RHCE8 资料整理(四)
RHCE8 资料整理
- 第四篇 存储管理
-
- 第13章 硬盘管理
-
- 13.1 对磁盘进行分区
- 13.2 交换分区(swap分区)
- 第14章 文件系统
-
- 14.1 了解文件系统
- 14.2 了解硬链接
- 14.3 创建文件系统
- 14.4 挂载文件系统
- 14.5 设置永久挂载
- 14.6 查找文件
- 14.7 find的用法
- 第15章 逻辑卷管理
-
- 15.1 了解逻辑卷
- 15.2 创建逻辑卷
- 第16章 虚拟数据优化器VDO
-
- 16.1 了解什么是VDO
- 16.2 配置VDO
- 16.3 测试VDO
- 第17章 访问NFS存储及自动挂载
-
- 17.1 访问NFS存储
- 17.2 自动挂载

第四篇 存储管理
第13章 硬盘管理
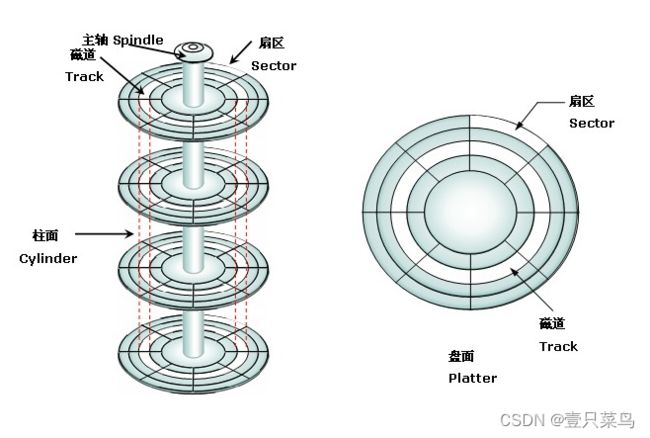
详细参考 https://blog.csdn.net/u010230019/article/details/133990531
我们知道磁盘可以划分为磁道,扇区、柱面等部分,而每个扇区size为512B,只能属于一个分区,不能同时属于多个分区。
第一个分区比较特殊,叫MBR(主引导记录),磁盘按照分区类型包括:主分区、扩展分区和逻辑分区。
- 主分区:直接从硬盘上划分,并可以直接格式化使用的分区
- 扩展分区:直接从硬盘上划分,但不能直接使用的分区,需要在其上划分更多小分区
- 逻辑分区:在扩展分区上划分的分区
分区表记录主分区和扩展分区信息,每记录一个分区(主分区或扩展分区)要消耗16B,所以分区表最多只能记录4个分区,一块硬盘最多划分4个分区,并且最多只能有一个扩展分区。
主引导记录(MBR,Master Boot Record)是采用MBR分区表的硬盘的第一个扇区,即C/H/S地址的0柱面0磁头1扇区,也叫做MBR扇区。主引导记录(master boot record,MBR)位于硬盘的第一物理扇区。由于历史原因,硬盘的一个扇区大小是512字节,包含最多446字节的启动代码、4个硬盘分区表项(每个表项16字节,共64字节)、2个签名字节(0x55,0xAA),如图1所示。分区表项的结构见表。

分区表:传统的分区方案(称为MBR分区方案)是将分区信息保存到磁盘的第一个扇区(MBR扇区)中的64个字节中,每个分区项占用16个字节,这16个字节中存有活动状态标志、文件系统标识、起止柱面号、磁头号、扇区号、隐含扇区数目(4个字节)、分区总扇区数目(4个字节)等内容。由于MBR扇区只有64个字节用于分区表,所以只能记录4个分区的信息。这就是硬盘主分区数目不能超过4个的原因。后来为了支持更多的分区,引入了扩展分区及逻辑分区的概念。但每个分区项仍用16个字节存储。
后面有时间这部分会详细整理下

13.1 对磁盘进行分区
查看分区,使用fdisk -l命令查看所有分区信息,或查看指定分区
fdisk -l [dev]
进入分区界面,语法:
fdisk [dev]
关于分区命令,详细参考 https://blog.csdn.net/u010230019/article/details/129381833
这里个比较有意思的是:在创建分区大小时,可以通过+sectors或+size{K,M,G,T,P}形式,举个例子,创建2G的分区,从2048扇区(默认是2048)开始计算:2G=2*1024M=2*1024*1024K=2*1024*1024*2扇区(1扇区=0.5K),所以一共需要4194304个扇区,最后一个扇区应该落在2048+4194304-1=4196351的位置,以上纯技术探讨,现实中我们更多使用+2G的形式
在分区类型中可以选择p主分区或e扩展分区,只能在扩展分区上建立逻辑分区
13.2 交换分区(swap分区)
swap分区在系统的物理内存不够用的时候,把硬盘内存中的一部分空间释放出来,以供当前运行的程序使用。那些被释放的空间可能来自一些很长时间没有什么操作的程序,这些被释放的空间被临时保存到Swap分区中,等到那些程序要运行时,再从Swap分区中恢复保存的数据到内存中。
查看交换分区
swapon -s
创建swap分区
mkswap /dev/sdb2 #创建
激活
swapon /dev/sdb2 #激活
关闭
swapoff /dev/sdb2
当有多个交换分区时,可以通过修改/etc/fstab调整其优先级
tail -1 /etc/fstab
/dev/sdb1 none swap defautls,pri=2 0 0
当写入fstab后,需要执行swapon -a加载信息,才能直接生效
第14章 文件系统
14.1 了解文件系统
详细参考 https://blog.csdn.net/u010230019/article/details/129358051
需要了解内容,包括:
- inode
- block
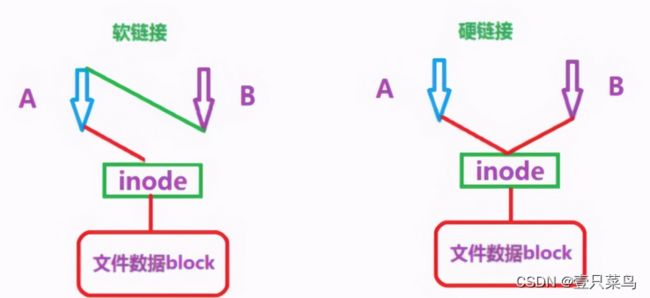
14.2 了解硬链接
创建硬链接
