[论文阅读]Point Density-Aware Voxels for LiDAR 3D Object Detection(PDV)
PDV
Point Density-Aware Voxels for LiDAR 3D Object Detection
论文网址:PDV
论文代码:PDV
简读论文
摘要
LiDAR 已成为自动驾驶中主要的 3D 目标检测传感器之一。然而,激光雷达的发散点模式随着距离的增加而导致采样点云不均匀,不适合离散体积特征提取。当前的方法要么依赖体素化点云,要么使用低效的最远点采样来减轻密度变化引起的有害影响,但在很大程度上忽略了点密度作为特征及其与 LiDAR 传感器距离的可预测关系。本文提出的解决方案,点密度感知体素网络 (PDV),是一种端到端的两阶段 LiDAR 3D 目标检测架构,旨在考虑这些点密度变化。 PDV 通过体素点质心有效地定位来自 3D 稀疏卷积主干的体素特征。然后,使用核密度估计 (KDE) 和具有点密度位置编码的自注意力,通过密度感知 RoI 网格池模块聚合空间局部体素特征。最后,利用 LiDAR 的点密度与距离关系来完善最终的边界框置信度。
引言
3D 目标检测是自动驾驶汽车领域的关键感知问题之一,因为目标姿态估计直接影响感知pipeline中下游任务的有效性。在自动驾驶传感器堆栈中,LiDAR 已成为用于 3D 目标检测的最流行的传感器之一,因为它可以通过激光产生准确的 3D 点云。
然而,对激光雷达数据的依赖是以点密度随距离变化为代价的。遮挡等其他因素也会产生影响,但最主要的原因是,随着距离的增加,激光雷达激光器之间的角度偏差会导致点的自然偏离。因此,距离较远的物体比距离激光雷达较近的物体返回的点要少。
基于体素的方法[Voxel r-cnn, Second, Cia-ssd, Voxelnet]通常忽略点密度,仅依赖于点云的量化表示。当提供高体素分辨率时,如 KITTI 数据集的情况,基于体素的方法 [Sessd] 优于基于点和基于点体素的方法。然而,在具有较大输入空间的数据集(例如 Waymo 开放数据集)上,由于内存限制,体素分辨率受到限制。因此,如图 1 (a) 所示,由于体素特征和点云之间的空间错位,精细的对象细节会丢失,从而导致性能下降。
![[论文阅读]Point Density-Aware Voxels for LiDAR 3D Object Detection(PDV)_第1张图片](http://img.e-com-net.com/image/info8/f1555ed3e5594f83afc2842b89e96222.jpg)
其他方法 [Pv-rcnn, Pointrcnn] 试图通过最远点采样 (FPS) 来纠正点密度变化,如图 1 (b) 所示。虽然在非均匀分布的点云上的采样位置有效,但作为点云中计算点的数量的函数缩放比例很差,增加了运行时间并限制了第二阶段提案细化的采样点的数量。
点密度还会影响对较小物体(例如行人和骑自行车的人)的检测。这些物体与激光雷达的激光束相交的表面积较小,导致物体定位效果较差。也许信息丰富的是,当前最先进的方法在很大程度上忽略了行人和骑自行车者的检测性能,仅关注汽车或车辆类别[Voxel r-cnn, Pyramid r-cnn, Voxel transformer for 3d object detection, Sessd]。随着转向具有更高环境覆盖范围的数据集,架构必须能够扩展到更大的输入空间,并作为 3D 目标检测的多类解决方案。
因此,本文提出点密度感知体素网络 (PDV),通过利用体素点质心定位和直接考虑多类 3D 目标检测中点密度的特征编码来解决这些已识别的问题。贡献:
- Voxel Point Centroid Localization. : PDV对每个非空体素中的LiDAR点进行分区,以计算每个体素特征的点质心,如图1©所示。通过使用点质心定位体素特征以进行第二阶段建议细化,PDV 使用点密度分布在特征编码中保留细粒度的位置信息,而不需要昂贵的点云采样方法(如 FPS)。
- Density-Aware RoI Grid Pooling. : 本文增强感兴趣区域(RoI)网格池化[Pv-rcnn],将局部点密度编码为附加特征。首先,使用核密度估计(KDE)对每个网格点球查询处的局部体素特征密度进行编码,然后使用新颖的点密度位置编码在网格点之间进行自注意力[Attention is all you need]。密度感知 RoI 网格池化在整个区域提案的背景下捕获局部点密度信息,以进行第二阶段细化。
