python面向对象
目录
知识点小结
面向对象基础
1. 初识面向对象
1.1 对象和self
1.2 常见成员
1.3 应用示例
2. 三大特性
2.1 封装
2.2 继承
练习题
2.3 多态
3. 扩展:再看数据类型
总结
面向对象进阶
1.成员
1.1 变量
1.2 方法
1.3 属性
2.成员修饰符
3.对象嵌套
4.特殊成员
总结
面向对象高级和应用
1. 继承【补充】
1.1 mro和c3算法
1.2 py2和py3区别(了解)
2. 内置函数补充
3.异常处理
3.1 异常细分
3.2 自定义异常&抛出异常
3.4 特殊的finally
练习题
4.反射
4.1 一些皆对象
4.2 import_module + 反射
总结
知识点小结
该处仅用于快速复习,详细知识及代码如何编写点请跳过。
Python中支持两种编程方式来写代码,分别是:函数式编程、面向对象式编程。
声明一个类:class Ok: 或class Ok() 或 class Ok(object) ,py3默认继承object,新式类,py2,经典类。
1.根据类型创建一个对象,内存的一块区域 。
2.执行__init__方法,模块会将创建的那块区域的内存地址当self参数传递进去。
self是什么?
self是一个参数,在通过 对象.方法 的方式去执行方法时,这个参数会被python自动传递(值为调用当前方法的对象)
即使第一个参数不写self,如改写成qqqq,此时qqqq即为self。
什么是对象?
对象,基于类实例化出来”一块内存“,默认里面没有数据;经过类的
__init__方法,可以在内存中初始化一些数据。
什么时候用面向对象编程好一些?
仅做数据封装。
封装数据 + 方法再对数据进行加工处理。
创建同一类的数据且同类数据可以具有相同的功能(方法)。
三大特性:封装 继承 多态
- 封装,将方法封装到类中 或 将数据封装到对象中,便于以后使用。
- 继承,将类中的公共的方法提取到基类中去实现。
- 多态,Python默认支持多态(这种方式称之为鸭子类型),最简单的基础下面的这段代码即可。
def func(arg):
v1 = arg.copy() # 浅拷贝 即要能执行这种方法,不然会报错。
print(v1)
成员: 实例变量 类变量,绑定方法 类方法 静态方法,属性。
class Ok:
country = 'china'
def __init__(self,name):
self.name = name
def fuc1(self):
print('这是绑定方法')
@classmethod
def fuc2(cls):
print('这是类方法')
@staticmethod
def fuc3():
print('这是静态方法')
@property
def fuc4(self):
print('这是属性')
分清楚每一步修改或者增加的是那里的对象
class People:
country = 'china'
def __init__(self, name='未输入', age=18):
self.name = name
self.age = age
def fuc1(self):
print(self.name, self.age)
person1 = People('卢本伟', 18)
print(person1.country) # china 对象中没有 会向类变量中寻找
person1.name = 'lbw' #将对象中的name变量修改
person1.country = '中国' #对象中没有country 会创建一个country对其进行赋值
print(person1.name, person1.age, person1.country, People.country) #lbw 18 中国 chinaclass People:
country = 'china'
def __init__(self, name='未输入', age=18):
self.name = name
self.age = age
def fuc1(self):
print(self.name, self.age, self.country)
class Ok(People):
name = 'nihao'
def fuc2(self):
print(self.name, self.age, self.country)
@classmethod
def fuc3(cls):
print(cls.name)
person = Ok('周润发', 19) # 相当于自己的类在有一个init
person.fuc1() # 周润发 19 china self是自己的优先在Ok里找
person.fuc2() # 周润发 19 china
person.fuc3() # 你好
Ok.country = '韩国' #添加类变量 优先找实例变量->自己的类变量->父类类变量
Ok.name = '不知道'
person.fuc1() # 周润发 19 韩国
person.fuc2() # 周润发 19 韩国
person.name = '卢本伟'
person.country = '日本' # 对象中添加了实例变量country
print(People.country, Ok.country) # china 韩国
person.fuc1() # 卢本伟 19 日本
person.fuc2() # 卢本伟 19 日本编写属性的方式有哪些?
(点击目录 属性 跳转)
成员修饰符(公有/私有)
对于私有成员,在成员名字前加两道下划线__,即为私有。
class Ok:
def __init__(self, name='未输入', age=18):
self.__name = name
self.age = age
def __fuc1(self):
pass
def fuc2(self):
self.__name = 'lbw'
print(self.__name)
class Yes(Ok):
def fuc3(self):
print(self.__name) #这样不执行不会报错
k = Ok('周润发')
k.fuc2() #lbw
print(k.age) #18
kk = Yes()
kk.fuc3() #在这里会报错 子类也无法调用父类的自私有变量/方法注意:要看self写在哪个类里
class Base(object):
def __data(self):
print("base.__data")
def num(self):
print("base.num")
self.__data()
class Foo(Base):
def func(self):
self.num()
obj = Foo()
obj.func()
'''
base.num
base.__data
虽然self一直都是Foo实例化的对象的,但其在调用__data时,是在Base类内部调用的
'''写在最后,按理说私有成员是无法被外部调用,但如果用一些特殊的语法也可以(Flask源码中有这种写法,大家写代码不推荐这样写)。
class Foo(object):
def __init__(self):
self.__num = 123
self.age = 19
def __msg(self):
print(1234)
obj = Foo()
print(obj.age)
print(obj._Foo__num)
obj._Foo__msg()特殊成员
new init call str dict add getitem setitem delitem enter exit iter
要明白每个的作用 去目录跳转查看 迭代器 生成器 可迭代对象 等的内容
class IT(object):
def __init__(self):
self.counter = 0
def __iter__(self):
return self
def __next__(self):
self.counter += 1
if self.counter == 3:
raise StopIteration()
return self.counter
class Foo(object):
def __iter__(self):
return IT()
obj = Foo() # 可迭代对象
for item in obj: # 循环可迭代对象时,内部先执行obj.__iter__并获取迭代器对象;不断地执行迭代器对象的next方法。
print(item)mro和c3算法
继承关系 :从左到右,深度优先,大小钻石,留住顶端
内置函数补充:classmethod、staticmethod、property、callable、super 、type 、isinstance 、issubclass
异常处理写法和细分
面向对象基础
目标:了解面向对象并可以根据面向对象知识进行编写代码。
概要:
-
初识面向对象
-
三大特性(面向对象)
-
封装
-
继承
-
多态
-
-
再看数据类型
1. 初识面向对象
想要通过面向对象去实现某个或某些功能时需要2步:
-
定义类,在类中定义方法,在方法中去实现具体的功能。
-
实例化类并的个一个对象,通过对象去调用并执行方法。
class Message:
def send_email(self, email, content):
data = "给{}发邮件,内容是:{}".format(email,content)
print(data)
msg_object = Message() # 实例化一个对象 msg_object,创建了一个一块区域。
msg_object.send_email("[email protected]","注册成功")
注意:1.类名称首字母大写&驼峰式命名;2.py3之后默认类都继承object;3.在类种编写的函数称为方法;4.每个方法的第一个参数是self。
类中可以定义多个方法,例如:
class Message:
def send_email(self, email, content):
data = "给{}发邮件,内容是:{}".format(email, content)
print(data)
def send_wechat(self, vid, content):
data = "给{}发微信,内容是:{}".format(vid, content)
print(data)
msg_object = Message()
msg_object.send_email("[email protected]", "注册成功")
msg_object.send_wechat("lbw", "注册成功")
你会发现,用面向对象编程写的类有点像归类的意思:将某些相似的函数划分到一个类中。
但,这种编写方式让人感觉有些鸡肋,直接用 函数 写多好呀。对吧?
