zset类型的底层数据结构的实现
参考资料:
redis中zset底层实现原理_渣渣-CSDN博客_zset底层数据结构
redis的zset数据结构:跳表 - 知乎
zset类型的底层数据结构的实现?
zset是Redis提供的一个非常特别的数据结构,常用作排行榜等功能,以用户id为value,关注时间或者分数作为score进行排序。与其他数据结构相似,zset也有两种不同的实现,分别是zipList和skipList。
数据结构
跳表(skiplist)是一个查询/插入/删除 复杂度o(lgn)的数据结构。在查询上跟平衡树的复杂度一致,因此是替代平衡树的方案。在redis的zset,leveldb都有应用。
跳表skipList在Redis中的运用场景只有一个,那就是作为有序列表zset的底层实现。
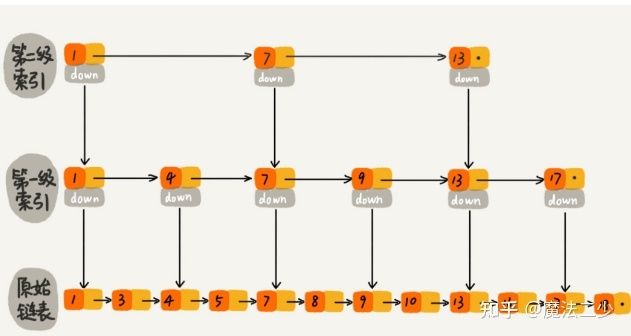
跳表如何构建
当插入一个数据时,随机获得这个节点的高度,没错,就是随机!每涨一层的概率为p,这个认为设置,一般为0.25或者0.5,这样层数越高的节点就越少(这种结构跟平衡树有点像)。
如何搜索
如上图所示,我们检索19这个值,遍历路径如下图所示

可以看到高层级的节点相当于一个快速通道,让搜索进行了节点的跳跃,而不是一个个的遍历。

什么是zset
zset是redis中一种有序、不重复的数据类型,每个元素都有一个分值,它可用于实现排行榜单,其底层采用压缩表ziplist或跳表skiplist的数据结构实现
zset的两种数据结构
-
压缩表ziplist
当redis插入第一个元素时,同时满足以下条件,就会以ziplist创建跳表
-
节点数量<128 (可通过server.zset_max_ziplist_entries设置)
-
节点的长度<64(可通过server.zset_max_ziplist_value设置)
当选择用ziplist实现zset后,以后插入的节点若不满足以上任一个条件,就会转为skiplist
-
跳表skiplist
跳表的本质是一个多层链表,它能快速地查询、插入、删除【时间复杂度均为O(logn)】,所以它的查询速度媲美平衡二叉树,而且它的数据结构比平衡二叉树简单,结构示意图如下:
特点:
-
跳表的最底层拥有所有的元素
-
跳表每一层都是一个链表,除了最底层是原始链表,层次逐渐往上可分别划分为一级索引层、二级索引层...
-
跳表插入元素时,会先随机生成出一个“层次数字”,然后元素会插入到这个层次的所有底层,直到原始链表层
-
如果一个元素存在与某个索引层,那么这个元素也会存在于低于它的所有索引下层,如元素在第99索引层,那么由上到下从99索引层直到原始链表层都会存在该元素
-
空间换时间,跳表查找变快了,但是要存储许多索引层,故空间开销变大了
/**
* 产生节点的高度。使用抛硬币
*
* @return
*/
private int getRandomLevel() {
//可知,元素的插入层次i从1开始自增,随机到哪一层的概率就像抛硬币一样,都是50%,故i越往后,其概率越小(每次都*0.5)
//第一层概率:0.5,第二层0.5*0.5=0.25,...
int lev = 1;
while (random.nextInt() % 2 == 0) {
lev++;
}
//MAX_LEVEL为跳表的最大层级
return lev > MAX_LEVEL ? MAX_LEVEL : lev;
}
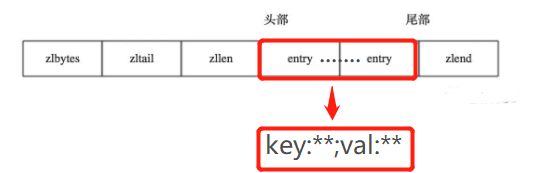
压缩列表ziplist
ziplist 编码的 Zset 使用紧挨在一起的压缩列表节点来保存,第一个节点保存 member,第二个保存 score。ziplist 内的集合元素按 score 从小到大排序,其实质是一个双向链表。虽然元素是按 score 有序排序的, 但对 ziplist 的节点指针只能线性地移动,所以在 REDIS_ENCODING_ZIPLIST 编码的 Zset 中, 查找某个给定元素的复杂度为 O(N)。

