子计算
在这个过程中为了减少计算耗时,将涉及次方运算的相关过程,用数组存储了起来:
1、y^32=1/2 ,提供y的n次方常数数组:
static const u32 runnable_avg_yN_inv[] __maybe_unused = {
0xffffffff, 0xfa83b2da, 0xf5257d14, 0xefe4b99a, 0xeac0c6e6, 0xe5b906e6,
0xe0ccdeeb, 0xdbfbb796, 0xd744fcc9, 0xd2a81d91, 0xce248c14, 0xc9b9bd85,
0xc5672a10, 0xc12c4cc9, 0xbd08a39e, 0xb8fbaf46, 0xb504f333, 0xb123f581,
0xad583ee9, 0xa9a15ab4, 0xa5fed6a9, 0xa2704302, 0x9ef5325f, 0x9b8d39b9,
0x9837f050, 0x94f4efa8, 0x91c3d373, 0x8ea4398a, 0x8b95c1e3, 0x88980e80,
0x85aac367, 0x82cd8698,
};
2、运行周期内,多个周期累加和使用数组存储, 1024 * (y + y^2 + … + y^n)
/*
* Precomputed \Sum y^k { 1<=k<=n }. These are floor(true_value) to prevent
* over-estimates when re-combining.
*/
static const u32 runnable_avg_yN_sum[] = {
0, 1002, 1982, 2941, 3880, 4798, 5697, 6576, 7437, 8279, 9103,
9909,10698,11470,12226,12966,13690,14398,15091,15769,16433,17082,
17718,18340,18949,19545,20128,20698,21256,21802,22336,22859,23371,
};
目前最新版本kernel采用函数__accumulate_pelt_sements()函数来计算连续一段时间内的运行时间衰减累加值,当连续时间超过345时,负载累加值达到最大值LOAD_AVG_MAX(47742)
3、以32个period累加和为基准,再次套娃:
/*
* Precomputed \Sum y^k { 1<=k<=n, where n%32=0). Values are rolled down to
* lower integers. See Documentation/scheduler/sched-avg.txt how these
* were generated:
*/
以32个周期为基准的累加和
static const u32 __accumulated_sum_N32[] = {
0, 23371, 35056, 40899, 43820, 45281,
46011, 46376, 46559, 46650, 46696, 46719,
};
三、code 跟踪
3.1 核心函数图示

3.2 核心结构
1、sched_avg
| 变量 | 说明 |
|---|---|
| last_update_time | 上一次负载更新时间。用于计算时间间隔。sched avg会定期更新,last_update_time是上次更新的时间点,结合当前的时间值,我们可以计算delta并更新*_sum和*_avg。对task se而言,还有一种特殊情况就是迁移到新的CPU,这时候需要将last_update_time设置为0以便新cpu上可以重新开始计算负载,此外,新任务的last_update_time也会设置为0。 |
| load_sum | 基于可运行(runnable)时间的负载贡献总和。runnable时间包含两部分:一是在rq中等待cpu调度运行的时间,二是正在cpu上运行的时间 |
| util_sum | 基于正在运行(running)时间的负载贡献总和。running时间是指调度实体se正在cpu上执行时间 |
| load_avg | 基于可运行(runnable)时间的平均负载贡献 |
| util_avg | 基于正在运行(running)时间的平均负载贡献 |
| period_contrib | period_contrib是一个中间计算变量,在更新负载的时候分三段,d1(合入上次更新负载的剩余时间,即不足1ms窗口的时间),d2(满窗时间),d3(不足1ms窗口的时间),period_contrib记录了d3窗口的时间,方便合入下次的d1。 |
| util_est | 任务阻塞后,其负载会不断衰减。如果一个重载任务阻塞太长时间,那么根据标准PELT算法计算出来的负载会非常的小,当该任务被唤醒重新参与调度的时候,由于负载较小会让调度器做出错误的判断。因此引入了这个成员,记录阻塞之前的load avg信息。 |
cfs rq有一个成员load保存了挂入该runqueue的调度实体load weight之和。为何要汇总这个load weight值?调度算法中主要有两个运算需要,一个是在计算具体调度实体需要分配的时间片的时候:
Se Time slice = sched period x se load weight / cfs rq load weight
此外,在计算cfs rq的负载的时候,我们也需要load weight之和,下文会详细描述。
2、*_sum的值是几何级数的累加(按照1ms为一个周期,距离当前点越远,衰减的越厉害,32个周期之后的load衰减50%,load_sum就是这些load的累加)。
*_sum的值仅考虑时间因素:
- load_sum是running+runnable时间
- util_sum仅统计running时间
对于task se,其runnable_load_sum等于util_sum,对于group se,runnable_load_sum综合考虑了其所属cfs上所有任务(整个层级结构中的任务)个数和group se处于running+runnable的时间
3、*_avg是根据 *_sum计算得到的负载均值。平均调度负载实际上包括了平均负载load_avg、平均运行负载runnable_load_avg和平均利用率util_avg。为了简单,后文省略“平均”二字,称这些术语为负载、运行负载和利用率。
4、decayed 表示是否衰减
5、delta表示task运行的时间