别着急,记者往下看。
1.1 对象和self
在每个类中都可以定义个特殊的:__init__ 初始化方法,在实例化类创建对象时自动执行,即:对象=类()。
class Message:
def __init__(self, content):
self.data = content
def send_email(self, email):
data = "给{}发邮件,内容是:{}".format(email, self.data)
print(data)
def send_wechat(self, vid):
data = "给{}发微信,内容是:{}".format(vid, self.data)
print(data)
# 对象 = 类名() # 自动执行类中的 __init__ 方法。
# 1. 根据类型创建一个对象,内存的一块 区域 。
# 2. 执行__init__方法,模块会将创建的那块区域的内存地址当self参数传递进去。 往区域中(data="注册成功")
msg_object = Message("注册成功")
msg_object.send_email("[email protected]") # 给[email protected]发邮件,内容是:注册成功
msg_object.send_wechat("lbw") # 给lbw发微信,内容是:注册成功
通过上述的示例,你会发现:
-
对象,让我们可以在它的内部先封装一部分数据,以后想要使用时,再去里面获取。
-
self,类中的方法需要由这个类的对象来触发并执行( 对象.方法名 ),且在执行时会自动将对象当做参数传递给self,以供方法中获取对象中已封装的值。
注意:除了self默认参数以外,方法中的参数的定义和执行与函数是相同。
当然,根据类也可以创建多个对象并执行其中的方法,例如:
class Message:
def __init__(self, content):
self.data = content
def send_email(self, email):
data = "给{}发邮件,内容是:{}".format(email, self.data)
print(data)
def send_wechat(self, vid):
data = "给{}发微信,内容是:{}".format(vid, self.data)
print(data)
msg_object = Message("注册成功")
msg_object.send_email("[email protected]") # 给[email protected]发邮件,内容是:注册成功
msg_object.send_wechat("xxx")
login_object = Message("登录成功")
login_object.send_email("[email protected]") # 给[email protected]发邮件,内容是:登录成功
login_object.send_wechat("xxx")
面向对象的思想:将一些数据封装到对象中,在执行方法时,再去对象中获取。
函数式的思想:函数内部需要的数据均通过参数的形式传递。
-
self,本质上就是一个参数。这个参数是Python内部会提供,其实本质上就是调用当前方法的那个对象。
-
对象,基于类实例化出来”一块内存“,默认里面没有数据;经过类的
__init__方法,可以在内存中初始化一些数据。
1.2 常见成员
在编写面向对象相关代码时,最常见成员有:
-
实例变量,属于对象,只能通过对象调用。
-
绑定方法,属于类,通过对象调用 或 通过类调用。
注意:还有很多其他的成员,后续再来介绍。
class Person:
def __init__(self, n1, n2):
# 实例变量
self.name = n1
self.age = n2
# 绑定方法
def show(self):
msg = "我叫{},今年{}岁。".format(self.name, self.age)
print(msg)
def all_message(self):
msg = "我是{}人,我叫{},今年{}岁。".format(Person.country, self.name, self.age)
print(msg)
def total_message(self):
msg = "我是{}人,我叫{},今年{}岁。".format(self.country, self.name, self.age)
print(msg)
# 执行绑定方法
p1 = Person("lbw",20)
p1.show()
# 或
# p1 = Person("lbw",20)
# Person.show(p1)
# 初始化,实例化了Person类的对象叫p1
p1 = Person("lbw",20)
1.3 应用示例
-
将数据封装到一个对象,便于以后使用。
class UserInfo: def __init__(self, name, pwd,age): self.name = name self.password = pwd self.age = age def run(): user_object_list = [] # 用户注册 while True: user = input("用户名:") if user.upper() == "Q": break pwd = input("密码") # user_object对象中有:name/password user_object = UserInfo(user, pwd,19) # user_dict = {"name":user,"password":pwd} user_object_list.append(user_object) # user_object_list.append(user_dict) # 展示用户信息 for obj in user_object_list: print(obj.name, obj.password) 总结: - 数据封装到对象,以后再去获取。 - 规范数据(约束)注意:用字典也可以实现做封装,只不过字典在操作值时还需要自己写key,面向对象只需要
.即可获取对象中封装的数据。 -
将数据分装到对象中,在方法中对原始数据进行加工处理。
user_list = ["用户-{}".format(i) for i in range(1,3000)] # 分页显示,每页显示10条 while True: page = int(input("请输入页码:")) start_index = (page - 1) * 10 end_index = page * 10 page_data_list = user_list[start_index:end_index] for item in page_data_list: print(item)class Pagination: def __init__(self, current_page, per_page_num=10): self.per_page_num = per_page_num if not current_page.isdecimal(): self.current_page = 1 return current_page = int(current_page) if current_page < 1: self.current_page = 1 return self.current_page = current_page def start(self): return (self.current_page - 1) * self.per_page_num def end(self): return self.current_page * self.per_page_num user_list = ["用户-{}".format(i) for i in range(1, 3000)] # 分页显示,每页显示10条 while True: page = input("请输入页码:") # page,当前访问的页码 # 10,每页显示10条数据 # 内部执行Pagination类的init方法。 pg_object = Pagination(page, 20) page_data_list = user_list[ pg_object.start() : pg_object.end() ] for item in page_data_list: print(item)还有这个示例:将数据封装到一个对象中,然后再方法中对已封装的数据进行操作。
import os import requests class DouYin: def __init__(self, folder_path): self.folder_path = folder_path if not os.path.exists(folder_path): os.makedirs(folder_path) def download(self, file_name, url): res = requests.get( url=url, headers={ "user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36 FS" } ) file_path = os.path.join(self.folder_path, file_name) with open(file_path, mode='wb') as f: f.write(res.content) f.flush() def multi_download(self, video_list): for item in video_list: self.download(item[0], item[1]) if __name__ == '__main__': douyin_object = DouYin("videos") douyin_object.download( "罗斯.mp4", "https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0200f240000buuer5aa4tij4gv6ajqg" ) video_list = [ ("a1.mp4", "https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0300fc20000bvi413nedtlt5abaa8tg"), ("a2.mp4", "https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0d00fb60000bvi0ba63vni5gqts0uag"), ("a3.mp4", "https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0200f240000buuer5aa4tij4gv6ajqg") ] douyin_object.multi_download(video_list) -
根据类创建多个对象,在方法中对对象中的数据进行修改。
class Police: """警察""" def __init__(self, name, role): self.name = name self.role = role if role == "队员": self.hit_points = 200 else: self.hit_points = 500 def show_status(self): """ 查看警察状态 """ message = "警察{}的生命值为:{}".format(self.name, self.hit_points) print(message) def bomb(self, terrorist_list): """ 投炸弹,炸掉恐怖分子 """ for terrorist in terrorist_list: terrorist.blood -= 200 terrorist.show_status() class Terrorist: """ 恐怖分子 """ def __init__(self, name, blood=300): self.name = name self.blood = blood def shoot(self, police_object): """ 开枪射击某个警察 """ police_object.hit_points -= 5 police_object.show_status() self.blood -= 2 def strafe(self, police_object_list): """ 扫射某些警察 """ for police_object in police_object_list: police_object.hit_points -= 8 police_object.show_status() def show_status(self): """ 查看恐怖分子状态 """ message = "恐怖分子{}的血量值为:{}".format(self.name, self.blood) print(message) def run(): # 1.创建3个警察 p1 = Police("lbw", "队员") p2 = Police("uzi", "队员") p3 = Police("mlxg", "队长") # 2.创建2个匪徒 t1 = Terrorist("alex") t2 = Terrorist("eric") # alex匪徒射击mlxg警察 t1.shoot(p3) # alex扫射 t1.strafe([p1, p2, p3]) # eric射击uzi t2.shoot(p2) # lbw炸了那群匪徒王八蛋 p1.bomb([t1, t2]) # lbw又炸了一次alex p1.bomb([t1]) if __name__ == '__main__': run()
总结:
-
仅做数据封装。
-
封装数据 + 方法再对数据进行加工处理。
-
创建同一类的数据且同类数据可以具有相同的功能(方法)。
2. 三大特性
面向对象编程在很多语言中都存在,这种编程方式有三大特性:封装、继承、多态。
2.1 封装
封装主要体现在两个方面:
-
将同一类方法封装到了一个类中,例如上述示例中:匪徒的相关方法都写在Terrorist类中;警察的相关方法都写在Police类中。
-
将数据封装到了对象中,在实例化一个对象时,可以通过
__init__初始化方法在对象中封装一些数据,便于以后使用。
2.2 继承
传统的理念中有:儿子可以继承父亲的财产。
在面向对象中也有这样的理念,即:子类可以继承父类中的方法和类变量(不是拷贝一份,父类的还是属于父类,子类可以继承而已)。
父类 子类 基类 派生类
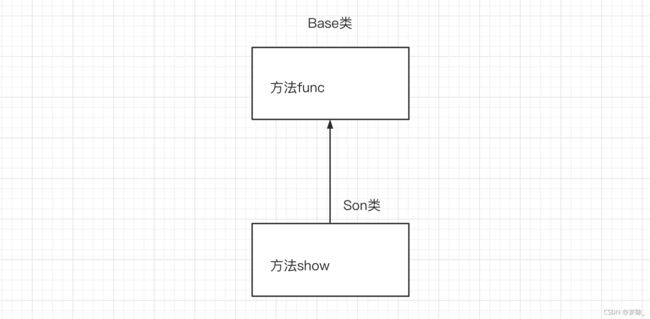
class Base:
def func(self):
print("Base.func")
class Son(Base):
def show(self):
print("Son.show")
s1 = Son()
s1.show()
s1.func() # 优先在自己的类中找,自己没有才去父类。
s2 = Base()
s2.func()
class Base:
def f1(self):
pass
class Foo(Base):
def f2(self):
pass
class Bar(Base):
def f3(self):
pass
o1 = Foo()
o1.f2()
o1.f1()
练习题
class Base:
def f1(self):
print('base.f1')
class Foo(Base):
def f2(self):
print('foo.f2')
obj = Foo()
obj.f1()
obj.f2()
class Base:
def f1(self):
print('base.f1')
class Foo(Base):
def f2(self):
print('before')
self.f1() # 调用了f1方法 obj.f1()
print('foo.f2')
