Linux程序地址空间

Tips: 之后的博客以记录笔记为主了
文章目录
- 0.前言
- 历史遗留
- 进程独立性
- 2. 地址空间是什么
- 2.1 地址空间
- 2.2 地址空间的区域划分
- 3. 页表
- 4. 为什么要有进程地址空间
0.前言
历史遗留
#include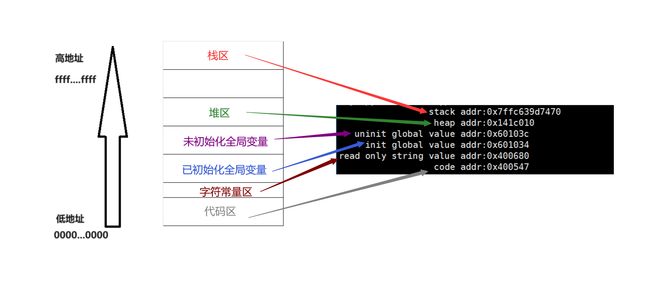
栈区的地址是高地址向低地址方向增长,堆区的地址是低地址向高地址方向增长
对于
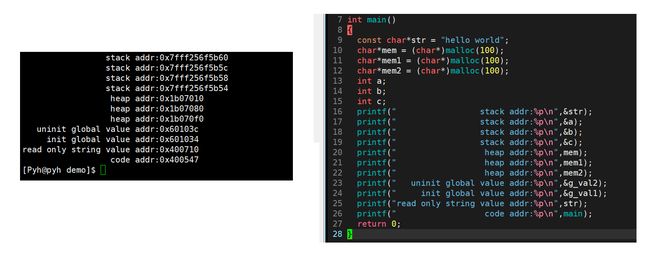
static修饰的静态变量,我们以为是是存储在栈区,其实在编译的时候,已经被编译到全局去了,所以在函数调用结束之后,并不会被释放,只不过它的作用域只是在这块函数里面(如下图验证,地址与全局数据相近)

进程独立性
接下来看这段代码
#include运行之后发现,子进程将全局的g_val修改后,并不会影响到父进程访问,但是子进程父进程访问的地址都是一样的。
这就说明他们访问的并不是直接的物理地址,这个地址叫做线性地址或者虚拟地址。
所以我们平时写的C/C++的指针,并不是物理地址

前面我们提到过,进程就是PCB+内核数据结构,但实际并没有这么简单。内核除了要创建PCB这样的结构,还要创建进程地址空间,
这些地址空间就是指向的虚拟地址,这个虚拟地址存在一张页表当中,是一个K_V结构,映射一个物理地址。
每个进程都有自己的页表,上面的子进程,拷贝了一份父进程的页表,当子进程的数据要修改的时候,就会进行写时拷贝,重新分配映射物理地址,所以这就有了_为什么这个子进程将g_val_修改之后,不影响父进程访问

2. 地址空间是什么
2.1 地址空间
在32位计算机中,有32位的地址和数据总线,CPU和内存通过总线连接起来。我们常说,计算机只认识二进制,再往深了说,计算机其实只认识高低电频,我们对内存中的寄存器进行充放电,就是数据的访问过程,由于只有高低电频,所以我们就将高电频定义为
1,低电频定义为0,这就是我们所说的二进制。然后将这些高低电频组合起来,就是向内存寻址,也就是我们的物理地址每根地址总线只有0、1,32根就是232总,寻址的单位是字节,所以这就注定了我们32位机器能够装载内存的内存空间为232 * 1byte = 4GB。
2.2 地址空间的区域划分
我们地址空间的范围是[0,232],在这个区间内,又被划分成了多个范围,例如我们的栈区、堆区什么的,通过这些区间的划分来管理好我们各个区域,我们需要什么区间的数据,直接定位在这个区间即可
struct mm_struct
{
long code_start,code_end;
long readonly_start,readonly_endl;
long heap_start,heap_end;
//...
}
3. 页表
对于页表,目前可以理解为一个映射表,每个虚拟地址都映射着自己的物理地址,另外也存储着读写的标识符rworr,这个标识符就代表着是否可以读写操作(只读常量)。
对于物理内存,并不知道是否可以读写,它没有权限这个概念,所以需要我们在中途进行标识。如果我们页表的标识符是只读,那么在中途就拦截下来了,并不会写入内存。这就是为什么有只读常量区。
我们玩的一些游戏,例如英雄联盟,下载就是十几个G,可是物理内存只有4个G或者8个G,但这个游戏还是能跑,这就能够说明,我们的操作系统对大文件,可以实现分批加载。
例如我们要加载一个500MB的空间,但我们的代码却是一行一行的执行,在短期之内并不需要这么多空间,可能只用到了10MB,那这剩余的490MB,需要全部加载到内存么?
这里我们要有一个共识,操作系统并不会做浪费时间和浪费空间的事情。
所以,这490MB,并不会全部加载到内存当中,操作系统采用的是一种惰性加载的策略。
在页表当中其实还有一个字段,这个标识符表示对应的代码和数据是否已经加载到内存当中。我们的虚拟地址都在这个也页表当中,但有些还没有给它加载到内存。当我们进行访问时,操作系统识别到页表中的这个标识符为未加载,那么在会申请一份物理内存,把这个可执行程序的代码和数据加载内存,然后把这个地址填到页表当中,这个过程叫做缺页中断,然后再进行访问就能访问了。
在进程创建的时候,一定是要先创建内核的数据结构,即对该进程维护的PCB、地址空间、页表这些对应关系处理好,然后再加载对应的可执行程序
4. 为什么要有进程地址空间
进程 = 内核数据结构(task_struct && mm_struct && 页表)+ 程序的代码和数据
-
每个进程启动时,操作系统都会给进程构建地址空间,依次来表征进程能看到的空间范围,这样就能让进程以统一的视角区看待内存结构,这样内存就不需要自己去维护了
但这其实是一个大饼,虽然能看到整个内存的空间范围,但是并不会全部给这个进程使用,例如我们C语言申请内存的时候,申请太大的时候,会申请失败
-
有了虚拟地址,这样进程访问内存的时候,会经过一个中间的转换,如果是一个非法的访问操作,在这个转换的过程中,就能对这个非法操作进行拦截,这样就能保护我们的物理内存
-
有了地址空间和页表的存在,进程的管理并不用关系内存管理,进程需要的内存,如果没有了,会自动缺页中断,操作系统调用内存管理的功能。这样就将进程管理模块和内存管理模块进行解耦。
,如果是一个非法的访问操作,在这个转换的过程中,就能对这个非法操作进行拦截,这样就能保护我们的物理内存 -
有了地址空间和页表的存在,进程的管理并不用关系内存管理,进程需要的内存,如果没有了,会自动缺页中断,操作系统调用内存管理的功能。这样就将进程管理模块和内存管理模块进行解耦。