6、period_contrib表示上次剩余的时间
3.3 decay_load 计算经过n个period衰减的值

/*
* Approximate:
* val * y^n, where y^32 ~= 0.5 (~1 scheduling period)
*/
static __always_inline u64 decay_load(u64 val, u64 n)
{
// this function is to calc y^n^ 计算y的n次
unsigned int local_n;
// y^0^ = 1, y^32^ ^*^ ^63^ = 0;
if (!n)
return val;
else if (unlikely(n > LOAD_AVG_PERIOD * 63))
return 0;
/* after bounds checking we can collapse to 32-bit */
local_n = n;
/*
* As y^PERIOD = 1/2, we can combine
* y^n = 1/2^(n/PERIOD) * y^(n%PERIOD)
* With a look-up table which covers y^n (n= LOAD_AVG_PERIOD)) {
val >>= local_n / LOAD_AVG_PERIOD;
local_n %= LOAD_AVG_PERIOD;
}
// 计算不足32周期的数值,为避免浮点运算,直接使用上述数组,这里是涉及到32bit和64bit的转换
val = mul_u64_u32_shr(val, runnable_avg_yN_inv[local_n], 32);
return val;
}
总结下函数内容:
1、判断n值,对于界限之外的值直接返回;
2、y32=1/2,根据2进制运算机制,32次右移一位;
3、对于不足32次方的情况,查表取值避免浮点运算耗时;
3.4 __compute_runnable_contrib 计算连续完整period(ps:即上述图示d2)的累加和
封装出来此函数通过数组计算,避免运算耗时,对于runnable状态的task,计算出来如下两个数组:
1~32个period周期的累加和;
以32个period为基准计算出11个周期的累加和;

/*
* For updates fully spanning n periods, the contribution to runnable
* average will be: \Sum 1024*y^n
*
* We can compute this reasonably efficiently by combining:
* y^PERIOD = 1/2 with precomputed \Sum 1024*y^n {for n = LOAD_AVG_MAX_N))
return LOAD_AVG_MAX;
/* Since n < LOAD_AVG_MAX_N, n/LOAD_AVG_PERIOD < 11 */
//n/32 查表取值,然后再 * y^n%32^ 次,以n=35为例,就是每个周期的val再*y^3^
contrib = __accumulated_sum_N32[n/LOAD_AVG_PERIOD];
n %= LOAD_AVG_PERIOD;
contrib = decay_load(contrib, n);
//对 n%32 查表取值,然后求和
return contrib + runnable_avg_yN_sum[n];
}
总结该函数内容:
1、判断周期数
a. <=32 则查表返回
b. “>=345 则取极限值”
2、对于周期数在中间的情况:
a. n/32 查表取值
b. n%32查表取值
c. 对上述第一步和第二步的结果求和;
这个函数抽离出来封装就是为了求去完整周期数的结果,并且将其中次方运算都转换为查表,效率极高;
3.5 __update_load_avg
task实体负载更新计算的核心函数
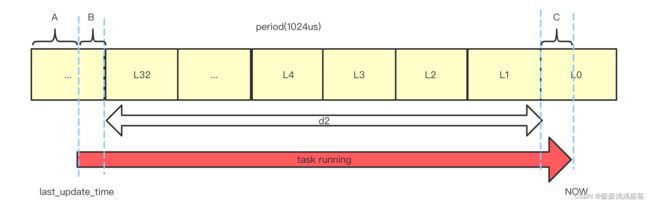
关键步骤:
period计算:
1. delta = (now - last_update_time) >> 10 // 这里转换为1024ns(作为1us)
2. delta_w = sa->period_contrib // 这个是上次更新时完整周期之外的数值,假设第一次此值为A,则第二次为C(对应上图)
3. delta + delta_w > 1024 period
1. delta_w = 1024 - delta_w
2. delta -= delta_w
3. period = delta / 1024
4. delta %= 1024
load计算:
load_sum = decay_load(load_sum, period + 1)
runnable_load_sum = decay_load(runnable_load_sum, period + 1)
util_sum = decay_load(util_sum, period + 1)
完整周期load计算:
contrib = __compute_runnable_contrib(periods)
contrib = contrib * scale_freq / 1024
更新新的period_contrib
period_contrib += delta
//更新的入口函数
static __always_inline int __update_load_avg(u64 now, int cpu, struct sched_avg *sa, unsigned long weight, int running, struct cfs_rq *cfs_rq)
{
u64 delta, scaled_delta, periods;
u32 contrib;
unsigned int delta_w, scaled_delta_w, decayed = 0;
unsigned long scale_freq, scale_cpu;
//计算当前时间与上次统计时间的差值,即上图中B+C+d2
delta = now - sa->last_update_time;
/*
* This should only happen when time goes backwards, which it
* unfortunately does during sched clock init when we swap over to TSC.
