leetcode刷题记录
现在的刷题链接:https://www.algomooc.com/1659.html
刷题方式建议先刷简单题型,按照优先级依次:
字符串,
数组,
链表,
排序,
递归,
二分查找,
双指针,
动态规划
 import java.util.*
import java.util.*
public class Main{
public static void main(String[] args){
System.out.println();
}
}
链表
206.翻转链表
while(cur != null){
ListNode temp = cur.next;
cur.next = pre;
pre = cur;
cur = temp;
}
案例3:反转单链表
反转单链表。例如链表为:1->2->3->4。反转后为 4->3->2->1
链表的节点定义如下:
class Node{
int date;
Node next;
}

虽然是 Java语言,但就算你没学过 Java,我觉得也是影响不大,能看懂。
还是老套路,三要素一步一步来。
1、定义递归函数功能
假设函数 reverseList(head) 的功能是反转但链表,其中 head 表示链表的头节点。代码如下:
Node reverseList(Node head){
}
2. 寻找结束条件
表只有一个节点,或者如果是空表的话,你应该知道结果吧?直接啥也不用干,直接把 head 返回呗。代码如下:
Node reverseList(Node head){
if(head == null || head.next == null){
return head;
}
}
3. 寻找等价关系
的等价关系不像 n 是个数值那样,比较容易寻找。但是我告诉你,它的等价条件中,一定是范围不断在缩小,对于链表来说,就是链表的节点个数不断在变小,所以,如果你实在找不出,你就先对 reverseList(head.next) 递归走一遍,看看结果是咋样的。例如链表节点如下
我们就缩小范围,先对 2->3->4递归下试试,即代码如下
Node reverseList(Node head)
{
if(head == null || head.next == null)
{
return head;
} // 我们先把递归的结果保存起来,先不返回,因为我们还不清楚这样递归是对还是错。
Node newList = reverseList(head.next);
}


我们在第一步的时候,就已经定义了 reverseLis t函数的功能可以把一个单链表反转,所以,我们对 2->3->4反转之后的结果应该是这样:
我们把 2->3->4 递归成 4->3->2。不过,1 这个节点我们并没有去碰它,所以 1 的 next 节点仍然是连接这 2。
接下来呢?该怎么办?
其实,接下来就简单了,我们接下来只需要把节点 2 的 next 指向 1,然后把 1 的 next 指向 null,不就行了?,即通过改变 newList 链表之后的结果如下:
也就是说,reverseList(head) 等价于 reverseList(head.next) + 改变一下1,2两个节点的指向。好了,等价关系找出来了,代码如下(有详细的解释):
//用递归的方法反转链表
public static Node reverseList2(Node head)
{
// 1.递归结束条件
if (head == null || head.next == null)
{
return head;
}
// 递归反转 子链表
Node newList = reverseList2(head.next);
// 改变 1,2节点的指向。
// 通过 head.next获取节点2
Node t1 = head.next;
// 让 2 的 next 指向 2
t1.next = head;
// 1 的 next 指向 null.
head.next = null;
// 把调整之后的链表返回。
return newList;
}
160.相交链表
判断一个整体是否重复用set,一整个整体用set
21.合并两个有序链表
ListNode dummyNode = new ListNode(0);
ListNode res = dummyNode;
//设置一个空节点,不能直接赋值res为空
temp1 = list1.next;
res.next = list1;
list1 = temp1;
//res指针不断后移
res = res.next;
//当有一个链表遍历完时,要判断
res.next = temp1 != null ? temp1 : temp2;
86.分隔链表
创建一个small和一个big链表,head的每个节点依次和x比较,小的放入small,大的放big
初始化small和big
ListNode dummySmall = new ListNode(0);
ListNode dummyBig = new ListNode(0);
ListNode small = dummySmall;
ListNode big = dummyBig;`
逻辑比较后,big是接在后面的所以后面要接一个null
big.next = null;
small.next = dummyBig.next;
return dummySmall.next;
142.环形链表 II
直接用hashset存储一整个节点,如果出现重复节点,则为入口节点,返回即可。
92.反转链表 II
直接在原链表的基础上进行操作
ListNode dummy = new ListNode(0);
dummy.next = head;
ListNode pre = dummy;
for (int i = 1; i < left; i++){
pre = pre.next;
}
ListNode cur = pre.next; //相当于新建一个链表cur,cur任何操作都不影响pre
ListNode temp;
for (int i = 1; i < right - left + 1; i++){
// 13245
//13425
//14325
temp = cur.next; //3
cur.next = temp.next; //cur2指针指向4
temp.next = pre.next; //3的指针指向2
pre.next = temp; //1的指针指向3
}
return dummy.next;
分割三个链表进行操作,在链接
//方法二:
// ListNode dummy = new ListNode(0);
// dummy.next = head;
// ListNode pre = dummy;
// for (int i = 1;i < left ;i++){
// pre = pre.next;
// }
//
// ListNode RightNode = pre.next;
// for (int i =1 ; i < right -left +1 ;i++){
// RightNode = RightNode.next;
// }
// ListNode LeftNode = pre.next;
// ListNode cur = RightNode.next; //保存剩余未反转的链表
// //截断
// pre.next = null;
// RightNode.next = null;
// reverseLinkedList(LeftNode);
//
// //链接 反转后left和rigt位置发生变化 接上的时候要变化
// pre.next = RightNode;
// LeftNode.next = cur;
// return dummy.next;
// }
// private void reverseLinkedList(ListNode head){
// ListNode pre =null;
// ListNode cur = head;
// while(cur != null){
// ListNode temp = cur.next;
// cur.next = pre;
// pre = cur;
// cur = temp;
// }
138复制带随机指针的链表
class Solution {
Map<Node,Node> cashcode = new HashMap<>();
public Node copyRandomList(Node head) {
if (head == null){
return null;
}
if (!cashcode.containsKey(head)){
Node newnode = new Node(head.val);
cashcode.put(head,newnode);
newnode.random = copyRandomList(head.random);
newnode.next = copyRandomList(head.next);
}
return cashcode.get(head);
}
}
栈
20.有效的括号
我们遍历给定的字符串 ss。当我们遇到一个左括号时,我们会期望在后续的遍历中,有一个相同类型的右括号将其闭合。由于后遇到的左括号要先闭合,因此我们可以将这个左括号放入栈顶。
当我们遇到一个右括号时,我们需要将一个相同类型的左括号闭合。此时,我们可以取出栈顶的左括号并判断它们是否是相同类型的括号。如果不是相同的类型,或者栈中并没有左括号,那么字符串 ss 无效,返回 \text{False}False。为了快速判断括号的类型,我们可以使用哈希表存储每一种括号。哈希表的键为右括号,值为相同类型的左括号。
在遍历结束后,如果栈中没有左括号,说明我们将字符串 ss 中的所有左括号闭合,返回 \text{True}True,否则返回 \text{False}False。
注意到有效字符串的长度一定为偶数,因此如果字符串的长度为奇数,我们可以直接返回 \text{False}False,省去后续的遍历判断过程。
将左括号存在栈里,因为后遇到的左括号要先闭合,所以将左括号放入栈顶。
当遇到一个右括号,我们要判断是否有一个左括号与之匹配,看左括号类型是否一致,所以为了快速判断左括号类型,我们建立一个哈希表存储每一种括号。
建立一个栈存储s中的左括号。
155.最小栈
方法一:辅助栈
思路
要做出这道题目,首先要理解栈结构先进后出的性质。
对于栈来说,如果一个元素 a 在入栈时,栈里有其它的元素 b, c, d,那么无论这个栈在之后经历了什么操作,只要 a 在栈中,b, c, d 就一定在栈中,因为在 a 被弹出之前,b, c, d 不会被弹出。
因此,在操作过程中的任意一个时刻,只要栈顶的元素是 a,那么我们就可以确定栈里面现在的元素一定是 a, b, c, d。
那么,我们可以在每个元素 a 入栈时把当前栈的最小值 m 存储起来。在这之后无论何时,如果栈顶元素是 a,我们就可以直接返回存储的最小值 m。
224.基本计算器
方法一:括号展开 + 栈
由于字符串除了数字与括号外,只有加号和减号两种运算符。因此,如果展开表达式中所有的括号,则得到的新表达式中,数字本身不会发生变化,只是每个数字前面的符号会发生变化。
因此,我们考虑使用一个取值为 {-1,+1}{−1,+1} 的整数sign 代表「当前」的符号。根据括号表达式的性质,它的取值:
与字符串中当前位置的运算符有关;
如果当前位置处于一系列括号之内,则也与这些括号前面的运算符有关:每当遇到一个以 -− 号开头的括号,则意味着此后的符号都要被「翻转」。
考虑到第二点,我们需要维护一个栈 \textit{ops}ops,其中栈顶元素记录了当前位置所处的每个括号所「共同形成」的符号。例如,对于字符串 \text{1+2+(3-(4+5))}1+2+(3-(4+5)):
扫描到 \text{1+2}1+2 时,由于当前位置没有被任何括号所包含,则栈顶元素为初始值 +1+1;
扫描到 \text{1+2+(3}1+2+(3 时,当前位置被一个括号所包含,该括号前面的符号为 ++ 号,因此栈顶元素依然 +1+1;
扫描到 \text{1+2+(3-(4}1+2+(3-(4 时,当前位置被两个括号所包含,分别对应着 ++ 号和 -− 号,由于 ++ 号和 -− 号合并的结果为 -− 号,因此栈顶元素变为 -1−1。
在得到栈 \textit{ops}ops 之后, \textit{sign}sign 的取值就能够确定了:如果当前遇到了 ++ 号,则更新 \textit{sign} \leftarrow \text{ops.top()}sign←ops.top();如果遇到了遇到了 -− 号,则更新 \textit{sign} \leftarrow -\text{ops.top()}sign←−ops.top()。
然后,每当遇到 (( 时,都要将当前的 \textit{sign}sign 取值压入栈中;每当遇到 )) 时,都从栈中弹出一个元素。这样,我们能够在扫描字符串的时候,即时地更新 \textit{ops}ops 中的元素。
946.验证栈序列—栈中元素不重复
方法一: 贪心
思路
所有的元素一定是按顺序 push 进去的,重要的是怎么 pop 出来?