- Density Confidence Prediction. : 通过使用最终边界框质心位置和最终边界框中原始 LiDAR 点的数量作为附加特征,进一步细化边界框置信度预测。因此,利用 LiDAR 建立的距离和点密度之间的内在关系来进行更明智的置信度预测。
PDV 在 Waymo 开放数据集上的表现优于所有当前最先进的方法,并在 KITTI 数据集上实现了有竞争力的性能。
相关工作
Point-based LiDAR 3D Object Detection. : 基于point的方法使用原始点云来提取点级特征以进行边界框预测。 F-PointNet在点云上应用 PointNet,通过基于图像的 2D 目标检测进行分割。 PointRCNN通过 PointNet++ 主干网直接生成点级 RoIs,并使用点级特征进行边界框细化。 STD 提出了用于RoI特征提取的PointsPool,而3DSSD在原始点云上采用了新的采样策略,为下采样点云中的对象保留足够的内部点。 Point-GNN 使用原始点云构建一个图,并聚合节点级特征来生成预测。基于point的方法利用昂贵的点云采样和分组,这不可避免地需要很长的推理时间。
Voxel-based LiDAR 3D Object Detection. : 基于体素的方法将点云划分为体素网格,直接应用 3D 和 2D 卷积来生成预测。 CIA-SSD 采用鸟瞰(BEV)网格上的光网络来提取鲁棒的空间语义特征,并带有置信校正模块以实现更好的后处理。 Voxel-RCNN 提出Voxel RoI pooling,通过聚合体素特征来生成RoI特征。 VoTr 提出了一种基于 Transformer 的 3D 主干作为标准稀疏卷积层的替代方案。基于体素的方法的性能受到量化点云的限制,因为细粒度的点级信息在体素化过程中丢失。
Point-Voxel-based LiDAR 3D Object Detection. : 基于point-voxel的方法利用点云的体素和点表示。 SA-SSD 在训练期间使用辅助网络,从中间体素层插入点级特征。 PV-RCNN 采用 RoI 网格池化来有效地将 FPS 采样的关键点特征聚合在每个边界框提案内均匀间隔的网格上。 PV-RCNN++ 提出了 FPS 的修改版本,以实现更快的点采样和用于 RoI 网格池化的 VectorPool 聚合。 CT3D 在每个边界框提案中构造一个圆柱形 RoI。它采用基于transformer的编码器-解码器架构,直接从附近点提取 RoI 特征,而不使用中间体素特征。 Pyramid-RCNN 将 RoI 网格池化的思想从一组均匀分布的网格扩展到不同尺度的多组网格,并具有自适应球查询半径,但计算成本明显更高。当前基于point-voxel的方法没有明确考虑每个 RoI 内点云密度的变化,并且由于依赖于点云采样,通常需要很长的推理时间。
Point Density Estimation. : KDE 使用一组有限的样本以及选定的核函数和带宽来估计随机变量的概率分布函数。有几种方法使用 KDE 在点云中进行特征编码。 MC Convolution 使用卷积积分的蒙特卡罗估计来处理非均匀采样点云,并使用 KDE 来估计局部卷积内点的可能性。 PointConv 也使用 KDE,但使用额外的前馈网络(FFN)估计每个样本的可能性。本文没有限制重新加权的密度估计,而是使用 KDE 作为密度感知 RoI 网格池化中每个网格点球查询中的附加功能。
方法
![[论文阅读]Point Density-Aware Voxels for LiDAR 3D Object Detection(PDV)_第2张图片](http://img.e-com-net.com/image/info8/3fcb7f47cd6e4eeb905599f338ca3c4d.jpg)
PDV 使用具有 3D 稀疏卷积主干的两阶段方法来进行初始边界框建议,然后在第二阶段通过每个体素层中的体素特征和原始点云数据进行细化。图 2 显示了 PDV 框架的概述。
3D Voxel Backbone
