博通BCM575系列RDMA网卡驱动bnxt_re分析(一)
简介
整个BCM系列驱动分成以太网部分(bnxt_en.ko)和RDMA部分(bnxt_re.ko), 两个模块之间通过内核的auxiliary_bus进行管理.我们主要分析下bnxt_re驱动.
代码结构
这个驱动的核心是 qplib_fp.c, 这个文件主要包含了驱动的数据路径, 包括Post Send, Post Recv, Poll CQ流程的实现. ib_verbs.c主要是实现了上层的Verbs接口, qplib_rcfw.c 实现了驱动和固件通信的部分, qplib_res.c 实现了核心资源的初始化和分配函数.
整个驱动四万多行代码, 每个小模块精密合作共同构成了这个性能利器.
Page Buffer List(PBL)
在Infiniband中QP接收用户发送的命令, 硬件处理QP中的命令. 处理完成后硬件将结果写入CQ, 用户Poll CQ去取命令执行结果. 这整个过程需要固件和驱动的协作, QP和CQ应该怎么实现, 才能保证硬件和驱动高效协作以实现RoCE的高带宽和低时延将数据包快速可靠的交付给用户呢 ?
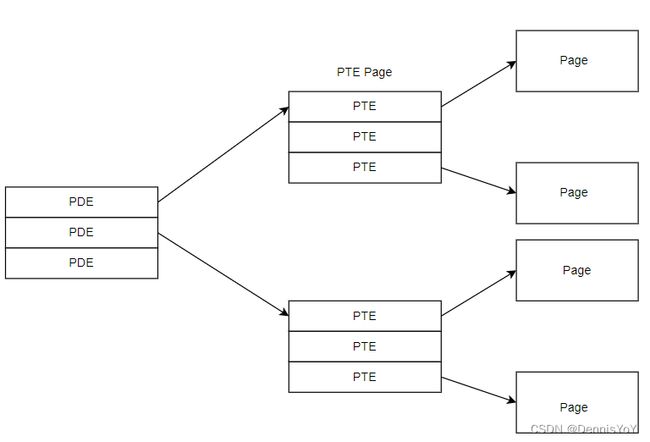
在bnxt_re中, 实现这个目标的方法是Page Buffer List(PBL), 驱动使用PBL作为核心去实现QP, CQ等核心资源, PBL使用类似页表的结构去管理DMA Buffer. PBL用来管理多个物理Page, 类似scatter-gather列表, 通过PBL将多个物理不连续的页组织成一个虚拟连续的空间.Page Table Entry(PTE)用来描述一个物理页面, 一个一级的PBL如下图所示, 通过多个vmalloc出来的PTE结构来描述多个物理页面.

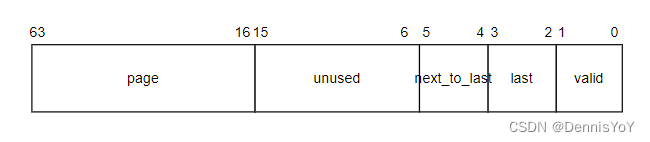
PTE长度为64位, 格式如下图所示, page表示页号, 共52位. next_to_last为1表示PTE指向的页是PBL的倒数第二个页, last为1表示PTE指向的页是PBL的最后一个页,
二级PBL使用两次遍历去找到最终的页, 第一次使用Page Directory Entry(PDE)找到存储PTE的页, 在使用PTE找到最终的数据页.
page字段表示PTE Page地址的高位, 如果PTE页的大小超过了4K(用来描述页的PDE会变少), page低位应该置为0.valid表示PDE是否指向了一个有效的PTE Page.
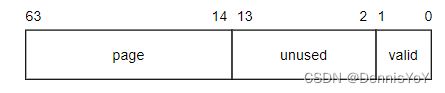
有效位
类似内核页表的有效位, PBL的valid的含义和内核页表类似, 表示PTE描述的页面是否有效. 避免在一开始就分配一大片的Page, 提高性能, 并且降低资源浪费.