假设当前栈顶元素值为 2,同时对应的 popped 序列中下一个要 pop 的值也为 2,那就必须立刻把这个值 pop 出来。因为之后的 push 都会让栈顶元素变成不同于 2 的其他值,这样再 pop 出来的数 popped 序列就不对应了。
算法
将 pushed 队列中的每个数都 push 到栈中,同时检查这个数是不是 popped 序列中下一个要 pop 的值,如果是就把它 pop 出来。
最后,检查不是所有的该 pop 出来的值都是 pop 出来了。
通过push的长度是否等于pop的长度来判断
739.每日温度
方法一:暴力
对于温度列表中的每个元素 temperatures[i],需要找到最小的下标 j,使得 i < j 且 temperatures[i] < temperatures[j]。
由于温度范围在 [30, 100] 之内,因此可以维护一个数组 next 记录每个温度第一次出现的下标。数组 next 中的元素初始化为无穷大,在遍历温度列表的过程中更新 next 的值。
反向遍历温度列表。对于每个元素 temperatures[i],在数组 next 中找到从 temperatures[i] + 1 到 100 中每个温度第一次出现的下标,将其中的最小下标记为 warmerIndex,则 warmerIndex 为下一次温度比当天高的下标。如果 warmerIndex 不为无穷大,则 warmerIndex - i 即为下一次温度比当天高的等待天数,最后令 next[temperatures[i]] = i。
方法二:单调栈 -----简单
可以维护一个存储下标的单调栈,从栈底到栈顶的下标对应的温度列表中的温度依次递减。如果一个下标在单调栈里,则表示尚未找到下一次温度更高的下标。
正向遍历温度列表。对于温度列表中的每个元素 temperatures[i],如果栈为空,则直接将 i 进栈,如果栈不为空,则比较栈顶元素 prevIndex 对应的温度 temperatures[prevIndex] 和当前温度 temperatures[i],如果 temperatures[i] > temperatures[prevIndex],则将 prevIndex 移除,并将 prevIndex 对应的等待天数赋为 i - prevIndex,重复上述操作直到栈为空或者栈顶元素对应的温度小于等于当前温度,然后将 i 进栈。
为什么可以在弹栈的时候更新 ans[prevIndex] 呢?因为在这种情况下,即将进栈的 i 对应的 temperatures[i] 一定是 temperatures[prevIndex] 右边第一个比它大的元素,试想如果 prevIndex 和 i 有比它大的元素,假设下标为 j,那么 prevIndex 一定会在下标 j 的那一轮被弹掉。
由于单调栈满足从栈底到栈顶元素对应的温度递减,因此每次有元素进栈时,会将温度更低的元素全部移除,并更新出栈元素对应的等待天数,这样可以确保等待天数一定是最小的。
以下用一个具体的例子帮助读者理解单调栈。对于温度列表 [73,74,75,71,69,72,76,73][73,74,75,71,69,72,76,73],单调栈 \textit{stack}stack 的初始状态为空,答案 \textit{ans}ans 的初始状态是 [0,0,0,0,0,0,0,0][0,0,0,0,0,0,0,0],按照以下步骤更新单调栈和答案,其中单调栈内的元素都是下标,括号内的数字表示下标在温度列表中对应的温度。
当 i=0i=0 时,单调栈为空,因此将 00 进栈。
\textit{stack}=[0(73)]stack=[0(73)]
\textit{ans}=[0,0,0,0,0,0,0,0]ans=[0,0,0,0,0,0,0,0]
当 i=1i=1 时,由于 7474 大于 7373,因此移除栈顶元素 00,赋值 ans[0]:=1-0ans[0]:=1−0,将 11 进栈。
\textit{stack}=[1(74)]stack=[1(74)]
\textit{ans}=[1,0,0,0,0,0,0,0]ans=[1,0,0,0,0,0,0,0]
当 i=2i=2 时,由于 7575 大于 7474,因此移除栈顶元素 11,赋值 ans[1]:=2-1ans[1]:=2−1,将 22 进栈。
\textit{stack}=[2(75)]stack=[2(75)]
\textit{ans}=[1,1,0,0,0,0,0,0]ans=[1,1,0,0,0,0,0,0]
当 i=3i=3 时,由于 7171 小于 7575,因此将 33 进栈。
\textit{stack}=[2(75),3(71)]stack=[2(75),3(71)]
\textit{ans}=[1,1,0,0,0,0,0,0]ans=[1,1,0,0,0,0,0,0]
当 i=4i=4 时,由于 6969 小于 7171,因此将 44 进栈。
\textit{stack}=[2(75),3(71),4(69)]stack=[2(75),3(71),4(69)]
\textit{ans}=[1,1,0,0,0,0,0,0]ans=[1,1,0,0,0,0,0,0]
当 i=5i=5 时,由于 7272 大于 6969 和 7171,因此依次移除栈顶元素 44 和 33,赋值 ans[4]:=5-4ans[4]:=5−4 和 ans[3]:=5-3ans[3]:=5−3,将 55 进栈。
\textit{stack}=[2(75),5(72)]stack=[2(75),5(72)]
\textit{ans}=[1,1,0,2,1,0,0,0]ans=[1,1,0,2,1,0,0,0]
当 i=6i=6 时,由于 7676 大于 7272 和 7575,因此依次移除栈顶元素 55 和 22,赋值 ans[5]:=6-5ans[5]:=6−5 和 ans[2]:=6-2ans[2]:=6−2,将 66 进栈。
\textit{stack}=[6(76)]stack=[6(76)]
\textit{ans}=[1,1,4,2,1,1,0,0]ans=[1,1,4,2,1,1,0,0]
当 i=7i=7 时,由于 7373 小于 7676,因此将 77 进栈。
\textit{stack}=[6(76),7(73)]stack=[6(76),7(73)]
\textit{ans}=[1,1,4,2,1,1,0,0]ans=[1,1,4,2,1,1,0,0]
判别是否需要使用单调栈,如果需要找到左边或者右边第一个比当前位置的数大或者小,则可以考虑使用单调栈;单调栈的题目如矩形米面积等等
42.接雨水(困难)
方法一:双指针
先明确几个变量意思
left_max:左边的最大值,它是从左往右遍历找到的
right_max:右边的最大值,它是从右往左遍历找到的
left:从左往右处理的当前下标
right:从右往左处理的当前下标
定理一:在某个位置i处,它能存的水,取决于它左右两边的最大值中较小的一个。
定理二:当我们从左往右处理到left下标时,左边的最大值left_max对它而言是可信的,但right_max对它而言是不可信的。(见下图,由于中间状况未知,对于left下标而言,right_max未必就是它右边最大的值)
定理三:当我们从右往左处理到right下标时,右边的最大值right_max对它而言是可信的,但left_max对它而言是不可信的。
right_max
left_max __
__ | |
| |__ __?????????????????????? | |
__| |__| __| |__
left right
对于位置left而言,它左边最大值一定是left_max,右边最大值“大于等于”right_max,这时候,如果left_max成立,那么它就知道自己能存多少水了。无论右边将来会不会出现更大的right_max,都不影响这个结果。 所以当left_max时,我们就希望去处理left下标,反之,我们希望去处理right下标。
public int trap(int[] height) {
int left = 0, right = height.length - 1;
int ans = 0;
int left_max = 0, right_max = 0;
while (left < right) {
if (height[left] < height[right]) {
if (height[left] >= left_max) {
left_max = height[left];
} else {
ans += (left_max - height[left]);
}
++left;
} else {
if (height[right] >= right_max) {
right_max = height[right];
} else {
ans += (right_max - height[right]);
}
--right;
}
}
return ans;
}
队列
232用栈实现队列 ( LeetCode 232 )
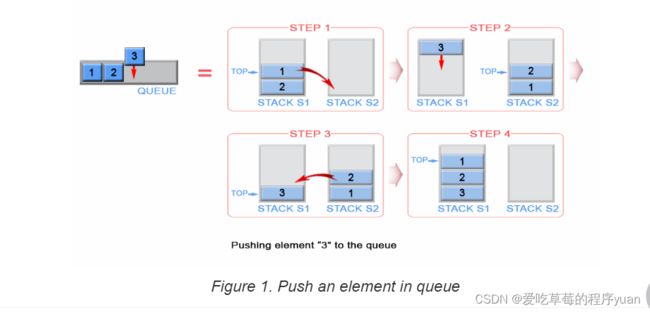
为了满足队列的 FIFO 的特性,我们需要用到两个栈,用它们其中一个来反转元素的入队顺序,用另一个来存储元素的最终顺序。
方法一(使用两个栈 入队 - O(n)O(n), 出队 - O(1)O(1))
算法
入队(push)
一个队列是 FIFO 的,但一个栈是 LIFO 的。这就意味着最新压入的元素必须得放在栈底。为了实现这个目的,我们首先需要把 s1 中所有的元素移到 s2 中,接着把新元素压入 s2。最后把 s2 中所有的元素弹出,再把弹出的元素压入 s1。
private int front;
public void push(int x) {
if (s1.empty())
front = x;
while (!s1.isEmpty())
s2.push(s1.pop());
s2.push(x);
while (!s2.isEmpty())
s1.push(s2.pop());
}
复杂度分析
时间复杂度:O(n)O(n)
