一文速览ICML 2023大模型和鲁棒性相关论文

本文大致总结了 ICML 2023 中与鲁棒性,连续学习,大规模语言/视觉模型相关的 Oral 文章。
01
/ ICML 2023 OralPoster /
论文标题:
The Price of Differential Privacy under Continual Observation
论文链接:
https://openreview.net/pdf?id=yPUc796tVF

背景:差分私有(DP)数据分析研究了算法的设计,这些算法可以发布关于输入数据集的汇总统计数据,同时保护数据集所包含的个人的隐私。然而,许多差分隐私的部署是在批处理模型中操作的:也就是说,它们一次性收集所有输入并产生单个输出。在许多情况下,敏感数据是随着时间的推移而收集的,发布的模型和统计数据需要定期更新。例如,COVID-19 仪表板可以显示有关 COVID 病例和死亡数量的统计数据、广告活动分析数据、推荐系统和预测性语言模型。研究人员提出了连续发布模型(continual release model)的概念,该模型接收一个敏感数据集作为输入流(长度为 的输入流),直观地说,全部 个时刻输出的整个向量满足微分隐私,那么算法才是满足 DP 的。
因此本文的一个核心贡献在于去从理论上回答,DP 算法在连续发布模型而不是批处理模型中解决问题必须付出什么样的精度代价。
1. 首次对连续发布机制的误差进行了较强的下界证明。通过研究两个与经验风险最小化密切相关且在标准批处理模型中被广泛研究和使用的基本问题,证明了每个连续发布算法的最坏情况误差比最佳批处理算法的误差大了Ω()倍。这一结果填补了先前研究在这两个模型中最坏情况误差可达性之间仅有的约为 Ω(logT)的差距。
2. 提出了适应性选择输入的模型。具体而言,这是形式化了一个更现实的模型,该模型允许对手通过观察连续释放算法的输出来在线选择输入流元素。这个模型给出了一个更真实的现实环境的表示,其中数据可能会根据算法的先前反馈而改变。例如,一个城市可能会根据对 COVID 病例的 DP 估计来调整其社交距离政策,这可能会反过来影响新病例的数量。新模型融入了用户的 feedback,尽管在这个模型中隐私和准确性一般较难获得,但研究人员证明了下界结果与对适应性选择输入有效的简单算法的误差相匹配。
3. 对 MaxSum 和 SumSelect 两个问题在连续发布模型中的误差进行了严格的界限分析。MaxSum 问题是在每个输入由二进制属性组成的情况下,近似计算属性和的最大值,每个时间步长的误差是该时间步长的真实答案与模型输出之间差的绝对值。SumSelect 问题是 MaxSum 问题的“argmax”版本,即找到属性和最大的索引。研究人员给出了在连续发布模型中解决这两个问题的误差的紧密界限,该界限与流长度(或“时间跨度”)T、属性数量 d 和隐私参数 ε 有关。
02
/ ICML 2023 OralPoster /
论文标题:
Scaling Vision Transformers to 22 Billion Parameters
论文链接:
https://openreview.net/pdf?id=Lhyy8H75KA

