C++内存管理
C++内存管理
第一讲 primitives 基础工具
2. 内存分配的每一层面

3. 四个层面的基本用法

#include
namespace jj01
{
void test_primitives()
{
cout << "\ntest_primitives().......... \n";
void* p1 = malloc(512); //512 bytes
free(p1);
complex<int>* p2 = new complex<int>; //one object
delete p2;
void* p3 = ::operator new(512); //512 bytes
::operator delete(p3);
//以下使用 C++ 標準庫提供的 allocators。
//其接口雖有標準規格,但實現廠商並未完全遵守;下面三者形式略異。
#ifdef _MSC_VER
//以下兩函數都是 non-static,定要通過 object 調用。以下分配 3 個 ints.
int* p4 = allocator<int>().allocate(3, (int*)0);
allocator<int>().deallocate(p4,3);
#endif
#ifdef __BORLANDC__
//以下兩函數都是 non-static,定要通過 object 調用。以下分配 5 個 ints.
int* p4 = allocator<int>().allocate(5);
allocator<int>().deallocate(p4,5);
#endif
#ifdef __GNUC__
//以下兩函數都是 static,可通過全名調用之。以下分配 512 bytes.
void* p4 = alloc::allocate(512);
alloc::deallocate(p4,512);
#endif
}
} //namespace
p3的写法和上面两种的写法是一模一样的,只是函数的名称换了
其实 ::operator new 里面就是调用 malloc、::operator delete里面就是调用free
对于allocator,根据不同的编译器,有不同的写法,根据:_MSC_VER、BORLANDC、GNUC
(分配器的接口不太一样)
/*
BORLANDC:并没有指定搞不清楚的第二参数
*/
//建立allocator对象,并且调用allocator函数
//分配 5 個 ints.
allocator<int>().allocate(5);
//注意归还的时候,不仅要把指针写进去,当初是分配了几个也要写进去
allocator<int>().deallocate(p4,5);
/*
VC:第二参数没有默认值,需要写
*/
/*
GNUC: allocator名字换了,叫做alloc
并且是按字节分配的(而不是其他单元)
*/
对于GNUC4.9版:
alloc名字也换了,和标准规格对齐了,和BORLANDC和VC的用法是一样的了
原来旧版本的alloc换了一个新的名字是:__pool_alloc
#ifdef __GNUC__
//以下兩函數都是 static,可通過全名調用之。以下分配 512 bytes.
//void* p4 = alloc::allocate(512);
//alloc::deallocate(p4,512);
//以下兩函數都是 non-static,定要通過 object 調用。以下分配 7 個 ints.
void* p4 = allocator<int>().allocate(7);
allocator<int>().deallocate((int*)p4,7);
//以下兩函數都是 non-static,定要通過 object 調用。以下分配 9 個 ints.
void* p5 = __gnu_cxx::__pool_alloc<int>().allocate(9);
__gnu_cxx::__pool_alloc<int>().deallocate((int*)p5,9);
#endif
4-6. 基本构件之一:newdelete expression

new里面包括分配空间和调用构造函数
:: operator new 是全局的函数,如果Complex没有重载operator new,那么它调用的就是全局的new
可以看到 operator new里调用的是malloc
(1) 分配空间
(2) 把指针转型
(3) 通过指针调用构造函数
在右上角的operator new函数中,如果malloc调用失败,就会调用callnewh函数(内存用光了,让来释放一些可以释放的内存)
关于它的第二个参数nothrow是保证不抛异常的

delete 会先调用析构函数,然后释放内存
operator delete 里面调用的是 free
我们吧 new delete 称作 new / delete expression
另外那个就是 operator new/ delete
Ctor & Dtor 直接调用
通过指针调用构造函数:在VC6是成功的,在GNUC下是失败的
如果真的想直接调用ctor,可以用placement new
new§ Complex(1, 2);
class A
{
public:
int id;
A() : id(0) { cout << "default ctor. this=" << this << " id=" << id << endl; }
A(int i) : id(i) { cout << "ctor. this=" << this << " id=" << id << endl; }
~A() { cout << "dtor. this=" << this << " id=" << id << endl; }
};
A* pA = new A(1); //ctor. this=000307A8 id=1
cout << pA->id << endl; //1
//通过指针调用构造函数:在VC6是成功的,在GNUC下是失败的
//! pA->A::A(3); //in VC6 : ctor. this=000307A8 id=3
//in GCC : [Error] cannot call constructor 'jj02::A::A' directly
//! A::A(5); //in VC6 : ctor. this=0013FF60 id=5
// dtor. this=0013FF60
//in GCC : [Error] cannot call constructor 'jj02::A::A' directly
// [Note] for a function-style cast, remove the redundant '::A'
cout << pA->id << endl; //in VC6 : 3
//in GCC : 1
delete pA; //dtor. this=000307A8
7. Array new

Array new,上面会建立一个cookie, 最重要的就是指明这一整块的长度
malloc 、free 是通过设置好的cookie 来沟通
注意内存泄漏是发生在类里面的,它里面的东西没有完整回收
实验:
A* buf = new A[size]; //default ctor 3 次. [0]先於[1]先於[2])
//A必須有 default ctor, 否則 [Error] no matching function for call to 'jj02::A::A()'
A* tmp = buf;
cout << "buf=" << buf << " tmp=" << tmp << endl;
//placement new 主动调用构造函数
for(int i = 0; i < size; ++i)
new (tmp++) A(i); //3次 ctor
cout << "buf=" << buf << " tmp=" << tmp << endl;
delete [] buf; //dtor three times (次序逆反, [2]先於[1]先於[0])
注意:
A* buf = new A[size]; 调用的是默认的构造函数,必须要有
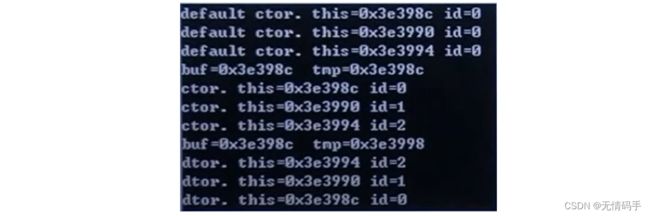
(前三个对象每个都是差4)
placement new 是主动调用构造函数:
new(指针) 构造函数() , 注意调用的前提是已经有这块内存了
注意析构的顺序(GNUC下)是由下往上析构,先析构后面的

malloc给了一整个大块
cookie分上cookie和下cookie

new一个复数类,里面有8个byte 8个字节(绿色)
调试器模式下:
上面是灰色的是一个是4 byte 8个是 32 byte 下面还会多一个灰色 4 上下的粉红色是cookie 一个是4
VC下面分配的内存一定是16的倍数,所以分配64 byte 深绿色的是填补物
cookie 后面是41 、16进制 4表示 64 、 1 表示这一块被分配出去了