对于除了新元素之外的所有元素,它们都会被压入两次,弹出两次。新元素只被压入一次,弹出一次。这个过程产生了 4n + 24n+2 次操作,其中 nn 是队列的大小。由于 压入 操作和 弹出 操作的时间复杂度为 O(1)O(1), 所以时间复杂度为 O(n)O(n)。
空间复杂度:O(n)O(n)
需要额外的内存来存储队列中的元素。
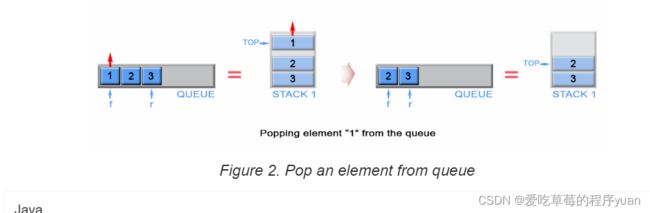
出队(pop)
直接从 s1 弹出就可以了,因为 s1 的栈顶元素就是队列的队首元素。同时我们把弹出之后 s1 的栈顶元素赋值给代表队首元素的 front 变量。
// Removes the element from the front of queue.
public void pop() {
s1.pop();
if (!s1.empty())
front = s1.peek();
}
复杂度分析
时间复杂度:O(1)O(1)
空间复杂度:O(1)O(1)
判断空(empty)
s1 存储了队列所有的元素,所以只需要检查 s1 的是否为空就可以了
// Return whether the queue is empty.
public boolean empty() {
return s1.isEmpty();
}
时间复杂度:O(1)O(1)
空间复杂度:O(1)O(1)
取队首元素(peek)
在我们的算法中,用了 front 变量来存储队首元素,在每次 入队 操作或者 出队 操作之后这个变量都会随之更新。
// Get the front element.
public int peek() {
return front;
}时间复杂度:O(1)O(1)
队首元素(front)已经被提前计算出来了,同时也只有 peek 操作可以得到它的值。
空间复杂度:O(1)O(1)
239滑动窗口最大值
思路
遍历数组,将 数 存放在双向队列中,并用 L,R 来标记窗口的左边界和右边界。队列中保存的并不是真的 数,而是该数值对应的数组下标位置,并且数组中的数要从大到小排序。如果当前遍历的数比队尾的值大,则需要弹出队尾值,直到队列重新满足从大到小的要求。刚开始遍历时,L 和 R 都为 0,有一个形成窗口的过程,此过程没有最大值,L 不动,R 向右移。当窗口大小形成时,L 和 R 一起向右移,每次移动时,判断队首的值的数组下标是否在 [L,R] 中,如果不在则需要弹出队首的值,当前窗口的最大值即为队首的数。
示例
输入: nums = [1,3,-1,-3,5,3,6,7], 和 k = 3
输出: [3,3,5,5,6,7]
解释过程中队列中都是具体的值,方便理解,具体见代码。
初始状态:L=R=0,队列:{}
i=0,nums[0]=1。队列为空,直接加入。队列:{1}
i=1,nums[1]=3。队尾值为1,3>1,弹出队尾值,加入3。队列:{3}
i=2,nums[2]=-1。队尾值为3,-1<3,直接加入。队列:{3,-1}。此时窗口已经形成,L=0,R=2,result=[3]
i=3,nums[3]=-3。队尾值为-1,-3<-1,直接加入。队列:{3,-1,-3}。队首3对应的下标为1,L=1,R=3,有效。result=[3,3]
i=4,nums[4]=5。队尾值为-3,5>-3,依次弹出后加入。队列:{5}。此时L=2,R=4,有效。result=[3,3,5]
i=5,nums[5]=3。队尾值为5,3<5,直接加入。队列:{5,3}。此时L=3,R=5,有效。result=[3,3,5,5]
i=6,nums[6]=6。队尾值为3,6>3,依次弹出后加入。队列:{6}。此时L=4,R=6,有效。result=[3,3,5,5,6]
i=7,nums[7]=7。队尾值为6,7>6,弹出队尾值后加入。队列:{7}。此时L=5,R=7,有效。result=[3,3,5,5,6,7]
通过示例发现 R=i,L=k-R。由于队列中的值是从大到小排序的,所以每次窗口变动时,只需要判断队首的值是否还在窗口中就行了。
解释一下为什么队列中要存放数组下标的值而不是直接存储数值,因为要判断队首的值是否在窗口范围内,由数组下标取值很方便,而由值取数组下标不是很方便。
代码
Java
class Solution {
public int[] maxSlidingWindow(int[] nums, int k) {
if(nums == null || nums.length < 2) return nums;
// 双向队列 保存当前窗口最大值的数组位置 保证队列中数组位置的数值按从大到小排序
LinkedList<Integer> queue = new LinkedList();
// 结果数组
int[] result = new int[nums.length-k+1];
// 遍历nums数组
for(int i = 0;i < nums.length;i++){
// 保证从大到小 如果前面数小则需要依次弹出,直至满足要求
while(!queue.isEmpty() && nums[queue.peekLast()] <= nums[i]){
queue.pollLast();
}
// 添加当前值对应的数组下标
queue.addLast(i);
// 判断当前队列中队首的值是否有效
if(queue.peek() <= i-k){
queue.poll();
}
// 当窗口长度为k时 保存当前窗口中最大值
if(i+1 >= k){
result[i+1-k] = nums[queue.peek()];
}
}
return result;
}
}
前言
对于每个滑动窗口,我们可以使用 O(k)O(k) 的时间遍历其中的每一个元素,找出其中的最大值。对于长度为 nn 的数组nums 而言,窗口的数量为 n-k+1n−k+1,因此该算法的时间复杂度为 O((n-k+1)k)=O(nk)O((n−k+1)k)=O(nk),会超出时间限制,因此我们需要进行一些优化。
我们可以想到,对于两个相邻(只差了一个位置)的滑动窗口,它们共用着 k-1k−1 个元素,而只有 11 个元素是变化的。我们可以根据这个特点进行优化。
方法一:优先队列,<大根堆>
优先队列---不熟悉
思路与算法
对于「最大值」,我们可以想到一种非常合适的数据结构,那就是优先队列(堆),其中的大根堆可以帮助我们实时维护一系列元素中的最大值。
对于本题而言,初始时,我们将数组 nums 的前 k个元素放入优先队列中。每当我们向右移动窗口时,我们就可以把一个新的元素放入优先队列中,此时堆顶的元素就是堆中所有元素的最大值。**然而这个最大值可能并不在滑动窗口中,在这种情况下,这个值在数组nums 中的位置出现在滑动窗口左边界的左侧。**因此,当我们后续继续向右移动窗口时,这个值就永远不可能出现在滑动窗口中了,我们可以将其永久地从优先队列中移除。
我们不断地移除堆顶的元素,直到其确实出现在滑动窗口中。此时,堆顶元素就是滑动窗口中的最大值。**为了方便判断堆顶元素与滑动窗口的位置关系,我们可以在优先队列中存储二元组 (num,index),**表示元素 num 在数组中的下标为 index。
代码
class Solution {
public int[] maxSlidingWindow(int[] nums, int k) {
int n = nums.length;
//优先队列
PriorityQueue<int[]> pq = new PriorityQueue<int[]>(new Comparator<int[]>() {
public int compare(int[] pair1, int[] pair2) {
return pair1[0] != pair2[0] ? pair2[0] - pair1[0] : pair2[1] - pair1[1];
}
});
for (int i = 0; i < k; ++i) {
pq.offer(new int[]{nums[i], i});
}
int[] ans = new int[n - k + 1];
ans[0] = pq.peek()[0];
for (int i = k; i < n; ++i) {
pq.offer(new int[]{nums[i], i});
while (pq.peek()[1] <= i - k) {
pq.poll();
}
ans[i - k + 1] = pq.peek()[0];
}
return ans;
}
}
复杂度分析
时间复杂度:O(n \log n)O(nlogn),其中 nn 是数组 \textit{nums}nums 的长度。在最坏情况下,数组 \textit{nums}nums 中的元素单调递增,那么最终优先队列中包含了所有元素,没有元素被移除。由于将一个元素放入优先队列的时间复杂度为 O(\log n)O(logn),因此总时间复杂度为 O(n \log n)O(nlogn)。
空间复杂度:O(n)O(n),即为优先队列需要使用的空间。这里所有的空间复杂度分析都不考虑返回的答案需要的 O(n)O(n) 空间,只计算额外的空间使用。
方法二:单调队列
思路与算法
我们可以顺着方法一的思路继续进行优化。
