Python爬虫 之数据解析之bs4
数据解析之bs4
-
- 一、bs4进行数据解析
- 二、bs4库和lxml库的安装
- 三、BeautifulSoup对象
- 四、项目实例
一、bs4进行数据解析
1、数据解析的原理
① 标签定位。
② 提取标签、标签属性中存储的数据值。
2、bs4数据解析的原理
① 实例化一个BeautifulSoup对象,并且将网页源码数据加载到该对象中。
② 通过调用BeautifulSoup对象中相关的属性或者方法进行标签定位和数据提取。
注:bs4是Python独有的,其它语言没有。
二、bs4库和lxml库的安装
因为BeautifulSoup对象是存在bs4库中的。而lxml是一个解析器,在bs4进行数据解析的时候需要lxml,当我们用bs4和xpath进行数据解析时都需要这个解析器。
1、bs4:
① bs4是什么:
它的作用是能够快速方便简单的提取网页中指定的内容,给我一个网页字符串,然后使用它的接口将网页字符串生成一个对象,然后通过这个对象的方法来提取数据
② 安装环境:
pip install bs4

2、lxml:
① lxml是什么:
lxml是一个解析器,也是以后的的xpath要用到的库,bs4将网页字符串生成对象的时候需要用到解析器,就用lxml,或者使用官方自带的解析器 html.parser
② 安装环境:
pip install lxml

