[论文阅读]VoteNet——基于深度 Hough 投票法的点云3D目标检测
VoteNet
Deep Hough Voting for 3D Object Detection in Point Clouds
用于点云三维物体检测的深度 Hough 投票法
论文网址:VoteNet
总结
这篇论文提出了一个称为VoteNet的3D物体检测模型,该模型基于Hough投票机制。其主要创新点包括:
- 将传统的Hough投票与深度学习结合,实现端到端的可微分架构。
- 利用点云网络backbone学习点云特征,作为种子点特征。
- 每个种子点通过投票模块生成一个投票(offset预测)。投票目标指向物体中心,从而在物体中心形成聚类。
- 对投票进行聚类,然后对每个聚类利用PointNet进行特征聚合,生成物体候选框。
- 整个流程无需转换表示,直接对原始点云进行操作,利用了点云的稀疏性。
- 在SUN RGB-D和ScanNet两个数据集上达到了state-of-the-art的性能,仅利用几何信息就明显优于之前利用RGB和geometry的方法。
- 分析实验表明,投票机制可以提供更广泛的上下文,特别是对物体中心距离表面点较远的情况更有帮助。
- 模型更紧凑高效,相比之前最好的方法在模型大小和速度上分别提升4倍和20倍。
整体而言,这篇论文通过改进的Hough投票机制,设计了一个端到端的3D检测模型,利用点云的稀疏性避免在空间中搜索,取得了state-of-the-art的性能。投票聚集远离表面的点,提供了更好的上下文聚合,是该方法的核心创新。
votenet讲解
![[论文阅读]VoteNet——基于深度 Hough 投票法的点云3D目标检测_第1张图片](http://img.e-com-net.com/image/info8/f078a8d55b824380b8bcaa74c75e779f.jpg)
VoteNet网络结构可以分为以下几个模块:
-
点云特征学习(Backbone)
使用基于PointNet++的层次点云特征学习网络。包含Set Abstraction(采样+局部特征提取)层和Feature Propagation(特征传播)层。输出M个种子点,每个点为(XYZ坐标 + C维特征)。 -
投票模块(Voting)
每个种子点独立通过一个多层全连接网络,预测一个偏移量(XYZ空间的投票偏移)和一个特征偏移量。实现种子点到物体中心的投票。
投票模块是完全共享的,网络需要学习辨别背景点和目标点,预测不同的偏移量。背景点预测的偏移量可以是无意义的小量值或毫无规律的随机量,在后续聚类中很难形成有效聚类。即使背景点预测到目标中心,也可能起到把目标周围的背景点聚集到一起的作用,增强目标点的聚类效果。
投票的概念主要体现在以下两个方面:
1.区分前景点和背景点
投票机制要求网络学习区分前景点和背景点,使前景点预测的偏移量指向目标中心,背景点的偏移无意义。
2.聚集属于同一目标的点
前景点通过预测偏移量指向目标中心,使属于同一目标的不同部分的点聚集在一起,形成一个聚类。 -
投票聚类
通过最远点采样从投票中采样K个中心,每个中心通过半径聚集周围的投票形成一个聚类。 -
提议模块(Proposal)
每个投票聚类通过一个PointNet处理生成一个物体提议,包含物体度、边框参数和语义分类分数。 -
损失函数
包含投票偏移回归损失、物体度分类损失、边框预测损失和语义分类损失。
整个网络端到端训练,直接作用于原始点云,避免了空间量化。投票机制提供了更好的目标中心预测和上下文聚合。
摘要
当前的 3D 物体检测方法深受 2D 检测器的影响。为了利用 2D 检测器中的架构,他们经常将 3D 点云转换为常规网格(即体素网格或鸟瞰图像),或者依靠 2D 图像中的检测来提出 3D 框。很少有作品尝试直接检测点云中的物体。在本文中回归第一原则,为点云数据构建一个尽可能通用的 3D 检测管道。然而,由于数据的稀疏性(来自 3D 空间中 2D 流形的样本),直接从场景点预测边界框参数时面临重大挑战:3D 对象质心可能远离任何表面点,因此很难准确回归一步之遥。为了应对这一挑战,本文提出了 VoteNet,这是一种基于深度点集网络和霍夫投票协同作用的端到端 3D 对象检测网络。本文的模型通过简单的设计、紧凑的模型尺寸和高效率,在两个大型真实 3D 数据集 ScanNet 和 SUN RGB-D 上实现了最先进的 3D 检测。值得注意的是,VoteNet 通过使用纯粹的几何信息而不依赖彩色图像,优于以前的方法。
引言
3D 对象检测的目标是定位和识别 3D 场景中的对象。更具体地说,在这项工作中,目标是估计定向 3D 边界框以及来自点云的对象的语义类别。
与图像相比,3D 点云提供了精确的几何形状和对照明变化的鲁棒性。另一方面,点云是不规则的。因此,典型的 CNN 不太适合直接处理它们。
为了避免处理不规则的点云,当前的 3D 检测方法在各个方面严重依赖基于 2D 的检测器。例如,[Deep sliding shapes for amodal 3d object detection in rgb-d images, 3D-SIS] 将 Faster/Mask R-CNN 等 2D 检测框架扩展到 3D。他们将不规则的点云体素化为规则的 3D 网格,并应用 3D CNN 检测器,但这种检测器无法利用数据的稀疏性,并且由于昂贵的 3D 卷积而导致计算成本高昂。或者,[Multi-view 3d object detection network for autonomous driving, Voxelnet] 投影指向常规 2D 鸟瞰图像,然后应用 2D 检测器来定位对象。然而,这牺牲了几何细节,而这在杂乱的室内环境中可能至关重要。最近,[2d-driven 3d object detection in rgb-d images, Frustum pointnets for 3d object detection from rgbd data]提出了一种级联两步流程,首先检测前视图像中的对象,然后定位从 2D 框挤出的截锥体点云中的对象,然而,这严格依赖于 2D 检测器。