由于我们需要求出的是滑动窗口的最大值,如果当前的滑动窗口中有两个下标 i 和 j,其中 i 在 j 的左侧(i 当滑动窗口向右移动时,只要 i还在窗口中,那么 j一定也还在窗口中,这是 i 在 j 的左侧所保证的。因此,由于 nums[j] 的存在,nums[i] 一定不会是滑动窗口中的最大值了,我们可以将nums[i] 永久地移除。 因此我们可以使用一个队列存储所有还没有被移除的下标。在队列中,这些下标按照从小到大的顺序被存储,并且它们在数组 nums 中对应的值是严格单调递减的。因为如果队列中有两个相邻的下标,它们对应的值相等或者递增,那么令前者为 i,后者为 j,就对应了上面所说的情况,即 nums[i] 会被移除,这就产生了矛盾。 当滑动窗口向右移动时,我们需要把一个新的元素放入队列中。为了保持队列的性质,我们会不断地将新的元素与队尾的元素相比较,如果前者大于等于后者,那么队尾的元素就可以被永久地移除,我们将其弹出队列。我们需要不断地进行此项操作,直到队列为空或者新的元素小于队尾的元素。 由于队列中下标对应的元素是严格单调递减的,因此此时队首下标对应的元素就是滑动窗口中的最大值。但与方法一中相同的是,此时的最大值可能在滑动窗口左边界的左侧,并且随着窗口向右移动,它永远不可能出现在滑动窗口中了。因此我们还需要不断从队首弹出元素,直到队首元素在窗口中为止。 为了可以同时弹出队首和队尾的元素,我们需要使用双端队列。满足这种单调性的双端队列一般称作「单调队列」。 代码 } 时间复杂度:O(n),其中 n 是数组 nums 的长度。每一个下标恰好被放入队列一次,并且最多被弹出队列一次,因此时间复杂度为 O(n)。 空间复杂度:O(k)。与方法一不同的是,在方法二中我们使用的数据结构是双向的,因此「不断从队首弹出元素」保证了队列中最多不会有超过 k+1 个元素,因此队列使用的空间为 O(k)。 方法一:递归 方法一:递归 对于给定的链表,首先对除了头节点head 以外的节点进行删除操作,然后判断head 的节点值是否等于给定的 val。如果 head 的节点值等于val,则 head 需要被删除,因此删除操作后的头节点为 head.next;如果 head 的节点值不等于 val,则head 保留,因此删除操作后的头节点还是 head。上述过程是一个递归的过程。 递归的终止条件是 head 为空,此时直接返回 head。当 head 不为空时,递归地进行删除操作,然后判断 head 的节点值是否等于val 并决定是否要删除 head。 方法二: 方法二:迭代 用temp 表示当前节点。如果 temp 的下一个节点不为空且下一个节点的节点值等于给定的 val,则需要删除下一个节点。删除下一个节点可以通过以下做法实现: 如果 temp 的下一个节点的节点值不等于给定的 val,则保留下一个节点,将 temp 移动到下一个节点即可。 当temp 的下一个节点为空时,链表遍历结束,此时所有节点值等于val 的节点都被删除。 具体实现方面,由于链表的头节点 head 有可能需要被删除,因此创建哑节点 dummyHead,令dummyHead.next=head,初始化temp=dummyHead,然后遍历链表进行删除操作。最终返回dummyHead.next 即为删除操作后的头节点。 步骤分解: 1.链表分区为 已翻转部分+待翻转部分+未翻转部分 方法一:将链表复制到数组当中,再用双指针判断 arraylist获取某索引的元素的方法是arr.get(index),而不是arr[index]。 方法二:快慢指针 -----不太懂 快指针走到末尾,慢指针刚好到中间。其中慢指针将前半部分反转。 方法一:分离节点后合并 对于原始链表,每个节点都是奇数节点或偶数节点。头节点是奇数节点,头节点的后一个节点是偶数节点,相邻节点的奇偶性不同。因此可以将奇数节点和偶数节点分离成奇数链表和偶数链表,然后将偶数链表连接在奇数链表之后,合并后的链表即为结果链表。 原始链表的头节点 head 也是奇数链表的头节点以及结果链表的头节点,head 的后一个节点是偶数链表的头节点。令 evenHead = head.next,则 evenHead 是偶数链表的头节点。 维护两个指针 odd 和 even 分别指向奇数节点和偶数节点,初始时 odd = head,even = evenHead。通过迭代的方式将奇数节点和偶数节点分离成两个链表,每一步首先更新奇数节点,然后更新偶数节点。 更新奇数节点时,奇数节点的后一个节点需要指向偶数节点的后一个节点,因此令 odd.next = even.next,然后令 odd = odd.next,此时 odd 变成 even 的后一个节点。 更新偶数节点时,偶数节点的后一个节点需要指向奇数节点的后一个节点,因此令 even.next = odd.next,然后令 even = even.next,此时 even 变成 odd 的后一个节点。 在上述操作之后,即完成了对一个奇数节点和一个偶数节点的分离。重复上述操作,直到全部节点分离完毕。全部节点分离完毕的条件是 even 为空节点或者 even.next 为空节点,此时 odd 指向最后一个奇数节点(即奇数链表的最后一个节点)。 最后令 odd.next = evenHead,将偶数链表连接在奇数链表之后,即完成了奇数链表和偶数链表的合并,结果链表的头节点仍然是 head。 利用递归: 先走至链表末端,回溯时依次将节点值加入列表 ,这样就可以实现链表值的倒序输出。 Java 算法流程: 递推阶段: 每次传入 head.next ,以 head == null(即走过链表尾部节点)为递归终止条件,此时直接返回。 时间复杂度o(n),空间负责度O(n). 思路与算法 最简单直接的方法即为顺序查找,假设当前链表的长度为 n,则我们知道链表的倒数第 k 个节点即为正数第 n - k 个节点,此时我们只需要顺序遍历到链表的第 n−k 个节点即为倒数第 kk个节点。 我们首先求出链表的长度 n,然后顺序遍历到链表的第kn−k 个节点返回即可。 复杂度分析 思路与算法 快慢指针的思想。我们将第一个指针fast 指向链表的第k+1 个节点,第二个指针 slow 指向链表的第一个节点,此时指针fast 与 slow 二者之间刚好间隔 k 个节点。此时两个指针同步向后走,当第一个指针 fast 走到链表的尾部空节点时,则此时slow 指针刚好指向链表的倒数第k个节点。 我们首先将fast 指向链表的头节点,然后向后走 k 步,则此时fast 指针刚好指向链表的第k+1 个节点。 我们首先将 slow 指向链表的头节点,同时 slow 与 fast 同步向后走,当fast 指针指向链表的尾部空节点时,则此时返回slow 所指向的节点即可。 代码 } 时间复杂度:O(n),其中 nn为链表的长度。我们使用快慢指针,只需要一次遍历即可,复杂度为 O(n)。 空间复杂度:O(1)。 方法一: 排序 对原数组从小到大排序后取出前 k 个数即可。 时间复杂度:O(nlogn),其中 n 是数组 arr 的长度。算法的时间复杂度即排序的时间复杂度。 空间复杂度:O(logn),排序所需额外的空间复杂度为 O(logn)。 方法二:堆 我们用一个大根堆实时维护数组的前 k小值。首先将前 k 个数插入大根堆中,随后从第 k+1 个数开始遍历,如果当前遍历到的数比大根堆的堆顶的数要小,就把堆顶的数弹出,再插入当前遍历到的数。最后将大根堆里的数存入数组返回即可。 时间复杂度:O(n\log k)O(nlogk),其中 nn 是数组 arr 的长度。由于大根堆实时维护前 kk 小值,所以插入删除都是 O(\log k)O(logk) 的时间复杂度,最坏情况下数组里 nn 个数都会插入,所以一共需要 O(n\log k)O(nlogk) 的时间复杂度。 空间复杂度:O(k)O(k),因为大根堆里最多 kk 个数。 方法三:快排思想 我们可以借鉴快速排序的思想。我们知道快排的划分函数每次执行完后都能将数组分成两个部分,小于等于分界值 pivot 的元素的都会被放到数组的左边,大于的都会被放到数组的右边,然后返回分界值的下标。与快速排序不同的是,快速排序会根据分界值的下标递归处理划分的两侧,而这里我们只处理划分的一边。 我们定义函数 randomized_selected(arr, l, r, k) 表示划分数组 arr 的 [l,r] 部分,使前 k 小的数在数组的左侧,在函数里我们调用快排的划分函数,假设划分函数返回的下标是 pos(表示分界值 pivot 最终在数组中的位置),即 pivot 是数组中第 pos - l + 1 小的数,那么一共会有三种情况: 如果 pos - l + 1 == k,表示 pivot 就是第 kk 小的数,直接返回即可; 如果 pos - l + 1 < k,表示第 kk 小的数在 pivot 的右侧,因此递归调用 randomized_selected(arr, pos + 1, r, k - (pos - l + 1)); 如果 pos - l + 1 > k,表示第 kk 小的数在 pivot 的左侧,递归调用 randomized_selected(arr, l, pos - 1, k)。 函数递归入口为 randomized_selected(arr, 0, arr.length - 1, k)。在函数返回后,将前 k 个数放入答案数组返回即 时间复杂度:期望为 O(n) ,由于证明过程很繁琐,所以不在这里展开讲。具体证明可以参考《算法导论》第 9 章第 2 小节。 最坏情况下的时间复杂度为 O(n^2)。情况最差时,每次的划分点都是最大值或最小值,一共需要划分n−1 次,而一次划分需要线性的时间复杂度,所以最坏情况下时间复杂度为 O(n^2。 空间复杂度:期望为 O(logn),递归调用的期望深度为 O(logn),每层需要的空间为 O(1),只有常数个变量。 最坏情况下的空间复杂度为 O(n)。最坏情况下需要划分 n 次,即 randomized_selected 函数递归调用最深 n - 1 层,而每层由于需要O(1) 的空间,所以一共需要 O(n) 的空间复杂度。 //快慢指针 时间复杂度:O(n)O(n),其中 nn 是数组 \textit{nums}nums 的长度。 空间复杂度:O(1)O(1)。除了存储答案的数组以外,我们只需要维护常量空间。 方法二:直接排序 Arrays.sort(ans); 时间复杂度:O(nlogn),其中 n 是数组 nums 的长度。 空间复杂度:O(logn)。除了存储答案的数组以外,我们需要 O(logn) 的栈空间进行排序。 方法:滑动窗口 在方法一和方法二中,都是每次确定子数组的开始下标,然后得到长度最小的子数组,因此时间复杂度较高。为了降低时间复杂度,可以使用滑动窗口的方法。 定义两个指针start 和 end 分别表示子数组(滑动窗口窗口)的开始位置和结束位置,维护变量 sum 存储子数组中的元素和(即从nums[start] 到]nums[end] 的元素和)。 初始状态下,start 和end 都指向下标 0,sum 的值为 0。 每一轮迭代,将 nums[end] 加到 sum,如果 sum≥s,则更新子数组的最小长度(此时子数组的长度是 end−start+1),然后将 nums[start] 从sum 中减去并将 start 右移,直到 sum 补充: 举一反三: 如果要取最大值,定义int res = Integer.MIN_VALUE 进行Math.Max( , )筛选操作 return res == Integer.MIN_VALUE ? 