obj = Foo()
obj.f2()
>>> before
>>> base.f1
>>> foo.f2
class Base:
def f1(self):
print('base.f1')
class Foo(Base):
def f2(self):
print("before")
self.f1() # obj,Foo类创建出来的对象。 obj.f1
print('foo.f2')
def f1(self):
print('foo.f1')
obj = Foo()
obj.f1() # obj对象到底是谁?优先就会先去谁里面找。
obj.f2()
>>> before
>>> foo.f1
>>> foo.f2
class Base:
def f1(self):
print('before')
self.f2() # slef是obj对象(Foo类创建的对象) obj.f2
print('base.f1')
def f2(self):
print('base.f2')
class Foo(Base):
def f2(self):
print('foo.f2')
obj = Foo()
obj.f1() # 优先去Foo类中找f1,因为调用f1的那个对象是Foo类创建出来的。
>>> before
>>> foo.f2
>>> base.f1
b1 = Base()
b1.f1()
>>> before
>>> base.f2
>>> base.f1
class TCPServer:
def f1(self):
print("TCPServer")
class ThreadingMixIn:
def f1(self):
print("ThreadingMixIn")
class ThreadingTCPServer(ThreadingMixIn, TCPServer):
def run(self):
print('before')
self.f1()
print('after')
obj = ThreadingTCPServer()
obj.run()
>>> before
>>> ThreadingMixIn
>>> after
class BaseServer:
def serve_forever(self, poll_interval=0.5):
self._handle_request_noblock()
def _handle_request_noblock(self):
self.process_request(request, client_address)
def process_request(self, request, client_address):
pass
class TCPServer(BaseServer):
pass
class ThreadingMixIn:
def process_request(self, request, client_address):
pass
class ThreadingTCPServer(ThreadingMixIn, TCPServer):
pass
obj = ThreadingTCPServer()
obj.serve_forever()
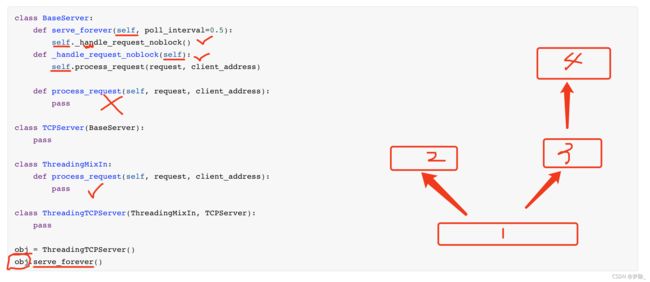
小结:
-
执行对象.方法时,优先去当前对象所关联的类中找,没有的话才去她的父类中查找。
-
Python支持多继承:先继承左边、再继承右边的。
-
self到底是谁?去self对应的那个类中去获取成员,没有就按照继承关系向上查找 。
2.3 多态
多态,按字面翻译其实就是多种形态。
-
其他编程语言多态
-
Python中多态
其他编程语言中,是不允许这样类编写的,例如:Java
class Cat{
public void eat() {
System.out.println("吃鱼");
}
}
class Dog {
public void eat() {
System.out.println("吃骨头");
}
public void work() {
System.out.println("看家");
}
}
public class Test {
public static void main(String[] args) {
obj1 = Cat()
obj2 = Cat()
show(obj1)
show(obj2)
obj3 = Dog()
show(obj3)
}
public static void show(Cat a) {
a.eat()
}
}
abstract class Animal {
abstract void eat();
}
class Cat extends Animal {
public void eat() {
System.out.println("吃鱼");
}
}
class Dog extends Animal {
public void eat() {
System.out.println("吃骨头");
}
public void work() {
System.out.println("看家");
}
}
public class Test {
public static void main(String[] args) {
obj1 = Cat()
show(obj1)
obj2 = Dog()
show(obj2)
}
public static void show(Animal a) {
a.eat()
}
}
在java或其他语言中的多态是基于:接口 或 抽象类和抽象方法来实现,让数据可以以多种形态存在。
在Python中则不一样,由于Python对数据类型没有任何限制,所以他天生支持多态。
def func(arg):
v1 = arg.copy() # 浅拷贝
print(v1)
func("lbw")
func([11,22,33,44])
class Email(object):
def send(self):
print("发邮件")
class Message(object):
def send(self):
print("发短信")
def func(arg):
v1 = arg.send()
print(v1)
v1 = Email()
func(v1)
v2 = Message()
func(v2)
在程序设计中,鸭子类型(duck typing)是动态类型的一种风格。在鸭子类型中,关注点在于对象的行为,能作什么;而不是关注对象所属的类型,例如:一只鸟走起来像鸭子、游泳起来像鸭子、叫起来也像鸭子,那么这只鸟可以被称为鸭子。
小结:
-
封装,将方法封装到类中 或 将数据封装到对象中,便于以后使用。
-
继承,将类中的公共的方法提取到基类中去实现。
-
多态,Python默认支持多态(这种方式称之为鸭子类型),最简单的基础下面的这段代码即可。
def func(arg): v1 = arg.copy() # 浅拷贝 print(v1) func("lbw") func([11,22,33,44])
3. 扩展:再看数据类型
在初步了解面向对象之后,再来看看我们之前学习的:str、list、dict等数据类型,他们其实都一个类,根据类可以创建不同类的对象。
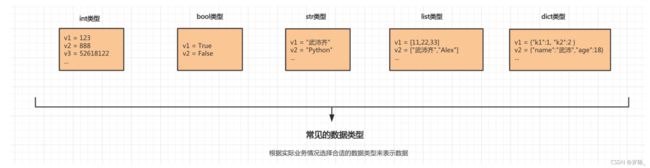
# 实例化一个str类的对象v1
v1 = str("lbw")
# 通过对象执行str类中的upper方法。
data = v1.upper()
print(data)
总结
-
类和对象的关系。
-
面向对象编程中常见的成员:
-
绑定方法
-
实例变量
-
-
self到底是什么?
-
面向对象的三大特性。
-
面向对象的应用场景
-
数据封装。
-
封装数据 + 方法再对数据进行加工处理。
-
创建同一类的数据且同类数据可以具有相同的功能(方法)。
-
-
补充:在Python3中编写类时,默认都会继承object(即使不写也会自动继承)。
class Foo: pass class Foo(object): pass这一点在Python2是不同的:
-
继承object,新式类
-
不继承object,经典类
-
面向对象进阶
目标:掌握面向对象进阶相关知识点,能沟通更加自如的使用面向对象来进行编程。
概要:
-
成员
-
变量
-
实例变量
-
类变量
-
-
方法
-
绑定方法
-
类方法
-
静态方法
-
-
属性
-
-
成员修饰符(公有/私有)
-
“对象嵌套”
-
特殊成员
1.成员
面向对象中的所有成员如下:
-
变量
-
实例变量
-
类变量
-
-
方法
-
绑定方法
-
类方法
-
静态方法
-
-
属性
通过面向对象进行编程时,会遇到很多种情况,也会使用不同的成员来实现,接下来我们来逐一介绍成员特性和应用场景。
1.1 变量
-
实例变量,属于对象,每个对象中各自维护自己的数据。
-
类变量,属于类,可以被所有对象共享,一般用于给对象提供公共数据(类似于全局变量)。
class Person(object):
country = "中国" #类变量
def __init__(self, name, age):
self.name = name
self.age = age
def show(self):
# message = "{}-{}-{}".format(Person.country, self.name, self.age)
message = "{}-{}-{}".format(self.country, self.name, self.age)
print(message)
print(Person.country) # 中国
p1 = Person("lbw",20)
print(p1.name)
print(p1.age)
print(p1.country) # 中国
p1.show() # 中国-lbw-20
提示:当把每个对象中都存在的相同的示例变量时,可以选择把它放在类变量中,这样就可以避免对象中维护多个相同数据。
易错点 & 面试题
第一题:注意读和写的区别。
class Person(object):
country = "中国"
def __init__(self, name, age):
self.name = name
self.age = age
def show(self):
message = "{}-{}-{}".format(self.country, self.name, self.age)
print(message)
print(Person.country) # 中国
p1 = Person("lbw",20)
print(p1.name) # lbw
print(p1.age) # 20
print(p1.country) # 中国
p1.show() # 中国-lbw-20
p1.name = "root" # 在对象p1中讲name重置为root
p1.num = 19 # 在对象p1中新增实例变量 num=19
p1.country = "china" # 在对象p1中新增实例变量 country="china"
print(p1.country) # china
print(Person.country) # 中国
class Person(object):
country = "中国"
def __init__(self, name, age):
self.name = name
self.age = age
def show(self):
message = "{}-{}-{}".format(self.country, self.name, self.age)
print(message)
print(Person.country) # 中国
Person.country = "美国"
p1 = Person("lbw",20)
print(p1.name) # lbw
print(p1.age) # 20
print(p1.country) # 美国
第二题:继承关系中的读写
class Base(object):
country = "中国"
class Person(Base):
def __init__(self, name, age):
self.name = name
self.age = age
def show(self):
message = "{}-{}-{}".format(Person.country, self.name, self.age)
# message = "{}-{}-{}".format(self.country, self.name, self.age)
print(message)
# 读
print(Base.country) # 中国
print(Person.country) # 中国
obj = Person("lbw",19)
print(obj.country) # 中国
# 写
Base.country = "china" #父类修改
Person.country = "泰国" #子类新增
obj.country = "日本" #子类的实例化对象新增
面试题
class Parent(object): x = 1 class Child1(Parent): pass class Child2(Parent): pass print(Parent.x, Child1.x, Child2.x) # 1 1 1 Child1.x = 2 print(Parent.x, Child1.x, Child2.x) # 1 2 1 Parent.x = 3 print(Parent.x, Child1.x, Child2.x) # 3 2 3
1.2 方法
-
绑定方法,默认有一个self参数,由对象进行调用(此时self就等于调用方法的这个对象)【对象&类均可调用】
-
类方法,默认有一个cls参数,用类或对象都可以调用(此时cls就等于调用方法的这个类)【对象&类均可调用】
-
静态方法,无默认参数,用类和对象都可以调用。【对象&类均可调用】
class Foo(object):
def __init__(self, name,age):
self.name = name
self.age = age
def f1(self):
print("绑定方法", self.name)
@classmethod
def f2(cls):
print("类方法", cls)
@staticmethod
def f3():
print("静态方法")
# 绑定方法(对象)
obj = Foo("lbw",20)
obj.f1() # 或者Foo.f1(obj)
# 类方法
Foo.f2() # cls就是当前调用这个方法的类。(类)
obj.f2() # cls就是当前调用这个方法的对象的类。
# 静态方法
Foo.f3() # 类执行执行方法(类)
obj.f3() # 对象执行执行方法
在Python中比较灵活,方法都可以通过对象和类进行调用;而在java、c#等语言中,绑定方法只能由对象调用;类方法或静态方法只能由类调用。
import os
import requests
class Download(object):
def __init__(self, folder_path):
self.folder_path = folder_path
@staticmethod
def download_dou_yin():
# 下载抖音
res = requests.get('.....')
with open("xxx.mp4", mode='wb') as f:
f.write(res.content)
def download_dou_yin_2(self):
# 下载抖音
res = requests.get('.....')
path = os.path.join(self.folder_path, 'xxx.mp4')
with open(path, mode='wb') as f:
f.write(res.content)
obj = Download("video")
obj.download_dou_yin()
面试题:
在类中 @classmethod 和 @staticmethod 的作用?
