搞流式计算,大厂也没有什么神话
抖音、今日头条,是字节跳动旗下最受用户欢迎的两款产品,也是字节跳动的门面。而在这背后,是众多技术团队在支撑,流式计算就是其中一支。
不过,即使是在字节跳动,搞流式计算也没有神话。只有一群年轻人,花了六年时间,一步一个脚印,从一开始的“不懂技术不懂业务”,最后承载起了字节内部流式计算平台以及应用场景的构建,支撑了机器学习平台、推荐、数仓、搜索、广告、流媒体、安全和风控等众多核心业务。2022 年,该团队完成了对 Flink 计算引擎的云原生化改造,并通过火山引擎正式对外提供云上能力。
这不是一个挽狂澜于既倒的英雄故事,没有什么跌宕起伏的情节,也没有耀眼的鲜花与掌声。而是千千万万个普通开发者中的一小群人,一边在业务中被动接受成长,一边在开源中主动寻求突破的一段记录。
01 代码要写,业务也要拉
2019 年,随着抖音的爆发,字节跳动站在了高速增长的起点,直播、短视频,广告等业务也都乘势而起。这些业务,都需要流式计算来支撑。
字节流式计算团队负责人张光辉,正面临诸多棘手的问题。
先把时间线往前推两年,彼时张光辉刚加入字节跳动,计算引擎用的还是 Apache Storm——诞生于 2011 年的、Twitter 开发的第一代流处理系统,只支持一些 low level 的 API。
“所有的 Storm 任务都是在开发机上用脚本提交,运维平台处于非常原始的状态。如果 Storm 集群故障,作业都无法自动恢复,甚至无法找到所有存量作业。”张光辉对此记忆犹新。
话虽这么说,但谁也别嫌弃谁。那时张光辉的履历上,并没有流式计算产品的经验,不过有些“沾亲带故”——参与过流式计算的上下游产品开发,比如数据采集、消息队列。
好在趁着字节的业务场景偏单一,主要聚焦在机器学习场景,张光辉和其团队将流式计算引擎从 Apache Storm 切换到了 Apache Flink。所谓团队,其实连他在内,也仅有两人。之后又在 2018 年与数据流团队合作完成了流式计算平台化的构建,包括任务的监控、报警,日志采集,异常诊断等工具体系。
来到 2019 年,流式计算要支撑的业务场景已经相当丰富,扩展到了实时数仓、安全和风控等,并且还在不断增加。单个场景需求也变得更加复杂:推荐业务越来越大,单个作业超过 5 万 Cores;实时数仓业务场景需要 SQL 来开发,且对数据准确性有了更高要求。
然而,由于团队人手严重不足,工作进展很是缓慢。“只有两个人,Oncall 轮流值周。不用值周的时候,往往都在解决上一周 Oncall 遗留的问题。”张光辉如此形容。
张光辉不得不一边扩充人员,一边与数据集成团队着手构建 SQL 平台。李本超正是这个时候加入了流式计算团队,并且在不久之后,就成为了 Flink SQL 方向的技术负责人。
然而,用 SQL 来开发流式计算任务,李本超也没有太多经验:“一开始,技术也不懂,业务也不懂。”
在此之前,他在一家中小型企业任职,工作范围涉及广泛,流式计算只能算其中一个方向。加入字节后,李本超这才意识到,字节的流式计算规模远超自己的想象。之前只能看到 1 个并发的任务,而在字节,一个任务的并发却可以上万,仅单个任务使用的计算资源就比其上家公司所有任务加起来都多。
但李本超不能不懂。一周五天上班时间,其中有三天,张光辉早上第一件事情就逮着他问,跟哪个业务聊了,能新建几个 SQL 任务。
指标每天都在头顶打转,李本超不得不给团队“拉业务”。用的话术就跟在大街上拦住路人卖产品一样,只不过地点换成了字节在北京的各个工区。