0 : res 方法一:按层模拟 定义矩阵的第 kk 层是到最近边界距离为 k 的所有顶点。例如,下图矩阵最外层元素都是第 1 层,次外层元素都是第 2 层,最内层元素都是第 3 层。 对于每层,从左上方开始以顺时针的顺序填入所有元素。假设当前层的左上角位于 (top,left),右下角位于 (bottom,right),按照如下顺序填入当前层的元素。 从左到右填入上侧元素,依次为 (top,left) 到 (top,right)。 从上到下填入右侧元素,依次为(top+1,right) 到(bottom,right)。 如果 left 填完当前层的元素之后,将 left 和 top 分别增加 11,将 right 和 \textit{bottom}bottom 分别减少 11,进入下一层继续填入元素,直到填完所有元素为止。 简洁函数 返回pre!!! 方法二:双指针 方法一:哈希集合 创建一个临时节点分别等于headA和headB 思路和算法 判断两个链表是否相交,可以使用哈希集合存储链表节点。 首先遍历链表 headA,并将链表headA 中的每个节点加入哈希集合中。然后遍历链表 headB,对于遍历到的每个节点,判断该节点是否在哈希集合中: 如果当前节点不在哈希集合中,则继续遍历下一个节点; 如果当前节点在哈希集合中,则后面的节点都在哈希集合中,即从当前节点开始的所有节点都在两个链表的相交部分,因此在链表headB 中遍历到的第一个在哈希集合中的节点就是两个链表相交的节点,返回该节点。 如果链表headB 中的所有节点都不在哈希集合中,则两个链表不相交,返回 null。 时间复杂度:O(m+n),其中 m和 n是分别是链表 headA 和headB 的长度。需要遍历两个链表各一次。 空间复杂度:O(m),其中 m 是链表 headA 的长度。需要使用哈希集合存储链表 headA 中的全部节点。 方法二:双指针class Solution {
public int[] maxSlidingWindow(int[] nums, int k) {
int n = nums.length;
//定义双向队列
Deque<Integer> deque = new LinkedList<Integer>();
//分两种情况i < k
for (int i = 0; i < k; ++i) {
while (!deque.isEmpty() && nums[i] >= nums[deque.peekLast()]) {
deque.pollLast();
}
deque.offerLast(i);
}
int[] ans = new int[n - k + 1];
ans[0] = nums[deque.peekFirst()];
//
for (int i = k; i < n; ++i) {
while (!deque.isEmpty() && nums[i] >= nums[deque.peekLast()]) {
deque.pollLast();
}
deque.offerLast(i);
while (deque.peekFirst() <= i - k) {
deque.pollFirst();
}
ans[i - k + 1] = nums[deque.peekFirst()];
}
return ans;
}
复杂度分析https://blog.csdn.net/cgsyck/article/details/108580298?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522165579296216782184616703%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=165579296216782184616703&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~first_rank_ecpm_v1~rank_v31_ecpm-3-108580298-null-null.142^v19^control,157^v15^new_3&utm_term=deque.polllast%28%29&spm=1018.2226.3001.4187
双向队列deque
添加元素:
add() 尾部添加元素,如果元素不能插入到Deque,那么add()方法将抛异常,这个和 offer()方法不一样,如果不能添加元素offer()方法将返回false。add()方法实际是继承Queue接口。
addLast() addLast()方法也可以在 Deque的尾部添加元素,这是Deque接口与从Queue接口继承的add()方法等效
addFirst() 如果Deque不能添加元素,addFirst()方法会抛异常, offerFirst()方法则返回 false。
offer()
offerFirst()
offerLast()
添加元素
add() :尾部添加元素
报异常
addLast()
报异常
addFirst()
报异常
offer():尾部添加元素
返回false
offerFirst()
返回false
offerLast()
返回false
查看元素:
可以查看Deque中的第一个或者最后一个元素,查看元素意味着获取元素的引用而不是移除元素,有下面几种方法:
peek() :peek()返回Deque中的第一个元素并且不擅长,如果Deque是空则返回null:
peekFirst()
peekLast() :Deque中可以通过peekLast()方法查看最后一个元素,如果Deque是空则返回null:
getFirst() :getFirst()方法获取Deque的第一个元素并且不删除,如果Deque是空则抛异常:
getLast()
查看元素
peek()
返回null
peekFirst()
返回null
peekLast()
返回null
getFirst()
抛异常
getLast()
抛异常
移除Deque中的元素
以下几种方法可以移除Deque 中的元素:
remove() :remove()方法移除Deque中的第一个元素并返回:如果是空则抛异常
removeFirst() :removeFirst()方法同样移除Deque中的第一个元素:
removeLast()
poll() :poll()方法移除Deque中的第一个元素,如果Deque为空则poll()返回null
pollFirst()
pollLast()
pop()方法移除Deque的第一个元素,如果Deque是空则抛异常:
移除元素
remove()
抛异常
removeFirst()
removeLast()
poll() :移除第一个元素
返回null
pollFirst()
pollLast()
203.移除链表元素
链表的定义具有递归的性质,因此链表题目常可以用递归的方法求解。这道题要求删除链表中所有节点值等于特定值的节点,可以用递归实现。class Solution {
public ListNode removeElements(ListNode head, int val) {
if (head == null) {
return head;
}
head.next = removeElements(head.next, val);
return head.val == val ? head.next : head;
}
}
也可以用迭代的方法删除链表中所有节点值等于特定值的节点。
temp.next=temp.next.nextclass Solution {
public ListNode removeElements(ListNode head, int val) {
ListNode dummyHead = new ListNode(0);
dummyHead.next = head;
ListNode temp = dummyHead;
while (temp.next != null) {
if (temp.next.val == val) {
temp.next = temp.next.next;
} else {
temp = temp.next;
}
}
return dummyHead.next;
}
}
641. 设计循环双端队列
25.k个一组反转链表
public ListNode reverseListNode(ListNode head,ListNode tail) {
//这是有头结点和尾结点的翻转链表与单独的反转链表只有一个头结点不同
ListNode prev = tail.next;
ListNode cur = head;
while (prev != tail){
ListNode next = cur.next;
cur.next = prev;
prev = cur;
cur = next;
return new ListNode[](tail,head);
}
}
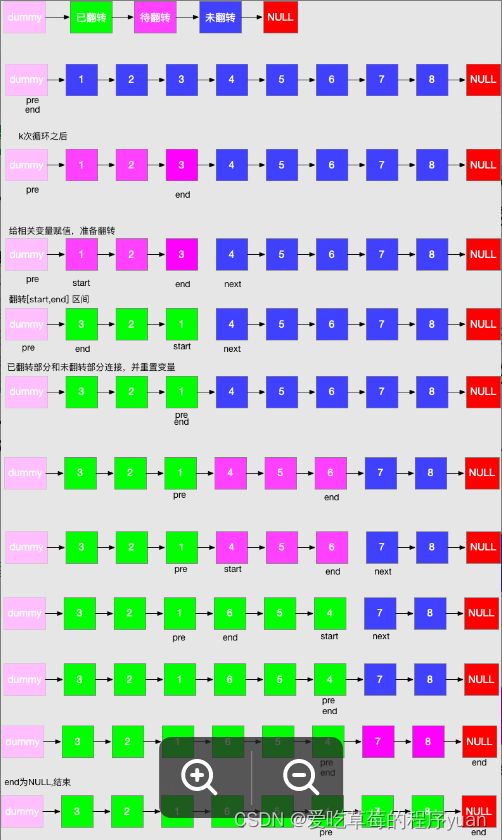
2.每次翻转前,要确定翻转链表的范围,这个必须通过 k 此循环来确定
3.需记录翻转链表前驱和后继,方便翻转完成后把已翻转部分和未翻转部分连接起来
4.初始需要两个变量 pre 和 end,pre 代表待翻转链表的前驱,end 代表待翻转链表的末尾
5.经过k此循环,end 到达末尾,记录待翻转链表的后继 next = end.next
6.翻转链表,然后将三部分链表连接起来,然后重置 pre 和 end 指针,然后进入下一次循环
7.特殊情况,当翻转部分长度不足 k 时,在定位 end 完成后,end==null,已经到达末尾,说明题目已完成,直接返回即可
8.时间复杂度为 O(n*K)最好的情况为 O(n) 最差的情况未 O(n^2)空间复杂度为 O(1)除了几个必须的节点指针外,我们并没有占用其他空间
public ListNode reverseKGroup(ListNode head, int k) {
ListNode dummy = new ListNode(0);
dummy.next = head;
ListNode pre = dummy;
ListNode end = dummy;
