正则表达式学习笔记(四)正则表达式引擎漫谈:NFA与DFA
截至上篇为止,我们学习了正则表达式的基本用法,包括捕获,引用,环视和量词匹配等。可以说,对于正则表达式的学习,我们已经到了一个不错的地步,但是就如博主博客上面所写的那样,“君子务本,本立而道生”,学习任何一个东西,都要想办法弄清楚最核心的部分,这样才能真正的学会,进而在使用中才能得心应手。
那么对正则表达式来说,它最核心的东西是什么呢?答案是引擎。正则表达式因为其漫长的历史而衍生出了不同的流派,这些不同的流派使用不同的引擎,这些引擎彼此提供了不完全一样的语法支持,甚至对于某个相同的表达式匹配任务,也会有不同的结果。了解引擎有助于我们更深入的了解我们所写的正则表达式匹配。
严格的说,有三种正则表达式的引擎,一种是最传统的NFA,历史最为悠久,.Net,PHP,Ruby等语言中所集成的正则表达式均使用NFA引擎。第二种是DFA,主要被egrep,awk,lex和flex支持。最后一种是满足Posix标准的NFA,这是什么呢,简而言之,就是一种对NFA引擎的规则,规定NFA引擎必须满足某些行为以符合POSIX标准。他们各自的特点如下:
| 引擎名称 | 程序 | 匹配特点 |
| NFA | .Net,PHP,Ruby,Java等 | 回溯,最左匹配 |
| POSIX NFA | mawk | 最长匹配 |
| DFA | egrep,awk等 | 无捕获,无回溯,最长匹配,不支持忽略优先量词 |
如果我们使用的语言没有出现在上面,那该怎么办呢?最简单的检测是,使用模式串"Hello|Hello World"匹配目标字符串"Hello World",如果匹配的结果是Hello,那么多半使用的是NFA引擎,如果整个Hello World都匹配,那么就是POSIX NFA或DFA,至于其中的原理我们后面会讲到。
在特点那一列,有一些特点我们从字面就能理解,比如不支持忽略优先量词,无捕获等,但是对于另外一些特点比如回溯和最左匹配,最长匹配等词汇比较陌生,别着急,在继续了解这它们之前,我们先了解两条对于所有类型正则表达式引擎都适用的基本规则。
从左到右匹配目标字符串
考虑目标字符串'This is a word'。使用模式'is'匹配目标字符串,那么无论在何种引擎下面,首先找到的匹配总是This中的is,而不是后面那个单词is。因为在匹配目标字符串的时候,遵循的原则是从左到右匹配。可以想象目标字符串下面有一条看不见的传送带,拉着字符串向前进,从左到右开始匹配。
量词默认总是匹配优先
量词*,?,+和{min,max}在不加?变成忽略优先量词(DFA不支持忽略优先量词)的时候,总是匹配优先。
好了,有了这两条基本规则在手,让我们来之前让我们觉得有些迷糊的引擎。
DFA
DFA全称确定型有穷自动机,不支持回溯和捕获括号,匹配时以目标字符串为导向,又称为文本导向的引擎。系统会在匹配之前花一定的时间理解模式串,在匹配的时候不会进行目标字符串回溯(回溯在NFA里面解释),只需要从左到右扫描目标字符串一次,其中每个字符至多尝试匹配一次,所以又叫文本导向。DFA的最大特点是会保证返回一个目标字符串里面的最长匹配,我们看刚刚那个例子,用Hello|Hello World尝试匹配Hello World。

从目标字符串的第一个字母H开始,DFA引擎知道模式串中的分支结构都满足字母H,就这样,引擎传送目标字符串向右移动,依次匹配ello。当匹配完o了以后,引擎知道某个分支已经达到了匹配条件,但是因为DFA会返回最长的匹配,所以引擎仅仅会记录一个成功的匹配,接着移动目标字符串,尝试寻找更长的匹配,当无法寻到更长的匹配时,才会返回这个成功的匹配Hello。在这个例子中,引擎能找到一个更长的匹配Hello World,因此这次匹配的结果就是Hello World。再看一个例子,体会一下DFA的文本导向和不回溯机制。这次我们尝试用Tomorrow|Today|Todo 去匹配Today。

和之前一样,从目标文本的一个字符出发,发现三个分支都匹配,接着向前移动,当移动到d的时候,第一个分支淘汰出局。

引擎发现还有两个“活着”的匹配(如果一个可能成功的匹配都没有,引擎会直接报告匹配失败),接着移动目标文本,到a的时候,第三个分支淘汰。

接着引擎继续匹配,终于在移动完整个目标文本之后,确定了唯一的匹配分支二,至此匹配成功返回。
NFA
NFA全称非确定型有穷自动机,这个非确定在博主看来,就是指回溯,回溯是NFA的一大特色。除此之外,NFA还是表达式导向,不同于之前的DFA文本导向,下面我们还是来看看相同的两个例子在NFA引擎下面的表现情况。
在Hello World这个例子中,不同于DFA目标文本导向,同时尝试匹配多个分支,依次淘汰。NFA表达式导向以遍历表达式为主,首先尝试用第一分支匹配目标文本,只有在第一分支无法匹配的时候,才尝试使用第二分支。

在这个例子中,第一分支Hello可以顺利的匹配成功,在NFA中,一旦某个分支匹配成功,就会返回这个成功的匹配,而不会接着尝试更多的匹配,所以这也是为什么在这个例子中,返回的成功匹配是Hello而不像DFA返回的是Hello World。
接着我们再来看看回溯,使用Today那个例子。在NFA的回溯机制下,第一个分支的第一个字母最先尝试匹配目标文本的第一个字符,如果匹配,再接着尝试匹配第二个字符;如果不匹配,就用第二个分支的第一个字母尝试匹配目标文本的第一个字符。如果匹配,则尝试匹配第二个字符;如果不匹配,则第三分支开始尝试,如果还不行,则表示目标文本的第一个字符无法被模式串匹配,接着目标文本被引擎向前传送,接着目标文本的第二个字符开始尝试匹配第一分支的第一字符……看到了吗,目标文本的每个字符都可能会被匹配多次(取决于分支数量和分支的匹配情况),引擎传送带可能会来回的传送目标文本,所以这个机制很形象的叫做,回溯。
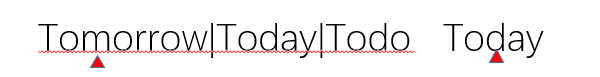
第一分支无法匹配,切换到第二分支,同时目标文本被引擎重新定位到第一字符T。

第二分支匹配成功,不会再次尝试第三分支,返回成功匹配Today。
总结
以上就是正则表达式的引擎NFA和DFA以及他们的主要特性,至于POSIX NFA,仅仅是规定了要返回所有可能匹配中最长匹配的NFA,大家稍微留意就好,但是原理还是那样的。
在使用正则表达式的时候,除了要注意不同的引擎,还要注意不同的工具、语言对同一种引擎的正则表达式支持也可能会不尽相同,大家在使用的时候,还是要多多查阅相关工具的文档,本系列提供的知识,可以当一个方向性的参考,希望各位通过阅读本系列文章,能做到在使用正则表达式的时候,心中有数,知道用哪些功能能实现哪些效果,那博主就很开心了。