*/
//如果delta<0 则直接返回
if ((s64)delta < 0) {
sa->last_update_time = now;
return 0;
}
/*
* Use 1024ns as the unit of measurement since it's a reasonable
* approximation of 1us and fast to compute.
*/
// 以1024ns为delta方便计算,更接近us
delta >>= 10;
if (!delta)
return 0;
sa->last_update_time = now;
//获取freq和capacity
scale_freq = arch_scale_freq_capacity(NULL, cpu);
scale_cpu = arch_scale_cpu_capacity(NULL, cpu);
/* delta_w is the amount already accumulated against our next period */
delta_w = sa->period_contrib;//这个值是上次统计时间整数周期以外剩余的time,假设为上图中A,则对应下次此值为C
//超过一个period
if (delta + delta_w >= 1024) {
decayed = 1;
/* how much left for next period will start over, we don't know yet */
sa->period_contrib = 0;
/*
* Now that we know we're crossing a period boundary, figure
* out how much from delta we need to complete the current
* period and accrue it.
*/
delta_w = 1024 - delta_w;
scaled_delta_w = cap_scale(delta_w, scale_freq);
if (weight) {
sa->load_sum += weight * scaled_delta_w;
if (cfs_rq) {
cfs_rq->runnable_load_sum += weight * scaled_delta_w;
}
}
if (running)
sa->util_sum += scaled_delta_w * scale_cpu;
delta -= delta_w;// delta = delta - 1024 + period_contrib,即上图中A+B+C+d2 -1
/* Figure out how many additional periods this update spans */
periods = delta / 1024;
delta %= 1024;
sa->load_sum = decay_load(sa->load_sum, periods + 1);
if (cfs_rq) {
cfs_rq->runnable_load_sum = decay_load(cfs_rq->runnable_load_sum, periods + 1);
}
sa->util_sum = decay_load((u64)(sa->util_sum), periods + 1);
/* Efficiently calculate \sum (1..n_period) 1024*y^i */
//计算完整周期数的负载情况,即上述d2
contrib = __compute_runnable_contrib(periods);
contrib = cap_scale(contrib, scale_freq);
if (weight) {
sa->load_sum += weight * contrib;
if (cfs_rq)
cfs_rq->runnable_load_sum += weight * contrib;
}
if (running)
sa->util_sum += contrib * scale_cpu;
}
/* Remainder of delta accrued against u_0` */
scaled_delta = cap_scale(delta, scale_freq);
if (weight) {
sa->load_sum += weight * scaled_delta;
if (cfs_rq)
cfs_rq->runnable_load_sum += weight * scaled_delta;
}
if (running)
sa->util_sum += scaled_delta * scale_cpu;
sa->period_contrib += delta;//如果这次不够一个周期则累加,如果多余一个周期则做减法后取模
if (decayed) {
sa->load_avg = div_u64(sa->load_sum, LOAD_AVG_MAX);
if (cfs_rq) {
cfs_rq->runnable_load_avg =
div_u64(cfs_rq->runnable_load_sum, LOAD_AVG_MAX);
}
sa->util_avg = sa->util_sum / LOAD_AVG_MAX;
}
return decayed;
}
此函数功能总结:
1、计算周期数
2、根据之前的load情况,计算现在最新的load情况,上文结构体部分有说明主要的几个变量;
a.通过decay_load计算load_sum、load_avg、util_sum、util_avg
b.计算完整周期中的负载情况,并根据配置确认是否添加;
3、返回是否衰减