本文引入了一个以点云为中心的 3D 检测框架,该框架直接处理原始数据,并且在架构和对象提案中都不依赖于任何 2D 检测器。本文的检测网络 VoteNet 基于点云 3D 深度学习模型的最新进展,并受到对象检测的广义霍夫投票过程的启发 [Combined object categorization and segmentation with an implicit shape model]。
本文利用 PointNet++ (一种用于点云学习的分层深度网络)来减少将点云转换为常规结构的需要。通过直接处理点云,不仅可以避免量化过程造成的信息丢失,而且还可以通过仅对感测点进行计算来利用点云的稀疏性。
虽然 PointNet++ 在对象分类和语义分割方面取得了成功 ,但很少有研究研究如何使用此类架构检测点云中的 3D 对象。一个简单的解决方案是遵循 2D 检测器中的常见做法并执行密集对象提议 [Ssd, Faster R-CNN],即直接从感测点(及其学习的特征)提出 3D 边界框。然而,点云固有的稀疏性使得这种方法不利。在图像中,物体中心附近通常存在一个像素,但在点云中通常不是这种情况。由于深度传感器仅捕获物体的表面,因此 3D 物体中心可能位于空白空间,远离任何点。因此,基于点的网络难以聚合对象中心附近的场景上下文。简单地增加感受野并不能解决问题,因为当网络捕获更大的上下文时,它也会引入更多地包含附近的物体和混乱信息。
为此,本文建议赋予点云深度网络类似于经典霍夫投票的投票机制。通过投票,本质上生成靠近对象中心的新点,可以对这些点进行分组和聚合以生成框建议。
与难以联合优化的多个单独模块的传统霍夫投票相比,VoteNet 是端到端可优化的。具体来说,在将输入点云通过主干网络后,对一组种子点进行采样并根据其特征生成投票。投票的目的是到达对象中心。结果,投票簇出现在对象中心附近,反过来可以通过学习模块聚合以生成框提案。结果是一个强大的 3D 物体检测器,它是纯几何的,可以直接应用于点云。
研究表明,投票方案支持更有效的上下文聚合,并验证了当对象中心远离对象表面(例如桌子、浴缸等)时,VoteNet 提供了最大的改进。
贡献:
- 通过端到端可微架构在深度学习背景下重新表述霍夫投票,将其称为 VoteNet。
- SUN RGB-D 和 ScanNet 上最先进的 3D 对象检测性能。
- 深入分析投票对于点云中 3D 物体检测的重要性。
相关工作
3D object detection
先前提出了许多方法来检测对象的 3D 边界框。例子包括:[Holistic scene understanding for 3d object detection with rgbd cameras-2013]其中成对的语义上下文潜力有助于指导提案的客观性得分;基于模板的方法[Database-assisted object retrieval for real-time 3d
reconstruction-2015, A search-classify approach for cluttered indoor scene understanding-2012, Asist: automatic semantically invariant scene transformation-2017]; Sliding-shapes [Sliding shapes for 3d object detection in depth images-2014] 及其基于深度学习的后继者 [Deep sliding shapes for amodal 3d object detection in rgb-d images-2016];定向梯度云(COG)[Three-dimensional object detection and layout prediction using clouds of oriented gradients-2016];以及最近的 3D-SIS。
由于直接在 3D 中工作的复杂性,尤其是在大型场景中,许多方法都采用某种类型的投影。例如,在 MV3D 和 VoxelNet 中,3D 数据首先被简化为鸟瞰图,然后再进入pipeline的其余部分。 Frustum PointNets [2018] 和 [2d-driven 3d object detection in rgb-d images-2017] 都证明了通过首先处理 2D 输入来减少搜索空间。类似地,在[Accurate
localization of 3d objects from rgb-d data using segmentation hypotheses-2013]中,使用 3D 地图验证了分割假设。最近,GSPN [2018] 和 PointRCNN [2018] 使用点云上的深度网络来利用数据的稀疏性。
Hough voting for object detection.
