CT3D:Improving 3D Object Detection with Channel-wise Transformer 论文阅读
Abstract
现在点云的两阶段3D物体检测灵活性和高性能的建议修正工作都不是很好。以前的refining 3D proposals 都依赖人工设计,比如关键点采样,set straction 和多尺度特征融合等,都不能很好捕捉点之间上下文依赖信息。所以我们提出CT3D,其中包含region proposal 和 a Channel-wise Transformer。对于每一个proposal 都是由proposal-aware embedding和 channel-wise context aggregation 组成。CT3D使用proposal的关键点进行空间上下文建模,并在编码模块中学习注意力传播,将proposal映射到点嵌入。之后,新的channel-wise解码模块通过channel-wise重新加权来丰富query-key的交互,从而有效地合并多级上下文,从而有助于更准确地进行对象预测。实验证明我们的model效果很好,在KITTI数据集中car目录中AP值达到81.77%。
1、Introduce
点云特点:稀疏、无序、不规则分布。对于这些个特点,许多方法都用体素化或者定制离散或来解决。有的处理点云用BEV+2D卷积,有的栅格化点云+3D卷积。点云检测任务的一个重大突破是点云表示的有效深层结构,如体素卷积和置换不变量卷积。
最近,大多数最先进的3D物体检测都是两阶段的,一阶段生成3D区域建议框,二阶段用来修正。最好的区域建议网络在KITTI上实现了95%的召回率,但精度却只有78%。造成这种差距的原因是在物体编码和在遮挡或远距离情况下从3D建议中提取鲁棒特征的困难。PointNet系列使用感受野,缺点:太依赖手工设计参数。基于体素系列使用3D卷积,缺点:对超参数很敏感,并且体素量化会影响。之后两种混合,太依赖RPN结构。
我们有两个重要贡献:1)提出端到端的两阶段3D物体检测模型:CT3D,收DETR和Transformer的影响。第一阶段是学习每个框的表示通过整合新的Transformer结构:解码基于通道数重新加权的结构。
第二个贡献是定制的Transformer。Transformer能跟好的获取上下文信息和增加假阴性的置信度。所以我们提出一个区域到点的编码能够有效在encoder模块中编码RPN区域信息。此外,考虑到编码点的全局和局部通道特性,我们采用了通道重加权的方法来增强标准Transformer解码器。目的是扩大特征解码空间,在这里我们可以计算关键字嵌入的各个通道维度上的注意力分布,从而增强查询-关键字交互的表现力。实验显示我们的效果很不错。
2、相关工作