ln hardlink file #硬链接
ln -s softlink file #软链接
注意:
- 删除硬链接指向的文件,硬链接仍有效,因为它指向文件的inode
- 删除软连接指向的文件,软连接无效,因为它指向文件
14.3 创建文件系统
- 对已存在的分区进行格式化(如果未存在分区,则新建分区,参考13.1),格式
mkfs.文件系统 [options] /dev/sdb
#或
mkfs -t 文件系统 [options] /dev/sdb
-b 指定block大小,默认单位KB
-f 强制格式化
当分区已存在文件系统时,强制格式化是个不错的办法
例如
mkfs.ext4 /dev/sdb
#或
mkfs -t ext4 /dev/sdb
[root@server ~]# xfs_info /dev/vg0/lv1
meta-data=/dev/vg0/lv1 isize=512 agcount=4, agsize=38912 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=1, sparse=1, rmapbt=0
= reflink=1 bigtime=1 inobtcount=1
data = bsize=1024 blocks=155648, imaxpct=25
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0, ftype=1
log =internal log bsize=1024 blocks=3527, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
blkid能够查看块设备的属性
[root@server ~]# blkid
/dev/sr0: BLOCK_SIZE="2048" UUID="2022-04-19-20-42-48-00" LABEL="RHEL-9-0-0-BaseOS-x86_64" TYPE="iso9660" PTUUID="3a60e52f" PTTYPE="dos"
/dev/sda2: UUID="8619dadd-3e38-4561-b72e-3d0c4c7be205" BLOCK_SIZE="512" TYPE="xfs" PARTUUID="df38b0a2-02"
/dev/sda5: UUID="858154c9-7e26-4668-b084-f6432be8b5e7" BLOCK_SIZE="512" TYPE="xfs" PARTUUID="df38b0a2-05"
/dev/sda3: UUID="a170c809-483a-4c70-a2b6-00831e1f7526" TYPE="swap" PARTUUID="df38b0a2-03"
/dev/sda1: UUID="ada9fc4c-61b9-4fef-aed7-4228d8e7887f" BLOCK_SIZE="512" TYPE="xfs" PARTUUID="df38b0a2-01"
/dev/sda6: PARTUUID="df38b0a2-06"
如果想单独查看某个XFS文件系统的UUID,可以通过xfs_admin -u 分区名查看
[root@server ~]# xfs_admin -u /dev/sda2
UUID = 8619dadd-3e38-4561-b72e-3d0c4c7be205
想更改UUID,可以通过uuidgen手动生成UUID
[root@server ~]# uuidgen
39ad98bf-90f9-4931-a577-58aced724a0f
然后对XFS文件系统更改UUID,通过-U选项
xfs_admin -U 'uuid' /dev/sdb
14.4 挂载文件系统
通过df能够查看分区已挂载及分区使用情况
df [-hT]
-h #以合适单位显示
-T #显示文件系统
挂载命令mount,格式
mount [-t vfstype] [-o opt1, opt2, ...] /dev/设备 目录(挂载点)
#-t 常用选项
iso9660:光盘或者镜像
nfs:文件网络共享
msdos:DOS fat16文件系统
auto: 自动检测文件系统
#-o 常用选项
loop :用来把一个文件当成硬盘分区挂接上系统
ro :采用只读方式挂接设备
rw :采用读写方式挂接设备
iocharset :指定访问文件系统所用字符集,例如iocharset=utf8
remount :重新挂载
# 默认-t auto,-o rw
挂载前,目录需要存在
注意:如果被挂载的目录中存在数据,挂载后,数据将会被隐藏,无法查看,一般情况下也不会被删除。举个例子,比如一个分区有500G空间,某个目录占用了200G,后来使用该目录进行挂载,实际使用空间只有300G,却怎么也找不到这200G的空间被谁占用了(实际该目录的原有数据以隐藏的形式,占用了挂载设备的空间)。当出现这种情况,就需要先把设备卸载,然后处理这部分数据。
卸载命令unmount,格式