1.3 属性
属性其实是由绑定方法 + 特殊装饰器 组合创造出来的,让我们以后在调用方法时可以不加括号,例如:
class Foo(object):
def __init__(self, name):
self.name = name
def f1(self):
return 123
@property
def f2(self):
return 123
obj = Foo("lbw")
v1 = obj.f1()
print(v1)
v2 = obj.f2
print(v2)
示例:以之前开发的分页的功能。
class Pagination:
def __init__(self, current_page, per_page_num=10):
self.per_page_num = per_page_num
if not current_page.isdecimal():
self.current_page = 1
return
current_page = int(current_page)
if current_page < 1:
self.current_page = 1
return
self.current_page = current_page
def start(self):
return (self.current_page - 1) * self.per_page_num
def end(self):
return self.current_page * self.per_page_num
user_list = ["用户-{}".format(i) for i in range(1, 3000)]
# 分页显示,每页显示10条
while True:
page = input("请输入页码:")
# page,当前访问的页码
# 10,每页显示10条数据
# 内部执行Pagination类的init方法。
pg_object = Pagination(page, 20)
page_data_list = user_list[ pg_object.start() : pg_object.end() ]
for item in page_data_list:
print(item)
class Pagination:
def __init__(self, current_page, per_page_num=10):
self.per_page_num = per_page_num
if not current_page.isdecimal():
self.current_page = 1
return
current_page = int(current_page)
if current_page < 1:
self.current_page = 1
return
self.current_page = current_page
@property
def start(self):
return (self.current_page - 1) * self.per_page_num
@property
def end(self):
return self.current_page * self.per_page_num
user_list = ["用户-{}".format(i) for i in range(1, 3000)]
# 分页显示,每页显示10条
while True:
page = input("请输入页码:")
pg_object = Pagination(page, 20)
page_data_list = user_list[ pg_object.start : pg_object.end ]
for item in page_data_list:
print(item)
其实,除了咱们写的示例意外,在很多模块和框架的源码中也有porperty的身影,例如:requests模块。
import requests
# 内部下载视频,并将下载好的数据分装到Response对象中。
res = requests.get(
url="https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0200f240000buuer5aa4tij4gv6ajqg",
headers={
"user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36 FS"
}
)
# 去对象中获取text,其实需要读取原始文本字节并转换为字符串
res.text
关于属性的编写有两种方式:
-
方式一,基于装饰器
class C(object): @property def x(self): pass @x.setter def x(self, value): pass @x.deleter def x(self): pass obj = C() obj.x obj.x = 123 del obj.x -
方式二,基于定义变量
class C(object): def getx(self): pass def setx(self, value): pass def delx(self): pass x = property(getx, setx, delx, "I'm the 'x' property.") obj = C() obj.x obj.x = 123 del obj.x
Django源码一撇:
class WSGIRequest(HttpRequest):
def __init__(self, environ):
script_name = get_script_name(environ)
# If PATH_INFO is empty (e.g. accessing the SCRIPT_NAME URL without a
# trailing slash), operate as if '/' was requested.
path_info = get_path_info(environ) or '/'
self.environ = environ
self.path_info = path_info
# be careful to only replace the first slash in the path because of
# http://test/something and http://test//something being different as
# stated in https://www.ietf.org/rfc/rfc2396.txt
self.path = '%s/%s' % (script_name.rstrip('/'),
path_info.replace('/', '', 1))
self.META = environ
self.META['PATH_INFO'] = path_info
self.META['SCRIPT_NAME'] = script_name
self.method = environ['REQUEST_METHOD'].upper()
# Set content_type, content_params, and encoding.
self._set_content_type_params(environ)
try:
content_length = int(environ.get('CONTENT_LENGTH'))
except (ValueError, TypeError):
content_length = 0
self._stream = LimitedStream(self.environ['wsgi.input'], content_length)
self._read_started = False
self.resolver_match = None
def _get_scheme(self):
return self.environ.get('wsgi.url_scheme')
def _get_post(self):
if not hasattr(self, '_post'):
self._load_post_and_files()
return self._post
def _set_post(self, post):
self._post = post
@property
def FILES(self):
if not hasattr(self, '_files'):
self._load_post_and_files()
return self._files
POST = property(_get_post, _set_post)
写在最后,对属性进行一个补充:
由于属性和实例变量的调用方式相同,所以在编写时需要注意:属性名称 不要 实例变量 重名。
class Foo(object):
def __init__(self, name, age):
self.name = name
self.age = age
@property
def func(self):
return 123
obj = Foo("lbw", 123)
print(obj.name)
print(obj.func)
一旦重名,可能就会有报错。
class Foo(object):
def __init__(self, name, age):
self.name = name # 报错,错认为你想要调用 @name.setter 装饰的方法。
self.age = age
@property
def name(self):
return "{}-{}".format(self.name, self.age)
obj = Foo("lbw", 123)
class Foo(object):
def __init__(self, name, age):
self.name = name
self.age = age
@property
def name(self):
return "{}-{}".format(self.name, self.age) # 报错,循环调用自己(直到层级太深报错)
@name.setter
def name(self, value):
print(value)
obj = Foo("lbw", 123)
print(obj.name)
如果真的想要在名称上创建一些关系,可以让实例变量加上一个下划线。
class Foo(object):
def __init__(self, name, age):
self._name = name
self.age = age
@property
def name(self):
return "{}-{}".format(self._name, self.age)
obj = Foo("lbw", 123)
print(obj._name)
print(obj.name)
2.成员修饰符
Python中成员的修饰符就是指的是:公有、私有。
-
公有,在任何地方都可以调用这个成员。
-
私有,只有在类的内部才可以调用改成员(成员是以两个下划线开头,则表示该成员为私有)。
示例一:
class Foo(object):
def __init__(self, name, age):
self.__name = name
self.age = age
def get_data(self):
return self.__name
def get_age(self):
return self.age
obj = Foo("lbw", 123)
# 公有成员
print(obj.age)
v1 = self.get_age()
print(v1)
# 私有成员
# print(obj.__name) # 错误,由于是私有成员,只能在类中进行使用。
v2 = obj.get_data()
print(v2)
示例2:
class Foo(object):
def get_age(self):
print("公有的get_age")
def __get_data(self):
print("私有的__get_data方法")
def proxy(self):
print("公有的proxy")
self.__get_data()
obj = Foo()
obj.get_age()
obj.proxy()
示例3:
class Foo(object):
@property
def __name(self):
print("公有的get_age")
@property
def proxy(self):
print("公有的proxy")
self.__name
return 1
obj = Foo()
v1 = obj.proxy
print(v1)
特别提醒:父类中的私有成员,子类无法继承。
class Base(object):
def __data(self):
print("base.__data")
def num(self):
print("base.num")
class Foo(Base):
def func(self):
self.num()
self.__data() # # 不允许执行父类中的私有方法
obj = Foo()
obj.func() #报错
class Base(object):
def __data(self):
print("base.__data")
def num(self):
print("base.num")
self.__data()
class Foo(Base):
def func(self):
self.num()
obj = Foo()
obj.func()#这样可以执行了
写在最后,按理说私有成员是无法被外部调用,但如果用一些特殊的语法也可以(Flask源码中有这种写法,大家写代码不推荐这样写)。
class Foo(object):
def __init__(self):
self.__num = 123
self.age = 19
def __msg(self):
print(1234)
obj = Foo()
print(obj.age)
print(obj._Foo__num)
obj._Foo__msg()
成员是否可以作为独立的功能暴露给外部,让外部调用并使用。
-
可以,公有。
-
不可以,内部其他放的一个辅助,私有。
3.对象嵌套
在基于面向对象进行编程时,对象之间可以存在各种各样的关系,例如:组合、关联、依赖等(Java中的称呼),用大白话来说就是各种嵌套。
下面我们就用示例来学习常见的嵌套的情景:
情景一:
class Student(object):
""" 学生类 """
def __init__(self, name, age):
self.name = name
self.age = age
def message(self):
data = "我是一名学生,我叫:{},我今年{}岁".format(self.name, self.age)
print(data)
s1 = Student("lbw", 19)
s2 = Student("Alex", 19)
s3 = Student("日天", 19)
