C++(12)——命名空间,模板函数,模板类
命名空间
命名空间是为了解决全局变量名的污染问题而设立的,用来处理程序中 常见的同名冲突,C++提供了这样的名字空间作用域的限制。
基本写法如下:
namespace 名字空间作用域
{
///
}
比如下面的代码,设立了两个不用的命名空间,并通过作用域解析符调用了各自的函数
namespace bw
{
void fun(int a)
{
a += 10;
}
}
namespace mk
{
void fun(int a)
{
a += 10;
}
}
int main()
{
bw::fun(10);
mk::fun(10);
return 0;
}
函数模板
为了代码重用,代码就必须是通用的,因此这种通用的代码就应该不受到数据类型的限制,那么我们可以把数据类型改为一个设计参数,这种类型的程序设计成为参数化的程序设计,软件模块由模板构造,包括函数模板和类模板。
函数模板
函数模板用来创建一个通用功能的函数,不是一个实在的函数,编译器不能为其生成可执行代码。定义函数模板后只是一个对函数功能框架的描述,以支持多种不同形参,简化重载函数的设计,当它具体执行时,在编译时将根据传递的实际参数决定其功能。
函数模板的写法如下:
template <模板参数表>
返回值类型 模板名(形参表)
{
函数体
}
<模板参数表>尖括号中的模板参数表不能为空,可以为多个,用逗号隔开;- 模板类型参数代表的是一种类型,由关键字
class和typename后跟一个标识符构成,在这里这两个关键词的意义相同,均表示后面的参数名代表一个潜在的内置或者用户设计的类型 - 比如下面的程序:
#include运行结果如下:

- 函数模板根据一组实际类型或值构造出独立的函数的过程是隐式发生的,称为
模板的实参推演(编译过程中发生)。 - 为了判断用作模板实参的实际类型,编译器需要检查函数调用中提供的函数实参的类型,比如上述代码中一个为int类型,一个为double类型,都用来决定每个实例的模板参数,该过程称作模板实参推演。
注意:在编译的主函数中,有编译函数模板而生成的函数称为模板函数,要分清这两个概念。- 但这个过程并不是在编译时简单地将Type替换成相应的类型,而是一种
类型重命名规则
对于最后一点的解释,先看下面的示例:
函数模板的推演过程详解
#include运行结果为:这里vscode显示的格式不太好看,我们使用vs2019


其原因是两次调用发生了这样的推演:
typedef int T;
void fun<T>(T a){...}
typedef int* T;
void fun<T>(T a){...}
修改代码加上const,再做思考:
int main()
{
const int x = 10;
fun(x);
fun(&x);
return 0;
}
运行结果如下:推演过程中,由于const限制,不能通过指针改变x的值,会被推演成
int const *
修改代码继续思考:
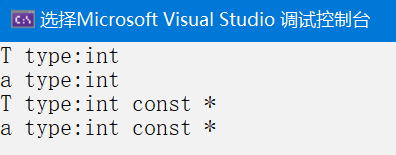
int main()
{
int x = 10;
const int y = 10;
int *xp = &x;
const int * yp = &yp;
fun(xp);
fun(yp);
}
运行结果如下:因为yp的指向被约束,自身的改变并不会影响y的值,只要指向为常性即可,因此会被推演
int const *
从上面的示例中,我也就意识到了更应该学好const和指针的关系的重要性。
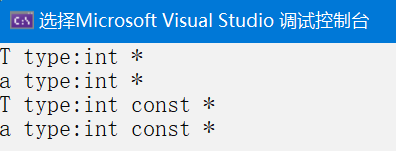
再看修改函数模板如下:
void fun(T* a)// * 和变量结合
{
T x,y;
cout<<"T type:"<<typeid(T).name()<<endl;//显示类型的类型名
cout<<"a type:"<<typeid(a).name()<<endl;//显示变量的类型名
}
int main()
{
int x = 10;
const int y = 20;
fun(&x);//T : int //a: int *
fun(&y);//T : const int //a : const int *
//除非我们将其初始化,但即便这样做,输出的结果仍为int,没有const,编译器并未丢失const特性,只是没有感知
}
上面的T就是整形的重命名规则,相当于typedef int T,这也就替换出了它的原始类型,但此时程序的编译是无法通过的,原因是:T被推演成const int,而在fun函数内的x和y并没有给予初始化,学习这些令人头疼的推演过程,
此时调用fun时,传入普通变量就无法推演成功,因为这是一种部分特化版本,它只能够接受指针类型,而之前的版本可以接受任何类型的参数,因此是一种完全泛化的版本,表示啥都可以。
void fun<char *>(char *a)
而上面这一种就是一种完全特化的版本,只接受char *类型,有一种非你莫属的味道。
再来看下面的代码,你将会更深层次地理解模板推演的过程。
void fun(const T* a)
{
T x,y;
cout<<"T type:"<<typeid(T).name()<<endl;//显示类型的类型名
cout<<"a type:"<<typeid(a).name()<<endl;//显示变量的类型名
}
int main()
{
int x = 10;
const int y = 20;
fun(&x);//T : int //a: const int *,注意:这个const是原有的,并非推演的产物
fun(&y);//T : const int //a : const int *,同理
}
继续:改为引用类型,继续琢磨:
void fun(T &a)//&和变量名结合
{
T x = 0,y = 0;
cout<<"T type:"<<typeid(T).name()<<endl;
cout<<"a type:"<<typeid(a).name()<<endl;
}
int main()
{
int x = 10;
const int y = 20;
int *xp = &x;
const int *yp = &y;
fun(x);//T : int //a: int &,
fun(y);//T : const int //a : const int &
fun(xp);//T:int *//a:int *&
