MySQL进阶(日志)——MySQL的日志 & bin log (归档日志) & 事务日志redo log(重做日志) & undo log(回滚日志)

前言
MySQL最为最流行的开源数据库,其重要性不言而喻,也是大多数程序员接触的第一款数据库,深入认识和理解MySQL也比较重要。
本篇博客阐述MySQL的日志,介绍重要的bin log (归档日志) 、 事务日志redo log(重做日志) 、 undo log(回滚日志)。
本系列文章合集如下:
【合集】MySQL的入门进阶强化——从 普通人 到 超级赛亚人 的 华丽转身

目录
- 前言
- 引出
- 一、MySQL日志分类
- 二、Redo Log
-
- 1. redo log重做日志的组成
- 2. 刷盘的时机
- 三、undo log (事务回滚)
- 四、Bin log
-
- 两阶段提交
- 为什么需要两阶段提交?
- MySQL主从复制
- 总结
引出
1.二进制日志bin log (归档日志) 和 事务日志redo log(重做日志) 和 undo log(回滚日志);
2.bin log用于备份恢复、主从复制;redo log用于掉电等故障恢复;
3.redo log一旦提交意味着持久化了,但是有时候需要对其进行rollback操作,那就需要undo log;
4.主从:写数据时只写主库,在读数据时只读从库,这样即使写请求会锁表或者锁记录,也不会影响读请求的执行;
一、MySQL日志分类
MySQL日志主要包括错误日志、查询日志、慢查询日志、事务日志、二进制日志几大类。其中,比较重要的还要属二进制日志binlog (归档日志) 和 事务日志redo log(重做日志) 和 undo log(回滚日志)。
MySQL日志主要包括七种:
- 1.重做日志(redo log)
- 2.回滚日志(undo log)
- 3.归档日志(bin log)
- 4.错误日志(error log)
- 5.慢查询日志(slow query log)
- 6.一般查询日志(general log)
- 7.中继日志(relay log)
二、Redo Log
redo log(重做日志)是nnoDB存储引擎独有的,它让MySQL拥有了崩溃恢复能力。比如MySQL实例挂了或宕机了,重启时,InnoDB存储引擎会使用redo log恢复数据
(1)redo log是物理日志,纪录页的物理修改操作
- 记录的是在某个数据页做了什么修改,比如对x表空间中的N数据页ZZZ偏移量的地方做了AAA更新:
(2)保证数据的持久性
- 持久性,redo log会在事务提交时将日志存储到磁盘redo log file,保证日志的持久性。同时mysql会将数据写入磁盘,保证数据的持久性。
1. redo log重做日志的组成
-
一是内存中的重做日志缓存,叫做redo log buffer
-
二是重做日志文件,叫做redo log file
MySQL中数据是以页为单位,你查询一条记录,会从硬盘把一页的数据加载出来,加载出来的数据叫数据页,会放入到Buffer Pool中。后续的查询都是先从Buffer Pool中找,没有命中再去硬盘加载,减少硬盘IO开销,提升性能。
更新表数据的时候,也是如此,发现Buffer Pool里存在要更新的数据,就直接在Buffer Pool里更新。然后会把在某个数据页上做了什么修改记录到重做日志缓存(redo log buffer)里,接着刷盘到redo log文件里。同时,InnoDB引擎会在适当的时候,将这个操作记录更新到磁盘里面。
redo log的更新流程如下,以一次update操作为例