class Classes(object):
""" 班级类 """
def __init__(self, title):
self.title = title
self.student_list = []
def add_student(self, stu_object):
self.student_list.append(stu_object)
def add_students(self, stu_object_list):
for stu in stu_object_list:
self.add_student(stu)
def show_members(self):
for item in self.student_list:
# print(item)
item.message()
c1 = Classes("三年二班")
c1.add_student(s1)
c1.add_students([s2, s3])
print(c1.title)
print(c1.student_list)
情景二:
class Student(object):
""" 学生类 """
def __init__(self, name, age, class_object):
self.name = name
self.age = age
self.class_object = class_object
def message(self):
data = "我是一名{}班的学生,我叫:{},我今年{}岁".format(self.class_object.title, self.name, self.age)
print(data)
class Classes(object):
""" 班级类 """
def __init__(self, title):
self.title = title
c1 = Classes("Python全栈")
c2 = Classes("Linux云计算")
user_object_list = [
Student("lbw", 19, c1),
Student("Alex", 19, c1),
Student("日天", 19, c2)
]
for obj in user_object_list:
print(obj.name,obj.age, obj.class_object.title)
情景三:
class Student(object):
""" 学生类 """
def __init__(self, name, age, class_object):
self.name = name
self.age = age
self.class_object = class_object
def message(self):
data = "我是一名{}班的学生,我叫:{},我今年{}岁".format(self.class_object.title, self.name, self.age)
print(data)
class Classes(object):
""" 班级类 """
def __init__(self, title, school_object):
self.title = title
self.school_object = school_object
class School(object):
""" 学校类 """
def __init__(self, name):
self.name = name
s1 = School("北京校区")
s2 = School("上海校区")
c1 = Classes("Python全栈", s1)
c2 = Classes("Linux云计算", s2)
user_object_list = [
Student("lbw", 19, c1),
Student("Alex", 19, c1),
Student("日天", 19, c2)
]
for obj in user_object_list:
print(obj.name, obj.class_object.title , obj.class_object.school_object.name)
4.特殊成员
在Python的类中存在一些特殊的方法,这些方法都是 __方法__ 格式,这种方法在内部均有特殊的含义,接下来我们来讲一些常见的特殊成员:
-
__init__,初始化方法class Foo(object): def __init__(self, name): self.name = name obj = Foo("lbw") -
__new__,构造方法class Foo(object): def __init__(self, name): print("第二步:初始化对象,在空对象中创建数据") self.name = name def __new__(cls, *args, **kwargs): print("第一步:先创建空对象并返回") return object.__new__(cls) obj = Foo("lbw") -
__call__class Foo(object): def __call__(self, *args, **kwargs): print("执行call方法") obj = Foo() obj() -
__str__class Foo(object): def __str__(self): return "哈哈哈哈" obj = Foo() data = str(obj) print(data) -
__dict__class Foo(object): def __init__(self, name, age): self.name = name self.age = age obj = Foo("lbw",19) print(obj.__dict__) -
__getitem__、__setitem__、__delitem__class Foo(object): def __getitem__(self, item): pass def __setitem__(self, key, value): pass def __delitem__(self, key): pass obj = Foo("lbw", 19) obj["x1"] obj['x2'] = 123 del obj['x3'] -
__enter__、__exit__class Foo(object): def __enter__(self): print("进入了") return 666 def __exit__(self, exc_type, exc_val, exc_tb): print("出去了") obj = Foo() with obj as data: print(data)超前知识:数据连接,每次对远程的数据进行操作时候都必须经历。 1.连接 = 连接数据库 2.操作数据库 3.关闭连接
class SqlHelper(object): def __enter__(self): self.连接 = 连接数据库 return 连接 def __exit__(self, exc_type, exc_val, exc_tb): self.连接.关闭 with SqlHelper() as 连接: 连接.操作.. with SqlHelper() as 连接: 连接.操作...# 面试题(补充代码,实现如下功能) class Context: def do_something(self): print('内部执行') with Context() as ctx: print('内部执行') ctx.do_something()上下文管理的语法。
-
__add__等。class Foo(object): def __init__(self, name): self.name = name def __add__(self, other): return "{}-{}".format(self.name, other.name) v1 = Foo("alex") v2 = Foo("sb") # 对象+值,内部会去执行 对象.__add__方法,并将+后面的值当做参数传递过去。 v3 = v1 + v2 print(v3) -
__iter__-
迭代器
# 迭代器类型的定义: 1.当类中定义了 __iter__ 和 __next__ 两个方法。 2.__iter__ 方法需要返回对象本身,即:self 3. __next__ 方法,返回下一个数据,如果没有数据了,则需要抛出一个StopIteration的异常。 官方文档:https://docs.python.org/3/library/stdtypes.html#iterator-types # 创建 迭代器类型 : class IT(object): def __init__(self): self.counter = 0 def __iter__(self): return self def __next__(self): self.counter += 1 if self.counter == 3: raise StopIteration() return self.counter # 根据类实例化创建一个迭代器对象: obj1 = IT() # v1 = obj1.__next__() # v2 = obj1.__next__() # v3 = obj1.__next__() # 抛出异常 v1 = next(obj1) # obj1.__next__() print(v1) v2 = next(obj1) print(v2) v3 = next(obj1) print(v3) obj2 = IT() for item in obj2: # 首先会执行迭代器对象的__iter__方法并获取返回值,一直去反复的执行 next(对象) print(item) 迭代器对象支持通过next取值,如果取值结束则自动抛出StopIteration。 for循环内部在循环时,先执行__iter__方法,获取一个迭代器对象,然后不断执行的next取值(有异常StopIteration则终止循环)。 -
生成器
# 创建生成器函数 def func(): yield 1 yield 2 # 创建生成器对象(内部是根据生成器类generator创建的对象),生成器类的内部也声明了:__iter__、__next__ 方法。 obj1 = func() v1 = next(obj1) print(v1) v2 = next(obj1) print(v2) v3 = next(obj1) print(v3) obj2 = func() for item in obj2: print(item) 如果按照迭代器的规定来看,其实生成器类也是一种特殊的迭代器类(生成器也是一个中特殊的迭代器)。 -
可迭代对象
# 如果一个类中有__iter__方法且返回一个迭代器对象 ;则我们称以这个类创建的对象为可迭代对象。 class Foo(object): def __iter__(self): return 迭代器对象(生成器对象) obj = Foo() # obj是 可迭代对象。 # 可迭代对象是可以使用for来进行循环,在循环的内部其实是先执行 __iter__ 方法,获取其迭代器对象,然后再在内部执行这个迭代器对象的next功能,逐步取值。 for item in obj: passclass IT(object): def __init__(self): self.counter = 0 def __iter__(self): return self def __next__(self): self.counter += 1 if self.counter == 3: raise StopIteration() return self.counter class Foo(object): def __iter__(self): return IT() obj = Foo() # 可迭代对象 for item in obj: # 循环可迭代对象时,内部先执行obj.__iter__并获取迭代器对象;不断地执行迭代器对象的next方法。 print(item)# 基于可迭代对象&迭代器实现:自定义range class IterRange(object): def __init__(self, num): self.num = num self.counter = -1 def __iter__(self): return self def __next__(self): self.counter += 1 if self.counter == self.num: raise StopIteration() return self.counter class Xrange(object): def __init__(self, max_num): self.max_num = max_num def __iter__(self): return IterRange(self.max_num) obj = Xrange(100) for item in obj: print(item)class Foo(object): def __iter__(self): yield 1 yield 2 obj = Foo() for item in obj: print(item)# 基于可迭代对象&生成器 实现:自定义range class Xrange(object): def __init__(self, max_num): self.max_num = max_num def __iter__(self): counter = 0 while counter < self.max_num: yield counter counter += 1 obj = Xrange(100) for item in obj: print(item)常见的数据类型:
v1 = list([11,22,33,44]) v1是一个可迭代对象,因为在列表中声明了一个 __iter__ 方法并且返回一个迭代器对象。
from collections.abc import Iterator, Iterable v1 = [11, 22, 33] print( isinstance(v1, Iterator) ) # false,判断是否是迭代器;判断依据是__iter__ 和 __next__。 v2 = v1.__iter__() print( isinstance(v2, Iterator) ) # True v1 = [11, 22, 33] print( isinstance(v1, Iterable) ) # True,判断依据是是否有 __iter__且返回迭代器对象。 v2 = v1.__iter__() print( isinstance(v2, Iterable) ) # True,判断依据是是否有 __iter__且返回迭代器对象。
-
总结
-
面向对象编程中的成员
-
变量
-
实例变量
-
类变量
-
-
-
方法 - 绑定方法 - 类方法 - 静态方法
-
属性
-
-
成员修饰符
-
对象中的数据嵌套