fun(yp);//T:const int *//a:const int *&
return 0;
}
继续:能否编译通过呢?再看下面的代码:
void fun(T &a)//&和变量名结合
{
T x = 0,y = 0;
cout<<"T type:"<<typeid(T).name()<<endl;
cout<<"a type:"<<typeid(a).name()<<endl;
}
int main()
{
int x = 10;
const int y = 20;
fun(&x);
fun(&y);
return 0;
}
我们来解释一下:
- 首先,我们传入x的地址,但是a本身是一个引用
- 所以会被推演成一个指针类型的引用
- 即
int * &a = &x,由此,我们可以通过a来改变x的地址 - 但是,作为一个普通变量其地址是无法修改的
- 所以a被推演成了常引用,
int * const &a = &x - 注意 :x的地址是一个常量,我们必须给引用的地址加上常性才可以通过,即T必须是
int const * - 但是这种推演,系统是无法完成的,所以无法编译通过
- 想要编译通过,就修改代码为:
void fun(T const &a)
对于模板函数的推演过程的理解就到这里,下面我们来学习函数模板的特化:
函数模板的特化
看下面的代码:
//A
template<class T>
void fun(T a)
{
cout<<"T a"<<endl;
}
//B
template<class T>
void fun(T *a)
{
cout<<"T *a"<<endl;
}
//C
template<class T>
void fun(const T *a)
{
cout<<"const T *a"<<endl;
}
//D
template<>
void fun<char>(const char * a)
{
cout<<"const char *a"<<endl;
}
int main()
{
int x = 10;
const int y = 20;
const char *p = "hello";
fun(x);//用A推演
fun(&x);//用B推演
fun(&y)//用C推演
//上述3个就是一种部分特化的效果
}
如果少写一个部分特化,比如少写C,仍然可以编译通过,&y也可以用B推演出T:const int,如果少写了B,&x也可以用C推演,此时只是能力收缩,不能通过a去改变x 的值而已。这就给我们了启示,我们在编写代码时是否需要考虑这些问题。
然而D就是C的一种完全特化版本,特化T类型为char类型,fun§将用完全特化版本进行推演。
模板函数的重载
template<class T>
void fun(T a,int)
{}
template<class T>
void fun(T a,char)
{}
类模板
- 类模板和函数模板有一个区别就是,类模板不会自动进行类型的推演,在定义对象的同时必须指定类型。
- 参数表内可以是类型,也可以是非类型,用逗号隔开,
- 从通用的类模板定义中生成类的过程叫做模板实例化。
template<class T>
class SeqStack
{
private:
T *data;
int size;
int top;
public:
void Push(const T&x);
};
int main()
{
//模板类
SeqStack<int> ist;
SeqStack<double> dst;
SeqStack<char> cst;
}
注意:模板类需要注明类型,不会自动推演
之后,编译时将会生成如下代码::(以“int”为例)
class SeqStack<int>
{
typedef int T;
//C1引入了一种新写法:using T = double;这种写法与上面的等价
private:
T *data;
int size;
int top;
public:
void Push(const T&x);
};
加入非模板类型:
template<class T,int N>
class SeqStack
{
private:
T data[N];
public:
void Push(const T&x);
};
int main()
{
SeqStack<int,10> ist;
SeqStack<int,100> ist;
}
之后,编译时将会生成如下代码::(以“ist”为例)
class SeqStack<int,10>
{
typedef T int;
private:
T data[10];
public:
void Push(const T&x);
};
总结:
- 非模板类型像宏一样被替换,而这个过程是发生在编译过程中,因此我们不能通过运行过程中指定用户输入来确定大小;
- 而模板类型是一种重命名规则。
因此,上述代码中的is和ist是完全不同的类型。
注意 : 类模板中的函数都是模板函数,如果不调用,是不会被实例化的,这也是有时候我们定义类模板时,不调用这些函数就没有报错的原因,一旦调用漏洞百出。
注意:模板类和模板包含的成员函数都必须包含在一个成员函数中,不能分离,即不能在头文件中声明模板类和其模板成员函数,而在cpp文件中进行函数的定义,原因是依赖关系太复杂,编译器无法实现。
模板类型参数的默认值
与函数形参的默认值一样,必须从右向左赋值,比如:
void fun(int a ,int b = 0,int c = 10,int d = 5)
对于模板类:
template<class T = int,int N = 100>
class SeqStack
{
private:
T data[N];
public:
void Push(const T&x);
};
int main()
{
SeqStack<> ist1; //ok
SeqStack<int,10> ist2;// ok
SeqStack<int> ist3; //ok
SeqStack<,10> ist4; //error
}
多参数的模板类
如果类模板有多个参数类型,可以这么写:
此时实际参数可以有多个:
template <class...Arg>
class Object
{};
int main()
{
Object<int> io;
Object<int,int> iio;
Object<int,int,double> iido;
return 0;
}