三个对象,内存里那多了一个3
使用array new 和 array delete的时候,内存块的布局是不一样的,array的个数会写到内存块里
8. Replacement new

把对象放到这个已经分配好的位置上!buf
它里面已经不需要再分配内存了
可以把它称作定点New
进入之后它的operator new 其实有第二个参数,buf (已经得到的一块内存)
new里的三个步骤(1)本来是要分配内存的,结果(1)就不做事了,(2)转型, (3)调用构造函数
9. 重载

怎么样把路线2 调用全局的operator改为针对对象Foo::的
把它放到固定内存里的,(内存池)速度更快,空间上更省,去除多余的cookie嘛,一对cookie8个bytes
很少重载全局的operator new

把一个元素放到容器里,容器也要new一块空间把你给的元素copy进来
在容器里并不想用默认operator new、operator delete,用的是自己的一套,包装在construct()、destroy()。
而内存的分配和释放被拉到分配器allocate里来
重载全局的operator new/delete

1、3是重载本身版本
2、4是重载array版本
重载某类的operator new / delete

因为在用它这个函数的时候,一般来说对象还没创建出来,所以一般把这种函数声明为static
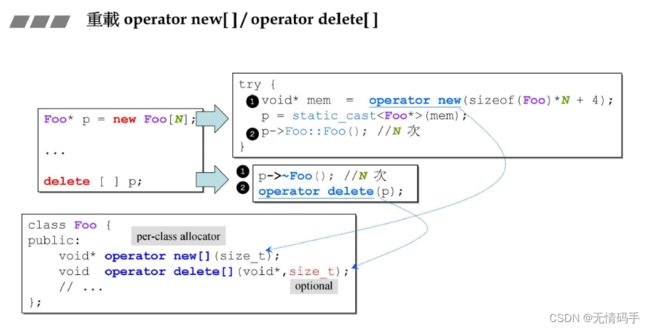
注意: new 和 new [] 调用的operator new函数是不一样的,一个是:operator new、一个是operator new[]
下面调用构造和析构的次数是由N定的
10-11.重载示例

重载operator new的时候也只是调用了malloc
(注意无论加不加[], operator new都只是调用一次,是构造函数调用的次数不同。)
注意如果这样用就会绕过所有重载的operator new / delete
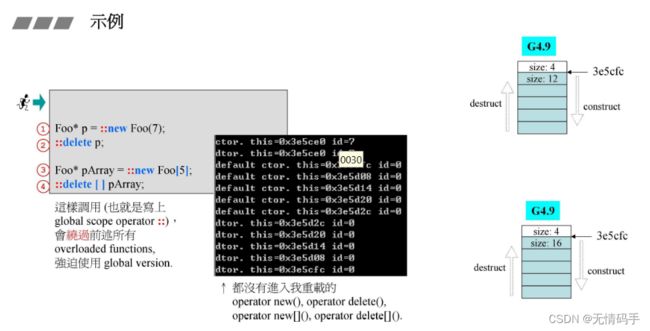
一般的operator new、array 的 operator new、placement new (new ()) 都可以重载
new() 里面不只是可以放一个指针。放指针的这个函数标准库已经写好了,还可以写多个版本

注意!重载operator new的时候,第一个参数必须是size_t,其余的参数你随意
size_t后面的参数是placement arguments,new(…)小括号里的便是placement arguments

第一个就是一般的operator new的重载
第二个就是一般所说的placement new的版本,里面有一个指针
后面是其他版本
对应四个版本的operator delete

(5)语句调用的是上一页的(3)版本
并且(5)语句它是调用了带int的ctor, 那个函数里抛出了一个异常
注意!重载的operator delete是在重载的operetor new调用完之后,如果接下来的构造函数里抛出了异常,才要让他们去释放空间的
即使operator delere(…)未能一一对应于operator new(…),也不会出现任何的报错。默认放弃处理ctor发出的异常。
basic_string使用new(extra)扩充申请量
string 就是 typedef 了 basic_string
标准库的字符串有一个reference的功能,所以它每次创建的时候都要多带出来一包东西

12. Per class allocator 1
尽管malloc可能开销不是那么大,但是当然越少越好。能否让他减少调用次数,一开始直接分好一块大的,然后一点一点的分?(同时也去除了cookie)

Screen里本身只有一个自己的成员变量i,里面还放了一个Screen* 的指针,用于指向下一个(额外的开销)
分割一大片并且当作linked list 串接起来

左边是每个对象间隔8个字节(对象本身大小)
右边是每个对象间隔16个字节(8字节的cookie)
13. Per Class allocator 2

本身5个字节(包装成8个字节)
union:同一个东西用不同的角度去看它
本来是8个字节,用指针去解释它,那看到的就是前四个字节(前四个就是用来放指针的)
(嵌入式指针 embedded pointer )
下面定义的常量是512个对象,内存池是512个
再看operator new,没有继承发生时,不会有误。
分配好后,用newBlock[i] 来每次移动8个字节
union的借用,把一个东西的前四个字节当作指针来用
operator delete: 把收回来的指针放入单向链表的头

把区块回收给自由链表,并没有free,没有还给操作系统,但是也没有泄露!都在它自己手上
把已经用完的,要回收区块,插到了自由链表上,表明说这一块是没用的了
14. static allocator
同样的东西,如果每个类都要像刚刚那样写,太繁琐了
抽取出来放到了allocator里面,
其他的类需要用内存管理时,用这个类就好了
这里面简化了使用union,而是选择使用了struct