跳表skiplist
-
插入节点
-
插入的时间复杂度为O(logn),每次插入都会先查找到要插入的位置(查找的时间复杂度就已经是【O(logn)】了,找到后直接插入【O(1)】,所以总的为【O(logn)】),删除也是同理为O(logn)
-
每个节点的插入层次是通过getRandomLevel()随机出来的,插入层次互不影响 以下模拟节点插入:
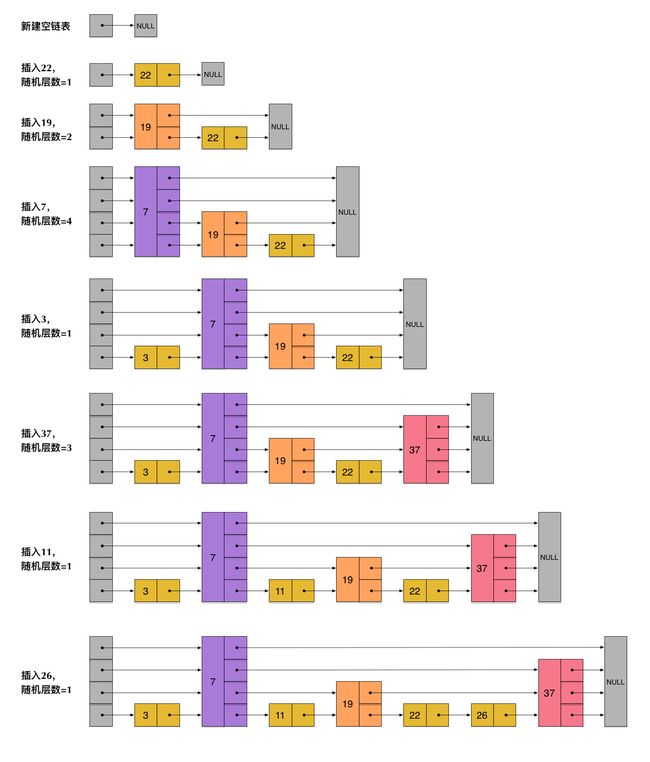
从上面skiplist的创建和插入过程可以看出,每一个节点的层数(level)是随机出来的,而且新插入一个节点不会影响其它节点的层数。因此,插入操作只需要修改插入节点前后的指针,而不需要对很多节点都进行调整。这就降低了插入操作的复杂度。实际上,这是skiplist的一个很重要的特性,这让它在插入性能上明显优于平衡树的方案。 skiplist,指的就是除了最下面第1层链表之外,它会产生若干层稀疏的链表,这些链表里面的指针故意跳过了一些节点(而且越高层的链表跳过的节点越多)。这就使得我们在查找数据的时候能够先在高层的链表中进行查找,然后逐层降低,最终降到第1层链表来精确地确定数据位置。在这个过程中,我们跳过了一些节点,从而也就加快了查找速度。
-
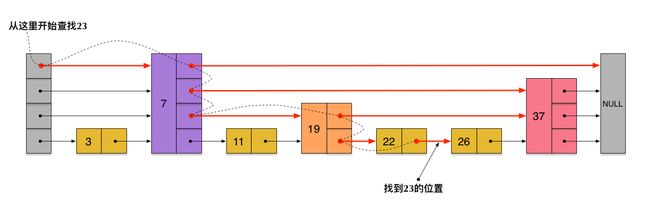
查找
查找节点时,从高索引层往低索引层查找: 一开始元素在高层从链表由前往后查找,直到要查找的目标元素在该层的某两个相邻元素之间,就会往下跳到下层的同一个位置,继续从同一位置向链表尾方向遍历查询->重复上面的过程,直到查找到目标元素 查找时每一层都跳过部分元素,进而加快了查找效率,以下模拟节点查找:
执行插入操作时计算随机数的过程,是一个很关键的过程,它对skiplist的统计特性有着很重要的影响。这并不是一个普通的服从均匀分布的随机数,它的计算过程如下:
首先,每个节点肯定都有第1层指针(每个节点都在第1层链表里)。 如果一个节点有第i层(i>=1)指针(即节点已经在第1层到第i层链表中),那么它有第(i+1)层指针的概率为p。 节点最大的层数不允许超过一个最大值,记为MaxLevel。 这个计算随机层数的伪码如下所示:
randomLevel() level := 1 // random()返回一个[0...1)的随机数 while random() < p and level < MaxLevel do level := level + 1 return level
randomLevel()的伪码中包含两个参数,一个是p,一个是MaxLevel。在Redis的skiplist实现中,这两个参数的取值为:
p = 1/4 MaxLevel = 32