3D物体检测中点云表示:PointNet系列使用置换不变性操作。F-PointNet在每个3D柱体中产生区域水平的特征;PointRCNN分割前后背景;STD通过将稀疏点特征变化为体素表示来修正建议框;3DSSD使用基于特征距离的一个新的采样方法;PointNet系列仍然有限制。另一类方法是将点云体素为2D/3D网格再用CNN处理。先驱者将点云转化为2D俯瞰图在进行映射产生3D候选框;VoxelNet变化点云形成一个紧凑的表示。SECOND介绍了3D稀疏卷积去处理3D体素;基于体素的方法仍然专注于体的细分,而不是自适应地建模局部几何结构。还有就是点和体素相结合处理的方式。SA-SSD提出一个辅助网络在基础的3D体素网络;PV-RCNN和VoxelRCNN采用3D体素CNN作为RPN来生成高质量的建议框,然后利用PointNet聚集网格周围的体素特征。这种方法太依赖手工制作特征。
Transformers用于物体检测中:Transformer模型学习局部上下文信息非常有效,DETR将物体看作集合预测问题并用transformer进行并行检测物体在2D图片中。DETR的一个变形开发了一个可变形的注意力模块,以使用跨尺度聚集。
3、CT3D for 3D Object Detection
建议框产生是广泛地使用RPN,像3D voxel CNN,这些使用卷积层进行体素特征提取,会造成广泛性不强和额外超参数优化。我们的CT3D直接在可以利用原始点云数据的RPN网络上使用一个被设计好的transformer。具体来说,这个检测网络被分为三部分:a RPN backbone 用来产生建议框, a channel-wise Transformer可以修正建议框的特征和a detect head 用来预测物体。
3.1. RPN for 3D Proposal Generation
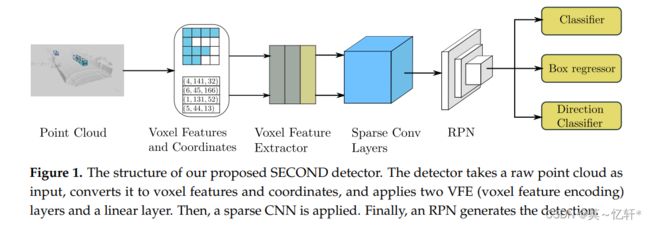
预测的3D候选框是通过RPN生成,包括中心坐标 p c = [x c , yc , zc ],长度l c , 宽度w c , 高度h c , 和方向θ c 。我们选用SECOND作为我们的RPN。
SECOND结构如图所示。
3.2. Proposal-to-point Encoding Module
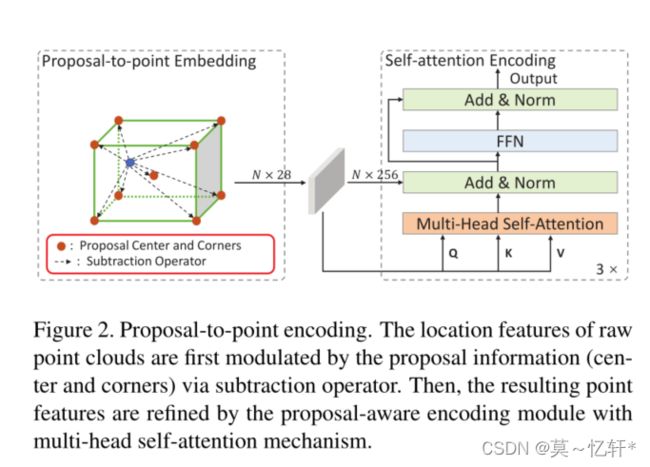
为了改进RPN的建议框,我们用两步。第一步是proposal-to-point embedding将建议映射成点特征;第二部是self-attention encoding去修正点特征介于匹配的框中的点之间的相对关系。
Proposal-to-point Embedding:根据给定的框我们现在原始点云中划定一个界限,也就是形成一个RoI,这个RoI不被高度限制,半径为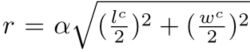 ,其中α是一个超参数,l,w分别是框的长和宽,之后随机采样256个点
,其中α是一个超参数,l,w分别是框的长和宽,之后随机采样256个点![]() 。首先转换为采样点和中心点之间相对坐标
。首先转换为采样点和中心点之间相对坐标![]()
![]() ,直接联结各个点的特征是最直接的方式,但是方向维度不是很好。使用关键点能够提供更多集合属性,所以我们提出keypoints subtraction strategy来计算每个点和他附近八个点之间的相对关系