每个class里都有专属为自己服务的一个allocator, allocator里有一条链表,专门为类来使用

这条链表是在allocator里面,它们的关系不用外面的类来管
allocate(size) 函数 返回去值的时候,就是返回了这个对应大小的空间(obj*类型的),后面我们再把它转为自己类型的就可以了。里面的关系是allocator自己的事情,我们用的这个类不用管。
allocate函数里malloc的空间是给了一个obj*, 最后返回来的也是它,它占的空间是比实际四个字节大,但是不影响它调用它的next

15. Macro for static allocator

两个macro,一个是DECLARE_POOL_ALLOC、一个是IMPLEMENT_POOL_ALLOC
对照allocator Foo::myAlloc 是在 class的外面,所以给它写一个macro
对照上面的两个方法,是在class的内部,所以给它写一个macro
写好macro后,将来要发展任何allocator,只要在class的里头写DECLARE_POOL_ALLOC,
在class的外头用IMPLEMENT_POOL_ALLOC 就可以了
用在外头的是要加类名称
四种版本
版本1:最一般的
版本2:加上了embedded pointer
版本3:把内存的动作抽取到了单一的class里,allocator
版本4:设计出一种宏出来
标准库有很多allocator,其中里面有一个很好的,它有16个自由链表,可以应付16种不一样的大小。是全局的!它可以针对所有的class

16. New Handler

当operator new 没能力分配出你所申请的memory,会抛出一个std:bad_alloc exception
在抛出异常之前,会调用一个new_handler函数,它是没有参数的
如果调用完,成功之后,就回再次分配
new_handler 是一个返回值为void, 没有参数的函数指针
new handler的两个选择:
(1)让更多memory可用
(2)调用abort或exit
typedef void (*new_handler)();
//它的返回值还是一个new_handler,可以把上次设置的new_handler返回去
new_handler set_new_handler(new_handler p)throw();


= delete 和 = default 不仅仅使用于 ctor, copy ctor, copy assignment, …还适用于 new/new[],delete/delete[]

第二讲 std::allocator
17. VC6 malloc

注意指针指向的是数据部分哦
18. VC6标准分配器之实现

我们已经知道allocator里头根本没有做任何的内存管理,只是把malloc,换一个样貌,换成allocate函数呈现出来
deallocate–>free
看右上角,注意VC里的容器的分配器都是由allocator实现的
19. BC5标准分配器之实现

Borlandc下的allocator它们的allocate、deallocate里面也是调用operator new 和 operator delete
20. G2.9下标准分配器的实现

它有注释说,不要使用这种的
发现它们的容器中确实用的不是allocator, 是alloc
但是注意哦,alloc(没有任何模版)是按bytes来分配的,不是按元素来分配的

21. G2.9 std alloc vs. __pool_alloc
原来2.9用的那个alloc,把它放到编制外了。变成了__pool_alloc

22. G4.9 __pool_alloc用例
先看4.9版的标准的allocator
还是以operator new 和 operator delete完成的(没有任何特殊设计,没有开辟一连串空间然后分配。没有这种)


它的大小是1,里面其实什么都没有,但是大小是1
接下来把分配器传给 cookie_test函数,第一个参数是Alloc对象,第二个参数是要分配的大小(分配一个,是double类型)
看上面结果(用__pool_alloc),38到40相差8个字节,40到48也是相差8个字节(一个double就是8个字节)
看下面结果(用标准分配器,是有cookie的间隔的),所以每个差16个字节
连续调用3次alloc.allocate(n)函数,在调用第一次的时候,大块的空间就已经是分配好了的。下次进的时候在链表上连好就能直接放
(一次性建立多个、或者多个一次建,都是一样的效果,链表是连起来的)
allocate(100);
for(int i = 0; i < 100; i++)
{
allocate(1);
}
23. G2.9 std alloc

4.9版和2.9版是完全一样的
原来是我们为一个类设计一个allocator,一个类一条链表
现在的alloc是有16条链表,16种大小,超过这种大小的就不为你服务了,我选择调用malloc
每条链表是差8个字节的
要6会给8,它会给到合适的范围内
比方说容器存的是32字节的,那么就是在32的那条链表里。
一次挖出来20个(切割出20个空间)
其实在实际调用的过程中,是一次挖出40个空间,但是后20个不做切割,
当下次的比方说调用的是64字节的了,那么上次的空间又被划分成了10个。七号链表的指针是指导了原来那次没划分的空间上。
现在你要放大小为96的进容器了,但是战备池已经空了(挖出来了但是没划分的)
96*20*2
deallocate 归还 并没有释放
根据回收的大小回收到负责的链表身上
这条链表是从8~128
当如果需要256大小的时候,不归它管,就调用malloc了,上下带cookie

绿色的是已经给出去了的。为什么还断了呢?因为给出去的和还回来的次序可能是不一样的
借用前四个字节当作指针,否则要多设计一个指针进去
给出去了的时候,这一部分的值就不按指针来看待了,用户要放什么就放什么,还回来的时候,我们才把它继续当指针用,去指向下一个
如果对象小于4个字节,就没法借用了。但是一般都会>=4
24-26. G2.9 std alloc 运行


分配器一般是搭配着容器一起使用
如果直接去用分配器,必须记住是要了多大。因为现在没有cookie帮助你了!
容器所有元素是一样的大小,且它的个数是在容器里记录着的。
pool为空指的是战备池
实际过程中,总是把分配到的内存先放到战备池里(两个指针夹起来的地方)。然后再从战备池里挖适当的内容出来。
32 * 20 * 2 + RoundUp(把数字调整到16的倍数) (0 >> 4) = 1280
其中640对应的20块里从中切出一个返回给客户,19个给list

allocate函数:拿出一块返回,并且把freeStore的头结点往下移
deallocate函数:

把p转成obj*后,拿出来它的next指向freeStore,并且把freeStore的头结点设成当前这个(obj*)p
对象里有个obj struct 里面存了一个 struct obj 的pointer。
我们把我们这个对象指针(首地址)拿出来转为obj *,去访问它的next

64byte的链表是空的,先看战备池,还有640个,所以切出来10个。
从战备池切出来的数量用远在1-20之间。也有可能不够切割,是碎片
下面这个图蓝色的线是说本来这两块是属于一个cookie的
绿色上面的小帽子代表cookie

