不想敲代码,如何快速实现数据标注、模型训练、高效部署?
SpireView简介
SpireView自动化标注工具可以减少人工标注的成本和时间,从而降低整个深度学习项目的成本。让更多的企业和组织参与深度学习项目,促进深度学习技术的发展和应用。
数据标注
1、下载SpireView标注软件,推荐下载最新版本,从百度网盘下载并解压。
https://gitee.com/amovlab1/spireview.git
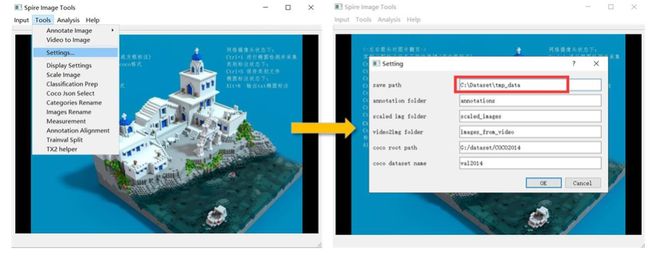
2、双击 SpireView.exe 打开标注软件,点击 Tools→Settings...在 saving path一栏填写一个英文路径,用于保存标注的文件。
注意:
所有的标注文件都会存储在这个文件夹中。
3、点击 Input→Image Dir选择待标注图像文件夹,导入待标注图像。
4、点击 Tools→Annotate Image选择标注类型,其中Box Label指矩形框标注,Instance Label指分割标注。
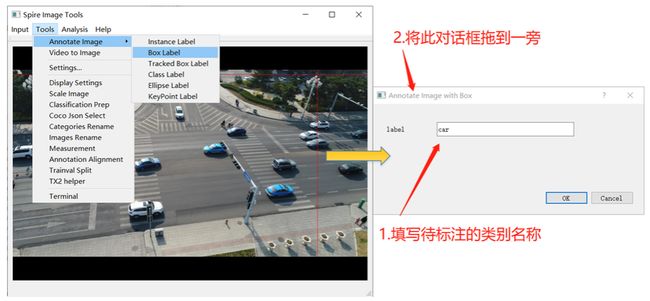
5、在弹出的界面中,修改 label为待标注目标类别,该界面无需关闭,完成单张标注后,左右方向键(-/→)切换上/下一张,标注结果自动保存。
6、鼠标滚轮放大缩小图像,按住左键移动可视图像区域,左键点击2个点将目标框包围(矩形框标注时)。

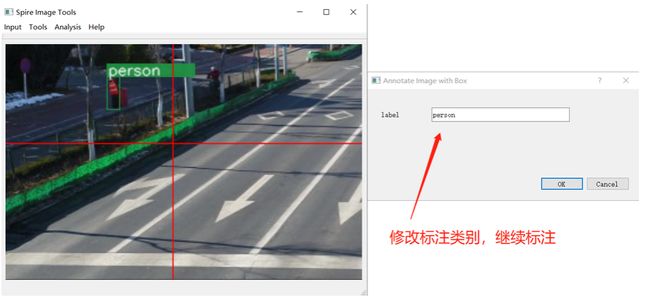
7、标注时,如果点错,鼠标右键可以取消。标注完成后, 如果不满意,可以左键点击绿色边框(边框会变红,如下图所示),按 Delete 删除。

8、标注多个类别时,修改标签即可。
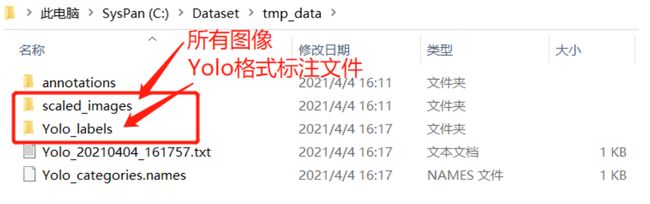
9、全部标注完成后,Ctrl+O选择标注格式并输出结果。此处我们选择Yolo detection format;如果是训练分割网络,额外选中output segs,点击OK在保存路径下生成YOLO格式训练文件;对于YOLO训练来说,我们需要scaled_images文件夹、Yolo_labels文件夹和Yolo_categories.names文件。
注意:如下两个文件夹是我们训练所需要的。
模型训练
1、训练准备:
在训练服务器/工作站计算机(带有12G显存以上的Nvidia显卡,推荐Ubuntu系统,需要安装CUDA 10.2+、PyTorch 1.7+) 上新建文件夹 [PATH-TO-YOUR-DATA]/images/train , 文件夹用于存放上一步骤中scaled_images文件夹内训练图片;新建文件夹 [PATH-TO-YOUR-DATA]/labels/train,文件夹用于存放Yolo_labels文件夹内训练标注。
模型结构(以YOLOv5算法为例):Yolov5发布的预训练模型,包含yolov5l.pt、yolov5l6.pt、yolov5m.pt、yolov5m6.pt、yolov5s.pt、yolov5s6.pt、yolov5x.pt、yolov5x6.pt等。针对不同大小的网络整体架构(n, s, m, l, x)都是一样的,只不过会在每个子模块中采用不同的深度和宽度,分别应对yaml文件中的depth_multiple和width_multiple参数。
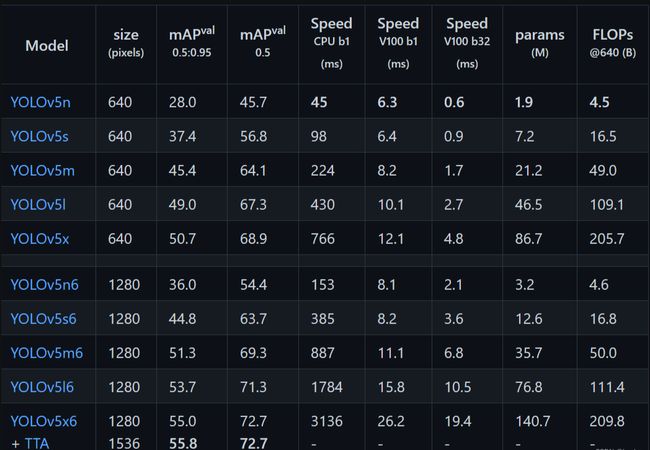
2、下载YOLOv5-v7代码。
git clone https://gitee.com/amovlab1/yolov5-v7.git
cd yolov5-v7
