大规模机器学习
I recently started a new newsletter focus on AI education. TheSequence is a no-BS( meaning no hype, no news etc) AI-focused newsletter that takes 5 minutes to read. The goal is to keep you up to date with machine learning projects, research papers and concepts. Please give it a try by subscribing below:
我最近开始了一份有关AI教育的新时事通讯。 TheSequence是无BS(意味着没有炒作,没有新闻等),它是专注于AI的新闻通讯,需要5分钟的阅读时间。 目标是让您了解机器学习项目,研究论文和概念的最新动态。 请通过以下订阅尝试一下:
Uber has been one of the most active contributors to open source machine learning technologies in the last few years. While companies like Google or Facebook have focused their contributions in new deep learning stacks like TensorFlow, Caffe2 or PyTorch, the Uber engineering team has really focused on tools and best practices for building machine learning at scale in the real world. Technologies such as Michelangelo, Horovod, PyML, Pyro are some of examples of Uber’s contributions to the machine learning ecosystem. With only a small group of companies developing large scale machine learning solutions, the lessons and guidance from Uber becomes even more valuable for machine learning practitioners (I certainly learned a lot and have regularly written about Uber’s efforts).
在过去的几年中,Uber一直是开源机器学习技术最活跃的参与者之一。 虽然像Google或Facebook这样的公司将其贡献集中在TensorFlow,Caffe2或PyTorch等新的深度学习堆栈上,但Uber工程团队实际上专注于在现实世界中大规模构建机器学习的工具和最佳实践。 诸如Michelangelo , Horovod , PyML , Pyro之类的技术是Uber对机器学习生态系统做出贡献的一些例子。 由于只有一小部分公司开发大规模的机器学习解决方案,因此Uber的经验教训和指导对于机器学习从业人员来说变得更加有价值(我当然学到了很多东西,并定期撰写有关Uber努力的文章)。
Recently, the Uber engineering team published an evaluation of the first three years of operations of the Michelangelo platform. If we remove all the Michelangelo specifics, Uber’s post contains a few non-obvious, valuable lessons for organizations starting in their machine learning journey. I am going to try to summarize some of those key takeaways in a more generic way that can be applicable to any mainstream machine learning scenario.
最近, Uber工程团队发布了对米开朗基罗平台前三年运营的评估 。 如果我们删除所有米开朗基罗的细节,Uber的帖子将为组织从机器学习之旅开始的一些非显而易见的,有价值的课程。 我将尝试以更通用的方式总结其中的一些关键知识,这些方法可以适用于任何主流机器学习场景。
什么是米开朗基罗? (What is Michelangelo?)
Michelangelo is the center piece of the Uber machine learning stack. Conceptually, Michelangelo can be seen as a ML-as-a-Service platform for internal ML workloads at Uber. From the functional standpoint, Michelangelo automates different aspects of the lifecycle of ML models allowing different Uber’s engineering teams to build, deploy, monitor and operate ML models at scale. Specifically, Michelangelo abstracts the lifecycle of a ML models in a very sophisticated workflow:
米开朗基罗是Uber机器学习堆栈的核心部分。 从概念上讲,米开朗基罗可以看作是Uber内部ML工作负载的ML即服务平台。 从功能的角度来看,米开朗基罗实现了ML模型生命周期的各个方面的自动化,从而使不同的Uber工程团队可以大规模构建,部署,监控和操作ML模型。 具体来说,米开朗基罗在非常复杂的工作流程中抽象了ML模型的生命周期:
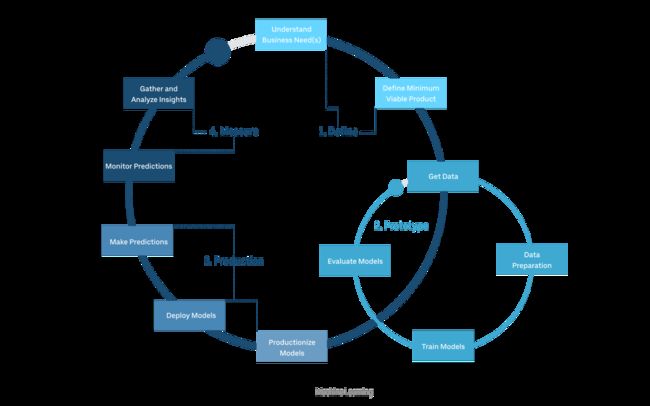
The architecture behind Michelangelo uses a modern but complex stack based on technologies such as HDFS, Spark, Samza, Cassandra, MLLib, XGBoost, and TensorFlow.
