前言
其实之前因为编码需要,专门学习过正则表达式,可惜,由于应用的比较少,慢慢的就淡忘了,也就大概只留了个印象在那儿,唯一的好处就是现用现查的时候,理解的比较快一点.
什么是正则
正则表达式,其实是个特别好玩东西,我之前学习正则的时候,看的书是<<正则表达式必知必会>>.如果需要系统的学习,可以取瞅一下...为什么说正则表达式是一个特别好玩的东西呢,因为有些地方我们可以通过正则来节省很大的工作量.先了解一下什么叫正则表达式.正则表达式的概念是这样,他通过某种模式来描述(匹配)一类字符.看看这个概念哈,他说某种模式,这个模式其实就是正则表达式.还有他并不是只可以匹配特定的字符,他可以匹配一类字符.正则表达式的好处是啥呢,节省工作量.比如,我们需要删除文本内容里,所有status字符串和date字符串.通常情况下,我们可能需要删除两次,第一次是删除status字符串,第二次再删除date字符串.但是如果我们使用正则的话,我们可以直接用正则表达式描述status和date字符串,然后执行一次删除即可.看起来只节省了一次,但是如果我们要删除一百个一千个字符串呢?关于正则更多的概念问题就不说了..没啥意思,还是来点干货比较合适.强烈建议先看看下面链接的内容.先给个正则学习的链接
正则表达式测试工具
需要注意的是,这里的正则和我之前学习的还有一些不同的地方.我先把一些表达式贴出来,以后留着备查.说实话,记录这个表之前,感觉记这个东西挺麻烦的..结果敲了一遍,基本就记住了...
[:alnum:] 匹配字母和数字 [:alpha:] 匹配字母 [:blank:] 匹配tab和空格 [:cntrl:] 匹配键盘的控制按键比如上下左右上面那九个. [:digit:] 匹配数字 [:graph:] 匹配除了tab和空格之外所有的按键 [:lower:] 匹配小写字符 [:print:] 匹配任何可以被打印出来的字符 [:punct:] 匹配标点符号 [:upper:] 匹配大写字母 [:space:] 匹配空白符 [:xdigit:] 匹配十六进制的数字 这里就大致记一下吧,因为这个东西会,感觉没啥好记的...(难道不是因为懒癌发作才不记的么...肯定不是,我打算在我下两个学习任务结束后,考虑从头开始记正则的学习笔记.)下面记一下正则的一些元字符.当然,此处并不完整,比如没有说?.还有贪婪型匹配和非贪婪型匹配,如果想要具体了解这个东西,不妨看一下上面正则链接的内容.
^单词 ^在这表示匹配行首的位置,这里是匹配在行首的指定单词 单词$ $在这表示句尾,这里是匹配在句尾的指定单词. . 可以匹配任意一个字符. \ 转义字符,可以将一些特殊字符转换为原意. * 跟在某一个字符或者某一组字符后,表示匹配0个(组)或多个(组)字符 [一堆字符] 通过中括号包裹一些字符,表示匹配一个中括号内的字符. [数字(字符)-数字(字符)] 这里主要是-(减号),他表示一个范围,表示匹配从减号前到减号后之间的内容. [^字符组] ^出现在这里表示非的意思,这里匹配的是所有不存在中括号内的字符 {n,m} 大括号包裹的是限制数量,表示前面的字符出现n次到m次.
linux使用正则的小工具
不得不承认,其实我是一个标题党,看了下面的内容你就知道了...先看一下第一个命令sed,是不是很眼熟...我写的第一个shell里面就用到了这个命令,但是我还没学到这个命令,百度了好久,所以印象深刻啊.通过man sed,我们可以发现sed命令其实是一个管道命令.他是一个流编辑器,可以过滤和转换文本.他的参数挺多的.好久没好好的学一下命令了.好好的看一下这个命令的各个选项,静静心.
通过-n选项只会打印出进过sed特殊处理后的输入流.
通过-e选项,在指令列模式执行
将脚本文件的内容作为内容执行
在脚本里使用扩展的正则表达式.
将zed修改的数据直接写入到文件内.这些选项里好像没有什么好记的.主要还是要记一下下面这些sed可以跟的动作表示.sed使用的格式是酱紫的,sed 选项 [起始行,结束行] 动作这里的起始行和结束行表示后面动作要操作的范围.比如 sed '1,10d' 表示删除1到十行.前面这个d其实就是sed命令的动作了.sed支持的动作有很多,比较常用的有:下面试试这个命令,先随便搞个文本文件...
a 新增,后面跟一个字符串,表示在当前行的下一行添加该字符串. c 取代,后面跟一个字符串,这些字符串将会替代指定行的内容. s 替换.后面可以跟两个字符串中间用/分割,依次为旧字符串和新字符串,新字符串将替换新字符串,要用/g作为终止哦. d 删除,这个比较好理解,就是删除指定行的内容 i 插入,后面跟一个字符串,将该内容添加到当前行的前面. p 打印,将被选择的数据打印出来 文件内容:merican walked to a telephone booth, "Hello. Is that the bank?
Local children rush from their homes to shout hello at the passing riders,
often adding “What is your name?” as they laugh and wave

先试试在下一行(a)和在前一行加点内容(i).