pip3 install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple/3、对于训练目标检测网络,复制一份 [PATH-TO-yolov5-v7]/data/coco128.yaml 并自定义命名,对于训练目标分割网络,复制一份 [PATH-TO- yolov5-v7]/data/coco128-seg.yaml 并自定义命名;修改`.yaml`文件内`path、train、val`,并根据`Yolo_categories.names`文件中的类别名称修改`names`,具体如下:
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: [PATH-TO-YOUR-DATA] # dataset root dir
train: images/train # train images (relative to 'path') 128 images
val: images/val # val images (relative to 'path') 128 images
test: # test images (optional)
# Classes
names:
0: person
1: car4、训练且标矩形框检测网络,执行以下命令:
cd [PATH-TO-yolov5-v7]
python3 train.py \
--weights weights/yolov5s6.pt \
-cfg models/hub/yolov5s6.yaml \
--data [PATH-TO-YOUR-yaml]\
--hyp data/hyps/hyp.scratch-med.yaml \
--epochs 50 \
--batch-size 8 \
--imgsz 12805、训练实例分割网络,执行以下命令:
cd [PATH-TO-yolov5-v7]
python3 segment/train.py \
--weights weights/yolov5s-seg.pt \
--cfg models/segment/yolov5s-seg.yaml \
--data [PATH-TO-YOUR-yaml]\
--hyp data/hyps/hyp.scratch-low.yaml \
--epochs 50 \
--batch-size 8 \6、关于4、5的参数说明如下:
[--weights:预训练的网络模型,用来初始化网络权重,可以从以下地址下载,下载后放到 [PATH-TO-yolov5-v7]/weights中
·https:/download.amovlab.com/model/yolov5-7/yolov5s.pt
·https:/download.amovlab.com/model/yolov5-7/yolov5s6.pt
·https:/download.amovlab.com/model/yolov5-7/yolov5s-seg.pt
[--cfg:定义网络结构,如models/yolov5s.yaml、models/hub/yolov5s6.yaml、models/segment/yolov5s-seg.yaml
·--data:训练数据描述文件,为刚刚自定义的.yaml 文件
[--hyp:训练网络的一些超参数设置
·--epochs:训练迭代次数
[--batch-size:批大小,每次训练输入至网络模型的图片数目
[-- iimgsz:训练时输入图片的尺寸,640或1280注意:
使用yolov5s.pt 或 yolov5-seg.pt 权重时,imgsz应为640;
使用yolov5s6.pt权重时, imgsz应为1280。
部署应用
训练平台.pt→.wts模型转换
1、在训练完成后
[PATH-TO-yolov5-v7]/runs/train 目录下为检测训练结果
[PATH-TO-yolov5-v7]/runs/train-seg 目录下为分割训练结果2、转换模型,运行如下代码(需要自行修改.pt 权重文件路径和生成 wts 文件的相应名称):