Transformers 的缩放为语言模型带来了突破性的功能。目前,最大的大型语言模型(LLMS)包含 100b 以上参数。Vision Transformers(VIT)将相同的架构引入了图像和视频建模,但这些架构尚未成功地缩放到几乎相同的程度。最大的密集 VIT 包含 4B 参数。本文提出了一种对 22B 参数 VIT(VIT-22B)高效且稳定的培训的配方,并在所得模型上进行了多种实验。当对下游任务进行评估(通常具有在冷冻特征上的轻量级线性模型)时,VIT-22B 表现出随着尺度的表现提高的性能。本文进一步观察到了规模的其他有趣的好处,包括在公平和表现之间取得改善的权衡,在形状/纹理偏见方面与人类视觉感知的最新一致性以及改善的鲁棒性。VIT-22B 展示了视觉中“类似 LLM 的”缩放的潜力,并为到达那里提供了关键步骤。
核心贡献:
1. 提出了 ViT-22B 模型:ViT-22B 是目前参数规模最大的视觉 Transformer 模型,具有 220 亿个参数。揭示了训练中的病态训练不稳定性(Self-Attention层里的 query 和 key 如果不做 normalization,会导致梯度不稳定),阻碍了默认 transformer 的扩展,并展示了能够实现扩展的架构改进。通过对原始架构进行小而关键的修改,包括并行层、查询/键(QK)归一化和省略偏置等三个主要改进,提高了效率和训练稳定性,实现了出色的硬件利用和训练稳定性,推动了多个基准任务的最新成果。
2. 通过综合的评估方式对 ViT-22B 的质量进行了评估,涵盖了从(少样本)分类到密集输出任务的各种任务,其中在 ImageNet 上达到或超越了当前最先进的结果。即使作为冻结的视觉特征提取器,ViT-22B 在 ImageNet 上实现了 89.5% 的准确率。
3. 使用与视觉特征相匹配的文本对进行训练,在零样本设置下,ViT-22B 在 ImageNet 上实现了 85.9% 的准确率。
4. ViT-22B 作为蒸馏目标用于训练 ViT-B 学生模型可以在 ImageNet 上实现了 88.6% 的准确率,达到了该规模下的最先进水平。
5. ViT-22B 在分布外行为、可靠性、不确定性估计和公平性权衡方面具有改进。而且 ViT-22B 模型在准确性和校准性之间取得了良好的平衡,能够更准确地估计其预测的可靠性。
6. 该模型的特征与人类感知更好地一致,达到了先前未见的87%的形状偏差。
7. 通过优化训练基础设施和使用异步并行线性操作等技术,实现了 ViT-22B 在 TPUv4 上高效的模型并行训练,每秒处理 1.15k 个 token。
03
/ ICML 2023 OralPoster /
论文标题:
Specializing Smaller Language Models towards Multi-Step Reasoning
论文链接:
https://openreview.net/forum?id=MXuLl38AEm

大型语言模型(LLM)在复杂推理上表现出色的惊人能力仅在很大的大规模模型中才能出现。本文表明,实际上可以将这种能力从 GPT-3.5(≥175b)蒸馏到 T5 变体(≤11b)。所以本文建议模型专业化(Specializing),以专门提高模型的目标任务能力。本文的假设是,大模型(通常被视为大于100b)具有强大的建模能力,因此它们可以执行大量的任务。小模型(通常被视为小于 10b)的模型容量有限,但是如果我们专门针对目标任务的能力,该模型可以实现不错的性能改进。本文使用多步数学推理(multi-step math reasoning )作为测试任务,因为它是非常典型的新兴能力。
我们展示了模型能力的两个重要方面:(1)平衡语言模型在多个任务上的表现是一个棘手的问题,因为一项任务的改进可能会损害其他任务;(2)通过降低大模型的全面性,我们可以清楚地在小于 10B 的不同模型量上专门改善多步数学推理能力。本文进一步就重要的设计选择进行了全面的讨论,以进行更好的概括,包括数据格式的混合和模型 checkpoint 的起始点选择。本文的实践和发现也许可以算是 LLMS 设定的新研究范式中专业小模型的重要尝试。

04
/ ICML 2023 OralPoster /
论文标题:
Pretraining Language Models with Human Preferences
论文链接:
https://openreview.net/forum?id=AT8Iw8KOeC

语言模型(LM)经过预训练,可以从大型多样的数据集中模仿文本,这些数据集中的内容如果由语言模型生成,则会违反人类的偏好:谎言、攻击性评论、个人可识别信息、低质量或有 bug 的代码等。本文探讨了预训练语言模型的其他目标,同时指导它们生成与人类偏好一致的文本。用人工反馈进行预训练,比标准的语言模型预训练,然后用反馈进行微调,即学习然后取消不需要的行为,产生了更好的偏好满意度。结果表明,在对语言模型进行预训练时,应该超越模仿学习,并从训练一开始就纳入人类偏好。

本文采用的方法是一种帕累托最优的简单方法:条件训练,或以人类偏好分数为条件的 token 分布学习。条件训练无论是在没有提示的情况下生成,还是在有对抗性选择的提示的情况下生成都可以将不良内容的比例降低了一个数量级。此外,无论是在特定任务微调之前还是之后,条件训练保持了标准 LM 预训练的下游任务性能。
05
/ ICML 2023 OralPoster /
论文标题:
Whose Opinions Do Language Models Reflect?
论文链接:
https://arxiv.org/abs/2303.17548

