【优化器框架】Apache Calcite - 一种用于异构数据源查询优化处理的基础框架
概要
Apache Calcite 是一支持多种开源数据处理系统,例如:Apache Hive,Storm,Flink,Druid 和 MapD,为其提供查询处理、优化和查询语言的基础框架。本文向广大的研究社区正式地介绍 Calcite,简要地介绍其历史演进,框架,特性,功能和使用模式。Calcite的框架包括一个内置上百条优化规则的、模块化的、并且可扩展的优化器,一个兼容处理各种查询语言的查询处理器,一个专为可扩展性而设计的适配器架构,以及支持各种异构数据模型和存储(关系型,半结构,流和地理数据)。这种灵活、可嵌入和可扩展的架构使得 Calcite 在大数据框架中具有很高的吸引力。Calcite 将持续引入对新的数据源、查询语言以及查询处理和优化的支持,这是一个活跃的项目。
1 介绍
继开创性的 System R ( 一个传统的关系型数据库引擎,主导了数据处理领域)之后。早在 2005 年,Stonebraker 和 Cetintemel 就预测,我们将看到一系列专业引擎,例如列存储引擎、流存储引擎、文本搜索引擎等等。他们认为专用引擎可以提供更具有陈本效益的性能,并且它们将终结“一刀切”范式。 他们的愿景今天似乎比以往任何时候都更有意义。 事实上,许多专门的开源数据系统已经流行起来,例如 Storm [50] 和 Flink [16](流处理)、Elasticsearch [15](文本搜索)、Apache Spark [47]、Druid [14] 等。
随着机构不断投资于针对其特定需求量身定制的数据处理系统,不断遇到两个问题:
- 此类专用的开发人员遇到了同样的问题。例如:query optimization [4, 25] 或者需要支持SQL 查询语言或相关扩展的(例如 streaming queries [26]),以及受到 LINQ [33] 的启发。在没有统一框架的情况下,让多个工程师独立开发类似的优化逻辑和语言支持会浪费工程精力。
- 使用这些专用系统的程序员通常必须将其中的几个集成在一起。一个机构可以依赖于 Elasticsearch, Apache Spark, 和 Druid。我们需要构建能够支持跨数据源的异构的优化查询系统[55]。
Apache Calcite 就是为了解决这些问题而开发的。它是一个完整的查询处理系统,提供数据库管理系统所需的许多通用功能——查询执行、优化和查询语言,而数据存储和管理功能留给专用的引擎实现。Calcite 很快就被 Hive、Drill[13]、Storm 和许多其他数据处理引擎所采用,为其提供了先进的查询优化和查询语言支持。例如,Hive[24]是一个建立在 Apache Hadoop 之上的流程仓库项目。随着 Hive 从批处理源转向交互式的SQL应答平台,很明显需要一个强大的优化器作为核心。因此,Hive 采用了 Calcite 作为其优化器,并且从那时起,它们之间的集成一直在推进。许多其他项目和产品纷纷效仿,包括 Flink、MapD[12]等。
此外,Calcite 通过一个公开的通用接口实现多个系统的跨平台优化。为了提高效率,优化器需要全局推理,例如,跨不同系统做出物化视图选择的策略。
构建通用的框架是一件很有挑战的事情。特别是,该框架还需要具有可扩展性和灵活性,以适用不同类型的系统。我们相信,具有以下特性有助于 Calcite 在开源社区和行业中被广泛采用:
- 开源。过去十年中的许多主要数据处理平台要么是开源的,要么基于开源。Calcite 是一个开源框架,由 Apache 软件基金会提供支持,它提供了协作开发项目的方法。此外,该软件由 java 编写,因此开源更轻松地与许多最新的数据处理系统[12, 13, 16, 24, 28, 44] 进行交互。这些系统通常使用 Java(或基于JVM的Scala)编写,尤其是 Hadoop 生态系统中的那些。
- 多种数据模型。Calcite 使用流和传统数据处理范例为查询优化和查询语言提供支持。Calcite 将流视为按时间顺序排列的记录或事件集,他们不会像在传统数据处理系统中那样持久保持到磁盘。
- 灵活的查询优化器。优化器的每个组件都是可插入和可扩展的,从规则到代价模型。另外,Calcite 还支持多个 planning engines。因此,优化可以分解为不同阶段,并且不同阶段可以由不同的优化引擎进行处理,具体取决于哪个优化引擎更为适用。
- 跨系统支持。Calcite 框架可以跨多个后台查询处理系统和数据库进行优化查询。
- 可靠性。Calcite 是可靠的,因为它多年来的广泛使用已经经过了详尽的测试。Calcite 还包含一个广泛的测试套件,用于验证系统的所有组件,包括查询优化器规则和后端数据源的集成。
- 支持 SQL 及其扩展。许多系统不提供自己的查询语言,而是更喜欢依赖现有的查询语言,例如SQL。因此,Calcite 提供对 ANSI 标准 SQL 以及各种 SQL 扩展的支持,例如,用于表达对流或嵌套数据的查询。此外,Calcate 还包含一个符合标准 Java API(JDBC) 的驱动。
本文剩下部分将介绍:第 2 节讨论一些相关的研究。第 3 节介绍 Calcite 的架构及其主要组件。第 4 节描述了核心的关系代数方程式。第 5 节介绍了 Calcite 的适配器,简要描述怎么读取外部数据源。反过来,第 6 节描述了 Calcite 的优化器及其主要功能,而第 7 节介绍处理不同查询范例的扩展。第 8 节概述了已经使用 Calcite 的数据处理系统。第 9 节讨论了未来可能的扩展。第 10 节总结。
2 相关研究
尽管 Calcite 目前是 Hadoop 生态系统中采用最为广泛的大数据分析优化器,但其背后的许多想法并不新颖。例如,构建在 Volcano[20] 和 Cascades[19] 之上的查询优化框架,并结合了其他广泛使用的优化技术,例如物化视图重写[10, 18, 22]。还有其他与 Calcite 类似的系统。
Orca [45] 是一种模块化查询优化器,用于 Greenplum 和 HAWQ 等数据管理产品。Orca 在优化器和执行引擎之间实现了一种被称为 Data eXchange Language 交换信息的框架,将优化器和执行引擎进行分离。Orca 还提供用于验证生成查询计划正确性和性能的工具。与 Orca 相比,Calcite 可以用作独立的查询执行引擎,联合多个存储和处理后端,包括可插拔的 planners 和 optimizers。
SparkSQL[3] 扩展了 Apache Spark 以支持 SQL 查询,它可以像 Calcite 一样在多个数据源上执行查询。然而,尽管 SparkSQL 中的 Catalyst 优化器也试图将查询执行成本降到最低,但它缺乏 Calcite 使用的动态编程方法,存在陷入局部最优的风险。