,直接联结各个点的特征是最直接的方式,但是方向维度不是很好。使用关键点能够提供更多集合属性,所以我们提出keypoints subtraction strategy来计算每个点和他附近八个点之间的相对关系![]() 。对于Proposal-to-point Encoding中每个点可以表示为:,其中A适合线性层用来映射点特征到高纬度的embedding。
。对于Proposal-to-point Encoding中每个点可以表示为:,其中A适合线性层用来映射点特征到高纬度的embedding。
Self-attention Encoding :如图所示
proposal-to-point Embedding之后为![]()
query、key、value计算为![]()
有H-head的注意力机制,所以说Q = [Q1, . . . , QH],K = [K1, . . . , KH], V = [V1, . . . , VH]
多头注意力输出结果为:

其中![]() ,σ(·)是一个softmax函数。最终self-attenfion Encoding输出结果为:
,σ(·)是一个softmax函数。最终self-attenfion Encoding输出结果为:

其中 Z(·)表示 Add & Norm,F(·)表示 FFN。在本文中我们选用H=3。
3.3 Channel-wise Decoding Module
我们的任务就是将编码器的输出的所有点特征解码,结果通过FFN得到最终目标预测。我们与标准的transformer解码器不同,我们只根据两点来解码:1)M个查询消耗了太高的存储,特别是处理多个建议;2)我们建议修正模型只需要一个预测,不同与说M个query需要有M句话或者物体。
标准的Decoder:通过D维的query Embedding来聚合所有通道的点特征。
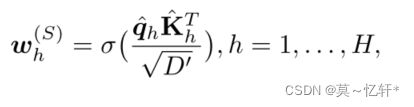
如图所示。
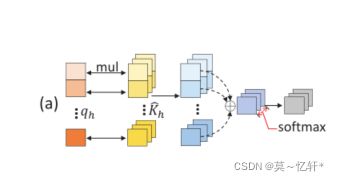
向量![]() 的每个值可以被视为单个点的全局聚集。这种方式只能利用全局信息,但却缺少了局部通道的信息。
的每个值可以被视为单个点的全局聚集。这种方式只能利用全局信息,但却缺少了局部通道的信息。
Channel-wise Re-weighting:
为每个通道生成D个不同的解码权向量,来获得D个解码值,之后线性投影来形成一个联合的以通道为单位的解码矢量。
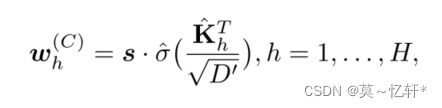
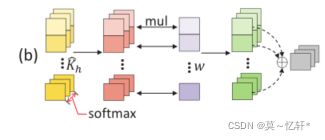
这个方式忽略了全局聚集,只关注了通道局部信息。
Extended Channel-wise Re-weighting:我们首先重复查询嵌入和关键字嵌入的矩阵乘积,将空间信息传播到每个通道,然后将输出与关键字嵌入逐个元素相乘,以保持通道差异。
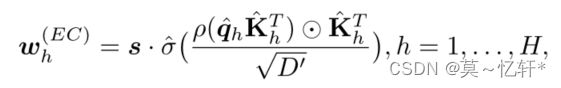
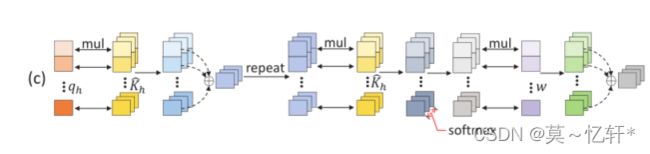