cd [PATH-TO-yolov5-v7]
python3 gen_wts.py -w runs/train/exp/weights/best.pt -o yolov5s.wts -t detect/seg注意:
检测模型选择'detect’,分类模型选择‘seg’。
实际运行平台.wts→.engine 模型转换
1、检测模型转换
在装好SpireCVSDK 的设备平台上运行(任意路径下):
SpireCVDet -s [PATH-TO-YOUR-WTS] [PATH-TO-YOUR-ENGINE] CLS_NUM s/s6其中:
[PATH-TO-YOUR-WTS] : 指上一步生成的.wts 文件路径
[PATH-TO-YOUR-ENGINE]: 指接下来要生成的.engine 文件路径
`CLS_NUM`:指目标类别数
`s`或`s6`:指不同网络模型注意:
1. `s`为640分辨率输入的网络,生成 engine 文件命名规则为DatasetName.engine;
2. `s6`为1280分辨率输入的网络,生成`engine`文件命名规则为DatasetName_HD.engine。
例如:
SpireCVDet -s yolov5s.wts COCo.engine 80 sSpireCVDet -s yolov5s6.wts COCO_HD.engine 80 s6
2、分割模型转换
在装好SpireCVSDK 的设备平台上运行(任意路径下):
SpireCVSeg -s [PATH-TO-YOUR-WTS] [PATH-TO-YOUR-ENGINE] CLS_NUM s其中:
[PATH-TO-YOUR-WTS]:指上一步生成的.wts 文件路径
[PATH-TO-YOUR-ENGINE]:指接下来要生成的.engine文件路径(需要以`_SEG`结尾)
CLS_NUM:指目标类别数
s:指不同网络模型(目前分割网络只支持640分辨率输入)例如:
SpireCVSeg -s yolov5s-seg.wts COCO_SEG.engine 80 s实际部署
按照SpireCVSDK的格式,通过上述过程我们得到了最终的`DatasetName.engine`、`DatasetName_HD.engine`、`DatasetName_SEG.engine`权重文件,将权重文件重命名并放置在`~/SpireCV/models`文件夹内。
针对自定义数据集,需要修改~/SpireCV/sv_algorithm_params.json文件,例如,自定义数据集名称为DatasetName , 该名称要与权重文件名 称对应。数据集中有两类目标,分别是person和car, 以下是参数修改示例:
注意:
当inputSize=640 且 withsegmentation=false 时,则运行 DatasetName.engine;
当inputSize=1280且withSegmentation=false时,则运行DatasetName_HD.engine;
当inputSize=640且withSegmentation=true时,则运行DatasetName_SEG.engine;
{
"CommonObjectDetector":{
"dataset" :"DatasetName",// 这里写哪个Dataset就执行相应的检测模型(如PersonVehicle, Drone, COCo, AnotherDatasetName)
"inputSize":640,
"nmsThrs":0.6,
"scoreThrs":0.4,
"useWidthorHeight":1,
"withSegmentation":false,
"datasetDatasetName":{
"person":[- 1,- 1],
