Python爬虫2--数据解析方法:bs4库的使用和案例
目录标题
-
- 数据解析
-
- 1、BeautifulSoup库
-
- 1.1 BeautifulSoup库入门
-
- 1.1.1 BeautifulSoup类的基本元素:
- 1.1.2 基于bs4库的HTML内容遍历方法
- 1.1.3 基于bs4库的HTML格式化和编码
- 1.2 信息组织和提取方法
-
- 1.2.1 信息标记的三种形式:xml,json,yaml
- 1.2.2 三种信息标记形式的比较
- 1.2.3 信息提取的一般方法
- 1.3 bs4解析
- 2、bs库案例:
-
- 2.1 中国大学排名爬虫
数据解析
聚焦爬虫:爬取页面中指定的页面内容
数据解析分类:正则、bs4、xpath(重点)
数据解析原理:
- 进行指定标签的定位
- 标签或者标签对应属性中存储数据值的提取
1、BeautifulSoup库
1.1 BeautifulSoup库入门
Beautiful soup库:能够对html 或xml进行解析,并提取其中的信息
安装:pip install beautifulsoup4
查看源代码:
法1,手动右击,获取源代码
法2,用request库获取
import requests
r = requests.get("http://python123.io/ws/demo.html")
r.text#即显示源代码
demo = r.text
from bs4 import BeautifulSoup
soup = BeautifulSoup(demo,"html.parser")#进行熬汤
print(soup.prettify()) #成功打印,即解析正确
BeautifulSoup的使用:
两个参数:第一个html格式的信息,第二个解析器

BeautifulSoup是解析、遍历、维护“标签树”的功能库
四种解析类:

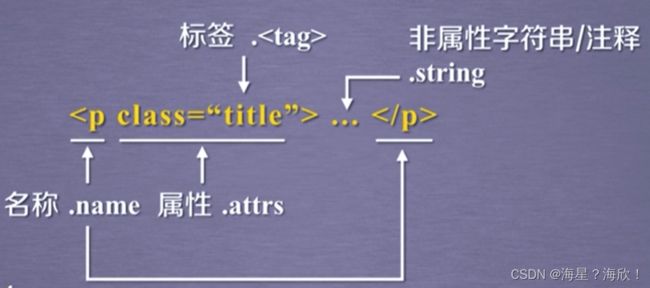
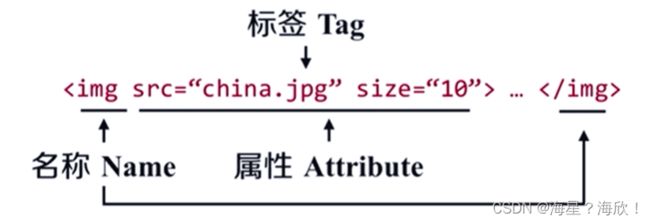
1.1.1 BeautifulSoup类的基本元素:

应用:
from bs4 import BeautifulSoup
r = requests.get("http://python123.io/ws/demo.html")
r.text#即显示源代码
demo = r.text
soup = BeautifulSoup(demo,"html.parser")#解析后的内容
soup.title #标签内容,左上方内容
tag = soup.a #a标签即链接标签的内容
print(tag)
soup.a.name #获取标签名字
soup.a.parent.name #获取父标签名字
tag.attrs #标签a的属性,打印出一个字典
tag.attrs['class'] #a属性中class的值
type(tag.attrs) #标签属性的类型--字典
type(tag) #标签的类型---bs4中类型
soup.a.string #a标签的字符串信息
type(soup.a.string) #字符串类型---bs4中类型
sooup.a----获得a标签
a.name—获得标签a的名字
a.sttrs—获得标签属性,返回一个字符串
a.string --标签的字符串
a.comment–可能有注释信息
1.1.2 基于bs4库的HTML内容遍历方法
html信息:

将html换成树形结构:

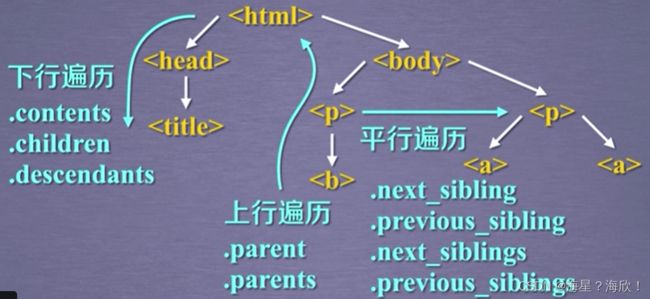
三种遍历方式:下行遍历、上行遍历、平行遍历
标签树的下行遍历:

content返回列表,其他两个都是迭代类型,需要用在循环中
soup = BeautifulSoup(demo,"html.parser")
soup.head
soup.head.contents #输出是列表类型
soup.body.contents
len(soup.body.contents)
标签树的上行遍历:

soup = BeautifulSoup(demo,"html.parser")
soup.title.parent #title标签的父亲
soup.html.parent #html标签的父亲,因为html是最高级的,所以其父亲是他本身
soup.parent #soup的父亲返回空
对a标签的所有前辈的名字进行打印:

可能会遍历到soup本身,但soup没有父标签,所以需要判断一下
标签树的平行遍历:

next_siblings和previous_siblings用在循环中
平行遍历发生在同一个父节点下的各节点之间
soup = BeautifulSoup(demo,"html.parser")
soup.a.next_sibling #a标签的下一个平行节点
soup.a.next_sibling.next_sibling #a标签的下一个平行节点的再下一个
soup.a.previous_sibling #a标签的前一个平行节点
soup.a.previous_sibling.previous_sibling

总结
1.1.3 基于bs4库的HTML格式化和编码
soup.prettify()–能够为html文本的标签和内容增加换行符,也可以对每个标签进行处理
from bs4 import BeautifulSoup
soup = BeautifulSoup(demo,"html.parser")#解析后的内容
soup.prettify()
print(soup.prettify())
print(soup.a.prettify()) #对于a标签进行处理
1.2 信息组织和提取方法

html—超文本标记语言hyper text markup language
超文本—声音,图像,视频
1.2.1 信息标记的三种形式:xml,json,yaml
1,XML --扩展标记语言

XML属于是xtml发展过来的
2,JSON --Java语言中面向对象信息的一种表达形式
json使用有类型的键值对将信息组织起来
如果值的地方有多个信息与键相对应,我们使用方括号
也可以把一个键值对作为值的部分,放入另一个键值对中,采样大括号进行嵌套
 好处:对于Java语言,可以直接使用,是的程序大大简化
好处:对于Java语言,可以直接使用,是的程序大大简化
3,YAML
使用无类型键值对,在键值对中不增加任何符号或者相关的类型标记
其中 - 表示并列 # 表示注释 键值对之间可以嵌套


1.2.2 三种信息标记形式的比较
XML —使用尖括号标签—来表达信息
JSON — 使用有类型的键值对
YAML — 使用无类型键值对
下面用这三种形式来表现同一信息
XML实现:
XML特点:有效信息并不高,大多信息被标签占用

JSON实现:
特点:键值对都用到了双引号

YAML实现:

三种信息标记形式的比较:
- XML 最早的通用学习标记语言,可扩展性好,但繁琐
- JSON 信息有类型,适合程序处理,是javascript扩展而来的,比XML简洁
- YAML 信息五类型,文本信息比例最高,即有效信息占比最多,可读性好
三者使用情形:
- XML Internet上的信息交互与传递
- JSON 移动应用云端和节点的信息通信,无注释。主要用在程序对接口处理的地方
- YAML 各类系统的配置文件,有注释易读,应用相对广泛
1.2.3 信息提取的一般方法
方法一:完整解析信息的标记形式,再提取关键信息。
XML,JSON,YAML 需要标记解析器 例如:bs4库的标签树遍历
优点:信息解析准确
缺点:提取过程繁琐,速度慢
方法二:无视标记形式,直接搜索关键信息
搜索
对信息的文本查找函数即可
优点:提取过程简洁,速度较快
缺点:提取结果准确性与信息内容相关
方法三:融合方法:结合形式解析与搜索方法,提取关键信息—最好的
需要标记解析器及文本查找函数
方法三案例:
from bs4 import BeautifulSoup
soup = BeautifulSoup(demo,"html.parser") #soup中包含了整个HTML信息
for link in soup.find_all("a"): #找a标签
print(link.get("href"))
find_all的使用:

soup.find_all("a") #返回该文件中所有的a标签
soup.find_all(["a","b"]) #返回该文件中所有的a标签和b标签
soup.find_all(True) #参数写成true,返回文件中所有的标签信息
for tag in soup.find_all(True):
print(tag.name) #打印出这个文档里的所有标签名称
#下面只打印出所有以b开头的标签
import re
for tag in soup.find_all(re.compile('b')):
print(tag.name)
#p标签中含有course字符串的信息
soup.find_all('p','course')
#找出标签id=link1的标签元素
soup.find_all(id="link1")
find_all可以结合正则表达式一起使用
两种等价形式:

1.3 bs4解析
bs4解析是python独有的,正则表达式可以用于其他语言
数据解析原理:1,标签定位 2,提取标签、标签属性中存储的数据值
bs4解析原理:
- 实例化一个Beautifulsoup对象,并且将页面源码数据加载到该对象中
- 通过调用Beautifulsoup对象中相关属性或者方法进行标签定位和数据提取
环境安装:
pip install bs4/lxml
pip install lxml
如何实例化BeautifulSoup对象:
- 将本地的html文档中的数据加载到该对象中
fp = open(‘./test.html’,‘r’,encoding = ‘utf-8’)
soup = BeautifulSoup(fp,‘html’) - 将互联网上获取的页面源码加载到该对象中
page_text = response.text
soup = BeautifulSoup(page_text,‘html’)
提供的用于数据解析的方法和属性:
- soup.tagName :返回html中第一次出现的tagname信息
- soup.find():其中find(‘tagName’) 等同与soup.div ,只返回第一次出现的
- soup.find():属性定位:print(soup.find(‘div’,class_ = ‘song’))
- soup.find_all():符合要求的所有信息
- select : select(‘某种选择器(id,class,)’)
- 获取标签之间的文本数据:soup.a.text/string/get_text(),其中text/get_text():可以获取某一个标签中所有文本内容。string:只可以获取该标签下面直系的文本内容
- 获取标签中属性值:soup.a[‘href’]
from bs4 import BeautifulSoup
if __name__ == "__main__":
fp = open('./test.html','r',encoding = 'utf-8')
soup = BeautifulSoup(fp,'html')
print(soup.a) #只是返回第一次出现的a标签
print(soup.find('div'))
print(soup.select('.tang'))#类选择器
2、bs库案例:
2.1 中国大学排名爬虫
url:http://www.zuihaodaxue.cn/zuihaodaxuepaiming2016.html
https://www.shanghairanking.cn/rankings/bcur/2022
程序输入:url 输出:大学排名输出
动态脚本信息–bs库还无法获取
进入网页–右键查看网络源代码–再查看一下robost协议(www.zuihaodaxue.cn/robots.txt)-网页不存在,即网站没做限制

import requests
from bs4 import BeautifulSoup
import bs4
def getHTMLText(url): #输入url,输出URL的内容
try:
r = requests.get(url,timeout = 30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
def fillUnivList(ulist,html): #将一个HTML页面的关键数据放到一个list中
soup = BesutifulSoup(html,'html.parser')
for tr in soup.find('tbody').children:
if isinstance(tr,bs4.element.Tag):
tds = tr('td')
ulist.append([tds[0].string],[tds[1].string],[tds[2].string])
pass
def printUnivList(ulist,num): #将ulist打印出来,num是将里面多少元素打印出来
print("{:^10}\t{:^6}\t{:^10}".format("排名","学校名称","总分"))
for i in range(num):
u = ulist[i]
print("{:^10}\t{:^6}\t{:^10}".format(u[0],u[1],u[2]))
print("Suc"+str(num))
def main(): #主函数
uinfo = []
url = "http://www.zuihaodaxue.cn/zuihaodaxuepaiming2022.html"
html = getHTMLText(url)
fillUnivList(ulist,html)
printUnivList(ulist,num)

优化代码
问题:中文字符对齐问题
解决:中文字符不够时,不用西文字符的空格填充,而是用中文字符的空格进行填充chr(12288)
import requests
from bs4 import BeautifulSoup
import bs4
def getHTMLText(url): #输入url,输出URL的内容
try:
r = requests.get(url,timeout = 30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
def fillUnivList(ulist,html): #将一个HTML页面的关键数据放到一个list中
soup = BesutifulSoup(html,'html.parser')
for tr in soup.find('tbody').children:
if isinstance(tr,bs4.element.Tag):
tds = tr('td')
ulist.append([tds[0].string],[tds[1].string],[tds[2].string])
pass
def printUnivList(ulist,num): #将ulist打印出来,num是将里面多少元素打印出来
tplt = "{0:^10}\t{1:^6}\t{2:^10}"
print("tplt.format("排名","学校名称","总分",chr(12288)))
for i in range(num):
u = ulist[i]
print(tplt.format(u[0],u[1],u[2],chr(12288)))
print("Suc"+str(num))
def main(): #主函数
uinfo = []
url = "http://www.zuihaodaxue.cn/zuihaodaxuepaiming2022.html"
html = getHTMLText(url)
fillUnivList(ulist,html)
printUnivList(ulist,num)