该文章的核心贡献如下:
1. 提出了一种定量框架,通过利用高质量的公开民意调查,研究语言模型(Language models,LMs)反映的观点。使用这个框架,创建了 OpinionQA 数据集,用于评估 LM 观点与美国 60 个人口群体的观点之间的一致性。研究发现,当前 LMs 反映的观点与美国人口群体存在相当大的不一致,这种不一致程度与民主党和共和党在气候变化问题上的分歧程度相当。即使在明确引导 LMs 朝特定群体的观点方向时,这种不一致仍然存在。研究还发现,一些经过人类反馈调整的 LMs 存在左倾的表现,并且一些群体(如65岁以上和丧偶者)的观点在当前 LMs 中得不到很好的反映。
2. 提出了一种将公共民意调查转化为评估 LM 观点的数据集的方法。利用Pew Research 的美国趋势面板(American Trends Panels)进行调查,创建了 OpinionQA 数据集,涵盖了科学、政治、个人关系等各种主题的 1498 个问题。
3. 提出了衡量人类- LM 观点一致性的评估指标,包括代表性、可操纵性和一致性。研究发现,大多数 LMs 在被引导时确实可以更好地与特定群体的观点一致,但这种改进有限,而且存在一些 LMs 与特定群体的不一致现象。此外,不同的 LMs 在一致性方面存在差异,即它们在不同主题上与特定群体的一致性不一致。
总体而言,该研究提供了一种定量框架和 OpinionQA 数据集,用于评估 LM 观点与不同人口群体观点之间的一致性,揭示了当前 LMs 在反映观点方面存在的不一致性和偏倚,并为开发人员和用户提供了更好地理解 LM 行为和识别观点表达失败的工具。
06
/ ICML 2023 OralPoster /
论文标题:
Mimetic Initialization of Self-Attention Layers
论文链接:
https://arxiv.org/abs/2305.09828

该文章的出发点是探索为什么在小型数据集上训练 Transformer 模型非常困难,通常需要使用大型预训练模型作为起点。作者观察到预训练的 Transformer 模型的自注意力层的权重存在一定的 pattern,即查询和键的权重的乘积近似为单位矩阵,值和投影的权重的乘积近似为负的单位矩阵。基于这一观察,作者提出了一种名为 “mimetic initialization” 的初始化方法,将自注意力层的权重初始化成与预训练模型类似的模式。该方法在视觉任务(如 CIFAR-10 和 ImageNet 分类)上训练普通的 Transformer 模型时,能够实现更快的训练速度和更高的准确性。实验证明,使用该初始化方法可以在 CIFAR-10 和 ImageNet 分类任务中分别获得超过 5% 和 4% 的准确性提升。此外,文章还观察到该初始化方法对语言建模任务也有一定的性能提升。

07
/ ICML 2023 OralPoster /
论文标题:
Cross-Modal Fine-Tuning: Align then Refine
论文链接:
https://arxiv.org/abs/2302.05738

针对许多领域缺乏相关预训练模型的问题,本文提出了一种名为 ORCA 的跨模态微调框架,将单个大规模预训练模型的适用性扩展到多样的模态。ORCA 通过一种对齐然后细化的工作流来适应目标任务:给定目标输入,ORCA 首先学习一个嵌入网络,将嵌入特征分布与预训练模态进行对齐。然后,在嵌入数据上对预训练模型进行微调,以利用跨模态间共享的知识。通过广泛的实验证明,ORCA 在包含 12 种模态的 60 多个数据集的 3 个基准测试上取得了最先进的结果,优于各种手动设计的方法、AutoML 方法、通用方法和特定任务方法。该研究强调通过一系列消融研究来验证数据对齐的重要性,并展示了 ORCA 在数据有限的情况下的实用性。
该文章的核心方法是 ORCA 框架,它包含以下主要步骤:
1. 构建任务特定的嵌入网络:通过设计一个特定于任务的嵌入网络,将目标输入转换为与预训练模型的嵌入维度相匹配的序列特征。
2. 嵌入对齐:通过训练嵌入网络,将目标嵌入特征的分布与预训练模型的特征分布对齐,以便更好地适应预训练模型。
3. 微调:对整个目标模型进行微调,以最小化目标任务的损失函数,进一步使嵌入网络和预测器与预训练模型相适应。