"car":[- 1,- 1]
},
"datasetAnotherDatasetName":{
"another_category": [-1, -1]
},
"datasetPersonVehicle": {
"person":[0.5,1.8],
"car":[4. 1,1.5],
"bus":[10,3],
"truck":[- 1,- 1],
"bike":[- 1,- 1],
"train":[- 1,- 1],
"boat":[-1,-1],
"aeroplane":[-1,-1]
},
"datasetDrone":{
"drone":[0.4,0.2]
},
"datasetCOCO":{
"person":[-1,-1],
"bicycle":[-1,-1], }
}
}精度评估(以COCO数据集为例)
安装相关环境
1、C++环境:
本功能C++部分完全依赖于SpireCV的开发环境,如需安装 SpireCV (开源版),请参考“ SDK安装 ”,安装地址如下:
https://docs.amovlab.com/Spire_CV_Amov/#/src/%E5%BF%AB%E9%80%9F%E4%BD%BF%E7%94%A8/SDK%E5%AE%89%E8%A3%85/SDK%E5%AE%89%E8%A3%852、Python 环境:
#1.安装pip
#由于Ubuntu自带pip, 可以直接使用以下命令检查是否已经安装pip:
pip3 --version
#如果已经安装了pip, 则会显示当前pip的版本号,否则会提示未找到pip命令。
#如未安装pip, 则使用以下命令进行安装:
sudo apt-get install python3-pip
#安装完成后,再次使用以下命令检查pip是否已经安装成功:
pip3 --version
#2.使用pip安装Python 模块
#安装opencv-python
pip3 install opencv-python
#安装pycocotools
pip3 install pycocotools数据集准备
可使用下述链接,下载val2017数据集;请将val2017.zip 解压到当前文件夹下:
cd
wget https://download.amovlab.com/model/val2017.zip 安装相关环境
1、使用检测算法精度评价的具体细节可以参考以下2个部分:
通用目标检测类:sv::CommonObjectDetector-算法参数文件:~/ SpireCV/sy algorithm params,ison其中相关检测算法精度配置参数(sv_algorithm_params.json中),详细说明如下:
dataset: 数据集名称,代表使用该数据集训练的模型进行检测,本功能需将其改为"COCO";
scoreThrs:得分阈值,仅输出目标置信度大于该阈值的目标,本功能需将其改为"0.001";2、使用eval_mAP_on_coco_val.cpp文件对COCO模型进行检测。
#编译例程
cd
sudo make install
#运行检测算法精度检测(完成此步骤,大概需要30min)
./EvaLModelOnCocoVal 3、使用pd2coco_json.py文件将第二步中输出的结果转为COCO格式的json文件。
4、使用coco_eval.py文件对结果进行评估,并输出算法精度。
cd
#第三步:将预测结果转为COCO格式的json文件
python3 pd2coco_json.py
#第四步:对预测结果进行评估,并输出算法精度
python3 coco_eval.py 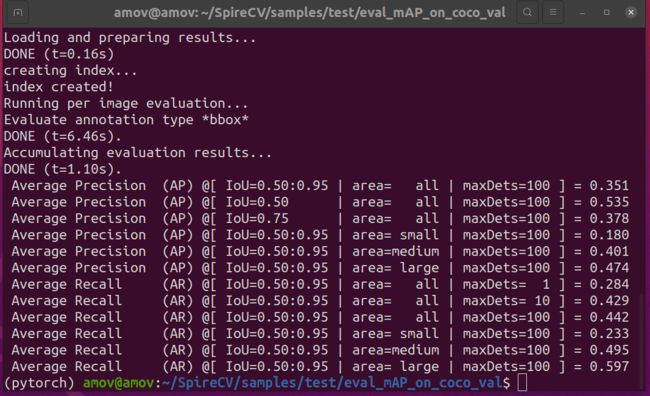
- End -
往期推荐:【全新开源项目】专为智能无人系统打造的边缘实时感知 SDK 库 SpireCV 正式上架