Algebricks [6] 是一种查询编译器框架,为大数据查询处理提供了逻辑代数数据模型和编译器框架。高级语言被编译成 Algebricks 逻辑代数。Algebricks 然后生成针对 Hyracks 并且处理的后端优化 jobs。虽然 Calcite 与 Algebricks 有相同的模块方法,但 Calcite 还包括对基于成本优化的支持。在 Calcite 当前版本中,查询优化器架构使用基于 Volcano 的动态规划生成计划,以及 Orca 中的多阶段优化扩展。尽管原则上 Algebricks 可以支持多个后端处理(例如 Apache Tez, Spark),但 Calcite 多年来为各种后端提供的支持经过了良好的测试验证。
Garlic[7] 是一种异构数据管理系统,它在统一的对象模型下,可以表示来自多个系统的数据。但是 Garlic 不支持跨系统的查询优化,依赖于每个系统来优化自己的查询。
FORWARD [17] 是一个联邦查询处理器,它实现了呗称为 SQL++[38] 的 SQL 超集。SQL++ 具有集成 JSON 和关系数据模型的半结构化数据模型,而 Calcite 在查询计划期间通过关系型数据模型来表示半结构化数据模型。FORWARD 将用 SQL++ 编写的联邦查询分解为子查询,并根据查询计划在底层数据库上执行。数据的合并在 FORWARD 引擎内部执行。
另一个联邦数据存储和处理系统是 BigDAWG,它抽象了广义上的数据模型,包括关系型、时间序列和流。BigDAWG 中的抽象单元称为信息岛。每个信息岛都有一种查询语言、数据模型,并连接到一个或多个存储系统。在单个信息岛的边界内支撑跨存储系统查询。相反,Calcite 提供了一个统一的关系抽象,允许跨后端使用不同的数据模型进行查询。
Myria 是用于大数据分析的通用引擎,具有对 Python 语言的高级支持。它为其他后端引擎(如 Spark 和 PostgreSQL)生成查询计划。
3 架构
Calcite 包含许多组成典型数据库管理系统的部分。但是,它忽略了一些关键组件,例如数据存储,处理数据的算法,以及元数据存储。这些组件是故意忽略的,它使 Calcite 成为具有一个或多个数据存储和使用多个数据处理引擎之间进行调解的最佳选择。它也是构建定制数据处理系统的坚实基础。
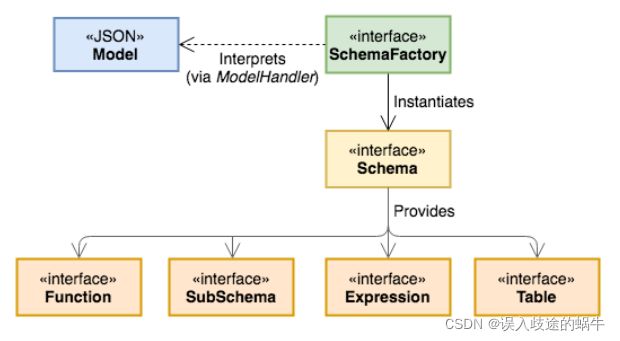
图 1 概述了 Calcite 架构的主要组件。Calcite 的优化器使用关系运算符树作为其内部表示。优化引擎主要由三个组件组成:rules,metadata providers,plannder engines。将在第 6 节中更为详细地讨论这些组件。在图 1 中,虚线代表与框架可能的外部交互。Calcite 有很多不同的交互方式。
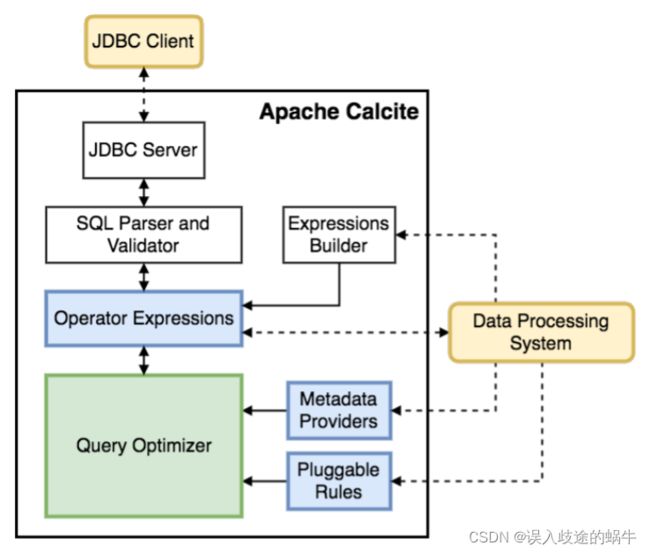
图 1 Apache Calcite 架构
首先,Calcite 包含了一个查询解析器和校验,将 SQL 查询转换为关系运算符树。Calcite 没有存储层,而是提供了一种机制来通过适配器(第5节中描述)在外部存储引擎中定义 table schema 和 views。
其次,虽然 Calcite 为需要这种数据库语言支持的系统提供了优化的 SQL,但它也为已经有自己的语言解析和解释的系统提供了优化支持:
- 一些系统支持 SQL 查询,但没有或仅有有限的查询优化。例如,Hive 和 Spark 最初都提供对 SQL 语言的支持,但它们没有包含优化器。对于这种情况,一旦优化了查询,Calcite 就可以将关系表达式转换回 SQL。此特性允许 Calcite 作为独立系统运行在任何具有 SQL 接口但没有优化器的数据管理系统之上。