while (end.next != null) {
for (int i = 0; i < k && end != null; i++) end = end.next;
if (end == null) break;
ListNode start = pre.next;
ListNode next = end.next;
end.next = null;
pre.next = reverse(start);
start.next = next;
pre = start;
end = pre;
}
return dummy.next;
}
private ListNode reverse(ListNode head) {
ListNode pre = null;
ListNode curr = head;
while (curr != null) {
ListNode next = curr.next;
curr.next = pre;
pre = curr;
curr = next;
}
return pre;
}
234 回文链表
1.数组和ArrayList都表示可以存一组同类型的对象;都使用下标定位和查找元素;
2.数组的定义:
int[] num=new int[10];
int n = num[i];
3.ArrayList的使用:
List lst=new ArrayList();
lst.add(employee);
lst.get(position);
class Solution {
public boolean isPalindrome(ListNode head) {
List<Integer> vals = new ArrayList<Integer>();
//定义一个数组m ,存储链表的val值
// 将链表的值复制到数组中
ListNode currentNode = head;
//注意是 要循环将链表的val值放入数组中 不能用if判断 一定要while
while (currentNode != null) {
vals.add(currentNode.val);
currentNode = currentNode.next;
}
//定义前后指针,看对应的val是否相等
// 使用双指针判断是否回文
int front = 0;
int back = vals.size() - 1;
//循环符合条件的数组
while (front < back) {
//arraylist获取某索引的元素的方法是arr.get(index),而不是arr[index]。
if (!vals.get(front).equals(vals.get(back))) {
return false;
}
front++;
back--;
}
return true;
}
}
public boolean isPalindrome(ListNode head) {
if(head == null || head.next == null) {
return true;
}
ListNode slow = head, fast = head;
ListNode pre = head, prepre = null;
while(fast != null && fast.next != null) {
pre = slow;
slow = slow.next;
fast = fast.next.next;
pre.next = prepre;
prepre = pre;
}
if(fast != null) {
slow = slow.next;
}
while(pre != null && slow != null) {
if(pre.val != slow.val) {
return false;
}
pre = pre.next;
slow = slow.next;
}
return true;
}
328.奇偶链表
如果链表为空,则直接返回链表。
class Solution {
public ListNode oddEvenList(ListNode head) {
if (head == null) {
return head;
}
//定义一个偶数链表头结点
ListNode evenHead = head.next;
ListNode odd = head, even = evenHead;
while (even != null && even.next != null) {
odd.next = even.next;//去除even节点
odd = odd.next;//更新odd节点
even.next = odd.next; //将even节点和后面的偶数节点连接
even = even.next;//更新even节点
}
odd.next = evenHead;//遍历结束后将奇数链表与偶数链表连接在一起
return head;
}
}
//循环条件是数量大于三,而怎么样判断是不是大于三要看偶数节点以及偶数节点的next是否未空
//首先定义一个evenHead 偶数头结点= 第一个偶数节点 head.next,
//奇数节点odd = head;even= head.next;
剑指offer06. 从尾到头打印链表
剑指offer06. 从尾到头打印链表
方法一:递归法
解题思路:
回溯阶段: 层层回溯时,将当前节点值加入列表,即tmp.add(head.val)。
最终,将列表 tmp 转化为数组 res ,并返回即可。class Solution {
ArrayList<Integer> tmp= new ArrayList<Integer>();
public int[] reversePrint(ListNode head) {
//因为recur方法中要用到tmp所以不能放在方法内
// ArrayList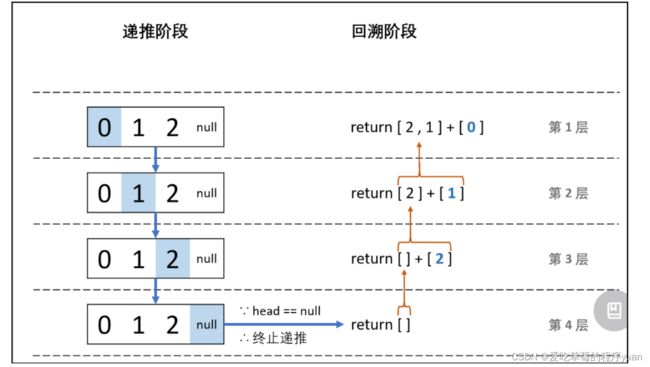
方法二:辅助栈法
解题思路:
链表特点: 只能从前至后访问每个节点。
题目要求: 倒序输出节点值。
这种 先入后出 的需求可以借助 栈 来实现。
算法流程:
入栈: 遍历链表,将各节点值 push 入栈。(Python 使用 append() 方法,Java借助 LinkedList 的addLast()方法)。
出栈: 将各节点值 pop 出栈,存储于数组并返回。(Python 直接返回 stack 的倒序列表,Java 新建一个数组,通过 popLast() 方法将各元素存入数组,实现倒序输出)。
复杂度分析:
时间复杂度 O(N)O(N): 入栈和出栈共使用 O(N)O(N) 时间。
空间复杂度 O(N)O(N): 辅助栈 stack 和数组 res 共使用 O(N)O(N) 的额外空间。
图解以 Java 代码为例,Python 无需将 stack 转移至 res,而是直接返回倒序数组。
class Solution {
//方法二,辅助栈
//链表特点: 只能从前至后访问每个节点。
// 题目要求: 倒序输出节点值。
// 这种 先入后出 的需求可以借助 栈 来实现。
public int[] reversePrint(ListNode head) {
LinkedList<Integer> stack = new LinkedList<Integer>();
while (head != null){
stack.addLast(head.val);
head = head.next;
}
int[] res = new int[stack.size()];
//错误 for (int i = 0;i < stack.size();i++),栈是一直在变的长度也是在变化的所以这里不能用栈的长度
for (int i = 0;i < res.length;i++){
res[i] = stack.removeLast();
}
return res;
}
}


剑指 Offer 22. 链表中倒数第k个节点
方法一:顺序查找
class Solution {
public ListNode getKthFromEnd(ListNode head, int k) {
int n = 0;
ListNode node = null;
for (node = head; node != null; node = node.next) {
//先遍历一下链表的长度为n
n++;
}
//直到n变为k 则剩余的节点就是倒数第k个节点,相当于走了n-k步
for (node = head; n > k; n--) {
node = node.next;
}
return node;
}
}
方法二:双指针
class Solution {
public ListNode getKthFromEnd(ListNode head, int k) {
ListNode fast = head;
ListNode slow = head;
while (fast != null && k > 0) {
fast = fast.next;
k--;
}
while (fast != null) {
fast = fast.next;
slow = slow.next;
}
return slow;
}
复杂度分析剑指offer40.最小的k个数
class Solution {
public int[] getLeastNumbers(int[] arr, int k) {
//对数组排序
Arrays.sort(arr);
int[] res = new int[k];
for (int i = 0; i < k; i++){
res[i] = arr[i];
}
return res;
}
}
思路和算法class Solution {
public int[] getLeastNumbers(int[] arr, int k) {
int[] vec = new int[k];
if (k == 0) { // 排除 0 的情况
return vec;
}
PriorityQueue<Integer> queue = new PriorityQueue<Integer>(new Comparator<Integer>() {
public int compare(Integer num1, Integer num2) {