本文使用与 SECOND 类似的体素骨干进行初始边界框提议。PDV 的输入是点云,它被定义为一组 3D 点 {pi = {xpi , fpi} |i= 1,,,Np} 其中 xpi ∈ R3 是 xyz 空间坐标,fpi ∈ RF 是附加特征,例如每个点的强度或伸长率,Np 是点云中的点数。首先,点云被体素化,随后使用一系列 3D 稀疏卷积进行编码,然后是用于初始边界框提案的区域提案网络 (RPN)。每个体素层具有不同的空间分辨率,根据原始体素网格大小具有 1x、2x、4x 和 8x 下采样分辨率。每层中的体素特征用于第二阶段的边界框细化。
Voxel Point Centroid Localization
受 KPConv 中网格子采样的启发,体素点质心定位模块在空间上定位非空体素特征,以便在密度感知 RoI 网格池中进行聚合。
令 Vl = {Vlk = {hVlk , fVlk} | k = 1,,,Nl} 是第 l 体素层中的非空体素集合,其中 hVlk 是 3D 体素索引,fVlk 是相关体素特征向量,Nl 是体素层 l 的非空体素数量= 1,,L。首先,通过根据空间坐标 xi 和体素网格维度计算它们的体素索引 hVlk,将同一体素内的点分组到集合 N(Vlk) 中。然后计算每个体素特征的点质心:
![[论文阅读]Point Density-Aware Voxels for LiDAR 3D Object Detection(PDV)_第3张图片](http://img.e-com-net.com/image/info8/882dabcccf964a2185659528d36c113c.jpg)
由于卷积层中的体素是稀疏格式,因此使用中间哈希表来有效地将每个计算的体素点质心映射到其相应的特征向量。如图 3 所示,体素点质心和稀疏体素特征都与共享体素索引相关联。中间哈希表使用匹配的体素索引hVlk 将质心cVlk 与Vlk 链接。
![[论文阅读]Point Density-Aware Voxels for LiDAR 3D Object Detection(PDV)_第4张图片](http://img.e-com-net.com/image/info8/f10d670d10f54037b5bd2a2d6859be6b.jpg)
使用体素的一个优点是,可以使用先前的体素层质心计算,根据卷积块的步长、填充和内核大小有效地计算后续体素点质心。令 Cl+1 k = {cVlj | Kl+1(hVl j ) = hVl+1 k } 是体素点质心的集合,其中 Kl+1 是将体素索引 hVl j 映射到 hVl+1 k 的卷积块。然后,可以对分组的体素点质心进行加权平均,以计算后续层中的质心:
![[论文阅读]Point Density-Aware Voxels for LiDAR 3D Object Detection(PDV)_第5张图片](http://img.e-com-net.com/image/info8/d1e5f77b6dbd4d258e7d3b5def311119.jpg)
通过避免使用每层的整个点云重新计算质心,体素点质心定位可以更有效地扩展到更大的点云。
Density-aware RoI Grid Pooling
密度感知 RoI 网格池化建立在 RoI 网格池化的基础上,通过结合 KDE 和自注意力来增强池化方法,将点密度特征编码到每个提案中。首先,U ×U ×U 均匀网格点 Gb = {g1, , , gU3} 对每个边界框提案 b 进行采样。
Local Feature Density. : 本文使用 KDE 来估计每个网格点球查询中的局部特征密度。密度感知 RoI 网格池化不像 MC Convolution 和 PointConv 那样将估计密度限制为特征重新加权,而是将估计概率密度编码为球查询中的附加特征,以实现更隐式的特征编码。首先,聚合每个网格点附近的相邻特征,其中 N(gj) 是以 gj 为中心、半径为 r 的球体中的体素点质心集:
![[论文阅读]Point Density-Aware Voxels for LiDAR 3D Object Detection(PDV)_第6张图片](http://img.e-com-net.com/image/info8/b918b843ad83453b8eab0f5b280473ba.jpg)
其中局部偏移 cVl k − gj 和似然性 p(cVl k |gj) 作为附加特征附加,如图 4 所示:
![[论文阅读]Point Density-Aware Voxels for LiDAR 3D Object Detection(PDV)_第7张图片](http://img.e-com-net.com/image/info8/ef680c523db846df904b59ee744ee312.jpg)