unmount /dev/设备
#或
unmount /挂载点
有时可能会出现设备无法卸载的情况,例如挂载点的文件被某个进程占用,可能提示target is busy等内容
可以使用fuser命令,通过文件或端口定位进程,进行查看
[root@server ~]# fuser -mv /dev/sda1
USER PID ACCESS COMMAND
/dev/sda1: root ...
root 15446 ..c.. bash
利用kill -9 pid结束进程
kill -9 15446
此时就可以正常卸载了
当文件系统改为只读时(-o rw改为-o ro),可对设备重新挂载,此时并不需要卸载之后再挂载,可通过
mount -o remount,新选项 /挂载点
例如
mount -o remount,rw /dev/sdb
我们在忘记root密码的时候可能会用到
14.5 设置永久挂载
前面提到mount挂载仅时临时生效,重启后设备不会自动挂载。如果希望永久挂载,则需要写入/etc/fstab中,格式
设备 挂载点 文件系统 挂载选项 dump值 fsck值
#或
设备UUID 挂载点 文件系统 挂载选项 dump值 fsck值
dump值:是否被dump备份命令作用,通常这个值为0或1
fsck值:是否检验扇区,开机过程中,系统默认会以fsck检验系统是否完整,通常这个值为0或1
这两个值建议为0,不建议使用其他值
[root@server ~]# cat /etc/fstab
...
UUID=8619dadd-3e38-4561-b72e-3d0c4c7be205 / xfs defaults 0 0
UUID=ada9fc4c-61b9-4fef-aed7-4228d8e7887f /boot xfs defaults 0 0
UUID=a170c809-483a-4c70-a2b6-00831e1f7526 none swap defaults 0 0
挂载时,建议使用uuid,因为设备名称容易发生变更,而uuid一般不会
写入/etc/fstab后,如果当前设备未被挂载,可使用mount -a自动挂载
14.6 查找文件
linux中查找文件的常用工具,有which,locate和find。
详细参考 https://blog.csdn.net/u010230019/article/details/132166657
which一共用于查找可执行文件
[root@server ~]# which cd
/usr/bin/cd
locate用于查询文件名或路径中包含特有关键字的文件,locate基于数据库文件/var/lib/mlocate/mlocate.db进行查询
如果该数据库文件不存在,则使用locate查询则会报错,此时创建该数据库即可
updatedb
locate abcdef
14.7 find的用法
find命令涉及的参数选项实在庞大,详细参考 https://blog.csdn.net/u010230019/article/details/132166657
这里只列举几个简单的示范:
find [path] -name|-iname xxx #基于名称查询(区分大小写)
find [path] -user|-group xxx #基于用户或组名查询
find [path] -nouser|-nogroup xxx #查询没有属主或属组的文件
find [path] -uid|-gid xxx #基于uid或gid查询
find [path] -size [+|-] 2M #查找大于|小于|等于2M的文件
find [path] -mtime [+|-] 1 #根据文件的时间查询,默认单位天,24小时以内,使用-1。24-48小时,用1。大于48小时,用+1。
find [path] -mmin [+|-] 1 #根据文件的时间查询,单位为分钟
find [path] -type [d|f|l|b] #根据文件类型查询,d目录,f文件,l链接,b块设备
find [path] -perm [/|-]326 #根据权限查询,注意符号和数字间没有空格,/326表示只要配置326中权限一个即可,
#-326表示可以比326多,不可以比326少
find [path] -perm /N000 #查找特殊权限suid,sgid,粘滞位
这条单独说明下:这里N代表4、2、1中的某个数或者某几个数的和,后面3个0表示忽略普通权限
N=4:查找含有suid的文件
N=2:查找含有sgid的文件
N=1:查找含有粘滞位的文件
N=6 6=4+2:查找含有suid或sgid的文件
find -perm /7000 #查找当前目录中含有特殊位的文件
组合查询
find /目录 \( 条件1 -o 条件2 \) -a \( 条件3 -o 条件4 \)
-o #表示或
-a #表示与
注意这里的反斜线\起到转义的作用,这里的\(和\)前后都要有空格 ,例如
find / \( -size 3M -o -size +3M \) -a \( -nouser -o -nogroup \)