-
特殊成员
-
重要概念:
-
迭代器
-
生成器
-
可迭代对象
-
面向对象高级和应用
目标:掌握面向对象高级知识和相关应用。
概要
-
继承【补充】
-
内置函数【补充】
-
异常处理
-
反射
1. 继承【补充】
对于Python面向对象中的继承,我们已学过:
-
继承存在意义:将公共的方法提取到父类中,有利于增加代码重用性。
-
继承的编写方式:
# 继承 class Base(object): pass class Foo(Base): pass
# 多继承 class Base(object): pass class Bar(object): pass class Foo(Base,Bar): pass
-
调用类中的成员时,遵循:
-
优先在自己所在类中找,没有的话则去父类中找。
-
如果类存在多继承(多个父类),则先找左边再找右边。
-
上述的知识点掌握之后,其实就可以解决继承相关的大部分问题。
但如果遇到一些特殊情况(不常见),你就可能不知道怎么搞了,例如:
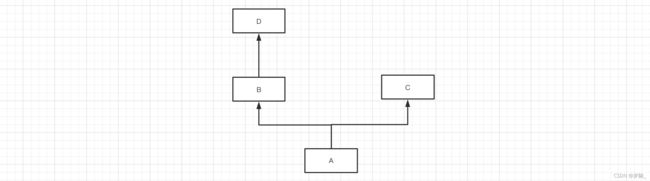
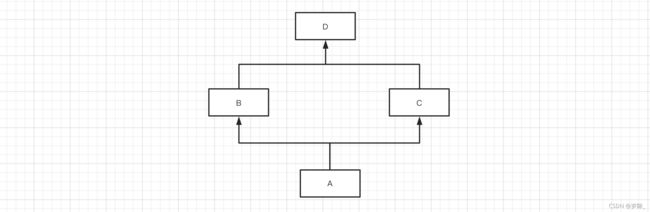
1.1 mro和c3算法
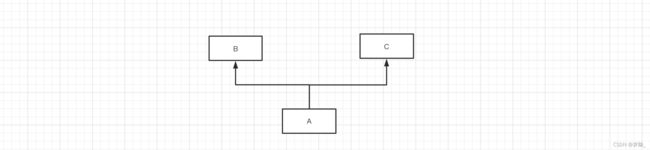
如果类中存在继承关系,在可以通过mro()获取当前类的继承关系(找成员的顺序)。
示例1:
mro(A) = [A] + [B,C] mro(A) = [A,B,C]
mro(A) = [A] + merge( mro(B), mro(C), [B,C] ) mro(A) = [A] + merge( [object], [object], [] ) mro(A) = [A] + [B,C,object] mro(A) = [A,B,C,object]
mro(A) = [A] + merge( mro(B), mro(C), [B,C] ) mro(A) = [A] + merge( [], [C], [,C] mro(A) = [A] + [B,C]
class C(object): pass class B(object): pass class A(B, C): pass print( A.mro() ) # [, , , ] print( A.__mro__ ) # ( , , , )
示例2:
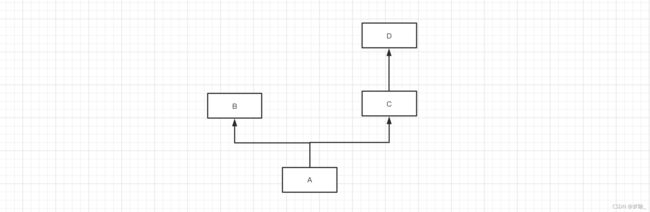
mro(A) = [A] + merge( mro(B), mro(C), [B,C] ) mro(A) = [A] + merge( [], [D], [] ) mro(A) = [A] + [B,C,D] mro(A) = [A,B,C,D]
class D(object): pass class C(D): pass class B(object): pass class A(B, C): pass print( A.mro() ) # [, , , , ]
示例3:
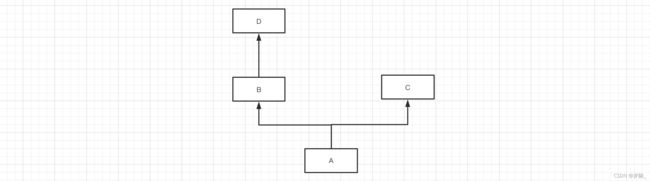
mro(A) = [A] + merge( mro(B),mro(C),[B,C]) mro(A) = [A] + merge( [], [C], [C]) mro(A) = [A,B,D,C]
class D(object): pass class C(object): pass class B(D): pass class A(B, C): pass print(A.mro()) # [, , , , ]
示例4:
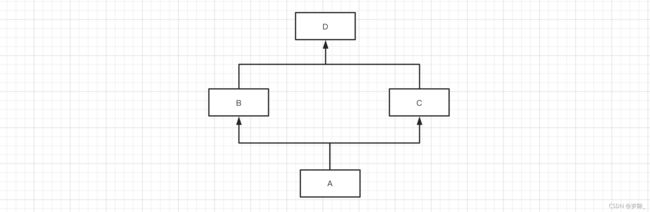
mro(A) = [A] + merge( mro(B), mro(C), [B,C]) mro(A) = [A] + merge( [B,D], [C,D], [B,C]) mro(A) = [A] + [B,C,D] mro(A) = [A,B,C,D]
class D(object): pass class C(D): pass class B(D): pass class A(B, C): pass print(A.mro()) # [, , , , ]
示例5:
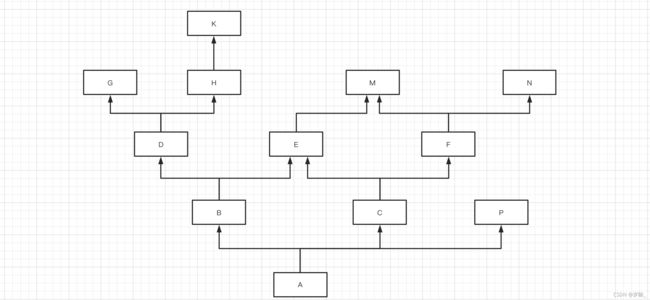
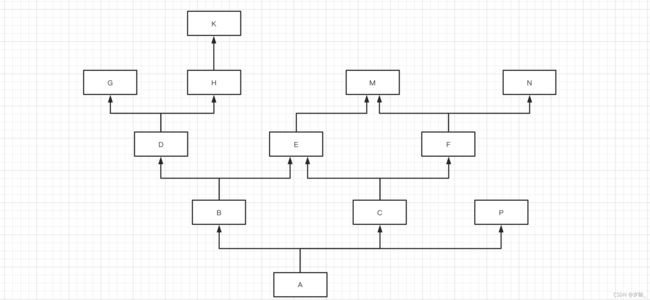
简写为:A -> B -> D -> G -> H -> K -> C -> E -> F -> M -> N -> P -> object
mro(A) = [A] + merge( mro(B), mro(C), mro(P), [B,C,P]) [] [N] [P] [P] mro(A) = [A,B,D,G,H,K,C,E,F,M,N,P] ----------------------------------------------------- mro(B) = [B] + merge( mro(D), mro(E), [D,E]) mro(D) = [D] + merge(mro(G),mro(H), [G,H]) mro(G) = [G] mro(H) = [H,K] mro(B) = [B] + merge( [], [E,M], [E]) mro(B) = [B,D,G,H,K,E,M] ----------------------------------------------------- mro(C) = [C] + merge(mro(E),mro(F),[E,F]) mro(E) = [E,M] mro(F) = [F,M,N] mro(C) = [C] + merge([M],[M,N] ,[]) mro(C) = [C,E,F,M,N]
class M: pass class N: pass class E(M): pass class G: pass class K: pass class H(K): pass class D(G, H): pass class F(M, N): pass class P: pass class C(E, F): pass class B(D, E): pass class A(B, C, P): pass print(A.mro()) # 简写为:A -> B -> D -> G -> H -> K -> C -> E -> F -> M -> N -> P -> object
特别补充:一句话搞定继承关系
不知道你是否发现,如果用正经的C3算法规则去分析一个类继承关系有点繁琐,尤其是遇到一个复杂的类也要分析很久。
所以,我自己根据经验总结了一句话赠送给大家:从左到右,深度优先,大小钻石,留住顶端,基于这句话可以更快的找到继承关系。
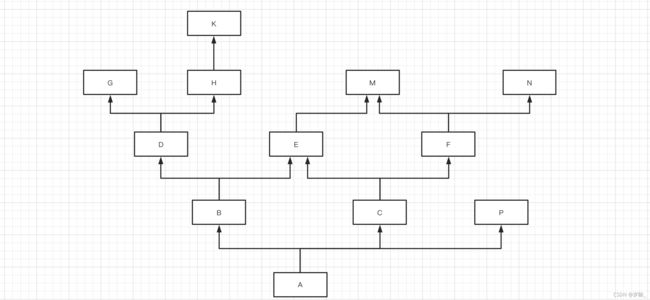
简写为:A -> B -> D -> G -> H -> K -> C -> E -> F -> M -> N -> P -> object
1.2 py2和py3区别(了解)
概述:
-
在python2.2之前,只支持经典类【从左到右,深度优先,大小钻石,不留顶端】
-
后来,Python想让类默认继承object(其他语言的面向对象基本上也都是默认都继承object),此时发现原来的经典类不能直接集成集成这个功能,有Bug。
-
所以,Python决定不再原来的经典类上进行修改了,而是再创建一个新式类来支持这个功能。【从左到右,深度优先,大小钻石,留住顶端。】
-
经典类,不继承object类型
class Foo: pass
-
新式类,直接或间接继承object
class Base(object): pass class Foo(Base): pass
-
-
这样,python2.2之后 中就出现了经典类和新式类共存。(正式支持是2.3)
-
最终,python3中丢弃经典类,只保留新式类。
详细文档:
https://www.python.org/dev/peps/pep-0253/#mro-method-resolution-order-the-lookup-rule
https://www.python.org/download/releases/2.3/mro/
In classic Python, the rule is given by the following recursive function, also known as the left-to-right depth-first rule.
def classic_lookup(cls, name):
if cls.__dict__.has_key(name):
return cls.__dict__[name]
for base in cls.__bases__:
try:
return classic_lookup(base, name)
except AttributeError:
pass
raise AttributeError, name
The problem with this becomes apparent when we consider a "diamond diagram":
class A:
^ ^ def save(self): ...
/ \
/ \
/ \
/ \
class B class C:
^ ^ def save(self): ...
\ /
\ /
\ /
\ /
class D
Arrows point from a subtype to its base type(s). This particular diagram means B and C derive from A, and D derives from B and C (and hence also, indirectly, from A).
Assume that C overrides the method save(), which is defined in the base A. (C.save() probably calls A.save() and then saves some of its own state.) B and D don't override save(). When we invoke save() on a D instance, which method is called? According to the classic lookup rule, A.save() is called, ignoring C.save()!
This is not good. It probably breaks C (its state doesn't get saved), defeating the whole purpose of inheriting from C in the first place.
Why was this not a problem in classic Python? Diamond diagrams are rarely found in classic Python class hierarchies. Most class hierarchies use single inheritance, and multiple inheritance is usually confined to mix-in classes. In fact, the problem shown here is probably the reason why multiple inheritance is unpopular in classic Python.
Why will this be a problem in the new system? The 'object' type at the top of the type hierarchy defines a number of methods that can usefully be extended by subtypes, for example __getattr__().
(Aside: in classic Python, the __getattr__() method is not really the implementation for the get-attribute operation; it is a hook that only gets invoked when an attribute cannot be found by normal means. This has often been cited as a shortcoming -- some class designs have a legitimate need for a __getattr__() method that gets called for all attribute references. But then of course this method has to be able to invoke the default implementation directly. The most natural way is to make the default implementation available as object.__getattr__(self, name).)
Thus, a classic class hierarchy like this:
class B class C:
^ ^ def __getattr__(self, name): ...
\ /
\ /
\ /
\ /
class D
will change into a diamond diagram under the new system:
object:
^ ^ __getattr__()
/ \
/ \
/ \
/ \
class B class C:
^ ^ def __getattr__(self, name): ...
\ /
\ /
\ /
\ /
class D
and while in the original diagram C.__getattr__() is invoked, under the new system with the classic lookup rule, object.__getattr__() would be invoked!
Fortunately, there's a lookup rule that's better. It's a bit difficult to explain, but it does the right thing in the diamond diagram, and it is the same as the classic lookup rule when there are no diamonds in the inheritance graph (when it is a tree).