Hough transform 最初于 20 世纪 50 年代末引入,它将检测点样本中的简单模式的问题转化为检测参数空间中的峰值。广义霍夫变换 进一步将该技术扩展到图像块,作为复杂对象存在的指示符。使用霍夫投票的例子包括 [Robust object detection with interleaved categorization and segmentation-2008] 的开创性工作,它引入了隐式形状模型、从 3D 点云中提取平面和 6D 姿态估计 等。
霍夫投票之前也与先进的学习技术相结合。在[Object detection using a max-margin hough transform-2009]中,投票被分配了表明其重要性的权重,这是使用最大利润框架学习的。 [Hough forests for object detection, tracking, and action recognition, Class-specific hough forests for object detection] 中介绍了用于目标检测的霍夫森林。最近,[Deep learning of local rgb-d patches for 3d object detection and 6d pose estimation] 通过使用提取的深度特征来构建码本,展示了改进的基于投票的 6D 姿态估计。同样,[Hough-cnn-2017] 学习了深度特征来构建用于 MRI 和超声图像分割的码本。在[Vehicle logo retrieval based on hough transform and deep learning-2017]中,经典的霍夫算法被用来提取汽车标志中的圆形图案,然后将其输入到深度分类网络中。 [Semi-convolutional operators for instance segmentation]提出了用于图像中2D实例分割的半卷积算子,这也与霍夫投票有关。
还有一些使用霍夫投票进行 3D 物体检测的研究 [Demisting the hough transform for 3d shape recognition and registration, Orientation invariant 3d object classification using hough transform based methods-2010, Implicit shape models for object detection in 3d
point clouds-2012, Scene cut-2011],它采用了与 2D 检测器类似的流程。
Deep learning on point clouds
最近,人们对设计适合点云的深度网络架构的兴趣激增[PointNet, PointNet++, Splatnet-2018, Point convolutional neural networks by extension operators-2018, Pointcnn, 3d semantic segmentation with submanifold sparse convolutional networks-2018, O-cnn-2017, Octree generating networks-2017, Tangent convolutions for dense prediction in 3d-2018, Pointgrid-2018, Escape from cells-2017, Foldingnet-2018, Spidercnn-2018, Dynamic graph cnn for learning on point clouds-2018, Attentional shapecontextnet for point cloud recognition-2018],这表明在3D对象分类、对象部分分割以及场景分割方面表现出色。在 3D 对象检测的背景下,VoxelNet 从体素中的点学习体素特征嵌入,而在 [Frustum pointnets] 中,PointNet 用于定位从 2D 边界框挤出的平截头体点云中的对象。然而,很少有方法研究如何在原始点云表示中直接提出和检测 3D 对象。
Deep Hough Voting
传统的霍夫投票二维检测器[Robust object detection with interleaved categorization and segmentation-2008]包括离线和在线步骤。首先,给定带有注释的对象边界框的图像集合,使用图像块(或其特征)之间存储的映射及其到相应对象中心的偏移来构造码本。在推理时,从图像中选择兴趣点以提取它们周围的补丁。然后将这些补丁与码本中的补丁进行比较,以检索偏移量并计算投票。由于对象补丁倾向于投票一致,因此簇将在对象中心附近形成。最后,通过将集群投票追溯到其生成的补丁来检索对象边界。