08
/ ICML 2023 OralPoster /
论文标题:
Self-Interpretable Time Series Prediction with Counterfactual Explanations
论文链接:
https://arxiv.org/abs/2306.06024

这篇文章的出发点是解决可解释的时间序列预测问题,特别是在关键领域如医疗保健和自动驾驶中。现有的方法主要集中在通过为时间序列的不同部分分配重要分数来解释预测结果,然而,了解不同输入的贡献通常不足以为决策提供足够的信息:人们通常想知道输入的哪些变化可能导致特定的(理想的)预测。本文采取了一种不同且更具挑战性的方法,旨在开发一种自解释模型,名为 Counterfactual Time Series(CounTS),该模型基于因果图和生成模型,通过变分推断来近似后验分布,以生成可解释的反事实解释。作者提出了一个证据下界(ELBO)作为学习生成和推断模型的目标函数,并在该基础上设计了损失函数,用于训练模型的参数。文章还提供了实验结果,与现有的基线方法相比,该自解释模型能够生成更好的反事实解释,同时保持可比较的预测准确性。
这里有一个比较有趣的概念就是文章提到的 Actionable Counterfactual Explanation,假设有一个模型将来自年龄 的受试者的呼吸信号 的时间序列作为输入,以预测相应的睡眠阶段 'Awake'∈{'Awake','Light sleep', 'Deep sleep'}。典型方法为 的每个条目分配重要性分数以解释预测结果。然而,他们没有提供关于如何修改 到 以便预测可以更改为 = 'Deep Sleep' 的可操作的反事实解释。具有这种能力的理想方法可以提供关于模型为什么进行特定预测的更多信息,而且可以为实际使用提供更准确的指导。
09
/ ICML 2023 OralPoster /
论文标题:
Evaluating Self-Supervised Learning via Risk Decomposition
论文链接:
https://openreview.net/pdf?id=dEjB1SLDnt
在评估自监督学习(SSL)的性能时,现有的工作常使用单一指标(在 ImageNet 上的 linear probing)而无法提供关于模型为什么更好以及如何改进的深入理解。为了解决这个问题,论文提出了一种 SSL 风险分解(Risk Decomposition)方法,通过考虑表示学习步骤引起的错误来推广经典的监督近似-估计分解。分解包括四个错误组成部分:近似误差、表示可用性误差、探测器泛化误差和编码器泛化误差。
1. 近似值误差,由于编码器的结构没有执行任务的能力;
2. 表示可用性误差:由于使用 SSL 和线性探测导致的表示可用性误差。如果给定的 SSL 算法不能产生可用于预测所需任务的线性可分离表示,可用性误差将很大;
3. 探测器泛化误差:训练数据有限导致的 probing 泛化误差;
4. 编码器泛化误差,由于在有限数据上预训练编码器引起的误差。
论文进一步为每个风险组件提供一致且计算效率高的估计器,并利用这些估计器分析了 30 个设计选择对 169 个在 ImageNet 上评估的 SSL 视觉模型的影响。这些估计器使用相同的 SSL 编码器,因此具有简单、高效和一致的特点。通过对 169 个 SSL 模型进行分析,论文揭示了现代 SSL 中最重要的错误源是linear probing的泛化误差。此外,论文还表明一些设计选择(如大型投影头、ViT 编码器)同时改善了所有错误组成部分。但是,其他设计选择(如表示维度或 SSL 目标)在不同设置下只能在特定情况下提供帮助。论文总结了 SSL 的风险分解以及每个错误组成部分的有效估计器,并提供了关于设计选择如何影响风险组成部分和完整/少样本性能的分析结果。
10
/ ICML 2023 OralPoster /
论文标题:
Delving into Noisy Label Detection with Clean Data
论文链接:
https://openreview.net/pdf?id=qAW0AD6qYA