总结:Python2和Python3在关于面向对象的区别。
-
Py2:
-
经典类,未继承object类型。【从左到右,深度优先,大小钻石,不留顶端】
class Foo: pass
-
新式类,直接获取间接继承object类型。【从左到右,深度优先,大小钻石,留住顶端 -- C3算法】
class Foo(object): pass
或
class Base(object): pass class Foo(Base): pass
-
-
Py3
-
新式类,丢弃了经典类只保留了新式类。【从左到右,深度优先,大小钻石,留住顶端 -- C3算法】
class Foo: pass class Bar(object): pass
-
2. 内置函数补充
本次要给讲解的内置函数共8个,他们都跟面向对象的知识相关。
-
classmethod、staticmethod、property 。
-
callable,是否可在后面加括号执行。
-
函数
def func(): pass print( callable(func) ) # True
-
类
class Foo(object): pass print( callable(Foo) ) # True
-
类中具有
__call__方法的对象class Foo(object): pass obj = Foo() print( callable(obj) ) # Falseclass Foo(object): def __call__(self, *args, **kwargs): pass obj = Foo() print( callable(obj) ) # True
所以当你以后在见到下面的情况时,首先就要想到handler可以是:函数、类、具有call方法的对象 这三种,到底具体是什么,需要根据代码的调用关系才能分析出来。
def do_something(handler): handler()
-
-
super,按照mro继承关系向上找成员。
class Top(object): def message(self, num): print("Top.message", num) class Base(Top): pass class Foo(Base): def message(self, num): print("Foo.message", num) super().message(num + 100) obj = Foo() obj.message(1) >>> Foo.message 1 >>> Top.message 101class Base(object): def message(self, num): print("Base.message", num) super().message(1000) class Bar(object): def message(self, num): print("Bar.message", num) class Foo(Base, Bar): pass obj = Foo() obj.message(1) >>> Base.message 1 >>> Bar.message 1000应用场景
假设有一个类,他原来已实现了某些功能,但我们想在他的基础上再扩展点功能,重新写一遍?比较麻烦,此时可以用super。
info = dict() # {} info['name'] = "lbw" info["age"] = 18 value = info.get("age") print(value)class MyDict(dict): def get(self, k): print("自定义功能") return super().get(k) info = MyDict() info['name'] = "lbw" # __setitem__ info["age"] = 18 # __setitem__ print(info) value = info.get("age") print(value)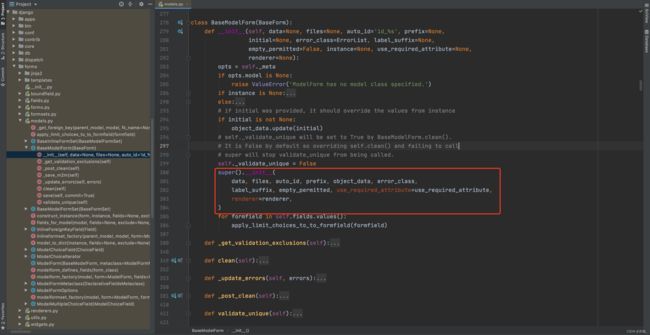
-
type,获取一个对象的类型。
v1 = "lbw" result = type(v1) print(result) #
v2 = "lbw" print( type(v2) == str ) # True v3 = [11, 22, 33] # list(...) print( type(v3) == list ) # True
class Foo(object): pass v4 = Foo() print( type(v4) == Foo ) # True
-
isinstance,判断对象是否是某个类或其子类的实例。
class Top(object): pass class Base(Top): pass class Foo(Base): pass v1 = Foo() print( isinstance(v1, Foo) ) # True,对象v1是Foo类的实例 print( isinstance(v1, Base) ) # True,对象v1的Base子类的实例。 print( isinstance(v1, Top) ) # True,对象v1的Top子类的实例。
class Animal(object): def run(self): pass class Dog(Animal): pass class Cat(Animal): pass data_list = [ "alex", Dog(), Cat(), "root" ] for item in data_list: if type(item) == Cat: item.run() elif type(item) == Dog: item.run() else: pass for item in data_list: if isinstance(item, Animal): item.run() else: pass -
issubclass,判断类是否是某个类的子孙类。
class Top(object): pass class Base(Top): pass class Foo(Base): pass print(issubclass(Foo, Base)) # True print(issubclass(Foo, Top)) # True
3.异常处理
在程序开发中如果遇到一些 不可预知的错误 或 你懒得做一些判断 时,可以选择用异常处理来做。
import requests
while True:
url = input("请输入要下载网页地址:")
res = requests.get(url=url)
with open('content.txt', mode='wb') as f:
f.write(res.content)
上述下载视频的代码在正常情况下可以运行,但如果遇到网络出问题,那么此时程序就会报错无法正常执行。
try:
res = requests.get(url=url)
except Exception as e:
代码块,上述代码出异常待执行。
print("结束")
import requests
while True:
url = input("请输入要下载网页地址:")
try:
res = requests.get(url=url)
except Exception as e:
print("请求失败,原因:{}".format(str(e)))
continue
with open('content.txt', mode='wb') as f:
f.write(res.content)
num1 = input("请输入数字:")
num2 = input("请输入数字:")
try:
num1 = int(num1)
num2 = int(num2)
result = num1 + num2
print(result)
except Exception as e:
print("输入错误")
以后常见的应用场景:
-
调用微信的API实现微信消息的推送、微信支付等
-
支付宝支付、视频播放等
-
数据库 或 redis连接和操作
-
调用第三方的视频播放发的功能,由第三方的程序出问题导致的错误。
异常处理的基本格式:
try: # 逻辑代码 except Exception as e: # try中的代码如果有异常,则此代码块中的代码会执行。
try:
# 逻辑代码
except Exception as e:
# try中的代码如果有异常,则此代码块中的代码会执行。
finally:
# try中的代码无论是否报错,finally中的代码都会执行,一般用于释放资源。
print("end")
"""
try:
file_object = open("xxx.log")
# ....
except Exception as e:
# 异常处理
finally:
file_object.close() # try中没异常,最后执行finally关闭文件;try有异常,执行except中的逻辑,最后再执行finally关闭文件。
"""
3.1 异常细分
import requests
while True:
url = input("请输入要下载网页地址:")
try:
res = requests.get(url=url)
except Exception as e:
print("请求失败,原因:{}".format(str(e)))
continue
with open('content.txt', mode='wb') as f:
f.write(res.content)
之前只是简单的捕获了异常,出现异常则统一提示信息即可。如果想要对异常进行更加细致的异常处理,则可以这样来做:
import requests
from requests import exceptions
while True:
url = input("请输入要下载网页地址:")
try:
res = requests.get(url=url)
print(res)
except exceptions.MissingSchema as e:
print("URL架构不存在")
except exceptions.InvalidSchema as e:
print("URL架构错误")
except exceptions.InvalidURL as e:
print("URL地址格式错误")
except exceptions.ConnectionError as e:
print("网络连接错误")
except Exception as e:
print("代码出现错误", e)
# 提示:如果想要写的简单一点,其实只写一个Exception捕获错误就可以了。
如果想要对错误进行细分的处理,例如:发生Key错误和发生Value错误分开处理。
基本格式:
try:
# 逻辑代码
pass
except KeyError as e:
# 小兵,只捕获try代码中发现了键不存在的异常,例如:去字典 info_dict["n1"] 中获取数据时,键不存在。
print("KeyError")
except ValueError as e:
# 小兵,只捕获try代码中发现了值相关错误,例如:把字符串转整型 int("无诶器")
print("ValueError")
except Exception as e:
# 王者,处理上面except捕获不了的错误(可以捕获所有的错误)。
print("Exception")
Python中内置了很多细分的错误,供你选择。
常见异常: """ AttributeError 试图访问一个对象没有的树形,比如foo.x,但是foo没有属性x IOError 输入/输出异常;基本上是无法打开文件 ImportError 无法引入模块或包;基本上是路径问题或名称错误 IndentationError 语法错误(的子类) ;代码没有正确对齐 IndexError 下标索引超出序列边界,比如当x只有三个元素,却试图访问n x[5] KeyError 试图访问字典里不存在的键 inf['xx'] KeyboardInterrupt Ctrl+C被按下 NameError 使用一个还未被赋予对象的变量 SyntaxError Python代码非法,代码不能编译(个人认为这是语法错误,写错了) TypeError 传入对象类型与要求的不符合 UnboundLocalError 试图访问一个还未被设置的局部变量,基本上是由于另有一个同名的全局变量, 导致你以为正在访问它 ValueError 传入一个调用者不期望的值,即使值的类型是正确的 """ 更多异常: """ ArithmeticError AssertionError AttributeError BaseException BufferError BytesWarning DeprecationWarning EnvironmentError EOFError Exception FloatingPointError FutureWarning GeneratorExit ImportError ImportWarning IndentationError IndexError IOError KeyboardInterrupt KeyError LookupError MemoryError NameError NotImplementedError OSError OverflowError PendingDeprecationWarning ReferenceError RuntimeError RuntimeWarning StandardError StopIteration SyntaxError SyntaxWarning SystemError SystemExit TabError TypeError UnboundLocalError UnicodeDecodeError UnicodeEncodeError UnicodeError UnicodeTranslateError UnicodeWarning UserWarning ValueError Warning ZeroDivisionError """
3.2 自定义异常&抛出异常
上面都是Python内置的异常,只有遇到特定的错误之后才会抛出相应的异常。
其实,在开发中也可以自定义异常。
class MyException(Exception): pass
try:
pass
except MyException as e:
print("MyException异常被触发了", e)
except Exception as e:
print("Exception", e)
上述代码在except中定义了捕获MyException异常,但他永远不会被触发。因为默认的那些异常都有特定的触发条件,例如:索引不存在、键不存在会触发IndexError和KeyError异常。
对于我们自定义的异常,如果想要触发,则需要使用:raise MyException()类实现。
class MyException(Exception):
pass
try:
# 。。。
raise MyException()
# 。。。
except MyException as e:
print("MyException异常被触发了", e)
except Exception as e:
print("Exception", e)
class MyException(Exception):
def __init__(self, msg, *args, **kwargs):
super().__init__(*args, **kwargs)
self.msg = msg
try:
raise MyException("xxx失败了")
except MyException as e:
print("MyException异常被触发了", e.msg)
except Exception as e:
print("Exception", e)
class MyException(Exception):
title = "请求错误"
try:
raise MyException()