96 bytes -> 战备池是0了,用malloc 开一块 96 * 20 * 2 + RoundUp( 1280 >> 4)
追加量是把目前的申请总量除以16再调到8的边界
追加量是越来越大的
申请88 ——> 第十号链表 ( 88 / 8 - 1)因为第0号是8,还有2000的战备池。
划分的时候尽量多,但是不要多于20。分完之后战备池还有240

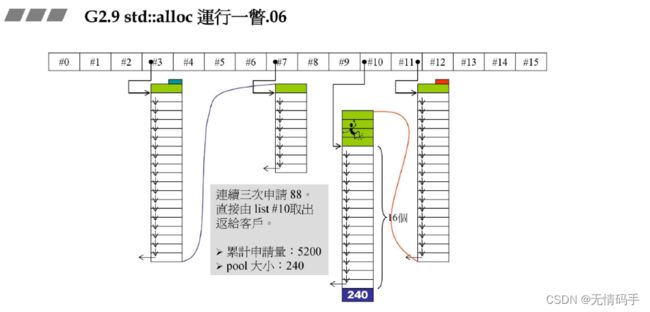
连续三次申请,一次给一个,它这里88还有很多位子
8字节从战备池申请,240分出来160 还剩 80

下面是又创建了一种容器,它的大小是104
它是空的,需要充值,但是战备池连一个都切不出来,战备池是碎片。
容量为80的碎片怎么办?
拨给第9号

104 * 20 * 2 + RoundUp(5200 >> 4)
目前累积量:9688
pool的大小:2408

申请112 -> 先看战备池 重置20个还有余 168
申请48 -> 是空的,先充值。切了三个余出来24个,下一次或许它是碎片。

heap的大小是10000
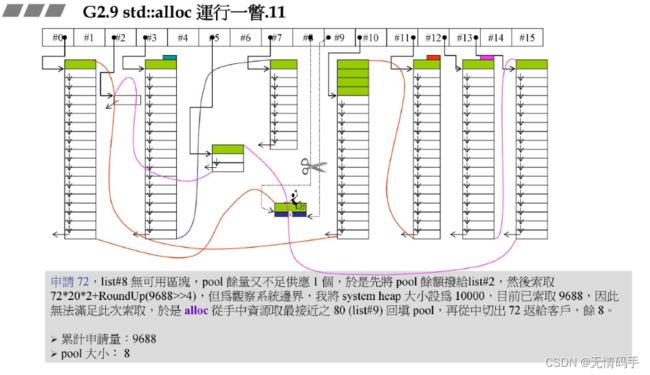
要申请8,给它充值,之前的战备池变成碎片挂在了第二号
现在追加量这么大,要再次申请,肯定已经超了,怎么办?
alloc往右边找,找最近的
之前9下面挂的是80 -> 现在给8了,那就变成了72字节+一个8字节的战备池
现在第9号变成空链表了
再申请一个8号链表的空间,找到第10号,借其中的一个,并且剩下16个作为战备池

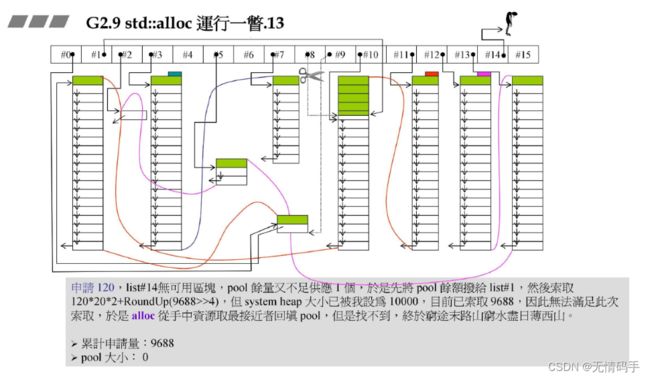
检讨:

27. G2.9 std alloc源码剖析

分配器分为2级别
第一级是次要的,malloc失败的话,第一级在模拟new_handler。整个第一级到第74行
因为alloc默认分配的单位是字节。从第77行到第89行,这一段是把字节转换为要分配的元素的个数。
先看第二级

enum 是常量 分别是定义free-list的区块边界及个数
这个class __default_alloc_template在后面重新命名为了alloc
template 第一个参数和线程有关,第二个参数没有用
ROUND_UP 上调的函数
下面是embedded pointer
下面来说,全部的function都是静态的
FREELIST_INDEX是根据区块大小帮你计算出是要放在第几条链表
下来是两根指针,指向战备池
heap_size -> 累积总量
上面是两个静态函数 refill(充值)
内存管理里有一个术语:chunk -> 一大块 block -> 一小块
allocate:
volatile -> 和线程有关

因为list的16个里面是指针,所以蓝色的my_free_list 和 free_list 必须声明为指针的指针
n > 128 -> 不服务,调用malloc
<= 128该我本人来做:
首先143行算出应该是第几号链表,然后去看它是否为空,链表如果是空,需要充值。
下面如果有可用区块,更改my_free_list里的值,把它变为result->free_list_link;(指向下一个)
对于deallocate:
回收的时候也要先判断是否大于128
如果>128 -> 用第一级去回收
<= 128 该由我本人来做
回收:把我这个指针的下一个节点指向my_free_list的头结点,并且把my_free_list的头结点设成要回收的这个
注意这里的deallocate并没有free


refill:
默认一次取20个区块
充值前需要先拿一大堆,最好是拿到20个,但是不一定

到了右边,先检查到底是拿到了几个,如果只是拿到了1个,那也不用检查,直接给用户。
如果拿到的不是一个,那就要做切割了,自由链表
把指针先转型为(obj *),再让它跨越n个位置去分割
i从1开始,因为第0个一会是要给出去了,剩下19个
!!!!!!因为已经分出去的不用连在链表里!!!!!!!!!!!
注意哦,第263行,要先把指针先转为指向字节的指针,才可以加n个字节
后面是自由链表的往下指向
chunc_alloc函数:
先看战备池尾巴减头剩下多少个字节。
如果pool满足,那么就让水位再变低

看能否大于20?能否满足一块?
都不能:-> 碎片
判断该由第几个链表回收,并把指针挂过去

碎片处理好了,把分配的结果放到start_free里
如果分配成功,给终点也设置好,战备池满了哦,然后再次调用刚刚的函数(递归)
失败了,start_free == 0 -> 找一块,放到战备池里,再次递归调用
注意,充值是永远先放到战备池里,然后再次调用
define!