“哎,这个流式计算我们可以通过 SQL 开发,你们感不感兴趣?想不想了解一下?”李本超没事就联系电商、直播、广告、游戏、教育等业务部门负责人。只要人家点头,李本超二话不说,马上坐班车跑去工区现场交流。
张光辉评价:“那个时候,真的是‘无所不用其极’。”
有了 SQL 平台,开发及维护效率飞速提升。“原来一个人开发一个任务,需要一两天。而现在,一个人一天直接就能搞定十个任务。此外,业务方与我们的沟通方式也更简单了,对方写的代码我们也都能看懂,优化起来很方便。”
除此之外,字节在 Flink 稳定性方面做了大量的工作,比如支持黑名单机制,单点故障恢复,Gang 调度,推测执行等功能。由于业务对数据的准确性要求更高了,团队支持作业开启 Checkpoint 机制来保证数据不丢失,并在字节得到了大面积的推广和落地。
在这个过程中,李本超也发现,Flink 可能没有想象得那么强大、易用,比如随便改一改 SQL 状态就没法兼容。针对这类尚未被社区解决的问题,字节内部也进行了大量的优化方案探索。
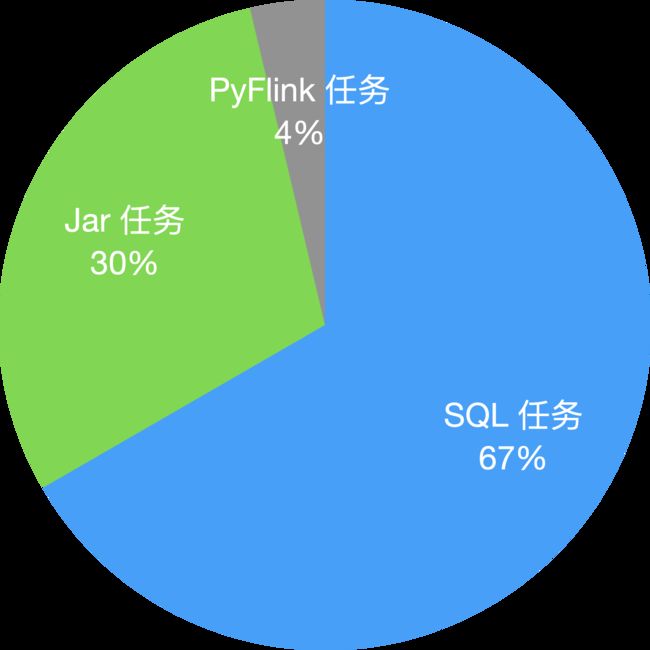
字节跳动 Flink SQL 任务占比
02 Flink,原来不止于流式计算
字节跳动选用 Flink 作为流式计算处理引擎后,每天有数万个 Flink 作业运行在内部集群上,峰值流量高达每秒 100 亿条数据。单个作业的规模也非常大,每个计算节点使用 3 万左右的并发,整个作业使用 300 多台物理机。Flink 集群的稳定性和性能优化,以及单个超大作业的部署、执行和 Failover 等优化,面临的问题在整个业界都难觅第二。
由于 Flink 是一个流批一体计算引擎,字节跳动内部也在积极推动 Flink 流批一体落地,上线了 2 万多个 Flink 批式作业,在这个过程中解决了很多稳定性和性能问题,比如 Hive 语法兼容、慢节点、推测执行等。
同时,字节跳动内部启动了 ByteHTAP 项目,结合字节内部的 OLTP 系统,已经能够支持数据延时低(亚秒级)、数据一致性要求高的分析型计算,但还缺一个计算引擎来支持 OLAP 计算。由于字节在 Flink 做了大量的深入优化,最终将其作为 ByteHTAP 的 OLAP 引擎。

然而,在 ByteHTAP 开始给业务方提供线上 OLAP 服务时,新的问题又出现了。业务方不仅对单并发查询的 latency (延迟)有要求,还希望团队提供的 OLAP 服务能够支持高并发度。
正值 2021 年年初,方勇加入了字节跳动,担任流式计算架构师。为了支撑线上业务,方勇和团队要尽快把这块的能力给补齐。
“整个开发过程非常煎熬,压力非常大。”方勇说:”ByteHTAP 已经提供了线上服务,我们需要快速迭代,使 Flink 支持更高的并发查询。”
每次团队开周会,方勇都会盯着 QPS 指标。用了近半年的时间,“总算把 QPS 从个位数优化到十几、几十,直到线上单集群支持几百 QPS”。
近两年,字节正在将 Flink OLAP 诸多优化贡献回社区。 Flink OLAP 的相关内容也加入了到了Apache Flink 2. 0 的 Roadmap 中。
一条完整的数据生产链路,分为三个计算场景,分别是流式、批式和 OLAP 计算。在实时数仓场景,需要 Storm 或 Flink 来支撑流式计算;在批式场景,则要依靠 Hive 或 Spark。当计算语义不一样时,两套引擎会导致流式结果和批式结果不一致。而且,流批一体数据计算完成之后,还需导入数仓或者离线存储,此时还要引入一套新的 OLAP 引擎去探查、分析,这就更加无法保证正确性和一致性。