本文确定了该技术非常适合本文感兴趣的问题的两种方式。首先,基于投票的检测比区域提议网络(RPN)更兼容稀疏集。对于后者,RPN 必须在目标中心附近生成一个提案,该中心可能位于空白空间,从而导致额外的计算。其次,它基于自下而上的原则,其中少量的部分信息被积累以形成可信的检测。尽管神经网络可以从大的感受野聚合上下文,但在投票空间中聚合仍然可能是有益的。
然而,由于传统的霍夫投票包含多个独立的模块,因此将其集成到最先进的点云网络中是一个开放的研究课题。为此,本文建议对不同的pipeline成分进行以下调整。
Interest points:兴趣点由深度神经网络描述和选择,而不是依赖于手工制作的特征。
Vote:投票生成是通过网络学习的,而不是使用密码本。利用更大的接受域,投票可以变得不那么模糊,从而更加有效。此外,可以使用特征向量来增强投票位置,从而实现更好的聚合。
Vote aggregation:投票聚合是通过具有可训练参数的点云处理层实现的。利用投票功能,网络可以过滤掉低质量的投票并生成改进的提案。
Object proposals:位置、尺寸、方向甚至语义类形式的对象提案可以直接从聚合的特征中生成,从而减少了追溯投票来源的需要。
VoteNet Architecture
整个网络可以分为两部分:一部分处理现有点以生成投票;另一部分则对虚拟点(投票)进行操作,以提议和分类对象。
Learning to Vote in Point Clouds
从大小为 N×3 的输入点云中,N 个点中的每个点都有一个 3D 坐标,本文的目标是生成 M votes、采样和分组 3D NMS,其中每个投票都具有 3D 坐标和高维特征向量。主要有两个步骤:通过主干网络进行点云特征学习以及从种子点学习霍夫投票。
Point cloud feature learning:点云特征学习。生成准确的投票需要几何推理和上下文。本文不依赖手工制作的特征,而是利用最近提出的点云上的深度网络 进行点特征学习。虽然本文的方法不限于任何点云网络,但本文采用 PointNet++ 作为主干,因为它简单,并且在从正常估计、语义分割到 3D 对象定位 等任务上取得了成功。
主干网络具有多个集合抽象层和带有跳跃连接的特征传播(上采样)层,输出具有 XYZ 的输入点子集和丰富的 C 维特征向量。结果是维度为 (3 +C) 的 M 个种子点。每个种子点生成一票。
Hough voting with deep networks.:与传统的霍夫投票相比,传统投票(本地关键点的偏移)是通过预先计算的码本中的查找来确定的,本文使用基于深度网络的投票模块生成投票,这不仅更高效(无需 kNN 查找),而且准确,因为它是与pipeline的其余部分联合训练的。
给定一组种子点 ,共享投票模块独立地从每个种子生成投票。具体来说,投票模块是通过具有全连接层、ReLU 和批量归一化的多层感知器(MLP)网络来实现的。 MLP 采用种子特征并输出欧几里得空间偏移 Δxi 和特征偏移 Δfi,使得投票 vi = [yi;gi] 具有 yi = xi +Δxi 和 gi = fi +Δfi。
预测的 3D 偏移 Δxi 由回归损失明确监督
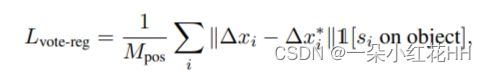
投票与张量表示中的种子相同,但不再基于对象表面。但更本质的区别是它们的位置——同一对象上的种子生成的投票现在比种子彼此更接近,这使得组合来自对象不同部分的线索变得更容易。接下来,将利用这种语义感知局部性来聚合对象提案的投票特征。
Object Proposal and Classification from Votes
投票创建了规范的“交汇点”,用于对象不同部分的上下文聚合。对这些投票进行聚类后,聚合它们的特征以生成对象提案并对它们进行分类。
Vote clustering through sampling and grouping.:虽然有很多方法可以对投票进行聚类,但本文选择了一种简单的策略,即根据空间邻近性进行均匀采样和分组。具体来说,来自一组投票{vi},在 3D 欧几里德空间中使用基于 {yi} 的最远点采样对 K 个选票的子集进行采样,得到 k = 1, …,K 的 {vik }。然后,通过找到 vik 的每个 3D 位置的相邻投票来形成 K 个簇:Ck。虽然简单,但这种集群技术很容易集成到端到端pipeline中,并且在实践中效果良好。