- Calcite 架构不仅针对 SQL 优化而定制。数据处理系统选择使用自己的解析器来处理自己的查询语言是很常见的。Calcite 也可以帮助优化这些查询。事实上,Calcite 还允许通过直接实例化关系运算符来轻松构建运算符树。可以使用内置的关系表达式构建接口。例如,假设我们想使用表达式构建器表达以下表达式:

等效表达式如下:

该接口公开了构建关系表达式所需的主要结构。优化阶段完成后,应用程序可以检视优化的关系表达式,然后可以将其映射回系统的查询处理单元。
4 查询关系代数
Operators. 关系代数[11]是 Calcite 的核心。处理最常见的数据操作运算符,如 filter, project, join 等,Calcite 还包含了满足不同目的的额外 operators,例如,能够简洁地表示负责的操作,或识别更高效的优化。
例如,OLAP,decision making 和 streaming 应用通常使用 window 定义来表达复杂分析函数,比如需要计算一定时间内或者一部分行记录的 moving average。因此 Calcite 引入了窗口运算符,封装了窗口定义,即上下边界、分区等,已经在每个窗口上执行的聚合函数。
Traits. Calcite 不使用不同实体来表扫逻辑合物理运算符。相反,它使用特征描述了与运算符相关的物理属性。这些特征帮助优化器评估不同替代计划的成本。改变特征值不会改变被评估的逻辑表达式,即给定运算符产生的行仍然相同。
在优化过程中,Calcite 尝试在关系表达式上强制执行某些特征,例如某些列的排序顺序。关系运算符可以实现一个转换器接口,该接口指示如何将表达式的特征从一个值转换为另一个值。
Calcite 包括描述由关系表达式生成的数据的物理属性的常见特征,例如排序、分组和分区。类似于 SCOPE 优化器 [57],Calcite 优化器可以推理这些属性并利用它们来找到避免不必要操作的计划。例如,如果排序运算符的输入已经正确排序——可能是因为这与后端系统中用于行的顺序相同——那么可以删除排序操作。
除了这些属性之外,Calcite 的主要特性之一是调用约定特性。本质上,特征代表将在其中执行表达式的数据处理系统。包含调用约定作为特征允许 Calcite 实现其优化透明查询的目标,这些查询的执行可能跨越不同的引擎,即约定将被视为任何其他物理属性。
例如,假设要 JOIN 一张 MySQL 的 Products 表到 Splunk 的 Orders 表(参见图 2)。首先,Orders 表先在 splunk 中进行扫描,Products 的扫描通过 jdbc 连接到 mysql 中进行。这些表必须在其各自的引擎内进行扫描。join 还只是逻辑操作,还未涉及具体实现。此外,图 2 中的 SQL 查询包含一个 filter(where 子句),它由特定于适配器的规则下推到 splunk(参见第 5 节)。一种可能的实现是使用 Apache Spark 作为外部引擎:join 转换为 spark 协议,其输入是从 jdbc-mysql 和 splunk 到 spark 协议的转换。但是有一个更有效的实现:利用 Splunk 可以通过 ODBC 对 MySQL 执行检索,一个 planner rule 从 splunk 到 spark 协议转换地下推 join ,在 Splunk 引擎内部运行.