第一级(4.9里已经没有了)

临时对象,是在stack里的,和分配器要了一块,有Foo本身,且作为链表有上下指针,然后做一个copy的动作。
push_back会引发copy,临时对象消失了
现在用动态分配,new出来的对象是带cookie的,把它push_back到容器中。容器向分配器发出请求,然后衔接了过来。list里的是不带cookie的

210行是非常容易让人误解的,为何不写成两行
34 行是炫技,其实就是右边的两行set_malloc_handler 接收 H 并且返回H
31. G4.9 pool allocator 进行观察
两个全局变量:
总分配量、调用次数

G4.9 里调用malloc 分配内存的地方改用了全局重载后的operator new,它记录了分配的空间和次数。

标准的分配器,没有特殊的做什么事情,每个元素都是带着cookie的
list 8(double) + 两个指针 (8) = 16
链表向分配器说一次我要16个
分配了16 百万个字节,分配了100万次
C++2.0里模版化名
listPool相当于下面那样建立list
只分配了122次,带122个cookie
左边数字为什么大于16百万?因为内部有一些管理,会多一些分配和释放
第三讲 malloc/free
32. VC6和VC10的malloc比较
SBH
SBH 是 Small Block Heap 的缩写,可见于 VC6 的源码当中,而迭代到 VC10 及之后版本,SBH机制虽继续存在,但已经整合至操作系统 API 当中去了(Windows Heap)。以下内容均以 VC6 版本为例进行展开。

为小区块服务


无论是新版的VC10还是旧版的VC6,都是调heap_init,里面都是初始化header

33. VC6内存分配(1)
heap_init(…)里面就是分配16个头 头里面是什么,还不知道。已经消耗了这些内存,内存从哪里来? 就是从和windows要的那个特殊的heap,(crtheap)
CRT : C Runtime Library

观察到的第一次内存分配:malloc_crt
看是否是debug模式:
如果没有定义 _DEBUG,那么_malloc_crt就换成了malloc
如果定义了,就改成了malloc_dbg -> 它安插了额外的另外一些东西
ininfo 4+1+1 = 6 -> 8
前面定义32个,所以256个
所有程序一进来第一块就是256个字节。(16进制100)

_malloc_dbg里又调用了 _heap_alloc_dbg (调整大小,增加debug header),它传进去的变量nSize就是刚刚的256,nNoManLandSize(大小为4)
前面是_CrtMemBlockHeader -> 给Debug用的 前两个是指针,第三个是指针,指向FileName(这一块内存是从哪个文件发出的需求)。第四个,从哪个文件的哪行发出来的。第五个记录真正的大小:100。第七个:流水号,现在是第一块。第八个:字符形成的array -> 4个字符。绿色下面也是4个字符。是数据上下的栏杆
目前空间扩大了,但是还没有分配
alloc_block -> 真正要割出去的那一块,不是你申请的大小。是你要附加的东西后的大小
_heap_alloc_dbg (调整大小,增加debug header)
然后调用_heap_alloc_base
即使这块空间已经分配给你了,但是还是要用链表串起来,要在它(SBH)的掌控之中
两个重要的指针_pFirstBlock _pLastBlock 一前一后

34. VC6内存分配(2)
memset -> 做一些特定的填充:
对于NoMansLandFill 填充 FD (有些地方已经设定了一些值了)
_heap_alloc_base

把刚刚扩充之后的大小去和threshold比较,看看如果它定义的是小,那么就让sbh去分配。那么比它大的话,就不能服务了,给操作系统。
threshold 常量 1016
小区块本来指的是1024 -> 1K,为什么是1016呢?因为这里还没有加cookie,加了cookie是加8个,所以在一开始比的时候是要和1016比。在比对通过之后才加Cookie

把分配得到的大小加上2*sizeof(int) -> cookie的大小,下面的奇怪的动作是做RoundUp,调整到16的倍数
第一次_ioinit分配进来的 100h -> 256字节 (32 * 8)
然后加上下两块给调试器用的 35bytes 24h
_heap_alloc_dbg 调整大小
再加上下cookie -> 0x130
为什么cookie里写的是131?
因为这一块将来是要给出去的,它既然是16的倍数,所以它用二进制看后四位一定是0,也就是说十六进制最后是0,那用最后一个位表示它是不是给出去了
到现在为止只是在计算区块的大小,还没分配到内存,更别提设置值
借出去了最后就是1,将来把这一块还给SBH,就变成了0
35. VC6内存分配

ssh_alloc_new_region()
每个Header里负责管理的1Mega内存。1M 1000千字节
tagRegion里有:
-
一个整数
-
64个char
-
and 4. 都是unsigned integer 32组,每组是64个bit(管理哪些区块 On/OFF)
-
数组,每个都是一个Group
Group里首先有一个int,接下来有64个listHead(双向链表)
Header将来分内存都是从它申请的1mega里面分,为了对它做管理,又使用了Region
为了很好的管理1M,它的成本是16K
36. VC6内存分配(4)

用new_group管理
1M/32 -> 每个group 32 K,在计算机中往往把4K叫做一个page (8个 page)

Group里有64条链表,把page的指针给最后一条链表
一开始的1M是一个虚的,只有号码牌存在
这8块是连在一起的,一次性和操作系统要的,把偏移值设为-1(作为篱笆阻隔器用)
4080是记录了两个黄色中间的大小(一大块是4096,上下两块一共是8,那中间两块是4088,但是4088不是16的倍数->拿出来一部分做保留,真正可以用的是4080)
任何一个BLOCK,都要带上下COOKIE