排除某个目录
find /目录 \( -path 目录1 -o -path 目录2 \) -prune -o 条件 -print
在/目录中按照条件查找文件,但排除目录1和目录2
对查询结果进行操作
find /usr/bin /usr/sbin -perm /7000 -exec ls -l {} \;

注意\;
第15章 逻辑卷管理
15.1 了解逻辑卷
详细参考 https://blog.csdn.net/u010230019/article/details/129381833
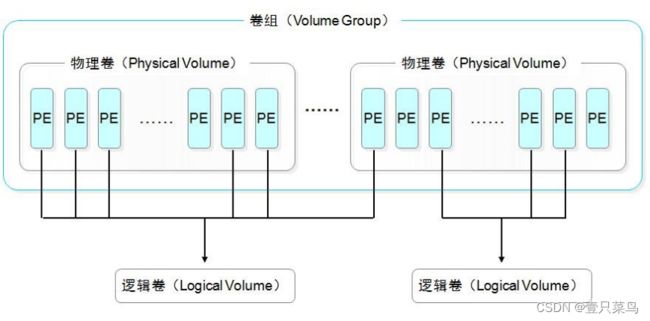
- PE
- PV
- VG
- LV
物理卷PV相关命令
pvs | pvscan #查看pv
pvcreate /dev/sdb #创建pv
pvremove /dev/sdb #删除pv
卷组VG相关命令
vgs | vgscan #查看卷组
vgcreate [-s n] vg0 /dev/sdb1 /dev/sdb2 #创建卷组
-s n:指定pe的大小,默认单位为M,默认值为4M
vgextend vg0 /dev/sdb3 #扩展卷组
vgreduce vg0 /dev/sdb3 #从卷组中去除某设备
vgdisplay vg0 #查看卷组详细信息
vgremove vg0 #删除卷组
15.2 创建逻辑卷
逻辑卷LV相关命令
lvs | lvscan #查看逻辑卷
lvcreate -L 大小 -n 名称 卷组 #创建逻辑卷1,直接指定卷大小
lvcreate -l pe数 -n 名称 卷组 #创建逻辑卷2,按照pe数量指定大小,参考vg创建时的pe大小
lvcreate -l 数字%free -n 名称 卷组 #创建逻辑卷3,按照剩余空间
lvdisplay 逻辑卷名
lvremove 逻辑卷名 #移除
lvextend [-r] -L [+]100{M,G} -n 逻辑卷名 #逻辑卷扩容,带+表示在原有基础上加100MB,不带表示直接扩充至100MB
-r #很重要,能够在扩展逻辑卷的同时,扩展文件系统
lvreduce -L [-]100{M,G} -n 逻辑卷名 #缩容逻辑卷
-
需要注意:逻辑卷扩容了,并不代表文件系统也得到了扩容的磁盘空间,如果
lvcreate未加-r则需要单独扩展文件系统XFS使用xfs_growfs进行扩展,xfs_growfs /挂载点EXT4使用resize2fs进行扩展,resize2fs 逻辑卷名
-
逻辑卷缩容,非常不建议对逻辑卷做缩小操作。但如果必须缩小,一定要先缩小文件系统,然后再缩小逻辑卷,否则会破坏文件系统。

原本文件系统和逻辑卷时贴合的,如果先把逻辑卷缩小了,则文件系统会多出一块,没有承载体,整个文件系统就会被破坏。- XFS文件系统不支持缩小
- EXT4支持文件系统缩小,命令
resizefs 逻辑卷名 100M,这里100M是最终文件系统的大小,并非缩减大小
以创建在逻辑卷上的EXT4文件系统为例,演示整个缩容过程:
- 卸载文件系统
umount /mnt/lv1- 对文件系统进行fsck检查
fsck -f /dev/vg0/lv1- 缩小文件系统
resize2fs /dev/vg0/lv1 100M- 缩容逻辑卷
lvreduce -L -500M /dev/vg0/lv1这里会警告“如果你缩小逻辑卷可能会损坏数据,你是否要继续?[y/n]”
- 重新挂载逻辑卷
mount /dev/vg0/lv1 /mnt/lv1 -
逻辑卷恢复,当在逻辑卷中存储数据时,数据是写入底层PV中的,所以即使删除了逻辑卷,也并没有删除存储在PV中的数据。如果恢复被删除的逻辑卷,仍然能看到逻辑卷中的原有数据。下面我们开始演示:
- 卸载并把逻辑卷删除
umount /mnt/lv1 lvremove -f /dev/vg0/lv1 ll /mnt/lv1/ total 0- 我们在卷组上的所有操作均有日志记录,可以通过
vgcfgrestore --list 卷组名查看
[root@server ~]# vgcfgrestore --list vg0 ... File: /etc/lvm/archive/vg0_00005-2049433319.vg/vg0_00005-2049433319.vg VG name: vg0 Description: Created *before* executing 'lvremove -f /dev/vg0/lv1' Backup Time: Wed Oct 25 19:29:43 2023 File: /etc/lvm/backup/vg0/vg0 VG name: vg0 Description: Created *after* executing 'lvremove -f /dev/vg0/lv1' Backup Time: Wed Oct 25 19:29:43 2023可以看到,执行
