数据结构学习笔记(第二章:线性表)
第二章:线性表
- 2.1 线性表的概念
-
- 线性表的定义
- 线性结构的特点
- 2.2 顺序表(顺序存储)
-
- 顺序表的定义
- 顺序表的实现(C++实现)
- 顺序表的简单应用
- 2.3 线性链表(链式存储)
-
- 线性链表的定义
- 线性链表的实现(C++实现)
- 线性链表的扩展
- 2.4 顺序表和链表在复杂度上的区别
-
- 插入和删除
- 查找
- 2.5 双链表
-
- 双链表的含义
- 双链表的部分实现
- 2.6 循环链表
-
- 循环链表的含义
- 循环双链表的部分实现
- 2.7 静态链表
-
- 静态链表的定义
- 静态链表的部分实现
2.1 线性表的概念
线性表的定义
- 一个线性表是n个数据元素的有限序列。
- 在稍微复杂的线性表中,一个数据元素可以由若干个数据项 组成。在这种情况下,数据元素也叫做记录,含有大量记录的线性表也叫做文件。
线性结构的特点
- “第一个”数据元素是唯一的,一个线性表中不可能拥有两个“第一个”数据元素。
- 存在唯一的“最后一个”数据元素,线性表不能有两个不同的结尾。
- 除了“第一个”数据元素以外,线性表中每个数据元素都只有一个前驱。
- 除了“最后一个”数据元素以外,线性表中每个数据元素都只有一个后驱
2.2 顺序表(顺序存储)
顺序表的定义
线性表的顺序表:指的是用一组地址连续的存储单元依次存储线性表的数据元素。
顺序表是一种支持随机存取的存储结构。根据起始地址加上元素的序号,可以很方便的访问任意一个元素,这就是随机存取的概念。
它的特点是:每一个数据元素的存储位置都和线性表的起始位置相差一个和数据元素在线性表中的排序成正比的常数,该常数为数据元素的大小。假设该起始位为LOC(L);
| 数据元素 | 存储位置 |
|---|---|
| a1 | LOC(L) |
| a2 | LOC(L)+1*数据元素的大小 |
| a3 | LOC(L)+2*数据元素的大小 |
| … | … |
顺序表的实现(C++实现)
在这里,我用c++实现的主要原因是我想要和严蔚敏教材上的内容更为贴近,用&作为形参和教材上提供的算法更像,所以我采用了C++实现。修改成C语言也很容易,但要注意,下面函数的形参不能是带取地址符&的,C语言中没有这样的语法,得换成指针才能用。取地址符作为形参是C++的用法,被称为‘别名’。
下面是定义顺序表的全部代码:
#include 顺序表的简单应用
- 应用一:假设两个线性表 LA 和 LB 分别代表集合 A A A 和集合 B B B ,现要求求一个新的集合 A = A ∪ B A=A \cup B A=A∪B,请你利用顺序表设计一个算法:
void union_l(sqlist &la,sqlist lb){
//la=la U lb
int lenga,lengb;
lenga=listlength_sq(la);
lengb=listlength_sq(lb);
elemtype e;
int sign;
for(int i=1;i<=lengb;i++){
get_elem_sq(lb,i,e);//因为是la=la U lb,所以检查lb是不是有元素不在la里的即可,没有就插入,有就不做操作
if(locate_elem_sq(la,e)==0){//必须找不到该元素才可以插入la表中
listinsert_sq(la,++lenga,e);//插入到尾部,注意使用++lenga,因为插入函数是插入到第i个之前的元素前,所以插到尾部应该是表长度+1的位置之前
}
}
return;
}
- 应用二:已知线性表 LA 和 LB 中的数据元素按值非递减有序排列,先要求将 LA 和 LB 归并为一个新的线性表 LC ,且 LC 中的数据元素扔按值非递减有序数列排序,例如: LA={3,5,8,11},LB={2,6,8,9,11,15,20},则LC={2,3,5,6,8,8,9,11,11,15,20},求设计算法:
void mergelist_sq(sqlist la,sqlist lb,sqlist &lc){
//线性表LA和LB中的数据元素按值非递减有序排列,将LA和LB归并为一个新的线性表LC,且LC中的数据元素扔按值非递减有序数列排序