一个Group有64个ListHead -> 两根指针,每根指针指向一个Entry

从图中看,为什么ListHead里的两根指针都是往上画呢?
指针指出去,指的是三格的东西,可是它自己只有64对指针,它借用了上面的

注意指针从Next出来指向3格的,然后最后指回去的时候是指向Next的上一个,借用它的上一个(只是借用,但是不会破坏)
(以上8块是交由最后一个链表把它串起来)
37. VC6内存分配(5)
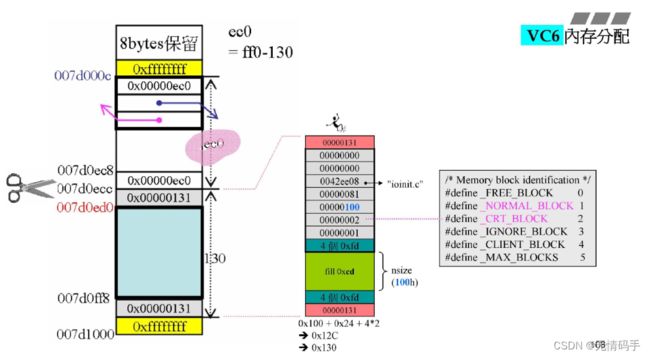
最后一跳链表:凡是大于1K的都归他管
一刀切下去,ioinit,拉出来256,加上cookie, 加上debuger,调整了边界后是 130(十六进制)
4080是ff0
减去后是ec0,系统吧cookie的指针给出去(红色的),同时,上面的cookie也缩小了
切割:指针的调整 + 把 cookie 传出去

把指针return的过程中,指针被调整到了绿色的部分交给用户使用

由ioinit的81行发出的请求
100表示浅绿色部分(客户要的大小)
2表示 _CRT_BLOCK

在main() 进入前内存分配好,在离开main之后,这部分内存还没死掉,是在exit后才放掉的。在放掉之前是2号_CRT_BLOCK状态,它不是内存泄漏,如果是1号 _NORMAL_BLOK状态,才是内存泄漏
每条链表间隔是16(类比GNU中的alloc链表间隔8)
容量/16 -1 -> 落到第几号链表
free的时候,比方说130 -> 落到第18号链表,第18号链表把指针拉过来指向这块区域
38. SBH行为分析 分配+释放之连续动作图解(1)

(1)VirtualAlloc分配地址空间,参数0的意思是,你可以在任意地方分配。1M -> 大小,MEM_RESERVE是说保留,现在只需要有号码牌,不需要有真正的地址空间**(从海量的地址空间里拿)**
(2)Header里的另外一根指针分配出Region,利用HeapAlloc,拿的大小是sizeof(Region)(从前面建立起的crtheap里面拿,它的大小是4096,不够了会自动扩充)
(3)Region里得到了一堆东西,包括32个Group,每个Group 64对指针
(4)从1M里真正地给我32K的内存吧(下面的31*32K还是虚的),32个32K,对应32个Group
(5)32K切割成更小的单元,每个4K共8个,放大看就是下面那样,串起来后最后再串回64个链表里的最后一对,小的每个里面的有效的是4080(比1K大)最后一条链表,1K以上的通通归他管
(6)8小块是怎么要到的呢? 是VirtualAlloc,在addr地址(1M的第一块),申请32Kb, 并且是MEM_COMMIT,是真正的要,不是假要
(7)拿出大小为130的,给出去到外面,变成蓝色了
(8)客户真正要的是100h,指针指向它,给到客户,100h的上下都被填入了fdfdfdfd,如果客户刻意往下写,被破坏了,debugger就会给出警告

上面的指针,特殊设计,没有使用的时候,指针都指向自己

64个bits,标明哪条链表有挂区块,现在只有最后一个是1
(共32组,每一横条64个bit)

第二次,切240 -> 由第N号链表来处理,这一号链表的那一个位置是0,是空的。
就只能由比它大的来处理,切割。
现在切割后,ec0-240 -> c80
注意64条链表前面是由一个整数的,标明了使用情况,现在是有两块要了内存空间,就是2(累积量)
释放了,就-1,变成0->全部收回来 八大块也都收了回来还给操作系统
Region里也有一个int值,标明group的使用情况:目前正在用哪个Group,目前是正在用0
第三次切割 70h先检查它由第几条链表提供服务是好的。检查发现,那条链表对应的bit是0,找更大的,就找到了最后一条链表,并且切了70,上面cookie变成c10

注意这里用的是嵌入式指针,每一块的头的地方是当作两根指针。客户拿到后可能盖掉指针,但是没关系,收回来后我继续当指针。
39. SBH行为分析 分配+释放之连续动作图解(2)

第十五次:释放,先前14次,减1,省13
要还240这部分,把它给第35号链表。怎么回收?把cookie的241改成240就是回收。回收之后要挂回到链表当中(嵌入式指针),拉到第35号链表,把35号链表的bit置为1
目前是有两条链表再用。注意要counter-1
40. SBH行为分析 分配+释放之连续动作图解(3)

想分配b0h,发现对应链表bit是0,但是后面35号链表有一块。所以由它来提供
从刚刚的240里面切出来一点给到b0,现在剩下190,它现在是比较小的了, 把它移动,挂在第24个链表

第n次,上一个Group的状态是有3个1(三个链表上挂着区块),最后一个链表的bit变成0了,回收了
现在再来一个230,但是上一个Group无法满足了,所以开下一个Group
41. SBH行为分析 分配+释放之连续动作图解(4)
合并:回收的是相邻的时候,是应该有合并的动作

灰色即将变成白色,上下两块也是白色,应该要合并起来。
(不一定是要一样大,任意大小都可以)
为什么要有上下两个cookie?原来以为是累赘,其实是很好用的,呵呵
注意看弓箭的地方,往上四个字节就是自己的cookie,加上自己的长度300,就落到了下一块的起点,也就是它的cookie,看它的末尾是不是0
合并好后,指针往上四个字节是自己的cookie,然后再往上四个字节是上一个人的下cookie,没有下cookie,就没办法往上合并
最后合并好后,链接到要挂的链表上。
42. VC6内存管理free(上)