'lvremove -f /dev/vg0/lv1'命令之前的日志文件是/etc/lvm/archive/vg0_00005-2049433319.vg(注意此处比上面查询结果少了具体文件),那么我们就利用这个文件对lv进行恢复,恢复命令是vgcfgrestroe,语法:vgcfgrestore -f 日志文件 卷组名- 开始恢复
[root@server ~]# vgcfgrestore -f /etc/lvm/archive/vg0_00005-2049433319.vg vg0 Volume group vg0 has active volume: lv2. Volume group vg0 has active volume: lv3. WARNING: Found 2 active volume(s) in volume group "vg0". Restoring VG with active LVs, may cause mismatch with its metadata. Do you really want to proceed with restore of volume group "vg0", while 2 volume(s) are active? [y/n]: y Restored volume group vg0. [root@server ~]# lvs LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert lv1 vg0 -wi------- 200.00m lv2 vg0 -wi-a----- 80.00m lv3 vg0 -wi-a----- 80.00m [root@server ~]# lvscan |grep lv1 inactive '/dev/vg0/lv1' [200.00 MiB] inherit- 可以看到lv1已经恢复,但此时状态时
inactive,现在需要激活它
[root@server ~]# lvchange -ay /dev/vg0/lv1 [root@server ~]# lvscan |grep lv1 ACTIVE '/dev/vg0/lv1' [200.00 MiB] inherit-ay表示active yes,此时已激活- 挂载逻辑卷
[root@server ~]# mount /dev/vg0/lv1 /mnt/lv1/ [root@server ~]# ll /mnt/lv1/ total 2 -rw-r--r-- 1 root root 681 Oct 25 19:27 fstab -rw-r--r-- 1 root root 23 Oct 25 19:28 issue目录可以正常访问了
-
逻辑卷快照
LVM还具备有“快照卷”功能,该功能类似于虚拟机软件的还原时间点功能。例如,可以对某一个逻辑卷设备做一次快照,如果日后发现数据被改错了,就可以利用之前做好的快照卷进行覆盖还原。LVM的快照卷功能有几个特点:- 快照卷的文件是逻辑卷中文件的影子(通过硬链接实现);
- 快照卷仅一次有效,一旦执行还原操作后则会被立即自动删除。
- 不要对快照卷进行格式化
- 在快照卷中进行任何文件操作都不会影响逻辑卷
- 快照仅是逻辑卷在某个时间点的记录,当快照完成后,对逻辑卷的操作也不会影响快照卷,可以说两者相互独立
- 创建快照,语法
lvcreate -L 大小 -n 名称 -s 逻辑卷[root@server ~]# lvcreate -L 20M -n lv1_snap -s /dev/vg0/lv1 Logical volume "lv1_snap" created. [root@server ~]# lvscan ACTIVE Original '/dev/vg0/lv1' [200.00 MiB] inherit ACTIVE '/dev/vg0/lv2' [80.00 MiB] inherit ACTIVE '/dev/vg0/lv3' [80.00 MiB] inherit ACTIVE Snapshot '/dev/vg0/lv1_snap' [20.00 MiB] inherit [root@server ~]# lvs LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert lv1 vg0 owi-aos--- 200.00m lv1_snap vg0 swi-a-s--- 20.00m lv1 0.00 lv2 vg0 -wi-a----- 80.00m lv3 vg0 -wi-a----- 80.00m- 挂载
[root@server ~]# mkdir /mnt/lv1_snap [root@server ~]# mount -o nouuid /dev/vg0/lv1_snap /mnt/lv1_snap/ [root@server ~]# ll /mnt/lv1_snap/ total 2 -rw-r--r-- 1 root root 681 Oct 25 19:27 fstab -rw-r--r-- 1 root root 23 Oct 25 19:28 issue注意:
- 快照不需要格式化
- 逻辑卷的文件系统是XFS的,所以挂载快照需要加上-o nouuid选项- 使用快照恢复数据
快照只能恢复一次,恢复完后快照也就没有了
[root@server ~]# rm -rf /mnt/lv1/ [root@server ~]# ll /mnt/lv1 total 0 [root@server ~]# ll /mnt/lv1_snap/ total 2 -rw-r--r-- 1 root root 681 Oct 25 19:27 fstab -rw-r--r-- 1 root root 23 Oct 25 19:28 issue [root@server ~]# umount /mnt/lv1 [root@server ~]# umount /mnt/lv1_snap [root@server ~]# lvconvert --merge /dev/vg0/lv1_snap Merging of volume vg0/lv1_snap started. vg0/lv1: Merged: 100.00% [root@server ~]# mount /dev/vg0/lv1 /mnt/lv1 [root@server ~]# ll /mnt/lv1 total 2 -rw-r--r-- 1 root root 681 Oct 25 19:27 fstab -rw-r--r-- 1 root root 23 Oct 25 19:28 issue [root@server ~]# ll /mnt/lv1_snap/ total 0
第16章 虚拟数据优化器VDO
16.1 了解什么是VDO
VDO(Virtual Data Optimize)是RHEL8/Centos8上新推出的一个存储相关技术(最早在7.5测试版中开始测试),是Redhat收购的Permabit公司的技术。
VDO的主要作用是节省磁盘空间,比如让1T的磁盘能装下1.5T的数据,从而降低数据中心的成本。
那vdo是如何实现的呢,关键原理主要是重删和压缩,重删就是硬盘里拷贝来相同的数据,以前要占多份空间,现在只需要1份空间就可以了。类似我们在百度网盘中上传一个大型软件安装包,能实现秒传,其实是之前就有,所以无需再传一遍,也无需再占百度一份空间。另一方面是数据压缩,类似于压缩软件的算法,也可以更加节省磁盘空间。
举例来说:在引进VDO技术前,File1和File2有相同的数据,那么他们各自占用磁盘空间,而引进该技术后,相同的数据只存储一份。

但从某种意义上讲,一块磁盘可能存放的超过本身磁盘容量的数据量
原理:https://www.jianshu.com/p/89bb879323ca
16.2 配置VDO
- 安装
yum install vdo kmod-kvdo -y
[root@node-138 ~]# vdo list
[root@node-138 ~]#
我们为虚拟机新增一块硬盘,然后开始配置VDO
- 创建vdo
[root@node-138 ~]# vdo create --name vdo1 --device /dev/sdb --vdoLogicalSize 5G
Creating VDO vdo1
Starting VDO vdo1
Starting compression on VDO vdo1
VDO instance 0 volume is ready at /dev/mapper/vdo1
[root@node-138 ~]# vdo list
vdo1
- 对设备格式化,创建文件系统
[root@node-138 ~]# mkfs.xfs -K /dev/mapper/vdo1
meta-data=/dev/mapper/vdo1 isize=512 agcount=4, agsize=327680 blks
= sectsz=4096 attr=2, projid32bit=1
= crc=1 finobt=0, sparse=0
data = bsize=4096 blocks=1310720, imaxpct=25
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=1
log =internal log bsize=4096 blocks=2560, version=2
= sectsz=4096 sunit=1 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
[root@node-138 ~]# df -hT
Filesystem Type Size Used Avail Use% Mounted on
devtmpfs devtmpfs 898M 0 898M 0% /dev
tmpfs tmpfs 910M 0 910M 0% /dev/shm
tmpfs tmpfs 910M 1.6M 909M 1% /run