现实场景中的数据通常是含有 noisy data 的,为了缓解噪声标签引来问题,最近对噪声标签学习算法进行了广泛的研究。噪声标签检测是其中一类,它的重点是根据在噪声数据集上训练的分类器的输出,将干净的数据从损坏的数据集中分离出来。例如,随机划分有噪声的训练数据,然后使用交叉验证对真实标记的样本进行分类,同时在每轮训练中删除大损失样本。尽管有这种前景,但现有的噪声标签检测方法在很大程度上忽略了干净的数据。本文发现在现实世界的噪声数据集中通常有一小部分干净数据。例如,Clothing1M 由 1m 图像组成,具有真实的噪声标签和额外的 48K 个经过验证的干净数据点。此外,干净的数据已被用于提高分类器的性能。基于上述动机,本文旨在探索干净数据对噪声标签检测的好处
该文章的出发点是噪声标签检测中对干净数据的利用,以提高噪声标签检测的性能。文章提出了一种新的框架,通过将带有干净数据的噪声标签检测问题视为多重假设检验问题,实现了对干净数据的利用。同时,文章还提出了一种名为 BHN 的简单而有效的方法,将 Benjamini-Hochberg(BH)过程整合到深度神经网络中进行噪声标签检测。BHN在CIFAR-10 数据集上取得了最先进的性能,相对于基线方法在错误发现率(FDR)上提高了 28.48%,在 F1 指标上提高了 18.99%。文章通过大量的消融研究进一步证明了 BHN 的优越性。
该文章的核心方法是将噪声标签检测问题转化为多重假设检验问题,并结合深度神经网络和 Benjamini-Hochberg 过程进行处理。文章利用干净数据定义了 p-value,并使用负交叉熵损失作为得分函数进行噪声标签检测。通过控制 FDR,文章能够有效地检测出噪声标签,并提高分类器的性能。
11
/ ICML 2023 OralPoster /
论文标题:
ODS: Test-Time Adaptation in the Presence of Open-World Data Shift
论文链接:
https://openreview.net/pdf?id=Phjti0QbkZ

这篇文章的出发点是研究测试阶段的数据分布偏移问题,并提出了一种名为“Test-time adaptation with Open-world Data Shift”(AODS)的新问题设置。传统的测试阶段适应算法主要关注协变量分布偏移,即测试数据的分布与源数据不同。但实际应用中还需要考虑标签分布偏移的影响,即标签分布也发生了变化。为了解决这个问题,作者提出了 ODS 框架,可以同时适应协变量和标签分布的偏移。该框架通过解耦混合分布偏移,并相应地处理协变量和标签分布偏移来优化模型性能。
文章的核心方法是提出的名为开放世界数据转换(ODS)的新框架,该框架包含两个关键模块:Distribution Tracker 和 Prediction Optimizer。Distribution Tracker 用于估计每个时间戳 处的标签分布 ,而Prediction Optimizer 用于基于估计的标签分布优化模型的预测结果。ODS 框架与许多现有的测试阶段适应算法相结合,共同优化以提高测试性能。
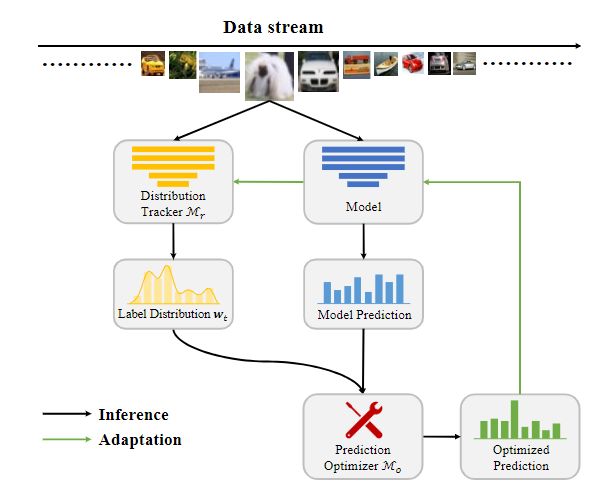
作者在多个不同类型的基准上进行了实验,以评估所提出方法的性能。实验结果表明,ODS 框架优于现有的 TTA 方法。此外,作者强调 ODS 框架与许多现有的 TTA 算法兼容。
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
投稿通道:
• 投稿邮箱:[email protected]
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
·
·