而且,优化及维护也颇为麻烦。三套系统就意味着,要建三个团队去分别维护。一旦遇到需要优化或者解决 bug 等情况,还要分别到三个社区提 issue 讨论。
Flink 社区提出了 Streaming Warehouse 解决这个问题,字节调研了目前流式计算发展方向和 Streaming Warehouse 系统,基于 Flink 和 Paimon 构建了 Streaming Warehouse 系统,分别统一流批一体的计算和存储,增加了作业和数据血缘管理、数据一致性管理、流式数据订正和回溯等核心功能,解决流式计算的准确性和数据运维等问题。
最终,“三套引擎,三个团队”变成“一套引擎,一个团队”。用方勇的话来说,使用 Flink 作为整个数据生产链路统一的流式、批式和 OLAP 一体的计算引擎,已经完全就不用担心数据的实时性、业务分析的复杂性。
至于 Flink 的未来,方勇已经有了设想。他希望能够集合社区的研发能力,一起完善整个 Flink 的计算生态,将 Flink 打造成统一流、批和 OLAP 的 Streaming Warehouse 系统。
03 新业务,新场景,新挑战
2022 年,字节流式计算团队支撑研发的计算引擎商业化产品“流式计算 Flink 版”上线火山引擎,正式对外提供云上计算能力,而不是仅仅服务于字节内部业务。
在字节,这款产品被称为“Serverless Flink”。Serverless Flink 依托于字节跳动在业内最大规模实时计算集群实践,基于火山引擎容器服务(VKE/VCI),提供 Serverless 极致弹性,是开箱即用的新一代云原生全托管实时计算平台。
事实上,将 Serverless Flink 称之为一款新上线的产品可能并不合适。李本超解释,所谓“流式计算 flink 版”,其实就是团队在六年时间里,让 Apache Flink 在字节内部实现了大规模应用,并把积累的大量的产品经验和技术能力“包装”了一下,而不是重新做了一个产品。
它是基于 Apache Flink 衍生出来的,可以理解为 Apache Flink 增强版,并且 100% 兼容 Apache Flink,包含诸多特性:
-
开发效率提升。 流式计算 Flink 版支持算子级别 Debug 输出、Queryable State、Temporal Table Function DDL,在开发效率上对开源版本 Flink 有显著提升。
-
可靠性提升。 流式计算 Flink 版针对单个 Task 进行 Checkpoint,提高了大并发下的 Checkpoint 成功率。单点任务恢复和节点黑名单机制功能,保障了对故障节点的快速响应,避免业务整体重启。
-
Serverless 云原生架构。 极致弹性,1‰ 核精细调度。
-
易用性增强。 极简 SQL 开发,开箱即用、免运维、支持流式数据全生命周期管理。
-
高性能低价格。 高性价比、高 SLA 保证、超低 TCO。
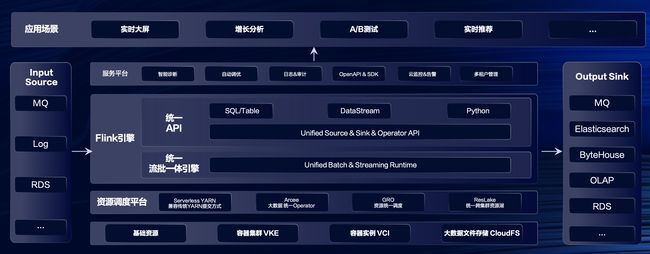
流式计算Flink版 架构图
在 Serverless Flink 上线火山引擎之后,方勇发现,外部客户需求与内部业务需求很是不同。比如有的客户还在使用 Storm、Samza 等相对较为早期的流式技术栈。因此,团队不仅要对客户进行技术培训和技术支持,还要帮助技术支持人员理解客户的作业逻辑,以更好地服务其业务。