except MyException as e:
print("MyException异常被触发了", e.title)
except Exception as e:
print("Exception", e)
案例一:你我合作协同开发,你调用我写的方法。
-
我定义了一个函数
class EmailValidError(Exception): title = "邮箱格式错误" class ContentRequiredError(Exception): title = "文本不能为空错误" def send_email(email,content): if not re.match("\[email protected]",email): raise EmailValidError() if len(content) == 0 : raise ContentRequiredError() # 发送邮件代码... # ... -
你调用我写的函数
def execute(): # 其他代码 # ... try: send_email(...) except EmailValidError as e: pass except ContentRequiredError as e: pass except Exception as e: print("发送失败") execute() # 提示:如果想要写的简单一点,其实只写一个Exception捕获错误就可以了。
案例二:在框架内部已经定义好,遇到什么样的错误都会触发不同的异常。
import requests
from requests import exceptions
while True:
url = input("请输入要下载网页地址:")
try:
res = requests.get(url=url)
print(res)
except exceptions.MissingSchema as e:
print("URL架构不存在")
except exceptions.InvalidSchema as e:
print("URL架构错误")
except exceptions.InvalidURL as e:
print("URL地址格式错误")
except exceptions.ConnectionError as e:
print("网络连接错误")
except Exception as e:
print("代码出现错误", e)
# 提示:如果想要写的简单一点,其实只写一个Exception捕获错误就可以了。
案例三:按照规定去触发指定的异常,每种异常都具备被特殊的含义。
3.4 特殊的finally
try:
# 逻辑代码
except Exception as e:
# try中的代码如果有异常,则此代码块中的代码会执行。
finally:
# try中的代码无论是否报错,finally中的代码都会执行,一般用于释放资源。
print("end")
当在函数或方法中定义异常处理的代码时,要特别注意finally和return。
def func(): try: return 123 except Exception as e: pass finally: print(666) func()
在try或except中即使定义了return,也会执行最后的finally块中的代码。
练习题
-
补充代码实现捕获程序中的错误。
# 迭代器 class IterRange(object): def __init__(self, num): self.num = num self.counter = -1 def __iter__(self): return self def __next__(self): self.counter += 1 if self.counter == self.num: raise StopIteration() return self.counter obj = IterRange(20) while True: try: ele = next(obj) except StopIteration as e: print("数据获取完毕") break print(ele) -
补充代码实现捕获程序中的错误。
class IterRange(object): def __init__(self, num): self.num = num self.counter = -1 def __iter__(self): return self def __next__(self): self.counter += 1 if self.counter == self.num: raise StopIteration() return self.counter class Xrange(object): def __init__(self, max_num): self.max_num = max_num def __iter__(self): return IterRange(self.max_num) data_object = Xrange(100) obj_iter = data_object.__iter__() while True: try: ele = next(obj_iter) except StopIteration as e: print("数据获取完毕") break print(ele) -
补充代码实现捕获程序中的错误。
def func(): yield 1 yield 2 yield 3 gen = func() while True: try: ele = next(gen) except StopIteration as e: print("数据获取完毕") break print(ele) -
补充代码实现捕获程序中的错误。(注意:本案例用于练习,在真是开发中对于这种情况建议还是自己做判断处理,不要用异常)
num = int("lbw")try: num = int("lbw") except ValueError as e: print("转换失败") -
补充代码实现捕获程序中的错误。(注意:本案例用于练习,在真是开发中对于这种情况建议还是自己做判断处理,不要用异常)
data = [11,22,33,44,55] data[1000]
try: data = [11,22,33,44,55] data[1000] except IndexError as e: print("转换失败") -
补充代码实现捕获程序中的错误。(注意:本案例用于练习,在真是开发中对于这种情况建议还是自己做判断处理,不要用异常)
data = {"k1":123,"k2":456} data["xxxx"]try: data = {"k1":123,"k2":456} data["xxxx"] except KyeError as e: print("转换失败") -
分析代码,写结果
class MyDict(dict): def __getitem__(self, item): try: return super().__getitem__(item) # KeyError except KeyError as e: return None info = MyDict() info['name'] = "lbw" info['wx'] = "lbw666" print(info['wx']) # info['wx'] -> __getitem__ print(info['email']) # info['email'] -> __getitem__
-
看代码写结果
def run(handler): try: num = handler() print(num) return "成功" except Exception as e: return "错误" finally: print("END") print("结束") res = run(lambda: 123) print(res)>>> 123 >>> END >>> 成功
def func(): print(666) return "成功" def run(handler): try: num = handler() print(num) return func() except Exception as e: return "错误" finally: print("END") print("结束") res = run(lambda: 123) print(res)>>> 123 >>> 666 >>> END >>> 成功
4.反射
反射,提供了一种更加灵活的方式让你可以实现去 对象 中操作成员(以字符串的形式去 对象 中进行成员的操作)。
class Person(object):
def __init__(self,name,wx):
self.name = name
self.wx = wx
def show(self):
message = "姓名{},微信:{}".format(self.name,self.wx)
user_object = Person("lbw","lbw666")
# 对象.成员 的格式去获取数据
user_object.name
user_object.wx
user_object.show()
# 对象.成员 的格式无设置数据
user_object.name = "lbw"
user = Person("lbw","lbw666")
# getattr 获取成员
getattr(user,"name") # user.name
getattr(user,"wx") # user.wx
method = getattr(user,"show") # user.show
method()
# 或
getattr(user,"show")()
# setattr 设置成员
setattr(user, "name", "lbw") # user.name = "lbw"
Python中提供了4个内置函数来支持反射:
-
getattr,去对象中获取成员
v1 = getattr(对象,"成员名称") v2 = getattr(对象,"成员名称", 不存在时的默认值)
-
setattr,去对象中设置成员
setattr(对象,"成员名称",值)
-
hasattr,对象中是否包含成员
v1 = hasattr(对象,"成员名称") # True/False
-
delattr,删除对象中的成员
delattr(对象,"成员名称")
以后如果再遇到 对象.成员 这种编写方式时,均可以基于反射来实现。
案例:
class Account(object):
def login(self):
pass
def register(self):
pass
def index(self):
pass
def run(self):
name = input("请输入要执行的方法名称:") # index register login xx run ..
account_object = Account()
method = getattr(account_object, name,None) # index = getattr(account_object,"index")
if not method:
print("输入错误")
return
method()
4.1 一些皆对象
在Python中有这么句话:一切皆对象。 每个对象的内部都有自己维护的成员。
-
对象是对象
class Person(object): def __init__(self,name,wx): self.name = name self.wx = wx def show(self): message = "姓名{},微信:{}".format(self.name,self.wx) user_object = Person("lbw","lbw666") user_object.name -
类是对象
class Person(object): title = "lbw" Person.title # Person类也是一个对象(平时不这么称呼)
-
模块是对象
import re re.match # re模块也是一个对象(平时不这么称呼)。
由于反射支持以字符串的形式去对象中操作成员【等价于 对象.成员 】,所以,基于反射也可以对类、模块中的成员进行操作。
简单粗暴:只要看到 xx.oo 都可以用反射实现。
class Person(object): title = "lbw" v1 = Person.title print(v1) v2 = getattr(Person,"title") print(v2)
import re
v1 = re.match("\w+","dfjksdufjksd")
print(v1)
func = getattr(re,"match")
v2 = func("\w+","dfjksdufjksd")
print(v2)
4.2 import_module + 反射
在Python中如果想要导入一个模块,可以通过import语法导入;企业也可以通过字符串的形式导入。
示例一:
# 导入模块 import random v1 = random.randint(1,100)
# 导入模块
from importlib import import_module
m = import_module("random")
v1 = m.randint(1,100)
示例二:
# 导入模块exceptions from requests import exceptions as m
# 导入模块exceptions
from importlib import import_module
m = import_module("requests.exceptions")
示例三:
# 导入模块exceptions,获取exceptions中的InvalidURL类。 from requests.exceptions import InvalidURL
# 错误方式
from importlib import import_module
m = import_module("requests.exceptions.InvalidURL") # 报错,import_module只能导入到模块级别。
# 导入模块
from importlib import import_module
m = import_module("requests.exceptions")
# 去模块中获取类
cls = m.InvalidURL
在很多项目的源码中都会有 import_module 和 getattr 配合实现根据字符串的形式导入模块并获取成员,例如:
from importlib import import_module
path = "openpyxl.utils.exceptions.InvalidFileException"
module_path,class_name = path.rsplit(".",maxsplit=1) # "openpyxl.utils.exceptions" "InvalidFileException"
module_object = import_module(module_path)
cls = getattr(module_object,class_name)
print(cls)
我们在开发中也可以基于这个来进行开发,提高代码的可扩展性,例如:请在项目中实现一个发送 短信、微信 的功能。
参考示例代码中的:auto_message 项目。
总结
-
了解 mro和c3算法
-
python2和python3在面向对象中的区别。
-
内置函数
staticmethod,classmethod,property,callable,type,isinstance,issubclass,super getattr,setattr,hasattr,delattr
-
异常处理
-
根据字符串的形式导入模块
import_module -
根据字符串的形式操作成员
反射-getattr,setattr,hasattr,delattr