tmpfs tmpfs 910M 0 910M 0% /sys/fs/cgroup
/dev/mapper/centos-root xfs 27G 17G 11G 63% /
/dev/sda1 xfs 1014M 181M 834M 18% /boot
tmpfs tmpfs 182M 0 182M 0% /run/user/0
[root@node-138 ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 30G 0 disk
├─sda1 8:1 0 1G 0 part /boot
└─sda2 8:2 0 29G 0 part
├─centos-root 253:0 0 27G 0 lvm /
└─centos-swap 253:1 0 2G 0 lvm [SWAP]
sdb 8:16 0 5G 0 disk
└─vdo1 253:2 0 5G 0 vdo
sr0 11:0 1 4.4G 0 rom
mkfs.xfs -K /dev/mapper/vdo1中-K类似与windows中的快速格式化
- 挂载设备
[root@node-138 ~]# mkdir /mnt/vdo1
[root@node-138 ~]# mount /dev/mapper/vdo1 /mnt/vdo1/
[root@node-138 ~]# vdostats --hu
Device Size Used Available Use% Space saving%
/dev/mapper/vdo1 5.0G 3.0G 2.0G 60% 98%
[root@node-138 ~]# df -Th
Filesystem Type Size Used Avail Use% Mounted on
devtmpfs devtmpfs 898M 0 898M 0% /dev
tmpfs tmpfs 910M 0 910M 0% /dev/shm
tmpfs tmpfs 910M 1.6M 909M 1% /run
tmpfs tmpfs 910M 0 910M 0% /sys/fs/cgroup
/dev/mapper/centos-root xfs 27G 17G 11G 63% /
/dev/sda1 xfs 1014M 181M 834M 18% /boot
tmpfs tmpfs 182M 0 182M 0% /run/user/0
/dev/mapper/vdo1 xfs 5.0G 33M 5.0G 1% /mnt/vdo1
这里自身消耗了3G空间(Used那列),因为这里不存在文件,所以空间节省率为98%(Space saving%)
16.3 测试VDO
-
向服务器上传一个较大文件
[root@node-138 ~]# ll /root/ -h|grep sonar.tar -rw-r--r-- 1 root root 537M Oct 25 15:27 sonar.tar -
把该文件copy到vdo目录中
- 第一次拷贝文件,如果未出现相同的文件内容,所以节省率可以很小 11%
[root@node-138 ~]# cp /root/sonar.tar /mnt/vdo1/file1 [root@node-138 ~]# vdostats --hu Device Size Used Available Use% Space saving% /dev/mapper/vdo1 5.0G 3.5G 1.5G 69% 11%- 第二次拷贝文件,由于两次拷贝文件内容相同,所以磁盘使用量依旧是3.5G,因此节省了约500M空间
节省率在50%左右(1/2)
[root@node-138 ~]# cp /root/sonar.tar /mnt/vdo1/file2 [root@node-138 ~]# vdostats --hu Device Size Used Available Use% Space saving% /dev/mapper/vdo1 5.0G 3.5G 1.5G 69% 51%- 第三次拷贝文件,三次拷贝文件内容相同,所以磁盘使用量依旧是3.5G,因此节省了约2个500M空间
节省率在67%左右(2/3)
[root@node-138 ~]# cp /root/sonar.tar /mnt/vdo1/file3 [root@node-138 ~]# vdostats --hu Device Size Used Available Use% Space saving% /dev/mapper/vdo1 5.0G 3.5G 1.5G 69% 68% -
删除vdo设备
[root@node-138 ~]# umount /mnt/vdo1 [root@node-138 ~]# vdo remove -n vdo1 Removing VDO vdo1 Stopping VDO vdo1 [root@node-138 ~]# ll /mnt/vdo1/ total 0
第17章 访问NFS存储及自动挂载
17.1 访问NFS存储