return num2 - num1;
}
});
for (int i = 0; i < k; ++i) {
queue.offer(arr[i]);
}
for (int i = k; i < arr.length; ++i) {
if (queue.peek() > arr[i]) {
queue.poll();
queue.offer(arr[i]);
}
}
for (int i = 0; i < k; ++i) {
vec[i] = queue.poll();
}
return vec;
}
}
思路和算法class Solution {
public int[] getLeastNumbers(int[] arr, int k) {
randomizedSelected(arr, 0, arr.length - 1, k);
int[] vec = new int[k];
for (int i = 0; i < k; ++i) {
vec[i] = arr[i];
}
return vec;
}
private void randomizedSelected(int[] arr, int l, int r, int k) {
if (l >= r) {
return;
}
int pos = randomizedPartition(arr, l, r);
int num = pos - l + 1;
if (k == num) {
return;
} else if (k < num) {
randomizedSelected(arr, l, pos - 1, k);
} else {
randomizedSelected(arr, pos + 1, r, k - num);
}
}
// 基于随机的划分
private int randomizedPartition(int[] nums, int l, int r) {
int i = new Random().nextInt(r - l + 1) + l;
swap(nums, r, i);
return partition(nums, l, r);
}
private int partition(int[] nums, int l, int r) {
int pivot = nums[r];
int i = l - 1;
for (int j = l; j <= r - 1; ++j) {
if (nums[j] <= pivot) {
i = i + 1;
swap(nums, i, j);
}
}
swap(nums, i + 1, r);
return i + 1;
}
private void swap(int[] nums, int i, int j) {
int temp = nums[i];
nums[i] = nums[j];
nums[j] = temp;
}
}
数组
704二分查找
class Solution {
public int search(int[] nums, int target) {
// if (nums.length == 0){
// return -1;
// }
// for (int i = 0;i <= nums.length-1 ; i++){
// if (nums[i] == target){
// return i;
// }
// }
// return -1;
//二分查找
if (nums.length == 0){
return -1;
}
int i= 0;
int j = nums.length - 1;
while (i <= j){//注意等于的情况
int mid = (j -i)/2 + i;
if (nums[mid] == target){
return mid;
}else if (nums[mid] > target){
j = mid -1;
}else {
i = mid +1;
}
}
return -1;
}
}
27移除元素
class Solution {
public int removeElement(int[] nums, int val) {
int n = nums.length;
int left = 0;
for (int right = 0; right < n; right++) {
if (nums[right] != val) {
nums[left] = nums[right];
left++;
}
}
return left;
}
} //双指针
int i= 0;
int j =nums.length -1;
while (i <= j){
if (nums[i] == val){
nums[i] = nums[j];
j--;
}else {
i++;
}
}
return i;
## 977 有序数组的平方
//给你一个按 非递减顺序 排序的整数数组 nums,返回 每个数字的平方 组成的新数组,要求也按 非递减顺序 排序。
// 示例 1:
//输入:nums = [-4,-1,0,3,10]
//输出:[0,1,9,16,100]
//解释:平方后,数组变为 [16,1,0,9,100]
//排序后,数组变为 [0,1,9,16,100]
// 示例 2:
//输入:nums = [-7,-3,2,3,11]
//输出:[4,9,9,49,121]
// 提示:
// 1 <= nums.length <= 10⁴
// -10⁴ <= nums[i] <= 10⁴
// nums 已按 非递减顺序 排序
// 进阶:
// 请你设计时间复杂度为 O(n) 的算法解决本问题
//leetcode submit region begin(Prohibit modification and deletion)
class Solution {
public int[] sortedSquares(int[] nums) {
//双指针法
int n = nums.length;
int[] res = new int[n];
int i =0;
int j = n-1;
while (n-1 >=0){
if (nums[i] * nums[i] >= nums[j] * nums[j]){
res[n-1] = nums[i] * nums[i];
i++;
}else {
res[n-1] = nums[j] * nums[j];
j--;
}
n--;
}
return res;
}
}
//leetcode submit region end(Prohibit modification and deletion)
class Solution {
public int[] sortedSquares(int[] nums) {
int[] ans = new int[nums.length];
for (int i = 0; i < nums.length; ++i) {
ans[i] = nums[i] * nums[i];
}
Arrays.sort(ans);
return ans;
}
}
209 长度最小的子数组
class Solution {
public int minSubArrayLen(int s, int[] nums) {
int n = nums.length;
if (n == 0) {
return 0;
}
int ans = Integer.MAX_VALUE;
int start = 0, end = 0;
int sum = 0;
while (end < n) {
//每一轮迭代,将 nums[end] 加到 sum
sum += nums[end];
//如果 sum≥s,则更新子数组的最小长度(此时子数组的长度是 end−start+1),然后将 nums[start] 从sum 中减去并将 start 右移,直到 sumInteger.MAX_VALUE的含义
在了解Integer.MAX_VALUE的含义之前,我们得先知道java中的基本数据类型
在Java中,一共有8种基本数据类型:
整数型:int , short , long , byte 。
浮点型:float , double 。
字符类型:char 。
表示真值的类型:boolean 。
(String属于Java中的字符串类型,也是一个引用类型,并不属于基本的数据类型)
整数型和浮点型取值范围如下:
Integer.MAX_VALUE表示int数据类型的最大取值数:2 147 483 647
Integer.MIN_VALUE表示int数据类型的最小取值数:-2 147 483 648
对应:
** Short.MAX_VALUE 为short类型的最大取值数 32 767
Short.MIN_VALUE 为short类型的最小取值数 -32 768**
其他数据类型同上含义
补充:
Integer.MAX_VALUE+1=Integer.MIN_VALUE
因为:
Integer.MAX_VALUE的二进制是0111 1111 1111 1111 1111 1111 1111 1111
Integer.MIN_VALUE的二进制是 1000 0000 0000 0000 0000 0000 0000 0000
0111 1111 1111 1111 1111 1111 1111 1111+1=1000 0000 0000 0000 0000 0000 0000 0000
59 螺旋矩阵
题目描述:给你一个正整数 n ,生成一个包含 1 到 n2 所有元素,且元素按顺时针顺序螺旋排列的 n x n 正方形矩阵 matrix 。
可以将矩阵看成若干层,首先填入矩阵最外层的元素,其次填入矩阵次外层的元素,直到填入矩阵最内层的元素。

public int[][] generateMatrix(int n) {
int num = 1;
int[][] matrix = new int[n][n];//定义matrix数组
int left = 0, right = n - 1, top = 0, bottom = n - 1;//定义四个点的位置
while (left <= right && top <= bottom) {