initlist_sq(lc);
int i,j,k=0;
int lengla=listlength_sq(la);
int lenglb=listlength_sq(lb);
for(i=j=1;i<=lengla&&j<=lenglb;){
elemtype ea,eb;
get_elem_sq(la,i,ea);
get_elem_sq(lb,j,eb);
if(ea>eb){
listinsert_sq(lc,++k,eb);
j++;//如果选了lb中的元素则lb进入下一个元素进行比较
}
else{
listinsert_sq(lc,++k,ea);
i++;//如果选了la中的元素则la进入下一个元素进行比较
}
}
for(;i<=lengla;i++){//查看一下la是否已经全部选完,没有选完则直接将la剩下的元素赋到lc的最后
elemtype ea;
get_elem_sq(la,i,ea);
listinsert_sq(lc,++k,ea);
}
for(;j<=lenglb;j++){//查看一下lb是否已经全部选完,没有选完则直接将la剩下的元素赋到lc的最后
elemtype eb;
get_elem_sq(lb,j,eb);
listinsert_sq(lc,++k,eb);
}
return;
}
- 应用三:假设顺序表中的数据元素类型是int型,求从有序顺序表中删除其值在给定值s与t之间(包含s和t,要求s
status delete_1(sqlist &l,int s,int t){
if(l.length==0||t<s) return error; //线性表L不存在,或者s和t的取值不合理,返回错误信号
int i,j;//因为是有序顺序表,所以s-t之间肯定是截一段数据段,用i标记数据段头,j标记数据段尾
for(i=1;i<=l.length;i++){
if(l.elem[i]>=s){
break;
}
}
for(j=i+1;j<=l.length;j++){
if(l.elem[j]>t){
break;
}
}
int k=j-i;
for(;j<=l.length;j++,i++){
l.elem[i]=l.elem[j];
}
l.length-=k;
return TRUE;
}
- 应用三:假设顺序表中的数据元素类型是int型,求从顺序表中删除其值在给定值s与t之间(包含s和t,要求s
思考:从头到尾扫描线性表,用k来记录符合删除要求的个数,对于当前扫描到的元素,如果不符合删除要求,则将其移动到前k个位置。
status delete_2(sqlist &l,int s,int t){
if(l.length==0||t<s) return error; //线性表L不存在,或者s和t的取值不合理,返回错误信号
int i,k=0;
for(i=1;i<=l.length;i++){
if(l.elem[i]<=t&&l.elem[i]>=s){
k++;
}
else{
l.elem[i-k]=l.elem[i];
}
}
l.length-=k;
return TRUE;
}
- 应用四:已知在一维数组中A[n+m]中依次存放两个线性表 ( a 1 , a 2 . . . a n ) (a_1,a_2...a_n) (a1,a2...an)和 ( b 1 , b 2 . . . b m ) (b_1,b_2...b_m) (b1,b2...bm),试编写一个函数,将数组中两个顺序表的位置互换,即把 ( b 1 , b 2 . . . b m ) (b_1,b_2...b_m) (b1,b2...bm)放在 ( a 1 , a 2 . . . a n ) (a_1,a_2...a_n) (a1,a2...an)前面,要求优先空间复杂度和时间复杂度达到最优解。
思考:一开始我就想着开一组数组临时存放,然后直接交换不就好了,但是因为追求空间复杂度,所以这题就不能这么写了,我们应该先将A[m+n]的全部元素逆置,得到