队列PBL
有些PBL用来描述队列, 当PBL被缓存到硬件cache的时候, current和next指针可以被保存, 用来提高cache利用率(通过预取next指针到硬件cache). 但是如果是环形队列最后一个元素, 这种prefetch机制可能会遇到一些障碍, 为了顺利的进行prefetch操作, 在PTE中加入了next_to_last指向PBL表中倒数第二个Page, last表示PTE指向队列最后一个Page.
实现原理
以一级PBL为例讲解下PBL的实现原理, 从上图中我们可以看到要实现一级PBL我们需要一片内存去存储PTE, 实际驱动中会先计算出占用的内存的大小, 然后计算出需要多少个Page, 再计算需要多少个PBL去管理这些Page. 一个4K页最多存储512个指针(4K / 8). 因此使用PBL的数量, 通过下面的方式计算得出:
npbl = npages >> 9;
if (npages % BIT(9))
npbl++;
bnxt_qplib_pbl
一个PBL结构用来描述多个Page, 其中pg_arr用来存储页面的CPU地址, pg_map_arr用来存储页面的DMA地址.
struct bnxt_qplib_pbl {
//PBL管理的页面数量
u32 pg_count;
//每个页的大小
u32 pg_size;
//存储PBL管理的Page的首地址
void **pg_arr;
//Page首地址的DMA表示
dma_addr_t *pg_map_arr;
};
PBL的创建和初始化
PBL结构嵌入到HWQ中使用, 根据页的数量分配DMA内存.
struct bnxt_qplib_hwq {
struct bnxt_qplib_pbl pbl[PBL_LVL_MAX];
};
int __alloc_pbl(struct bnxt_qplib_res *res, struct bnxt_qplib_pbl *pbl,
struct bnxt_qplib_sg_info *sginfo)
{
struct pci_dev *pdev;
int i;
if (sginfo->nopte)
return 0;
pdev = res->pdev;
//分配PBL表
pbl->pg_arr = vmalloc(sginfo->npages * sizeof(void *));
if (!pbl->pg_arr)
return -ENOMEM;
//存储dma地址
pbl->pg_map_arr = vmalloc(sginfo->npages * sizeof(dma_addr_t));
if (!pbl->pg_map_arr) {
vfree(pbl->pg_arr);
return -ENOMEM;
}
//初始化页面数为0, pg_size等于要管理的sg的页面大小
pbl->pg_count = 0;
pbl->pg_size = sginfo->pgsize;
if (!sginfo->sghead) {
//从DMA_ZONE分配空间给Page
for (i = 0; i < sginfo->npages; i++) {
pbl->pg_arr[i] = msdrv_dma_alloc_coherent(&pdev->dev,
pbl->pg_size,
&pbl->pg_map_arr[i],
GFP_KERNEL);
if (!pbl->pg_arr[i])
goto fail;
memset(pbl->pg_arr[i], 0, pbl->pg_size);
pbl->pg_count++;
}
}
return 0;
fail:
__free_pbl(res, pbl, is_umem);
return -ENOMEM;
}
PBL_LVL_0表示描述PTE Page的PBL, PBL_LVL_1表示描述数据Page的PBL, 整个过程就是把数据Page的DMA地址 | flag, 然后写入到PTE中的过程. 对于队列类型的HWQ, 还需要将PTE Page的最后两项写入魔数PTU_PTE_NEXT_TO_LAST和PTU_PTE_LAST.
