30 “select distinct(field1)“ 的实现
前言
在日常工作生活中, 我们应该经常会使用到 select distinct(field) from table; 等功能
来实现 获取符合条件的 field 的去重之后的记录信息
然后 我们这里来看一下 具体的实现
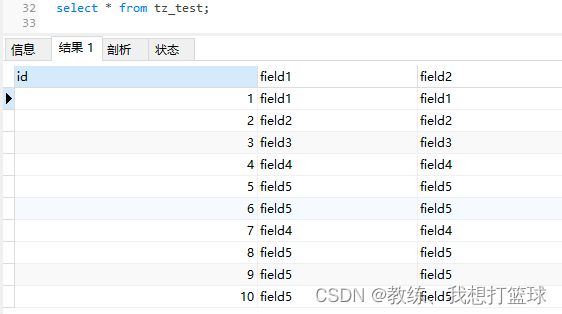
测试数据表如下
CREATE TABLE `tz_test` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`field1` varchar(12) DEFAULT NULL,
`field2` varchar(16) DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE,
KEY `field1` (`field1`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=108 DEFAULT CHARSET=utf8
测试数据列表如下

distinct 的实现
这里来看一下 “select distinct(field1) from tz_test;”
接下来 分为三种情况, 分别 distinct 三种不同的字段
假设目标字段是主键索引的情况
查询主键索引, 然后迭代数据返回 比如这里是 id 为 1 的记录

如下为 id 为10 的记录
假设目标字段有索引的情况
执行 explain 情况如下

我们这里 field1 有索引, 我们来看一下 实现 的情况, 这个走的是 field1 的索引树
这里遍历的是 field1 索引树, 会依次遍历
field1->1
field2->2
field3->3
field4->4
field4->7
field5->5
field5->6
field5->8
field5->9
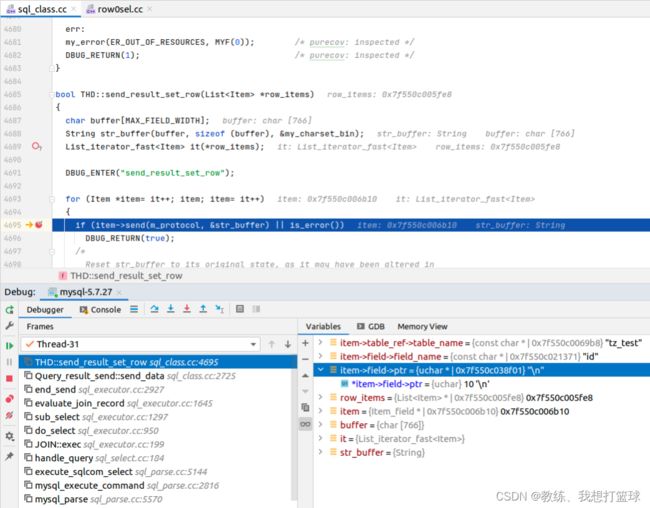
field5->10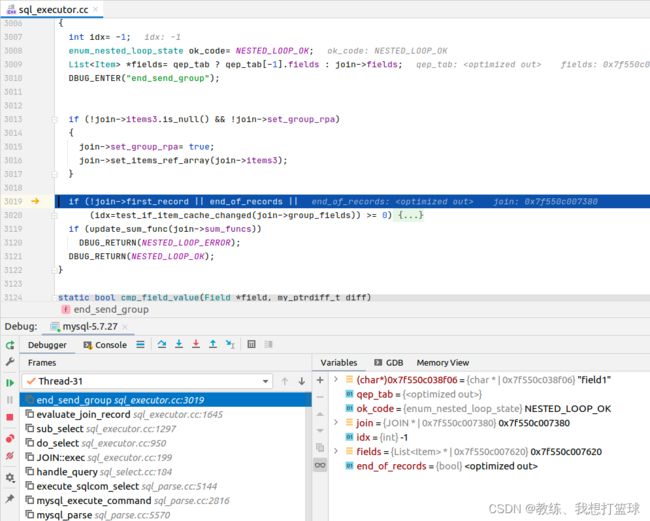
对于 “field1->1, field2->2, field3->3, field4->4” 会走 “test_if_item_cache_changed” 对应的 if 的 block, 其中会输出字段 field1 的值