这意味着,流式计算团队面临的是新的场景与挑战,有时甚至要从零开始构建一个新的系统。
不过,一切工作都在有条不紊地展开。近两年,团队成员已经扩展到 30 人,并对 Serverless Flink 在调度、运行时、SQL 等各个方面都进行了全方面的优化,极大提升性能。
此外,基于 Apache Flink 及 Apache Paimon,团队在 Streaming Warehouse 实时数仓场景也有了新的突破,实现了支持数据的一致性、血缘,以及数据回溯等实时数仓的产品能力。
截止目前,基于流式计算 Flink 构建的实时业务场景已经涉及到字节几乎所有的业务和产品,包括实时数仓、实时风控、商业化、电商、游戏、小说、教育、房产、财经等,日常实时峰值超 100 亿 QPS。与此同时,流批一体在特征工程,数据同步,计数服务,电商等场景均得到了广泛的使用和落地,已上线将近 2万 Flink Batch SQL 任务。
此刻,张光辉才终于敢说:“ 经历了从 0 到 1 的过程之后,今天字节的流式计算平台,已经可以打 8 分了。”
方勇提到,未来,团队将在可用性、稳定性、性能等方面持续优化流式计算平台,并继续深入 Flink OLAP 生产实践,建设和完善稳定性和可用性等周边系统,比如 Debug 能力、 Auto Scaling 系统。
除了流式计算之外,团队在 Flink 批式方面也做了很多的优化和尝试, 比如兼容 Hive SQL 语法等。同时,一些超大规模的作业,也在往 Flink 批式方向上去尝试。在 Flink 批式场景积累经验之后,团队将会持续推动 Flink 流批一体的应用和实践,同时结合社区需求,贡献一些新的能力。
Native Engine 也将成为团队探索的一大方向。Flink 以 Java 语言为主,部分技术涉及行式计算,导致它并不能很好地利用 CPU,以及更新迭代的一些新功能。而如何利用 Native Engine提升性能及运算能力,降低成本,是大势所趋。
04 开源是一件自然而然的事
从服务内部业务到服务外部客户,字节对 Apache Flink 的应用愈加深入。当然,字节之于 Apache Flink,并非只停留在“用”的层面,而是源源不断地将其创新成果贡献到开源社区中,更是成为了研发 Flink OLAP 等方向的主要牵头企业。在众多为 Flink 社区贡献的国内企业中,字节参与度能排到第二。
除了 Apache Flink,流式计算团队还为 Apache Calcite 、Apache Paimon 这两个项目做出了不小的贡献,并在社区构建了一定的影响力。
Apache Calcite 是一个动态的数据管理框架,它可以实现 SQL 的解析、验证、优化和执行。当前,字节是该项目核心贡献公司之一,参与 plan 优化、方言生态增强、运行时优化等工作。Apache Paimon (incubating) 则是一项流式数据湖存储技术,可以为用户提供高吞吐、低延迟的数据摄入、流式订阅以及实时查询能力。字节是该项目的创始贡献公司之一。
截至目前,字节流式计算团队培养了包括李本超、方勇等在内共 8 名 Apache 项目 committer,为 Flink 社区贡献了 174 个 commits,为 Calcite 社区贡献了 47 个 commits,以及为 Paimon 社区贡献了 107 个 commits。