for (int column = left; column <= right; column++) {
matrix[top][column] = num;
num++;
}
for (int row = top + 1; row <= bottom; row++) {
matrix[row][right] = num;
num++;
}
if (left < right && top < bottom) {
for (int column = right - 1; column > left; column--) {
matrix[bottom][column] = num;
num++;
}
for (int row = bottom; row > top; row--) {
matrix[row][left] = num;
num++;
}
}
left++;
right--;
top++;
bottom--;
}
return matrix;
}
}
# 排序
## 冒泡排序
各个排序代码:
https://github.com/MisterBooo/Play-With-Sort-OC
```java
public class demo_sort {
public static void main(String[] args) {
//冒泡排序算法
int[] numbers=new int[]{1,5,8,2,3,9,4};
//需进行length-1次冒泡
for(int i=0;i<numbers.length-1;i++)
{
for(int j=0;j<numbers.length-1-i;j++)
{
if(numbers[j]>numbers[j+1])
{
int temp=numbers[j];
numbers[j]=numbers[j+1];
numbers[j+1]=temp;
}
}
}
System.out.println("从小到大排序后的结果是:");
for(int i=0;i<numbers.length;i++)
System.out.print(numbers[i]+" ");
}
}

直接插入排序
直接插入排序(Insertion Sort)的基本思想是:每次将一个待排序的记录,按其关键字大小插入到前面已经排好序的子序列中的适当位置,直到全部记录插入完成为止。
设数组为a[0….N-1]:
(1)初始时,a[0]自成1个有序区,无序区为a[1..n-1]。令i=1
(2)将a[i]并入当前的有序区a[0…i-1]中形成a[0…i]的有序区间。
(3)i++并重复第二步直到i==n-1,排序完成。
按照上面的思路,给出代码:
public class insert{
public stactic void insertSort1(int[] a){
int i;
int j;
int n = a.length;
for(int i=1; i<n,i++){//依次把a[1]到a[n-1]插入到前面有序序列中
//从前往后找到a[i]的插入点
for(int j = 0;j < i;j++){//假设0至i-1已结是排好序的序列,将a[i]插入其中
if(a[j]>a[i]){
break;//跳出内层循环
}
}
//将元素a[i]插在a[j]的位置上,从a[j]到a[i-1]后移
int temp =a[i];
//将a[j]开始的元素到a[i-1]后移一位,覆盖a[i]
for(int k=i-1; k>=j; k--){
a[k+1] = a[k];
}
//将a[i]插入
a[j] = temp;
}
}
//测试函数
public static void main(String[] args){
int[] nums = new int[]{1,1,2,0,9,3,12, 7, 8, 3, 4, 65, 22};
InsertionSort.insertSort2(arr, arr.length);
for(int i:arr){
System.out.print(i+",");
}
}
int i, j;
for(i =1; i<n; i++) {//依次把a[1]到a[n-1]插入到前面
for(j = i-1; j>=0 && a[j]>a[j+1]; j--){
int temp;
temp = a[j];
a[j] = a[j+1];
a[j+1]=temp;
}
}
}
# 链表
```java
import java.util.*
public class Main{
public static void main(String[] args){
System.out.printlin();
}
}
24两两交换链表
class Solution {
public ListNode swapPairs(ListNode head) {
ListNode dummyHead = new ListNode(0);
dummyHead.next = head;
ListNode temp = dummyHead;
while (temp.next != null && temp.next.next != null) {
ListNode node1 = temp.next;
ListNode node2 = temp.next.next;
temp.next = node2;
node1.next = node2.next;
node2.next = node1;
temp = node1;
// temp = n2;//错误的
// temp = n1;//temp等于已经反转后的n1
}
return dummyHead.next;
}
}
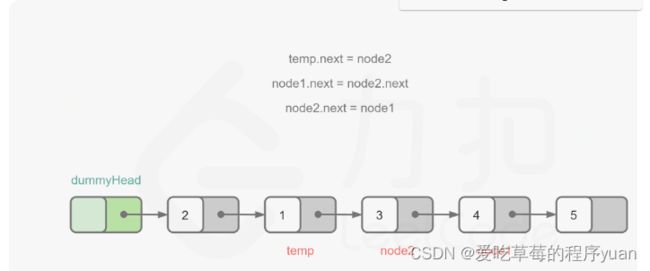
顺序:temp= dummy,temp.next =n2; n1.next = n2.next; n2.next = n1;
temp = n1;此时n1已经反转在第二个位置上206.翻转链表
203移除链表元素
while(temp.next != null){
if(temp.next.val == val){
temp.next = temp.next.next;
}
else{
temp = temp.next;
}
}
19.删除链表的倒数第N个节点







class Solution {
public ListNode removeNthFromEnd(ListNode head, int n) {
ListNode dummy = new ListNode();
dummy.next = head;
int l = 0;
//先遍历链表的长度
while (head != null){
l++;
head = head.next;
}
ListNode cur = dummy;//不能直接在head,或是dummy上操作
for (int i = 1; i < l - n + 1; ++i) {
cur = cur.next;
}
cur.next = cur.next.next;//后面的链接上
ListNode ans = dummy.next;
return ans;
}
}
class Solution {
public ListNode removeNthFromEnd(ListNode head, int n) {
//创建val = 0,dummy.next = head的节点
ListNode dummy = new ListNode(0, head);
//创建快慢指针
ListNode first = head;
ListNode second = dummy;
//快指针走n步
for (int i = 0; i < n; ++i) {
first = first.next;
}
while (first != null) {
first = first.next;
second = second.next;
}//走到结尾后删除倒数第n个节点
second.next = second.next.next;
ListNode ans = dummy.next;
return ans;
}
}
面试题 02.07. 链表相交
import java.util.HashSet;
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int x) {
* val = x;
* next = null;
* }
* }
*/
public class Solution {
public ListNode getIntersectionNode(ListNode headA, ListNode headB) {
HashSet set = new HashSet<>();
ListNode temp = headA;
while (temp != null){
set.add(temp);
temp = temp.next;
}
temp = headB;
while (temp != null) {
if (set.contains(temp)){
return temp;
}
temp = temp.next;
}
return null;
}
}
public class Solution {
public ListNode getIntersectionNode(ListNode headA, ListNode headB) {
/*
总体思路:双指针
headA=[a1,a2,...,an]与headB=[b1,b2,...,bn]
pA在a1出发,pB在b1出发;当pA到达A链表末尾null就到B开头处重新开始;pB同理
最后两个指针相遇时就是相交的地方
*/
ListNode pA = headA, pB = headB;
while (pA != pB) {
// A指针与B一路往下走,走完了就去另一个链表的头结点,直至相遇
// 这里注意不能用pA.next作为判断,因为遇到空链表会发生空指针异常
// 这里就算有其中一个链表为空或者没相交的也成立(最后为null)
pA = pA == null ? headB : pA.next;
pB = pB == null ? headA : pB.next;
}
// pA==pB
return pA;
}
}