详细参考 https://blog.csdn.net/u010230019/article/details/129037280
NFS即网络文件系统,实现linux服务器之间共享
17.2 自动挂载
这里的自动挂载是指,把一个外部设备和某个目录关联起来,平时是否挂载不需要考虑,但当访问该目录的时候,系统就可以访问到外部设备,这个时候系统会自动把外部设备挂载到该目录上。
一般常用在挂载软件光盘作为yum源
- 挂载光盘
mount /dev/cdrom /mnt
- 编写repo文件,如下
cat /etc/yum.repos.d/aa.repo
[aa]
name=aa
baseurl=file:///mnt/AppStream
enabled=1
gpgcheck=0
安装autofs,命令如下
yum install autofs -y
自动挂载光盘
下面我们把光盘自动挂载到/mnt/zz/dvd目录上,注意这里不需要创建dvd目录
[root@server ~]# mkdir /mnt/zz
在/etc/auto.master.d目录中创建后缀为autofs的文件,后缀名必须是autofs
[root@server ~]# cat /etc/auto.master.d/aa.autofs
/mnt/zz /etc/auto.aa
该文件的意思是把哪个外部设备挂载到/mnt/zz的子目录上由/etc/auto.aa决定,内容使用【tab】分割
[root@server ~]# cat /etc/auto.aa
dvd -fstype=iso9660,ro :/dev/cdrom
该文件格式:
子目录 -fstype=文件系统,选项1,选项2 :外部设备
这里的外部设备如果是本地磁盘或者光盘,冒号(:)前面保持为空,但冒号不能省略
如果是其他机器上的共享目录,则写远端IP。
结合aa.autofs的意思,即当访问/mnt/zz/dvd时,系统会自动把/dev/cdrom挂载到该目录上
systemctl restart autofs
重启后生效
自动挂载NFS远程目录

本次这个实验比较有意思,通过NFS在SVR1添加mary用户,指定家目录为/rhome/mary,并且指定NFS网络共享目录也为/rhome/mary
在SVR2也添加mary用户,指定家目录为/rhome/mary,不过在添加用户的时候,并不创建家目录,而是通过autofs自动挂载到SVR1的NFS共享目录,这样每当在SVR2登录mary的时候,就自动切换到挂载目录了
- 在SVR1执行
useradd -d /rhome/mary mary
echo 123456 |passwd --stdin mary
[root@node-138 ~]# cat /etc/exports
/rhome *(rw,no_root_squash)
[root@node-138 ~]# exportfs -arv
exporting *:/rhome
[root@node-138 ~]# chmod o=rx /rhome/mary/
[root@node-138 ~]# ll /rhome/mary/ -d
drwx---r-x 4 mary mary 119 Oct 27 09:05 /rhome/mary/
在SVR1上使用了NFS服务
- 在SVR2执行
useradd -d /rhome/mary -M mary
echo 123456|passwd --stdin mary
[root@server ~]# cat /etc/auto.master.d/bb.autofs
/rhome /etc/auto.bb
[root@server ~]# cat /etc/auto.bb
mary -fstype=nfs,rw 192.168.17.138:/rhome/mary
[root@server ~]# showmount -e 192.168.17.138
Export list for 192.168.17.138:
/rhome *
systemctl restart autofs
[root@server ~]# su - mary
[mary@server ~]$ pwd
/rhome/mary
[mary@server ~]$ ll
total 4
-rw-r--r-- 1 root root 4 Oct 27 09:05 123
drwxr-xr-x 2 1018 1018 6 Aug 14 17:12 WWW
[mary@server ~]$ mount|grep mary
192.168.17.138:/rhome/mary on /rhome/mary type nfs4 (rw,relatime,vers=4.2,rsize=262144,wsize=262144,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=192.168.17.140,local_lock=none,addr=192.168.17.138)
在SVR2上使用了autofs服务