对于 “field4->7” 不会走 “test_if_item_cache_changed” 对应的 if 的 block, 就不会输出字段信息到 客户端
join->group_fields 中存放的是 field1 上一次迭代的数据的值
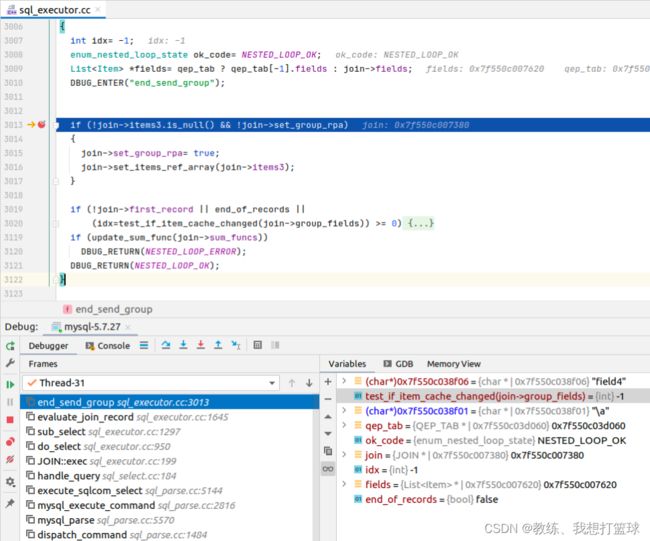
对于 “field5->5”, 会走 “test_if_item_cache_changed” 对应的 if 的 block, 其中会输出字段 field1 的值
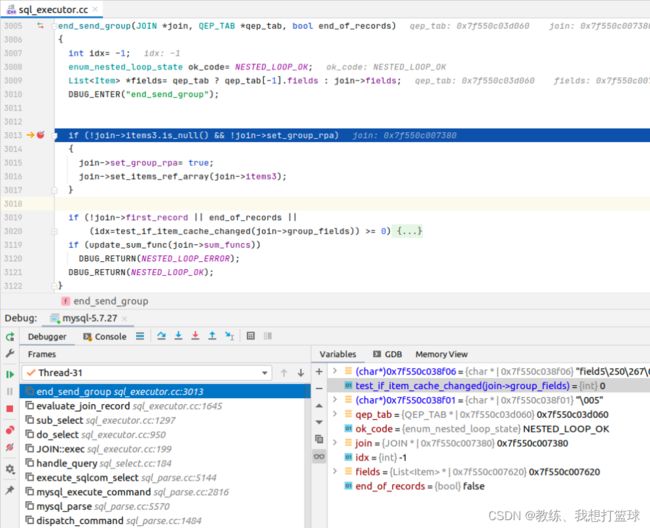
对于 “field5->6, field5->8, field5->9, field5->10” 不会走 “test_if_item_cache_changed” 对应的 if 的 block, 就不会输出字段信息到 客户端

