redis源码剖析 | 跳表与压缩列表剖析
压缩列表,跳表的特点
a:压缩列表类似于一个数组,不同的是:压缩列表在表头有三个字段zlbytes,zltail和zllen分别表示长度,列表尾的偏移量和列表中的entry的个数,压缩列表尾部还有一个zlend,表示列表结束

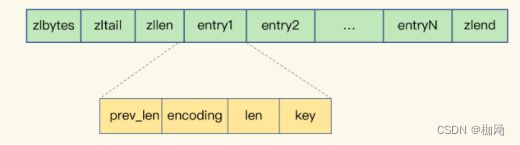
- prev_len,表示前一个 entry 的长度。prev_len 有两种取值情况:1 字节或 5 字节。取值 1 字节时,表示上一个 entry 的长度小于 254 字节。虽然 1 字节的值能表示的数值范围是 0 到 255,但是压缩列表中 zlend 的取值默认是 255,因此,就默认用 255 表示整个压缩列表的结束,其他表示长度的地方就不能再用 255 这个值了。所以,当上一个 entry 长度小于 254 字节时,prev_len 取值为 1 字节,否则,就取值为 5 字节。
- len:表示自身长度,4 字节;
- encoding:表示编码方式,1 字节;
- content:保存实际数据。
b:跳表:是在链表的基础上增加了多级索引,通过索引的几次跳转,实现数据快速定位,跳表的查找复杂度就是 O(logN)。
跳表其实是一种多层的有序链表

跳表节点的数据结构:

Sorted Set 中既要保存元素,也要保存元素的权重,所以对应到跳表结点的结构定义中,就对应了 sds 类型的变量 ele,以及 double 类型的变量 score。此外,为了便于从跳表的尾结点进行倒序查找,每个跳表结点中还保存了一个后向指针。
因为跳表是一个多层的有序链表,每一层也是由多个结点通过指针连接起来的。因此在跳表结点的结构定义中,还包含了一个 zskiplistLevel 结构体类型的 level 数组。
level 数组中的每一个元素对应了一个 zskiplistLevel 结构体,对应了跳表的一层。
zskiplistLevel 结构体定义了一个指向下一结点的前向指针(*forward),这就使得结点可以在某一层上和后续结点连接起来。同时,zskiplistLevel 结构体中还定义了跨度span,这是用来记录结点在某一层上的*forward指针和该指针指向的结点之间,跨越了 level0 上的几个结点。
跳表的结构:

定义了跳表的头结点和尾结点、跳表的长度,以及跳表的最大层数
- 跳表结点查询
跳表会先从头结点的最高层开始,查找下一个结点。而由于跳表结点同时保存了元素和权重,所以跳表在比较结点时,相应地有两个判断条件:
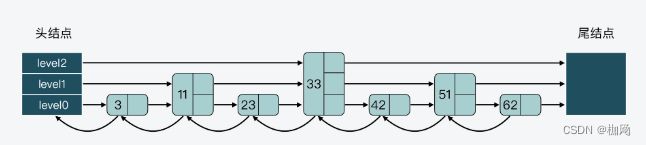
- 当查找到的结点保存的元素权重,比要查找的权重小时,跳表就会继续访问该层上的下一个结点。
- 当查找到的结点保存的元素权重,等于要查找的权重时,跳表会再检查该结点保存的 SDS 类型数据,是否比要查找的 SDS 数据小。如果结点数据小于要查找的数据时,跳表仍然会继续访问该层上的下一个结点。
- 当上述两个条件都不满足时,跳表就会用到当前查找到的结点的 level 数组了。跳表会使用当前结点 level 数组里的下一层指针,然后沿着下一层指针继续查找,这就相当于跳到了下一层接着查找。
- 跳表结点层数设置
随机生成每个结点的层数。
相邻两层链表上的结点数并不需要维持在严格的 2:1 关系。这样一来,当新插入一个结点时,只需要修改前后结点的指针,而其他结点的层数就不需要随之改变了,这就降低了插入操作的复杂度
在 Redis 源码中,跳表结点层数是由 zslRandomLevel 函数决定。zslRandomLevel 函数会把层数初始化为 1,这也是结点的最小层数。然后,该函数会生成随机数,如果随机数的值小于 ZSKIPLIST_P(指跳表结点增加层数的概率,值为 0.25),那么层数就增加 1 层。因为随机数取值到[0,0.25) 范围内的概率不超过 25%,所以这也就表明了,每增加一层的概率不超过 25%。下面的代码展示了 zslRandomLevel 函数的执行逻辑

- 哈希表和跳表的组合使用
当创建一个 zset 时,代码中会相继调用 dictCreate 函数创建 zset 中的哈希表,以及调用 zslCreate 函数创建跳表。