虽说开源成果丰硕,但在流式计算团队,并没有安排专门的人去贡献开源。于他们而言,开源是一个自然而然的过程。
“我们用开源的组件来搭建产品,鼓励组员在日常开发过程中,将新增的功能特性、bug 修复以及一些优化,贡献到社区。这就是我们日常的工作模式。希望大家在社区交流中,可以提升代码质量以及保持对技术的探索。”张光辉补充说:“当然,最开始,也没有什么开源的氛围,每个人都忙着业务。不过,李本超和方勇这两个开源积极分子起了带头作用,其他团队成员在其影响下,也逐渐接触开源。”
李本超也提到,社区和公司之间没有明显界限。“上游项目 Apache Flink 跟我们的 Serverless Flink 其实是一个项目,只不过我们在用 Serverless Flink 来支撑一个更具体的公司业务场景。公司非常鼓励我们把成果贡献给社区。但如果内部需求更着急,或者说很难有一个非常快速且完整通用的方案,就会在内部先上线试用。”
团队也不强制要求研发人员一定要参加社区。
“参与开源是一件比较偏个人的事情,看他自己个人兴趣,以及对职业生涯、技术方面的规划。不过为了保证内外系统的一致性,以及我们系统后续发展的兼容性,增进研发同学之间的技术交流及合作,我们非常鼓励大家把遇到的问题提交到社区。有一些需要内部讨论或支持方案,如果刚好也是外部开源社区所需要的,我们都会考虑把这些需求引进到内部。这样可以做到内部统一开发,然后统一推进。”方勇解释。
05 要贡献开源,其实并不容易
如李本超所言,所有有利于社区变的更好的事情,都是一种贡献,比如用户问答、代码 review、文档的维护、不稳定测试的修复、build 系统的提升、技术讨论、release 等等。
但对于从未参与过开源的人来说,开始可能是最困难的一步。
“在 Apache Calcite 、Apache Flink 以及 Apache Paimon 等社区,开发者非常活跃,很多人提 issue 都会得到解答。但没参与之前,去哪里去找 issue,怎么写代码,怎么提 PR,怎么新建 feature,整个流程完全是陌生的。这个过程其实听起来比较简单,但真正去实践的时候,发现它还是有一定门槛。”方勇提到。
即使已经有了一些重大的开发成果,要贡献给社区,也并不是简单地把代码从内部拿到外部。
一些针对专项业务定制化开发的功能,在开源社区可能会被认为不够通用。李本超说,一些新开发的功能特性,即使已经在业务上验证过,但在回馈开源社区时,往往需要重新思考和设计,使其在满足业务诉求的基础上,又能抽象出更通用的能力。
当然,对李本超和方勇而言,字节业务的优先级自然是更高的,技术架构的普适性、能力的通用性方面的优先级稍微低一点。但在面对业务和社区共同的需求时,他们还是尽可能做到同时兼顾。也许最后开发出来的解决方案并不是最完美的,但已经能解决 80% 的问题。
再进一步,如果已经抽象出一些功能特性,想把代码贡献到社区,也不代表这个过程会很顺利。由于社区对核心组件的代码要求比较高,在代码被合并之前,包括 API 设计、PR 合理性等在内的各方面问题,都需要经过社区讨论。
方勇曾向 Flink 提了一个PR :在 job manager 节点进行内存优化。 一位德国的项目成员 review 代码后,认为原理上可以。但他还问了几个问题:为什么要提交这个 PR,你们遇到了什么问题,为什么要采用这种方式修复它? 因为 Flink JVM 的 Java 代码从实现上来看,并没有内存问题。