Michelangelo背后的体系结构使用了基于HDFS , Spark , Samza , Cassandra , MLLIb , XGBoost和TensorFlow等技术的现代而复杂的堆栈。
Michelangelo powers hundreds of machine learning scenarios across different divisions at Uber. For instance, Uber Eats uses machine learning models running on Michelangelo to rank restaurant recommendations. Similarly, the incredibly exact estimated time of arrivals(ETA) in the Uber app are calculated using incredibly sophisticated machine learning models running on Michelangelo that estimate ETAs segment-by-segment.
Michelangelo支持Uber不同部门的数百种机器学习场景。 例如,Uber Eats使用在米开朗基罗上运行的机器学习模型对餐厅推荐进行排名。 同样,使用在米开朗基罗上运行的极其复杂的机器学习模型(逐段估算ETA)来计算Uber应用程序中令人难以置信的准确估计到达时间(ETA)。
To enable this level of scalability across dozens of data science teams and hundreds of models, Michelangelo needs to provide a very flexible and scalable architecture as well as the corresponding engineering process. The first version of Michelangelo was deployed in 2015 and three years and hundreds of machine learning models later, there are a few important lessons Uber has learned.
为了在数十个数据科学团队和数百个模型之间实现这种级别的可伸缩性,米开朗基罗需要提供一个非常灵活和可伸缩的体系结构以及相应的工程流程。 米开朗基罗的第一个版本于2015年部署,三年后又部署了数百种机器学习模型,Uber从中吸取了一些重要的教训。
1-培训需要自己的基础架构 (1-Training Requires its Own Infrastructure)
If you are building a single model, you are tempted to leverage the same infrastructure and tooling for training and development. If you are building a hundred models, that approach doesn’t work. Uber’s Michelangelo, uses a proprietary toolset called the Data Science Workbench(DSW) to train models across large GPU clusters and different machine learning toolkits. Beyond the consistent infrastructure, Michelangelo’s DSW abstracts common tasks of machine learning training processes such as data transformation, model composition, etc.
如果要构建单个模型,则很容易利用相同的基础结构和工具进行培训和开发。 如果您要构建一百个模型,则该方法无效。 Uber的Michelangelo使用称为数据科学工作台(DSW)的专有工具集来在大型GPU集群和不同的机器学习工具包之间训练模型。 除了一致的基础架构,米开朗基罗的DSW还抽象了机器学习训练过程的常见任务,例如数据转换,模型组成等。
需要监控2个模型 (2-Models Need to be Monitored)
Paraphrasing one of my mentors in this space “models that make stupid predictions are worse than models than don’t predict at all”. Even models that performed impeccably against training and evaluation data can start making dumb predictions when faced with new datasets. From that perspective, model monitoring and instrumentation is a key component of real world machine learning solutions. Uber Michelangelo configures machine learning models to log predictions made in production and then compare them against actuals. This process produces a series of accuracy metrics that can be used to evaluate the performance of the models.
解释我在这个领域的一位导师“做出愚蠢的预测的模型要比根本没有预测的模型差”。 当面对新的数据集时,即使对训练和评估数据表现出色的模型也可以开始做出愚蠢的预测。 从这个角度来看,模型监视和检测是现实世界机器学习解决方案的关键组成部分。 Uber Michelangelo配置了机器学习模型来记录生产中的预测,然后将其与实际值进行比较。 此过程产生了一系列精度指标,可用于评估模型的性能。
3-数据是最难解决的问题 (3-Data is the Hardest Thing to Get Right)
In machine learning solutions, data engineers spend a considerable percentage of their time running extraction and transformation routines over datasets to select features that are then used by training and production models. Michelangelo approach to streamline this process was to build a common feature store that allow different teams to share high quality features across their models. Similarly, Michelangelo provides monitoring tools to evaluate specific features over time.