假设目标字段无索引的情况
为了更好的调试, 更新 field2 的字段数据如下
执行 explain 情况如下

这个的实现是基于 临时表来实现的
数据从真实业务表, 抽取到临时表的处理如下
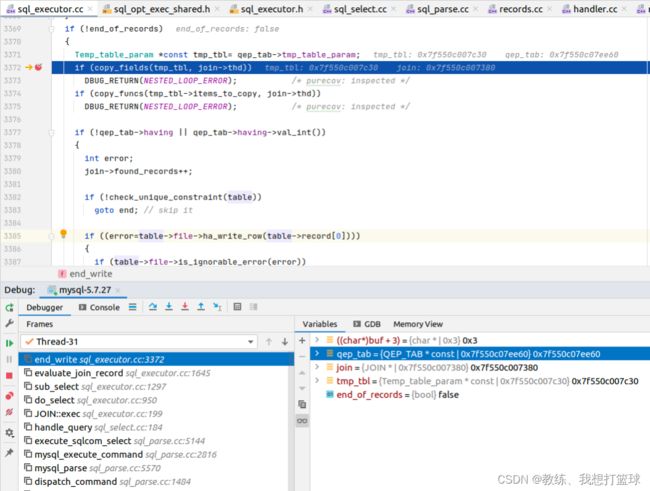
外层的 sub_select 是遍历 tz_test 表的常规流程, 然后这里的处理是 拷贝需要的字段, 然后使用 table->file->ha_write_row 入库临时表
然后使用同样的步骤拷贝了 ”field2”, “field3” , “field4” , “field5” 到临时表
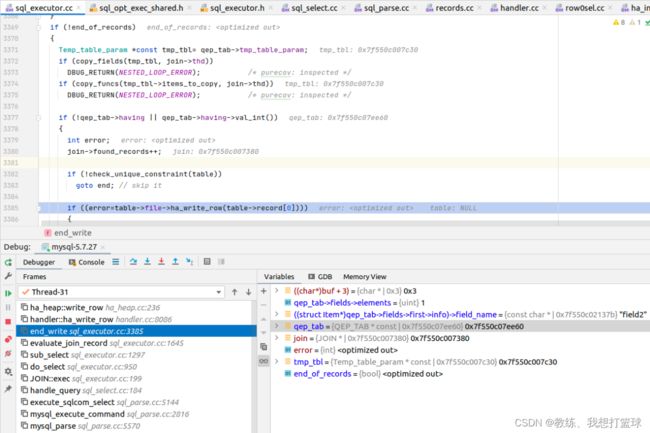
然后临时表的 table->record[0] 信息变化如下, 可以看到将 field2 的字段数据拷贝进去了
临时表仅仅只有一个字段 field2

临时表结构如下, 一个字段, 然后字段名称为 field2

然后向临时表写出数据的处理是在这里
临时表是基于 ha_heap, 将数据存放在内存中的, 和之前提到过的 union 的处理类似
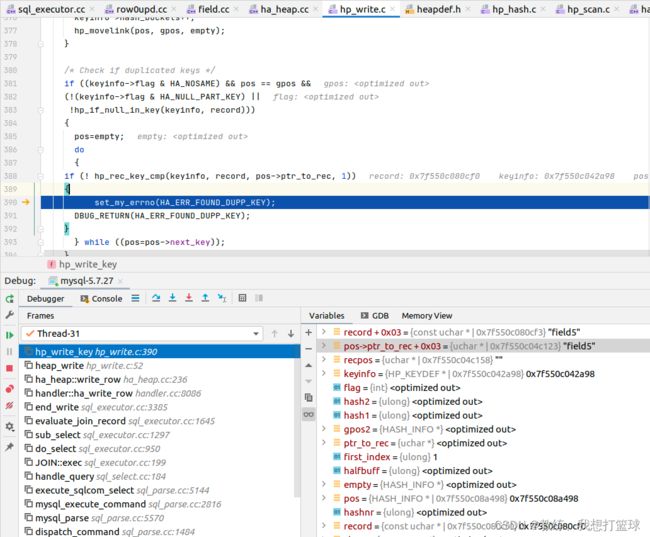
接下来的 “field4” , “field5” , “field5” , “field5” 由于存在唯一约束, 因此 接下来这几个记录的 field2 没有入库
然后是迭代临时表的数据, 响应给客户端
如下图 join_init_read_record + qep_tab->read_record.read_record 为迭代临时表中的数据
evaluate_join_record 为输出结果信息到客户端

迭代临时表中所有的记录, 响应回去
依次为 ”field1”, ”field2”, “field3” , “field4” , “field5”
创建临时表, 以及定义 keyDefinition 的地方
完