由于该部分涉及到 JVM 层的 classloader 和 full GC 优化,在此之前,方勇就曾与 JVM 系统组有过深入研究探讨。他们发现,JVM 不仅有 Java 代码实现, 还有 C++ 代码实现,而 C++ 实现的代码如果有一些复用情况,会出现内存泄露,导致 job manager 节点的 full GC 变多,处理性能下降。当方勇把这一分析过程以及 Benchmark 测试贴到社区后,最终获得了认可。PR 也很快就被合并了。
此外,贡献开源还要从代码架构的角度来思考,是否与现有系统兼容。李本超说,要获得业务部门的认可,要求开发人员对业务有深入的理解,帮助业务部门解决问题,达到预期收益就可以。但在开源社区,想要贡献代码,不仅要考虑事件本身的合理性,还要考虑其通用性是否够强,是否会跟已有功能冲突,未来怎么维护,如何演进等等。
方勇就曾遇到过一个案例。一个容灾体系,要先靠外部的数据流生成容灾 ID,Flink 再通过该 ID 实现整个作业容灾。社区为了支持这一功能,做了特定的 API 的开发。方勇在将部分功能代码提交到仓库时,就要考虑是否兼容特定的 API 。“不能让这个 API 受到干扰,否则 Flink 用户升级版本之后,原先功能就运行不起来了。这对 Flink 的稳定性以及后续发展都是不利的。”
06 加入 PMC/PPMC,责任更大了
今年,李本超、方勇先后分别成为了 Apache Calcite、Apache Paimon(incubating)的 PMC member(项目管理委员会成员)、PPMC member(孵化器项目管理委员会成员)。
这意味着,二人为开源社区做出的贡献,得到了认可。这并不容易。在社区想要获得认可,不仅仅只看代码,还要看技术能力、沟通能力、持续贡献的意愿,以及行为是否符合社区文化(比如 Apache 之道)。如何在日常参与社区事务的过程中,将能力和素质展现出来,是很有挑战性的。
李本超有一次印象深刻的经历。在 Apache Calcite 社区,他从创建 issue,讨论 issue,写代码,提交 PR ,到最终合入代码,前后一共用了五个月的时间。
“不是说这个 issue 复杂到需要五个月,也不是说这五个月只做这一件事。社区成员都是异步沟通,大部分人都在利用业余时间来讨论问题和贡献代码。加上社区对代码质量要求高,项目本身很复杂,在讨论过程中,经常会产生不同的想法和建议。”这个过程对李本超来说,还是挺煎熬的。
“因为实现方案可能会换好几次,不同方案要写不同的代码。最后讨论来讨论去,可能还是原来的好,又要在原来的基础上再改。反反复复。最终代码量也没多大。”他补充说:“但这个过程能够很好地展现出个人素质和能力。”
具备耐心,并且长期坚持,在开源社区是很必要的。方勇认为,成为 PPMC 需要持续关注和投入,保持在自己在社区的活跃度。“持续关注新的 issue,把自己的工作整理出来,再去社区提 issue,然后在社区发起讨论,一起评估方案。最终把任务分解后,再开发代码,再把它合进去,花费的时间周期可能会非常长。在 Flink 社区,如果要合入一些对公共 API 有修改的代码,从设计讨论,到投票,再到开发以及推进,整个过程至少需要 3 个月。”
对李本超来说,成为 Apache Calcite 的 PMC member 就意味着肩负了起更大的责任。“我在社区没有任何角色的时候,只关心是不是把问题解决了。而且社区里一定会有更资深的人去帮我去确认代码有没有问题,有人在后背托着我。”