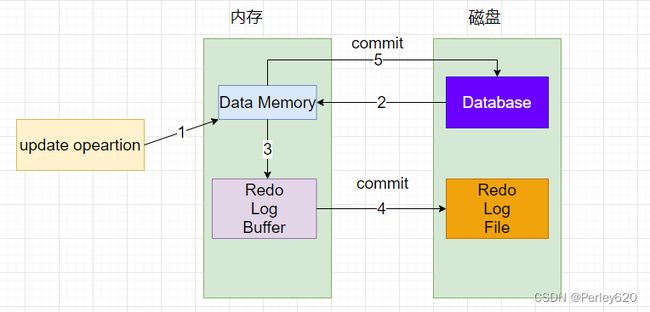
(1)执行Update操作
(2)先将原始数据读从磁盘读取到内存,修改内存中的数据。
(3)生成一条重做日志写入redo log buffer ,纪录数据被修改后的值。
(4)当事物提交时,需要将redo log buffer中的内容刷新到redo log file。
(5)事物提交后,也会将内存中修改的数据写入到磁盘。
为什么需要写Redo Log Buffer 和 Redo Log Flle?
为什么需要写Redo Log Buffer 和 Redo Log Flle?而不是直接持久化到磁盘?
直接写磁盘会有产生严重的性能问题:
(1)InnoDB在磁盘中存储的基本单元是页,可能本次修改只变更一页中几个字节,但是需要刷新整页的数据,就很浪费资源。
(2)一个事务可能修改了多页中的数据,页之间又是不连续的,就会产生随机IO,性能更差。
这种方案叫做WAL(Write-Ahead Logging),预写日志,就是先写日志,再写磁盘.
2. 刷盘的时机
InnoDB存储引擎为redo log的刷盘策略提供了innodb-f1ush_log-at_-trX-commit参数,它支持三种策略:
(1) 0(延迟写) :表示每次事务提交时都只是把redo log留在redo log buffer中,开启一个后台线程,每1s刷新一次到磁盘中;
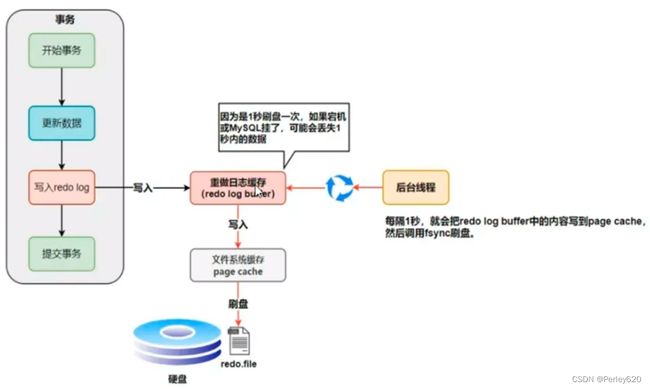
(2)1(实时写,实时刷):表示每次事务提交时都将redo log直接持久化到磁盘,真正保证数据的持久性(默认值);

刷盘的时机为1时,只要事务提交成功,redo log记录就一定在硬盘里,不会有任何数据丢失
如果事务执行期间MySQL挂了或宕机,这部分日志丢了,但是事务并没有提交,所以日志丢了也不会有损失。
(3)2(实时写,延迟刷):表示每次事务提交时都只是把 redo log 写到 page cache,每秒刷一次到磁盘(速度快,但是会丢1s的数据,甚至更多,1s并不严格)

三、undo log (事务回滚)
redo log一旦提交意味着持久化了,但是有时候需要对其进行rollback操作,那就需要undo log。
undo log是逻辑日志,只是将数据库逻辑的恢复到原来的样子。并不能将数据库物理地恢复到执行语句或者事务之前的样子。虽然所有的逻辑修改均被取消了,但是数据结构和页本身在回滚前后可能不一样了。
既然是逻辑日志,可以理解为它存储的是SQL, 在事务中使用的每一条 INSERT 都对应了一条 DELETE,每一条 UPDATE 也都对应一条相反的 UPDATE 语句。

undo log实现了事务的一致性,是通过undo log恢复到事务之前的逻辑状态,保证一致性。
在事务没提交之前,MySQL会先记录更新前的数据到undo log日志文件里面,当事务回滚时,可以利用undo log来进行回滚。如下图:

Undo Logi通过两个隐藏列tx_id(最近一次提交事务的ID)和roll_pointer(上个版本的地址),建立一个版本链,实现回滚到上一个版本。

四、Bin log
bin log用于备份恢复、主从复制;
redo log用于掉电等故障恢复。
(1) 如果不小心整个数据库的数据被删除了,能使用redo log文件恢复数据吗?
不可以使用redo log文件恢复,只能使用binlog文件恢复。
因为redo log文件是循环写,是会边写边擦除日志的,只记录未被刷入磁盘的数据的物理日志,已经刷入磁盘的数据都会从redo log文件里擦除。
binlog文件保存的是全量的日志,也就是保存了所有数据变更的情况,理论上只要记录在binlog上的数据,都可以恢复,所以如果不小心整个数据库的数据被删除了,得用binlog文件恢复数据。
(2) MySQL在完成一条更新操作后,Server.层会生成一条binlog,Bin Log也是采用WL模式,先写日志,再写磁盘。
事务执行过程中,先把日志写到binlog cache,事务提交的时候,再把binlogcache写到binlog文件中。
因为一个事务的binlog?不能被拆开,无论这个事务多大,也要确保一次性写入,所以系统会给每个线程分配一块内存作为binlog cache。
至于什么时候刷新到磁盘,可以sync_binlog配置参数指定。
- 0(延迟写)每次提交事务都不会刷盘,由系统自己决定什么时候刷盘,可能会丢失数据。
- 1(实时写)每次提交事务,都会刷盘,性能较差。
- N(延迟写)提交N个事务后,才会刷盘。
加入写Bin Log 后的事务流程
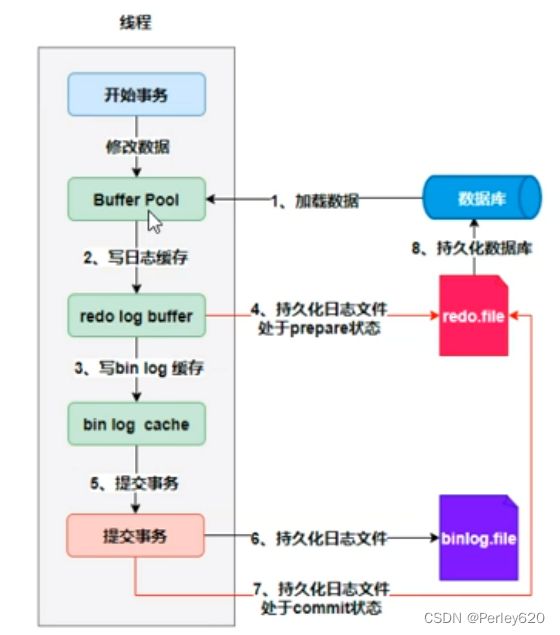
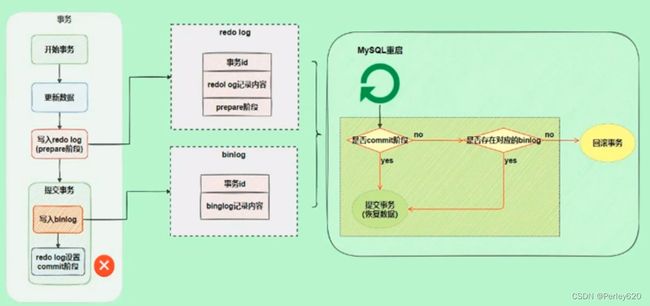
加入写Bin Log.之后的事务流程,先写处于prepare状态的Redo Log,事务提交后,再写处于commit状态的Redo Log,这就是二阶段提交的概念。
两阶段提交
redo log(重做日志)让 InnoDB 存储引擎拥有了崩溃恢复能力。
bin log(归档日志)保证了MySQL集群架构的数据一致性。
bin log是MySQL Server提供的一种日志,叫做归档日志,所有引擎都可以使用bin log。
redo log是 InnoDB 引擎特有的。
redo log主要记录的是某个数据页做了什么修改,bin log记录的是语句的原始逻辑,比如更新了某一行的某个字段。
redo log是循环写的,数据会被覆盖。bin log是追加写,一个文件写满,就写下一个文件。
两者是如何配合完成两阶段提交的。
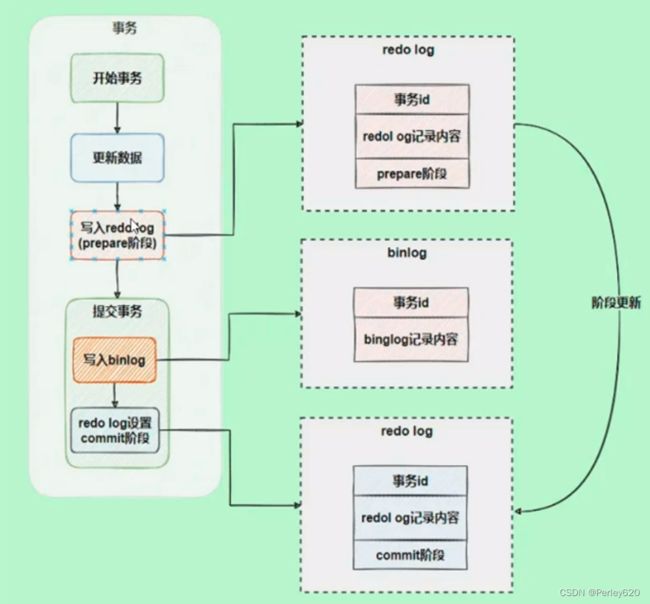
从上图中可以看出,在最后提交事务的时候,有3个步骤:
1.写入redo log,处于prepare状态。
2.写bin log。
3.修改redo log状态变为commit。
先写处于prepare状态的Redo Log,事务提交后,再写处于commit状态的Redo Log。由于redo log的提交分为prepare和commit两个阶段,所以称之为两阶段提交。
为什么需要两阶段提交?
(1) redo log与bin log两份日志之间的逻辑不一致,会出现什么问题?
以updatei语句为例,假设id=2的记录,字段c值是0,把字段c值更新成1,SQL语句为update T set c=1 where id=2。假设执行过程中写完redo log日志后,binlog日志写期间发生了异常,会出现什么情况呢?由于binlog没写完就异常,这时候binlog里面没有对应的修改记录。因此,之后用binlog日志恢复数据时,就会少这一次更新,恢复出来的这一行c值是0,而原库因为redo log日志恢复,这一行c值是1,最终数据不一致。
为了解决两份日志之间的逻辑一致问题,InnoDB存储引擎使用两阶段提交方案。
(2)使用两阶段提交后,写入bin log时发生异常也不会有影响,因为MySQL根据redo log日志恢复数据时,发现redo log还处于prepare阶段,并且没有对应bin log日志,就会回滚该事务。
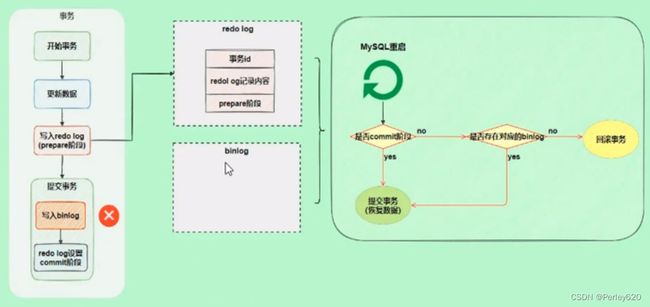
(3)再看一个场景,redo log设置commit阶段发生异常,那会不会回滚事务呢?
并不会回滚事务,虽然redo log是处于prepare 阶段,但是能通过事务id找到对应的bin log日志,所以MySQL认为是完整的,就会提交事务恢复数据。
MySQL主从复制
MySQL的主从复制依赖于bin log,也就是记录MySQL上的所有变化并以二进制形式保存在磁盘上。复制的过程就是将bin log中的数据从主库传输到从库上。
这个过程一般是异步的,也就是主库上执行事务操作的线程不会等待复制binlog的线程同步完成。
MySQL集群的主从复制过程梳理成3个阶段:
- 写入Bin log:主库写bin log日志,提交事务,并更新本地存储数据,
- 同步Bin log:把bin log复制到所有从库上,每个从库把bin log写到暂存日志中。
- 回放Bin log:回放bin log,并更新存储引擎中的数据。