Sorted Set 中同时有了这两个索引结构,想组合使用它们,就需要保持这两个索引结构中的数据一致。
Zsetadd:
比如,当往 Sorted Set 中插入数据时,zsetAdd 函数就会被调用。
zsetAdd 函数会判定 Sorted Set 采用的是 ziplist 还是 skiplist 的编码方式。
zsetAdd 函数会先使用哈希表的 dictFind 函数,查找要插入的元素是否存在。
如果不存在,就直接调用跳表元素插入函数 zslInsert 和哈希表元素插入函数 dictAdd,将新元素分别插入到跳表和哈希表中。(Redis 并没有把哈希表的操作嵌入到跳表本身的操作函数中,而是在 zsetAdd 函数中依次执行以上两个函数。这样设计的好处是保持了跳表和哈希表两者操作的独立性。)
如果元素已经存在,那么 zsetAdd 函数会判断是否要增加元素的权重值。如果权重值发生了变化,zsetAdd 函数就会调用 zslUpdateScore 函数,更新跳表中的元素权重值。紧接着,zsetAdd 函数会把哈希表中该元素(对应哈希表中的 key)的 value 指向跳表结点中的权重值。这样一来,哈希表中元素的权重值就可以保持最新值了。
总结::
Sorted Set 数据类型的底层实现。Sorted Set 为了能同时支持按照权重的范围查询,以及针对元素权重的单点查询,在底层数据结构上设计了组合使用跳表和哈希表的方法。
跳表是一个多层的有序链表,在跳表中进行查询操作时,查询代码可以从最高层开始查询。层数越高,结点数越少,同时高层结点的跨度会比较大。因此,在高层查询结点时,查询一个结点可能就已经查到了链表的中间位置了。
这样一来,跳表就会先查高层,如果高层直接查到了等于待查元素的结点,那么就可以直接返回。如果查到第一个大于待查元素的结点后,就转向下一层查询。下层上的结点数多于上层,所以这样可以在更多的结点中进一步查找待查元素是否存在。
跳表的这种设计方法就可以节省查询开销,同时,跳表设计采用随机的方法来确定每个结点的层数,这样就可以避免新增结点时,引起结点连锁更新问题。
此外,Sorted Set 中还将元素保存在了哈希表中,作为哈希表的 key,同时将 value 指向元素在跳表中的权重。使用了哈希表后,Sorted Set 可以通过哈希计算直接查找到某个元素及其权重值,相较于通过跳表查找单个元素,使用哈希表就有效提升了查询效率。
总结2:
1、ZSet 当数据比较少时,采用 ziplist 存储,每个 member/score 元素紧凑排列,节省内存
2、当数据超过阈值(zset-max-ziplist-entries、zset-max-ziplist-value)后,转为 hashtable + skiplist 存储,降低查询的时间复杂度
3、hashtable 存储 member->score 的关系,所以 ZSCORE 的时间复杂度为 O(1)
4、skiplist 是一个「有序链表 + 多层索引」的结构,把查询元素的复杂度降到了 O(logN),服务于 ZRANGE/ZREVRANGE 这类命令
5、skiplist 的多层索引,采用「随机」的方式来构建,也就是说每次添加一个元素进来,要不要对这个元素建立「多层索引」?建立「几层索引」?都要通过「随机数」的方式来决定
6、每次随机一个 0-1 之间的数,如果这个数小于 0.25(25% 概率),那就给这个元素加一层指针,持续随机直到大于 0.25 结束,最终确定这个元素的层数(层数越高,概率越低,且限制最多 64 层,详见 t_zset.c 的 zslRandomLevel 函数)
7、这个预设「概率」决定了一个跳表的内存占用和查询复杂度:概率设置越低,层数越少,元素指针越少,内存占用也就越少,但查询复杂会变高,反之亦然。这也是 skiplist 的一大特点,可通过控制概率,进而控制内存和查询效率
8、skiplist 新插入一个节点,只需修改这一层前后节点的指针,不影响其它节点的层数,降低了操作复杂度(相比平衡二叉树的再平衡,skiplist 插入性能更优)
关于 Redis 的 ZSet 为什么用 skiplist 而不用平衡二叉树实现的问题,原因是:
- skiplist 更省内存:25% 概率的随机层数,可通过公式计算出 skiplist 平均每个节点的指针数是 1.33 个,平衡二叉树每个节点指针是 2 个(左右子树)
- skiplist 遍历更友好:skiplist 找到大于目标元素后,向后遍历链表即可,平衡树需要通过中序遍历方式来完成,实现也略复杂
- skiplist 更易实现和维护:扩展 skiplist 只需要改少量代码即可完成,平衡树维护起来较复杂