( b m , . . . , b 2 , b 1 , a n , . . . , a 2 , a 1 ) (b_m,...,b_2,b_1,a_n,...,a_2,a_1) (bm,...,b2,b1,an,...,a2,a1),然后再分别将前m个元素和后n个元素原地逆置,即可得到 ( b 1 , b 2 . . . b m , a 1 , a 2 . . . a n ) (b_1,b_2...b_m,a_1,a_2...a_n) (b1,b2...bm,a1,a2...an)
(忽然发现这题是2010统考题一题的稍微变形题,不过答案都不用变)
status reversal_sq(sqlist &l,int begin,int length){
//反转函数,将线性表l的从begin的位置将长度为length的数据转置
if(!l.elem||begin+length-1>l.length){
return error;
}
int mid=begin+(length-1)/2;//找到中间位
int right=begin+length-1;
for(int left=begin;left<=mid;left++,right--){
//将left和right的元素交换
int t=l.elem[left];
l.elem[left]=l.elem[right];
l.elem[right]=t;
}
return TRUE;
}
void f(sqlist &l,int n,int m){
reversal_sq(l,1,l.length);
reversal_sq(l,1,m);
reversal_sq(l,m+1,n);
}
2.3 线性链表(链式存储)
线性链表的定义
线性表的链式存储定义是:用一组任意的存储单元存储线性表的数据元素。
它的特点是:
- 插入或删除时,不需要像顺序存储一样,移动其他元素,但是也失去了顺序表可随意读取数据元素内容的特点;
- 每个数据元素 a i a_i ai除了存储自己本身的信息,还有一个指示其直接后继的信息,这两部分组成了数据元素 a i a_i ai的存储映像,称为结点。
- 整个链表的存取必须从头指针开始进行,由于最后一个数据元素没有直接后继,示意图最后一个结点的指针为空(NULL)

线性链表的实现(C++实现)
这里我遇到了一个关于定义结构体的小问题,在严蔚敏的数据结构书中是这样写结构体的。
typedef struct lnode{
elemtype data;
struct lnode *next;
}lnode,*linklist;
我发现这其实是将结构体struct和typedef类型定义语句组合了起来。
这句话其实可以换成
struct lnode{
elemtype data;
struct lnode *next;
};//定义结构体
typedef lnode lnode,*linklist;//将结构体结点重命名
值得注意的是:因为 typedef 语句可以掩饰复合类型,如指针和数组。当经常用到需要申请相同类型的指针或者相同大小的数组时,就可以这样定义,例如
typedef int temp[100];
temp a;
这样执行申请到的a其实是int[100]数组。
所以在这里教材中为了方便的申请到指针使代码更加规范,这里采用了重命名方式将*lnode重新命名为linklist类型。
下面是定义链表的全部代码:
#include 链表的重点应该是尾插和头插法,所以要着重注意头插法和尾插法的原理,和区别。
线性链表的扩展
- 扩展:利用头插法实现链表的转置,比如要求将链表L={27,16,10}转置,请你设计算法实现:
void list_reversal_l(linklist &l){//用头插法将链表l翻转
linklist t,q,p;
t=q=l->next; //因为转置后第一个结点会变成最后一个结点,所以这里用t记录一下结点
for(;q;){
p=q->next; //因为后面q的next指针就被更改了,但是next的结点下一轮循环还需要使用,所以这里应该提前记忆一下next的信息
q->next=l->next; //头插法,将结点插到表头
l->next=q;
q=p; //进入下一个结点进行循环
}
t->next=NULL; //最后一个结点next置空
return;
}