要知道先落在哪一个1Mega,再知道是哪一个Group,再看是哪个free-list
Header: SBH看你的p是否在这个1Mega的头和尾巴这个范围内,判断是不是在这个Header下。
Group是从哪里找?把p的地址减去1Mega的头/32K,看看是落在哪个Group
free-list? 通过指针往上走一个,看到cookie,然后去/16 -1
43. VC6内存管理总结(上)
以上都是分段管理,一个段是32K
全部回收后,又变成8大块,并且连在最后一个指针上,但是他们没有合并,因为块与块之间有-1
为什么没有合并呢?因为没有着急还回去
延缓全回收的释放动作

指针先指向一个全回收group所属的Header。当有第二个全回收出现时,SBH才会释放这个Defer group
如果尚未出现第二个全回收,用户又要地方,那么就取出它从Defer group里
指针是指向header的,里面的__sbh_indGroupDefer是索引
44. VC6内存管理总结(下)
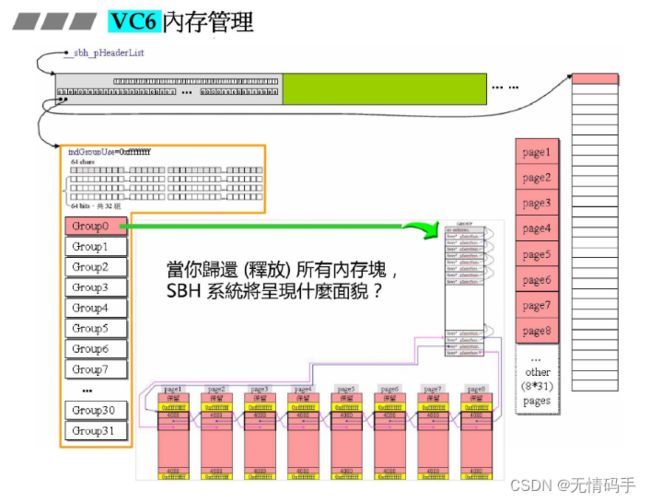

分配器最终要内存还是要和malloc要。malloc其实里面已经够快了,其实分配器做那么多管理,不是为了提升速度。目的是为了去除cookie
分配器的缺点:不愿意还
第四讲 loki::allocator
45. 上中下三个classes分析
Loki allocator 里面有三个类
注意这三个类的层级关系

Chunk -> 分配比较大的一块
sunsigned char 一个byte
first… :第一个可用区块在哪里
blockAvailable: 目前还有几块可供应
46. Loki allocator行为图解

Chunk 的 Init 里创建了unsigned char 数组,大小是区块大小乘以区块个数
Rew 完之后调用Reset,用那三格去管理上面那一大块
现在指针是指向创建好的空间的头部的,现在里面可以切64个,第一个最优先要给出去的是0
接下来就是借前面一个byte来当索引来用**(有点像嵌入式指针)**
Release的时候要delete
三个类每一个类都有一个Allocate和Deallocate

优先给出去第四号。经过一次分配之后,次高优先权的变成最高优先权了
pResult是返回首指针 + firstAvaiableBlock_(不是指针是索引) * blockSize
(里面前面的数字是它下一个要访问的第几块,注意最前面的是第0块)
Chunk是FixedAllocator的Inner class,这个函数前面加了两个域名,是Chunk类只为FixedAllocator服务
要找是来自哪个Chunk的,也是要从头指针位置+长度来判断这个p是在哪个Chunk里面

确认是落在哪个Chunk之后才会进入Deallocate()
(用指针减去头) / blocksize,看是第几块。它是第几块,就把它当作接下来的最高优先权(有点像单向链表)
所以4变成了最高优先权,那原来的最高优先权变成了次高优先权,放在了p的第一个unsigned char里

47. class FixedAllocator分析(上)
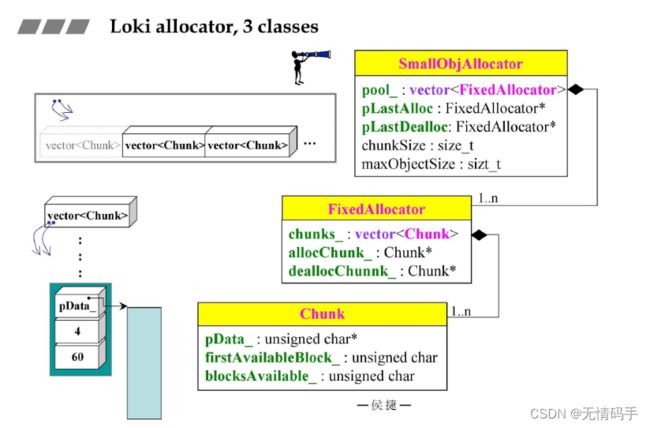
FixedAllocator里有两根指针指向Vector里的两个Chunk
两根指针用于标出最近一次分配出去的Chunk,第327个Chunk刚刚分配了一块出去,下一次还用你给
deallocChunk -> 刚刚就是从你这里回收的,看看这次还是不是由你回收了(当然可以用头夹尾的方法)

如果是初始状态或者已经用光
用迭代器找,如果不是尾巴,看他有没有可用空间,如果有,就先标识allocChunk
最后用刚刚标识出的Chunk去调用allocate
先对迭代器取值,*i 取到Chunk,然后再取地址 &*i
到达尾端了,还没找到,建立新的chunk
对vector使用push_back,可能引发vector的搬动,过去存在的那些迭代器iterator就都失效了
所以dealloc要重设,只好把它设成头
48. class FixedAllocator分析(下)
Deallocate,先找到是哪一个Chunk,然后就好办了,交给下一级的chunk去做即可
把找到的结果给了deallocate_Chunk,然后去回收p

Vicinity Find
chunks_是vector的名字,front是取出第一个chunk , back() 是最后
循环里面兵分两路,往上找一个,往下找一个,这样找
检查的时候是夹杀
DoDeallocate

进来直接调用Chunk的Deallocate
回收了之后要判断是不是全回收,如果等于先前登记了。和之前malloc一样,有Defer,有两个了才是会release
延缓
最高级的是很多个vector
49. Loki allocator总结

什么简单的方式?可用区块还有几个
和malloc一样,是有一个counter在记录
它使用了vector,vector背后是std allocator,不是loki,代码里同时用了两个分配器!没有蛋生鸡,鸡生蛋的问题
第五讲 other issues
50. GNU C++对allocators的描述