三、BeautifulSoup对象
1、导入包:
from bs4 import BeautifulSoup
2、对象的实例化:
① 将本地的html文档中的数据加载到该对象中
基本写法:
fp = open('一个本地的html文件','r',endcoding='utf-8')
soup = BeautifulSoup(fp,'lxml')
详细的表述:
from bs4 import BeautifulSoup
if __name__ == '__main__':
# 将本地的html文档中的数据加载到该对象中
# ./wenjian.heml:是该目录下的一个html文件,也可以是其它本地的html文件,改个路径就行
fp = open('./wenjian.html','r',endcoding='utf-8')
soup = BeautifulSoup(fp,'lxml')
print(soup)
② 将互联网上获取的页面源码加载到该对象中
基本写法:
page_text = requests.text
soup = BeautifulSoup(page_text,'lxml')
详细的表述:
from bs4 import BeautifulSoup
import requests
if __name__ == '__main__':
# 将互联网上获取的页面源码加载到该对象中
url = '一个网址'
header = {
'User-Agent':'一个User-Agent'
}
page_text = requests.get(url=url,headers=header).text
soup = BeautifulSoup(page_text,'lxml')
print(soup)
我们通常使用第二种方法实例化化BeautifulSoup对象,第一种需要将网页上的信息存储到本地文件中,再进行实例化。而第二种可以之间实例化,方便许多。
3、BeautifulSoup的方法和属性
| 方法 | 描述 | 实例 |
|---|---|---|
| .tagName | 返回html第一次出现的tagName对应的标签 | soup.div,返回第一次出现div标签对应的数据 |
| find(‘tagName’) | 等价于soup.tagName,返回html第一次出现的tagName对应的标签 | soup.find(‘div’),等价于soup.tagName,返回第一次出现div标签对应的数据 |
| find(‘tagName’,属性名) | 属性定位:返回属性所对应的tagName标签对应的数据,返回符合要求的第一个,只返回一个 | soup.find(‘div’,class_=‘song’),返回class='song’对应的div标签对应的数据,class是关键字,所以要用class_ |
| find_all(‘tagName’) | 返回符合要求的所有标签(列表) | soup.find_all(‘div’),返回所有有div标签的数据 |
| select(‘某种选择器,可以是id、class、标签…选择器’) | 返回一个列表 | soup.select(‘class’),返回class选择器的数据,一个列表 |
| select(‘a > b > c’) / select(‘a > b c’) | 层级选择器,>表示一个层级,空格表示多个层级。返回一个列表 | soup.select(‘a > b > c’) / soup.select(‘a > b c’) |
获取标签之间的文本数据:
soup.tagName.text / string / get_text()
text / get_text() : 可以获取某一个标签中的所有文本内容
string : 只可以获取该标签下面直系的文本内容
获取标签中属性值:
soup.tagName['属性名']
如:soup.a.['href']
注:tagName 为标签名
四、项目实例
需求:
爬取《三国演义》小说所有的章节标题和章节内容,并将标题和内容存储到 txt 文件中。
网址:https://www.shicimingju.com/book/sanguoyanyi.html
思路:
首先我们打开管理员选项,选中某一刻标题查看右侧框。然后读取每个标题的数据。在首页中解析出章节标题和详情页url。然后实例化BeautifulSoup对象,需要将页面源码数据加载到该对象中。
soup = BeautifulSoup(page_text,'lxml')
li_list = soup.select('.book-mulu > ul > li')
可以用BeautifulSoup的select方法解析对象,这样就读取到了标题信息,同时页得到了详情页的网址信息。
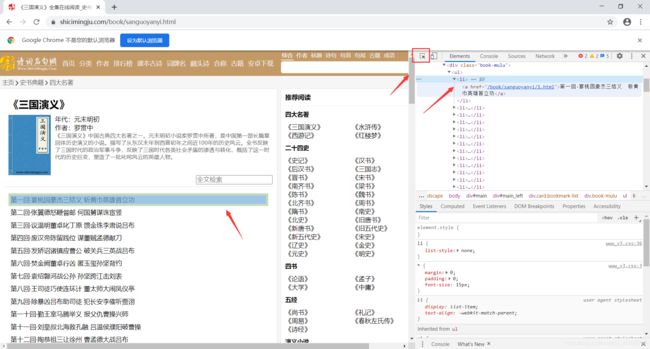
打开某一个标题,再次点开管理员选项查看右侧框,发现可以用BeautifulSoup的find方法,解析出详情页章节内容。根据从首页读取到的详情页的网址信息,来读取详情页的信息。然后再实例化BeautifulSoup对象,然后用find方法解析对象,然后将文章内容保存下来。
detail_url = 'https://www.shicimingju.com' + li.a['href'] # 每一章节的链接(详情页链接)
# 对详情页发出请求,解析内容
detail_page_taxt = requests.get(url=detail_url,headers=header).text # 详情页
# 解析出详情页章节内容
detail_soup = BeautifulSoup(detail_page_taxt,'lxml') # 详情页soup
detail_content = detail_soup.find('div',class_='chapter_content')
# 文章内容
content = detail_content.text

代码实现:
from bs4 import BeautifulSoup
import requests
if __name__ == '__main__':
url = 'https://www.shicimingju.com/book/sanguoyanyi.html'
header = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4209.2 Safari/537.36'
}
page_text = requests.get(url=url,headers=header).text # 首页响应数据
# 在首页中解析出章节标题和详情页url
# 实例化BeautifulSoup对象,需要将页面源码数据加载到该对象中
soup = BeautifulSoup(page_text,'lxml')
li_list = soup.select('.book-mulu > ul > li')
# 定义文件
fp = open('./sanguoyanyi.txt','w',endcoding='utf-8')
for li in li_list:
title = li.a.string # 章节的标题
# 打印标题
# print(title)
detail_url = 'https://www.shicimingju.com' + li.a['href'] # 每一章节的链接(详情页链接)
# 对详情页发出请求,解析内容
detail_page_taxt = requests.get(url=detail_url,headers=header).text # 详情页响应数据
# 解析出详情页章节内容
detail_soup = BeautifulSoup(detail_page_taxt,'lxml') # 详情页soup
detail_content = detail_soup.find('div',class_='chapter_content')
# 文章内容
content = detail_content.text
# 打印文章
# print(content)
fp.write(title + '\n' + content + '\n')
print(title + '爬取成功!!!')