2.4 顺序表和链表在复杂度上的区别
插入和删除
顺序表:
- 最好的情况:新元素插表尾,不需要移动数据,时间复杂度为 O ( 1 ) O(1) O(1);
- 最坏的情况:新元素插表头,移动原有的n个所有数据,时间复杂度 O ( n ) O(n) O(n);
- 平均情况:假设新元素插入到任何一个位置的概率相同,则平均移动 n 2 \frac{n}{2} 2n个元素,所以平均时间复杂度 O ( n 2 ) O(\frac{n}{2}) O(2n),即 O ( n ) O(n) O(n);
链表:
- 最好的情况:新元素插表头,指针能不用移动直接插入,时间复杂度为 O ( 1 ) O(1) O(1);
- 最坏的情况:新元素插表尾,指针移动经过到n个结点后才可插入,时间复杂度 O ( n ) O(n) O(n);
- 平均情况:假设新元素插入到任何一个位置的概率相同,则平均查找 n 2 \frac{n}{2} 2n个元素,所以平均时间复杂度 O ( n 2 ) O(\frac{n}{2}) O(2n),即 O ( n ) O(n) O(n);
删除同理。
查找
顺序表:
- 按位查找:最好、最坏、平均时间都是 O ( 1 ) O(1) O(1)
- 按值查找:最好的情况目标元素在表头,时间复杂度为 O ( 1 ) O(1) O(1),最坏的情况目标元素在表尾,时间复杂度 O ( n ) O(n) O(n);平均情况假设目标元素在任何一个位置的概率相同,则平均查找 n 2 \frac{n}{2} 2n个元素,所以平均时间复杂度 O ( n 2 ) O(\frac{n}{2}) O(2n),即 O ( n ) O(n) O(n);
链表:
- 无论是按位查找还是按值查找,时间复杂度都是 O ( n ) O(n) O(n);
2.5 双链表
双链表的含义
双链表,可进可退,比单链表多消耗一点存储空间来储存前驱的地址。
双链表的部分实现
这里只实现一部分函数,因为大多数函数操作是和单链表相差不大的,重复写我觉得没有多大的意义。
#include 2.6 循环链表
循环链表的含义
循环链表分为循环单链表和循环双链表两种:
循环单链表:与单链表唯一的差别就是,表中的最后一个结点的指针不是NULL,而改为只想头结点,从而整个链表形成一个环。如下图:

note:很多时候对链表的操作都是在头部和尾部
指针L的位置如果在头结点:找到尾部的时间复杂度 O ( n ) O(n) O(n)
指针L的位置如果在尾结点:找到头结点的时间复杂度 O ( 1 ) O(1) O(1),而且尾部的时间复杂度也是 O ( 1 ) O(1) O(1),只是在插入和删除时可能需要多修改一个L的位置。
循环双链表:与双链表的差别就是,表头结点的prior指向表尾,表尾结点的next指向头结点。如下图:
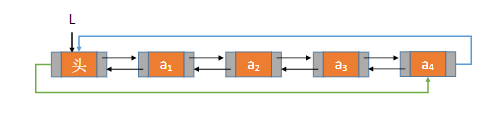
循环双链表的部分实现
#include 2.7 静态链表
静态链表的定义
静态链表:分配一段连续的内存空间,各个结点集中安置。
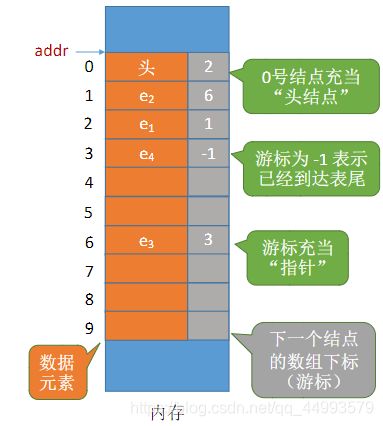
静态链表如上图所示,接下来用一个单链表作类比
静态链表内存中的addr指针相当于单链表中的L,游标相当于单链表中的next指针,与单链表不同的是,静态链表由数组存放,而单链表是一个一个分开的结点存放构成。
也就是说单链表的实现需要依靠指针申请空间操作的,但是有些低级语言是不存在这种操作的,但是又想在这种低级语言的环境下使用单链表的特性和功能,这时候静态链表就由此而生了。
静态链表的部分实现
静态链表的实现的难点在于:需要自己实现在实现单链表时所用的malloc函数和free函数。
这时候想要实现这两个函数的功能就需要引出备用链表的概念了。
备用链表的作用是回收数组中未使用或之前使用过(目前未使用)的存储空间,留待后期使用。
也就是说:静态链表使用数组申请的物理空间中,存有两个链表,一条连接数据,另一条连接数组中未使用的空间。
在这里注意:游标为0时,链表达到链尾。且备用链表的头指针为space[0].cur+
,而如果有数据则数据链表的头指针为space[MAXSIZE-1].cur。
#include