在机器学习解决方案中,数据工程师花费大量时间在数据集上运行提取和转换例程,以选择功能,然后再由训练和生产模型使用这些功能。 米开朗基罗简化这一过程的方法是建立一个通用的功能库,该功能库允许不同的团队在其模型之间共享高质量的功能。 同样,米开朗基罗(Michelangelo)提供了监视工具,可以随时间评估特定功能。
4机学习应作为软件工程过程来衡量 (4-Machine Learning Should be Measured as a Software Engineering Process)
I know it sounds trivial but it’s far from it. Most organizations, orchestrated their machine learning efforts separated from other software engineering tasks. It is true that is hard to adapt traditional agile or waterfall processes to machine learning solutions but there are plenty of software engineering practices that are relevant in the machine learning world. Uber enforces the view that machine learning is a software engineering process and has provisioned Michelangelo with a series of tools to enforce the correct lifecycle of machine learning models.
我知道这听起来很琐碎,但距离还很远。 大多数组织将其机器学习工作与其他软件工程任务分开安排。 的确很难使传统的敏捷或瀑布式流程适应机器学习解决方案,但是在机器学习领域中有许多相关的软件工程实践。 Uber认为机器学习是一个软件工程过程,并为Michelangelo提供了一系列工具来实施正确的机器学习模型生命周期。
Versioning, testing or deployment are some of the software engineering aspects that are rigorously enforced by Uber’s Michelangelo. For instance, once Michelangelo recognizes that a model is like a compiled software library, it keeps track of the model’s training configuration in a rigorous, version-controlled system in the same way that you version control the library’s source code. Similarly, Michelangelo runs comprehensive test suites evaluates models against holdout datasets before they are deployed to production trying to validate their correct functioning.
版本,测试或部署是Uber的Michelangelo严格执行的一些软件工程方面。 例如,一旦Michelangelo意识到模型就像一个编译的软件库,它就会在严格的版本控制的系统中跟踪模型的训练配置,就像对库的源代码进行版本控制一样。 同样,Michelangelo运行全面的测试套件,然后根据保持数据集评估模型,然后将其部署到生产中以验证其正确功能。
5,自动化优化 (5-Automating Optimization)
Fine tuning and optimizing hyperparameters is a never-ending task in machine learning solutions. Many times, data science engineers spend more time finding the right hyperparameter configuration than building the model itself. To address this challenge, Uber’s Michelangelo introduced an optimization-as-a-service tool called AutoTune which uses state-of-the-art black box Bayesian optimization algorithms to more efficiently search for an optimal set of hyperparameters. The idea of Michelangelo’s AutoTune is to use machine learning to optimize machine learning models allowing data science engineers to focus more time in the implementation of the models instead of their optimization.
在机器学习解决方案中,微调和优化超参数是一项永无止境的任务。 很多时候,数据科学工程师比建立模型本身花费更多的时间来寻找正确的超参数配置。 为了应对这一挑战,Uber的米开朗基罗推出了一种名为AutoTune的优化服务即服务工具,该工具使用最新的黑盒贝叶斯优化算法来更有效地搜索最优的超参数集。 Michelangelo的AutoTune的想法是使用机器学习来优化机器学习模型,从而使数据科学工程师可以将更多的时间投入到模型的实现上,而不是对其进行优化。
From a machine learning perspective, Uber can be considered one of the richest lab environments in the world. The scale and sophistication of the tasks tackled by Uber’s data scientists is second to none in the industry. The first three years of operation of Michelangelo have certainly showed that implementing large-scale machine learning solutions is still an incredibly complicated effort. The lessons learned from Michelangelo are an incredible source of insights for organization embarking in their machine learning journey.
从机器学习的角度来看,Uber被认为是世界上最丰富的实验室环境之一。 Uber数据科学家所处理任务的规模和复杂程度在业内是首屈一指的。 Michelangelo运行的头三年肯定表明,实施大规模机器学习解决方案仍然是一项极其复杂的工作。 从米开朗基罗中学到的经验教训对于组织开展机器学习之旅而言是令人难以置信的见解之源。
翻译自: https://medium.com/swlh/5-lessons-uber-learned-from-running-machine-learning-at-scale-1c2fe2e0b8ef
大规模机器学习