/* Fill PBL with PTE pointers */
dst_virt_ptr =
(dma_addr_t **)hwq->pbl[PBL_LVL_0].pg_arr;
src_phys_ptr = hwq->pbl[PBL_LVL_1].pg_map_arr;
for (i = 0; i < hwq->pbl[PBL_LVL_1].pg_count; i++)
//只有将地址写入到DMA内存中, PTE才算生效
dst_virt_ptr[PTR_PG(i)][PTR_IDX(i)] =
src_phys_ptr[i] | flag;
if (hwq_attr->type == HWQ_TYPE_QUEUE) {
/* Find the last pg of the size */
i = hwq->pbl[PBL_LVL_1].pg_count;
dst_virt_ptr[PTR_PG(i - 1)][PTR_IDX(i - 1)] |=
PTU_PTE_LAST;
if (i > 1)
dst_virt_ptr[PTR_PG(i - 2)]
[PTR_IDX(i - 2)] |=
PTU_PTE_NEXT_TO_LAST;
}
PBL实现了结合了scatter-gather list和页表的优点, 实现了一个拓展性好, 且虚拟连续的内存空间.
Hardware Queue(HWQ)
HWQ是驱动中抽象出来的生产者-消费者队列, 实体是由PBL. 队列中每个元素的大小是16字节(stride=(sizeof sq_sge)), 在代码中一个元素被称为一个slot. 一个Page最多能容纳, 4K/16=256个slot. 下图是HWQ被封装后的示意图, 通过指针cons和prod的挪动实现了一个生产者-消费者队列.
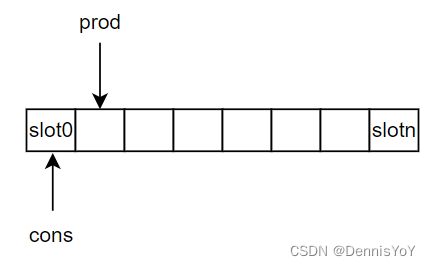
原理
HWQ的底层是通过PBL实现, 在访问时需要将slot id翻译成对应的PBL的页号和页内偏移, 如下所示, pg_num就是页号, pg_idx就是在页面内的slot偏移.
void *bnxt_qplib_get_qe(struct bnxt_qplib_hwq *hwq,
u32 indx, u64 *pg)
{
u32 pg_num, pg_idx;
pg_num = (indx / hwq->qe_ppg);
pg_idx = (indx % hwq->qe_ppg);
if (pg)
*pg = (u64)&hwq->pbl_ptr[pg_num];
return (void *)(hwq->pbl_ptr[pg_num] + hwq->element_size * pg_idx);
}
通过这样的读写方式, 我们可以将PBL抽象成下面的形式, 我们可以看到多个物理不连续的页面, 被划分成了连续的slot. 这些slot的数量就是HWQ的深度.
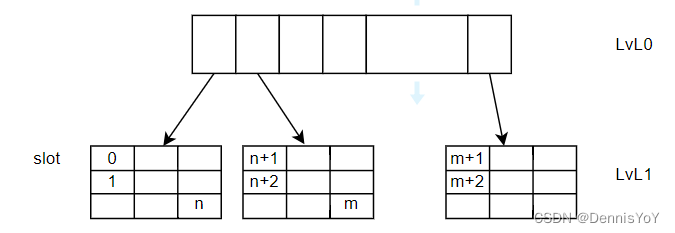
以下就是HWQ的实现, 其中pbl_ptr和pbl_dma_ptr存储了物理页面的首地址, depth是队列深度, element_size是每个slot的大小, qe_ppg表示每个页面能容纳多少个slot.
struct bnxt_qplib_hwq {
struct pci_dev *pdev;
spinlock_t lock;
struct bnxt_qplib_pbl pbl[PBL_LVL_MAX];
enum bnxt_qplib_pbl_lvl level; /* 0, 1, or 2 */
void **pbl_ptr; /* ptr for easy access
to the PBL entries */
dma_addr_t *pbl_dma_ptr; /* ptr for easy access
to the dma_addr */
u32 max_elements;
u32 depth; /* original requested depth */
u16 element_size; /* Size of each entry */
u16 qe_ppg; /* queue entry per page */
u32 prod; /* raw */
u32 cons; /* raw */
};
参考
https://lore.kernel.org/all/[email protected]/