Proposal and classification from vote clusters.:由于投票簇本质上是一组高暗点,因此可以利用通用点集学习网络来聚合投票以生成对象提案。与传统霍夫投票识别对象边界的回溯步骤相比,该过程甚至可以从部分观察中提出非模态边界,并预测其他参数,如方向、类别等。
在本文的实现中,使用共享的 PointNet 进行集群中的投票聚合和提案。给定一个投票簇 C = {wi},其中 i = 1, …, n 及其簇中心 wj,其中 wi = [zi; hi],其中 zi ∈ R3 作为投票位置,hi ∈ RC 作为投票特征。为了能够使用局部投票几何结构,通过 zi` = (zi − zj)/r 将投票位置转换为局部标准化坐标系。然后通过将集合输入传递给类似 PointNet 的模块来生成该集群 p© 的对象建议:
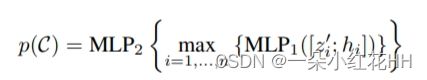
其中来自每个集群的投票由 MLP1 独立处理,然后被最大池化(通道方式)到单个特征向量并传递到 MLP2,其中来自不同投票的信息被进一步组合。将提案 p 表示为具有客观性得分、边界框参数(如参数化的中心、标题和比例)和语义分类得分的多维向量。
Loss function:提议和分类阶段的损失函数包括对象性、边界框估计和语义分类损失。
本文监督靠近地面真实对象中心(0.3 米以内)或远离任何中心(超过 0.6 米)的投票的客观性分数。将这些投票产生的提案分别视为正面提案和负面提案。对其他提案的客观性预测不会受到惩罚。对象性是通过交叉熵损失来监督的,该交叉熵损失按批次中不可忽略的提案数量进行归一化。对于积极的建议,根据最接近的地面真实边界框进一步监督边界框估计和类别预测。具体来说,它将框损失与中心回归、航向角估计和框大小估计解耦。对于语义分类,使用标准交叉熵损失。在检测损失的所有回归中,使用 Huber (smooth-L1 ) 损失。
Implementation Details
Input and data augmentation. 检测网络的输入是从弹出深度图像 (N = 20k) 或 3D 扫描(网格顶点,N = 40k)中随机二次采样的 N 个点的点云。除了 XYZ 坐标之外,还为每个点添加一个高度特征,指示其到地板的距离。楼层高度估计为所有点高度的 1% 百分位。为了增强训练数据,动态地从场景点中随机地对点进行子采样。还在两个水平方向上随机翻转点云,围绕垂直轴随机旋转场景点 Uniform[−5°, 5°],并按 Uniform[0.9, 1.1] 随机缩放点。
Network architecture details. 主干特征学习网络基于PointNet ++ [36],它具有四个集合抽象(SA)层和两个特征传播/上采样(FP)层,其中SA层的接收半径逐渐增加为0.2、0.4、0.8和1.2米,同时它们将输入分别子采样为 2048、1024、512 和 256 点。两个 FP 层将第 4 个 SA 层的输出上采样回 1024 个点,具有 256 维特征和 3D 坐标。
投票层通过多层感知器实现,FC 输出大小为 256、256、259,其中最后一个 FC 层输出 XYZ 偏移和特征残差。
提案模块被实现为具有后处理 MLP2 的集合抽象层,以在最大池化后生成提案。 SA 使用半径 0.3 和 MLP1,输出大小为 128、128、128。最大池特征由 MLP2 进一步处理,输出大小为 128、128、5+2NH+4NS+NC,其中输出由 2 个对象分数组成,3 个中心回归值,用于标题回归的 2NH 数字(NH 标题 bins)和用于框大小回归的 4NS 数字(NS 框锚点)和用于语义分类的 NC 数字
Training the network. 使用 Adam 优化器、批量大小 8 和初始学习率 0.001 从头开始端到端地训练整个网络。学习率在 80 个 epoch 后降低 10×,然后在 120 个 epoch 后又降低 10×。
Inference. VoteNet 能够获取整个场景的点云并在一次前向传递中生成提案。这些提案由 IoU 阈值为 0.25 的 3D NMS 模块进行后处理。
结论
本文介绍了 VoteNet:一个简单但功能强大的 3D 对象检测模型,其灵感来自霍夫投票。该网络学习直接从点云投票给对象质心,并学习通过其特征和局部几何形状聚合投票以生成高质量的对象提案。该模型仅使用 3D 点云,与之前同时使用深度和彩色图像的方法相比有了显着改进。
在未来的工作中,打算探索如何将 RGB 图像合并到检测框架中,并在下游应用(例如 3D 实例分割)中利用本文的检测器。本文相信,霍夫投票和深度学习的协同作用可以推广到更多应用,例如 6D 姿态估计、基于模板的检测等,并期望看到更多沿着这方面的研究。