现在,他的身份变了,不再只是贡献代码,而是辅助他人贡献。“我就是把好最后那道关的那个人,压力和责任更大了。心里会想着,这个东西我一定得想清楚,一定得为了社区健康、长远的发展去思考,而不只是把代码快速合入,把问题快速地解决掉。总之,更小心,更谨慎,思考维度也更多了。”
李本超还需要承担很多非代码的工作,比如代表社区跟 Apache 软件基金会的基础设施团队讨论社区机制、流程等问题,让新加入的开发者在为项目做贡献的时候,更容易、更方便。“很多时候,付出就不只是单纯贡献的维度了。投入到社区,需要自己有很大的兴趣和足够的精力。”
同样深感责任重大的,还有方勇。他见到过一些开源社区,在成员慢慢变少后,不再活跃,对项目造成了严重打击。每年都有很多新的项目开源,也有很多老的开源项目死掉。
“既然给了 PPMC 这么大的权限,作为成员之一,我对整个项目的发展方向就要有更多的考量。 PPMC 最主要的责任,就是对开源项目的把控,包括方向的抉择、重大 feature 的演进。”
不同公司及团队源源不断地加入社区,会贡献很多新的功能,有些甚至能够拿来就用,无需重新开发,在加快项目和社区发展的同时,也在帮助字节完善其内部相关系统功能。当然,字节在将项目用于实际生产业务中时,也会为项目开发很多新的功能特性,并且经过了大量场景的验证和锤炼。因此,在规划项目演进方向时,方勇除了考量外部需求以及其他 PPMC 的提议,会更加主动地去展现公司内部开发的功能,这样既可以让内外系统保持一致,也能推动项目更好地往前走。
07 有了开源社区,好像有了靠山
大部分人对开源的认知,都发端于使用开源项目。“但如果只是使用一个开源软件,对社区的感知几乎是没有的。”张光辉虽然并未获得 Apache Flink 的 committer 或 PMC member 的身份,但他和很多人一样,也在为项目贡献着自己的力量。
“以前觉得开源离我们很远。尤其是在中国,这种感受更加明显。但是在参与 Apache Flink 社区以及线下大会之后,跟开发者有了交流和接触,自然而然就产生了情感上的链接,促使你主动回馈,促使你去成长。”张光辉自己也是从开源社区中成长起来的。此前在将流式计算引擎迁移到 Flink 时,张光辉就曾遇到过不少问题,经常会跟阿里、美团等公司的开发者在 Apache Flink 社区中讨论。
开源给李本超带来了很强的踏实感。“我和这个领域最优秀的一群人站在了一起。有什么问题一起讨论,一起解决,好像多了一个非常强大的虚拟团队,即使是在处理内部业务的时候,也感觉自己有靠山了。社区里边有很多写代码超过 30 年的资深专家,不管是在技术领域,还是非技术领域,我都能从他们身上学到很多。”
在 Flink 社区,很多用户都会在邮件组提一些涉及使用、调优等方面的问题。也许问题本身并不复杂,但因为 Flink 系统很复杂,对初学者而言,门槛还是有点高。
同样经历过新手期的方勇,很能理解这种情况。“有时候,对方邮件提到的 bug 或者 issue,我们没有遇到过,但我们仍然会去研究了相关的代码,帮他解答,甚至直接提交代码。问题解决之后,我经常会收到感谢邮件,这时候就觉得付出有回报,非常有成就感。”
参与社区之后,方勇与开源社区成员见面的机会也更多了,经常与其深入交流项目演进、技术发展、行业趋势等各方面的想法,同时也在促进各开源项目、社区之间的结合。现在,他正琢磨着,怎么把 Apache Flink 和 Apache Paimon 更好地结合,做下一代流式计算解决方案。