使用 KDE 计算每个网格点的似然度:
![[论文阅读]Point Density-Aware Voxels for LiDAR 3D Object Detection(PDV)_第8张图片](http://img.e-com-net.com/image/info8/5d525f7022734674923da7502d86c470.jpg)
一旦附加了特征,PointNet 多尺度分组(MSG)模块用于获取每个网格点 gj 的特征向量 fl gj :
本文使用多个半径 r 来捕获每个网格点不同尺度的特征密度,并将输出特征连接在一起。最后,从不同体素层附加特征以获得每个网格点的最终特征:
Grid Point Self-Attention. : 每个 RoI 网格点编码的特征都局限于球查询的大小,但不同网格点之间缺乏相互依赖的关系。一个简单的解决方案是使用自注意力来捕获网格点之间的远程依赖关系,但简单地添加注意力模块缺乏LiDAR点云的几何信息。因此,本文还引入了一种新型的位置编码,它考虑了点云内的点密度。
![[论文阅读]Point Density-Aware Voxels for LiDAR 3D Object Detection(PDV)_第9张图片](http://img.e-com-net.com/image/info8/ec4aeaa861994dee85212a8afea5f6ea.jpg)
如图5所示,自注意力模块在非空网格点特征之间进行自注意力,使用标准 Transformer 编码器层和类似于非局部神经网络块的残差连接:
其中 Tgi 是 fgi 的 Transformer 编码器层输出,~fgi 是输出网格特征。空网格点特征|N(gi)| = 0 不受自注意力模块影响,并保留其原始特征编码。
Point Density Positional Encoding. : 通过使用局部网格点位置和框提案中的点数将位置编码添加到自注意力模块中。使用相同的 U×U×U 网格分辨率将边界框提案划分为体素 Vgj 来为每个网格点建立体素。每个网格特征的位置编码计算如下:
其中 δgj = Xgj −Cb 是 gj 与边界框提案质心 cb 的相对位置,|N(Vgj )|是每个网格点体素 Vgj 中的点数,并且 ϵ 是常数偏移。通过利用每个体素内的局部偏移和点数,密度感知 RoI 网格池能够捕获每个区域提案内的点密度。
Density Confidence Prediction
PDV 还利用扫描对象上的距离和 LiDAR 点数量之间的关系来预测最终边界框预测的置信度。共享 FFN 首先对来自密度感知 RoI 网格池模块的扁平化特征进行编码。然后,两个独立的 FFN 分支对框细化和框置信度输出的特征进行编码。在框置信度分支中,另外附加两个特征来预测最终边界框 ∼b 的输出置信度 p∼b:
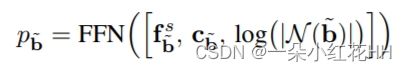
其中 fs b~ 是共享 FFN 的输出特征向量,cb~ 是最终边界框的质心,|N(~b)|是最终边界框中的原始点数。
Training Losses
本文对 PDV 使用端到端训练策略,并联合训练区域提案损失 LRPN 和提案细化损失 LRCNN。 LRPN 计算如下:
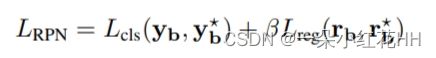
其中Lcls是focal loss,Lreg是smooth-L1损失,yb是预测的类向量,y⋆b是地面真值类别,rb是预测的RoI锚残差,r⋆b是地面真值锚残差,β 是比例因子。 LRCNN 的组成为:

其中 p⋆ b~是由 3D RoI 及其相关的地面真实边界框缩放的置信度训练目标,如 PV-RCNN中所做的那样。因此 LRCNN 是:
![]()
其中 r b~ 是预测的边界框残差,r⋆b~是地面真实残差。 smooth-L1 损失用于回归边界框残差。使用与 PV-RCNN 相同的置信度和回归目标。
结论
本文提出了 PDV,一种新颖的 LiDAR 3D 物体检测方法,该方法使用体素特征和原始点云数据来解释 LiDAR 点云中的点密度变化。 PDV 在点云采样成本昂贵且体素分辨率较低的大型输入空间中特别有用,从而在 Waymo 数据集上实现最先进的性能,并在 KITTI 数据集上获得具有竞争力的结果。