不是在std下,是在__gnu_cxx下
上面好一点,::operator new里面可以重载

内存加以缓存 -> 内存池:
fixed-size: pooling cache (16条链表)
bitmap index
__mt_alloc -> 多线程的
我们面对的是子类

debug_allocator在分配器的基础上包了一些申请量(表明这一块多大),它自己是不做事情的
array_allocator 分配已知且固定大小的内存块 内存来自array**(一开始就知道要多少元素,没有必要由小到大的成长)**
只有这一块的是用底部静态的数组实现的
其他的都是动态的用malloc / operator new 实现的
51. VS2013标准分配器&G4 9标准分配器与new allocator以及G4 9malloc
allocator是在《…\memeory》
它里allocate有两个,下面的调用上面的,其实它就是最普通的,里面调用了operator new

第一种:new_allocator
GNU4.9下allocator继承自new_allocator
它也是最普通的allocator,里面用到的是operator new

第二种:malloc_allocator
它里面主要做的是malloc和free

52. G4 9array allocator
第三种 array_allocator
array_type 是 _Array 后面模版定义为它是array容器
_M_array 是一根指针,它指向这样一个容器

由于它是一个c++的数组,它是静态的,它不需要释放
如果你调用它的deallocate 是父类的,里面什么都没做

调用构造函数,注意声明的那个容器的类型,大小要和上面的一样。
指针被保存在了_M_array里面
下面的两个allocate表示要分配的两次一个是要1个,一个是要3个
deallocate是什么都没有做的,如果真的要说有用的话,应该把指针往后退回来换回来,才是有用的。
这样就变成一个小型内存池。
下面这个是在创建的时候,是用new的方法new出来的,其他的和上面是一样的
(上面第一种是用C++静态的数组、第二种是用C++动态分配出来的array数组,是一样的)

53. G4 9 debug allocator
第四种:G4 9 debug allocator
它有一个模版参数allocator,它把另一个allocator包进来
_M_extra 表示是额外的大小 ,它在构造函数里会计算出来
__obj_size -> 一个元素大小
sizeof(size_type) -> 绝大多数系统下都是4
最后返回 (sizeof(size_type) + __obj_size-1) / __obj_size -> 额外的这个大小会占一个元素的大小吗?
比方说额外的大小是4,一个元素大小是4 (4+3) / 4 -> 占1个

在allocate的时候,回吧_M_extra放进去。但是需要注意的是,它是隐身在幕后的,返回指针的时候,要跳过它
在deallocate的时候,要退回去,再回收
第五种:pool_allocator


记得用的时候要用全名

54.bitmap allocator 上
第六种 bitmap

它里面继承了free_list

它一次性地挖64个blocks来供应
没一个block需要一个bit来控制,所以这里前面还有两个unsigned int(共64位)。
1表示在手中,0表示给出去,所以现在是FFFFFFFF。
再往前面use count -> 用掉几个了
再往前面,记录这个super-blocks的大小
两个指针来操纵super-block,指向头和尾(这两个指针放在一个单元里),再来一个super-block,就再来一个单元
_M_start是指向__mini_vector的头,_M_finish是表示走到哪里了 end_of_storage是__mini_vector的尾
分配了格子出去



换了1个

用完之后,再次申请super-block, block大小扩大1倍
第一个单元头尾两个指针指向的还是它

此时的__mini_vector成长了,且是两倍成长的

55. bitmap allocator(下)

用一个free_list(mini_vector)指向super-block表示回收了
这个mini_vector的每个元素是一个指针。
所以是有两个mini_vector,一个是登记回收的,一个是登记分配的
1st super-block 全回收,登录到另一个vector,下一次分配规模减半。现在是分配到256,下次再分配是128
这个free-list是最多64个元素
全回收后,mini_vector里那个元素的指针都打断了
注意上面图片的Q&A

新进的时候,如果已经 > 64,就用delete 放掉那个最大的super-block

现在三个都free了,现在又要一个block,不是分配第四个superblock,而是把三个里的其中一个挂回来再去分配
分配器的使用(注意头文件和分配器前的域名)


56. 谈谈Const
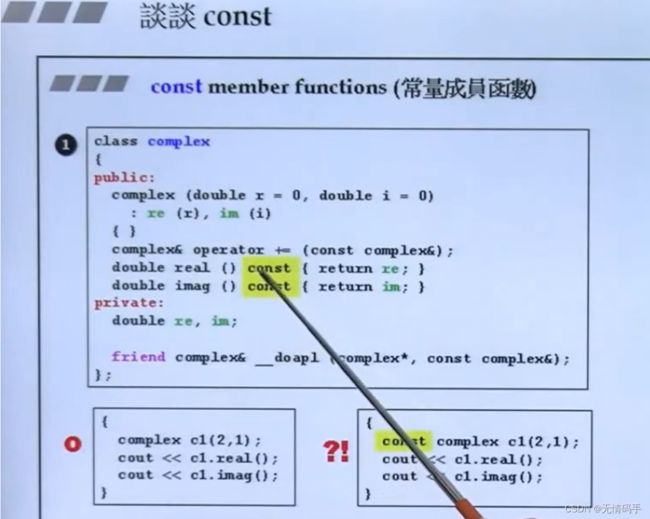
放在成员函数后面,不能放在全局函数后面。放了const之后表明,不打算改变成员的数据

常量对象调用非常量函数,错误
右边两个函数重载,不需要考虑函数返回值,是要看返回值后的签名(const 也属于签名的一部分)
这里为什么要设计两个呢?
[]可以用来写,s[5] = “a”; operator[] 可能用来改变数据
所以必须要做Copy On Write, ABCD四个人共享。A要改动时,A先复制出来一份,在上面做修改,不能影响了BCD
常量不必考虑COW,其余的需要考虑
常量对象只会const函数,不影响
当const和non-const版本同时存在,常量obj只能调用const版本,非常量obj只能调用非常量版本
57-59. new delete示例 接口

在GNUC下调用 operator new 的时候,它的大小是sizeof(size) * N + 4 (4是一个counter,用于记录有多少个)




60. Basic String 使用new (extra) 扩充申请量

想要无声无息,不知不觉的多分配一些东西