这种方式既关注了全局有关注了局部。
最后解码后输出为:
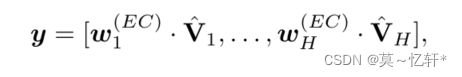
3.4 Detect head and Training Targets
置信度: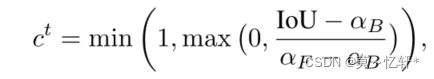
回归:
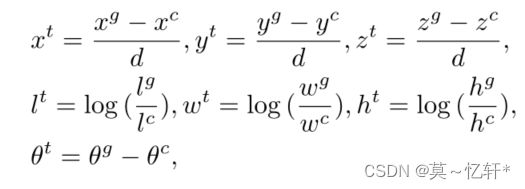
其中![]()
3.5. Training Losses
总损失等于三个阶段损失之和
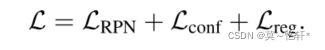
置信度损失计算:

框损失计算:
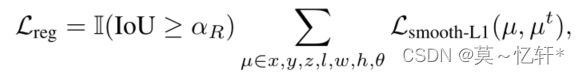
4、Experiments
数据集:KITTI 和 Waymo
在KITTI上表现:
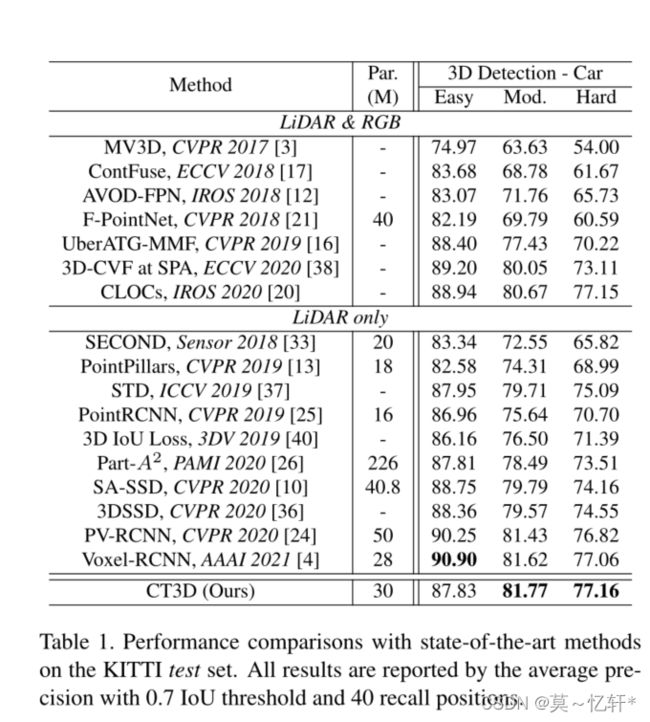
表中可以看到本文提出的结构在MOD、Hard困难等级上都有小幅度提高,但是提高并不是很高,在Easy的Car上反而会有下降。作者说道:这一显著的改进主要来自于CT3D在精化阶段处理原始点而不是依赖于关于人类特定的设计和中间特征。本文还说在Easy难度上精度下降可能是两个原因:采样点太小,简单的也可能会有很多点;第二个是KITTI这个数据集在训练集和测试集上差异很大。
接着作者继续实验:
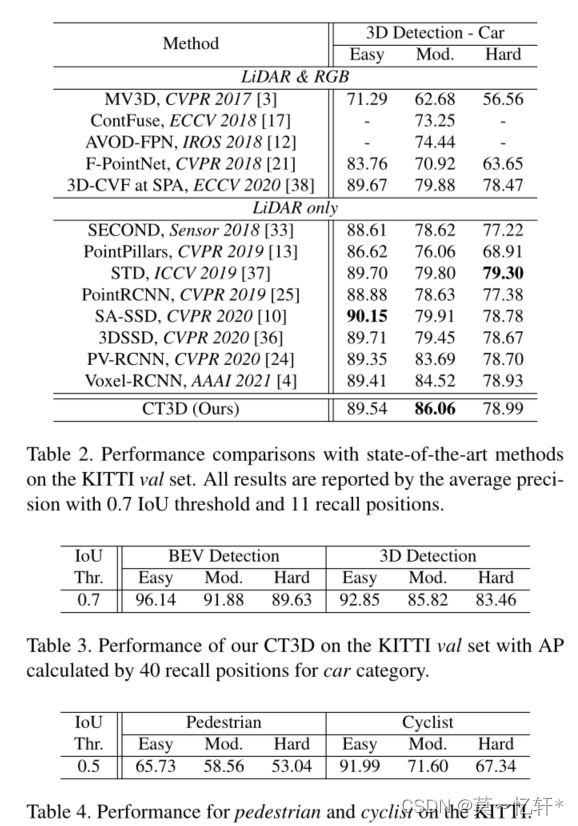
表2中在中等难度的检测上CT3D效果最好。并且在表3和表4上说明该模型在行人、骑自行车的人的检测上效果也很不错。
在Waymo的表现:
将数据划分了两个水平LELVEL_1表示物体包含多余5点,LELVEL_2表示物体包含1~5点。
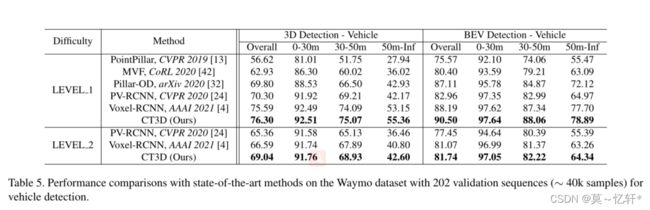
从表格5可以看到,CT3D实现了最好的检测效果,在BEV检测上也是实现了最好的效果。
消融实验
Proposal-to-point Embedding
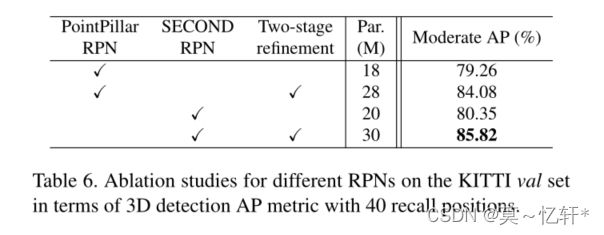
可以看到两阶段修正精度都比基准要高,作者说这得益于我们的两阶段框架CT3D可以集成在任何RPN的顶部,以提供强大的proposal细化能力。Par代表参数数量。
Self-attention Encoding:
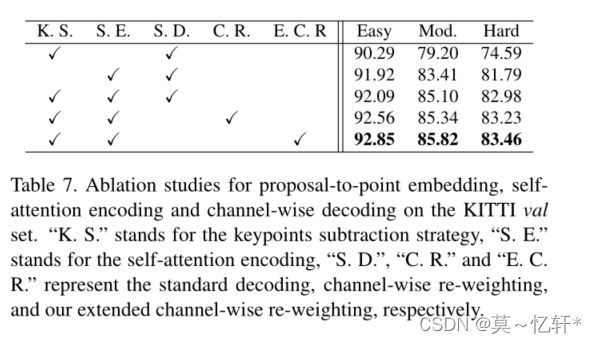
比较1、3行可以看到子注意力编码确实能够提升精度。
Channel-wise Decoding:
比较3、4、5行,我们改进的通道重新加权解码效果是优于标准的解码和通道重新加权的解码。
5、Conclusion
我们提出了CT3D结构:raw point -> proposal-to-point embedding -> self attention ->channel-wise re-weighting。对于点云检测任务我们提出的模型灵活并且高效。通过实验证明,在KITTI和Waymo数据集上我们的效果都很好。