然后我们替换掉所有的hello,改成hi.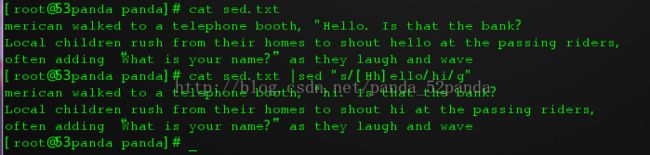
看,sed是支持正则表达式的哟.额,还是啥...试试删除吧.
看,就这么一丢丢东西...对了,sed命令如果加上i参数可以直接修改文件内容,而不是这样将改变的结果输出到屏幕上哈.
扩展一丢丢正则表达式
上面的正则表达式元字符的表格只给出了一部分,现在再补充一点元字符.额...这里好像也没有啥...
+ 重复前一个字符一次或者一次以上 ? 匹配前一个字符零次或一次 | 表示或者的意思 () 在里面可以放一组字符串 ()+ 其实就是()和+的组合,表示匹配一个或多个括号内的内容.
文件内容格式化及其相关处理
先说一个格式化文件内容的命令--printf.
啧啧,学过编程的人,看这个命令可能会很眼熟啊,这不是打印语句么...(c和java是..其他的我就不知道喽...)
man一下printf命令发现该命令用于格式化并显示数据,注意哈,printf不是管道命令.
看一下printf里一些比较特殊的字符.
在我们学过的大多数命令里,都说\反斜杠是转义字符,可以改变后面跟的元素原本的含义,使其具有特殊意义.
现在看一下printf支持的一些转义字符.
\xNNN N是两个数字,可以转换数字为字符.这个事十六进制表示的字符
还有一个挺好玩的,叫\nnn 后面跟三个数字,这个是八进制表示的字符
\\ 就是反斜杠这个好像没啥好说的,就是讲转义字符反斜杠转义为他原本的含义.\a,就是那个讨厌的嘟嘟报警声.\b,退格.,注意看最后那个a没了.
\f 清除屏幕\r 相当于丹霞enter按键\t水平的tab键\v垂直的tab键上面都是一些比较好玩的转义字符.也是搞格式的时候,经常会用的...吧.说完这几个转义字符,还有个比较好玩的要说一下.printf指定的变量格式.%ns 表示n个字符,%ni表示n个整数,%N,nf表示一个浮点数,整数位有N个,小数位有n个.找下规律哈.仔细看这三个,其实规律还是很简单的,首先,他们都可以看做是由三部分构成的,第一部分是%,第二部分是数字,表示位数,第三部分表示类型.其中字符型也就是string用s表示,整数型也就是Integer,用i表示,浮点型也就是float用f表示,关于第二部分,也就浮点类型比较特殊一点,因为有整数位和小数位所以有两个数值,中间用小数点隔开.那应该怎么格式化文件呢?我们做一下练习.先搞一个文件
然后格式化一下.
说一下上面的格式哈.有三个%10s\t 表示这个字符串占十个字符位置,我们有\t也就是tab键分隔,然后三个之后换下行..好像也没啥难的...再看一个awk命令.之前printf命令主要针对的是整个文件,处理的通常是一行行的数据,awk不一样,他针对的是一行行的数据,处理的是字段.而默认的字段分隔符通常是空格或者tab键.awk命令使用格式是这样的:awk后面跟一个单引号包裹的内容,然后跟要处理的文件名.这个被单引号包裹的内容,就是一些awk处理的命令.通常是酱紫的:'条件{执行动作} 条件{执行动作}'在使用之前有一点需要了解,在每一行,每一个字段,其实都对应着一个变量名,比如$1就代表着第一个字段,$2代表第二个,一次类推,而$0则代表这一整行.那肯定有人会问,我们怎么知道这一行有多少个字段呢?我们可以通过变量NF来获取这一行的字段总数.NR获取当前是第几行.FS获取分割字符.比如: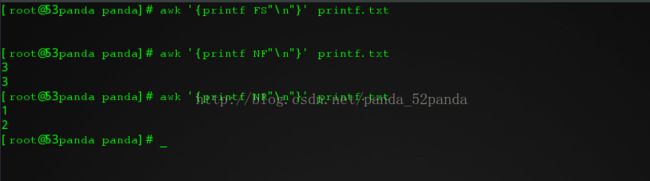
我们刚刚说过,awk可以根据条件来执行对应的动作,这里就用到了一些逻辑符号,这样,基本的awk语法和需要用到的东西就都了解了.哦,对了.还有两个条件选项一个是BEGIN表示开始之前,这里可以设置一下FS或者初始化个变量啥的.还有一个END表示结束之前.好了...这样就没啥了...
> 大于 < 小于 <= 小于等于 >= 大于等于 == 等于(逻辑判断) = 需要和==区分开来,==表示逻辑判断,而=表示赋值. 还有两个好玩的命令.一个是diff,一个是patch.diff命令可以用来比对两个文件,格式是酱紫的,diff 选项 文件1 文件2 可用的选项有b,将多个空白字符视为一个.B忽略掉空白行,i忽略大小写.额,然后就没了.还有一个命令叫patch,这个命令可以用来更新合并文件.我们可以先用diff命令对比两个文件生成一份差异文档,然后用这份差异文档通过pitch命令来对文件进行更新或者覆盖操作,但是这个命令我感觉我一般用不到,所以只是随意的看了下.并没有详细的记录.额...终于搞定了...