具体详细过程如下:
- MySQL主库在收到客户端提交事务的请求之后,会先写入bin log,再提交事务,更新存储引擎中的数据,事务提交完成后,返回给客户端“操作成功的响应。
- 从库会创建一个专门的/o线程,连接主库的log dump线程,来接收主库的bin log日志,再把bin log信息写入relay log的中继日志里,再返回给主库“复制成功的响应
- 从库会创建一个用于回放bin log的线程,去读relay log中继日志,然后回放bin log更新存储引擎中的数据最终实现主从的数据一致性。
在完成主从复制之后,你就可以在写数据时只写主库,在读数据时只读从库,这样即使写请求会锁表或者锁记录,也不会影响读请求的执行。
从库数量增加,从库连接上来的/O线程也比较多,主库也要创建同样多的log dump线程来处理复制的请求,对主库资源消耗比较高,同时还受限于主库的网络带宽。
所以在实际使用中,一个主库一般跟2~3个从库(1套数据库,1主2从1备主),这就是一主多从的MySQL集群结构。
总结
1.二进制日志bin log (归档日志) 和 事务日志redo log(重做日志) 和 undo log(回滚日志);
2.bin log用于备份恢复、主从复制;redo log用于掉电等故障恢复;
3.redo log一旦提交意味着持久化了,但是有时候需要对其进行rollback操作,那就需要undo log;
4.主从:写数据时只写主库,在读数据时只读从库,这样即使写请求会锁表或者锁记录,也不会影响读请求的执行;