MySQL——九、SQL编程
MySQL
- 一、触发器
-
- 1、触发器简介
- 2、创建触发器
- 3、一些常见示例
- 二、存储过程
-
- 1、什么是存储过程或者函数
- 2、优点
- 3、存储过程创建与调用
- 三、存储函数
-
- 1、存储函数创建和调用
- 2、修改存储函数
- 3、删除存储函数
- 四、游标
-
- 1、声明游标
- 2、打开游标
- 3、使用游标
- 4、关闭游标
-
- 游标案例
一、触发器
1、触发器简介
触发器(trigger)是一个特殊的存储过程,它的执行不是由程序调用,也不是手工启动,而是由事件来触发,比如当对一个表进行操作( insert,delete, update)时就会激活它执行。
触发器经常用于加强数据的完整性约束和业务规则等。例如,当学生表中增加了一个学生的信息时,学生的总数就应该同时改变。因此可以针对学生表创建一个触发器,每次增加一个学生记录时,就执行一次学生总数的计算操作,从而保证学生总数与记录数的一致性。
2、创建触发器
语法结构:
CREATE TRIGGER 触发器名称 BEFORE|AFTER 触发事件
ON 表名 FOR EACH ROW
BEGIN
触发器程序体;
END
# 说明:
<触发器名称> 最多64个字符,它和MySQL中其他对象的命名方式一样
{ BEFORE | AFTER } 触发器时机
{ INSERT | UPDATE | DELETE } 触发的事件
ON <表名称> 标识建立触发器的表名,即在哪张表上建立触发器
FOR EACH ROW 触发器的执行间隔:
FOR EACH ROW子句通知触发器 每隔一行执行一次动作,而不是对整个表执行一次
<触发器程序体> 要触发的SQL语句:可用顺序,判断,循环等语句实现一般程序需要的逻辑功能
3、一些常见示例
1、示例1:
-
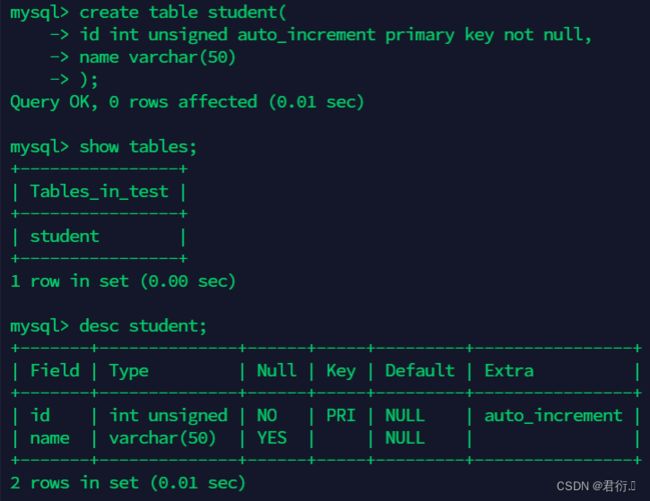
- 创建表
mysql>create table student(
id int unsigned auto_increment primary key not null,
name varchar(50)
);
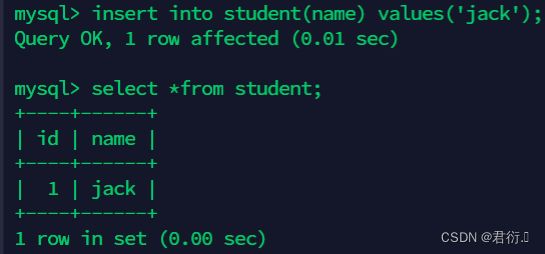
mysql>insert into student(name) values('jack');
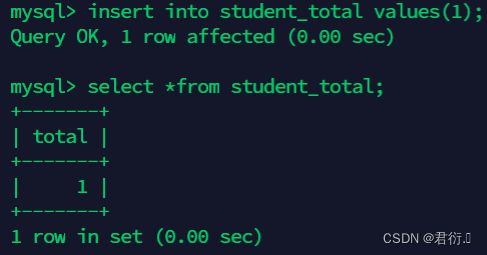
create table student_total(total int);
insert into student_total values(1);

-
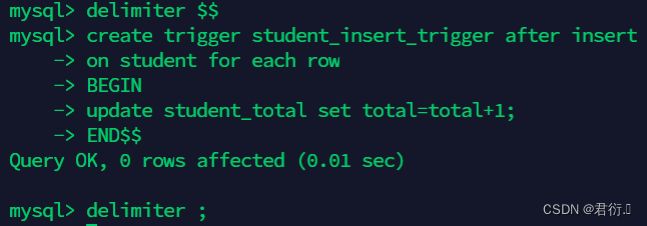
- 创建触发器student_insert_trigger
mysql> delimiter $$
mysql> create trigger student_insert_trigger after insert
on student for each row
BEGIN
update student_total set total=total+1;
# 其他SQL
END$$
mysql> delimiter ;
查看触发器
-
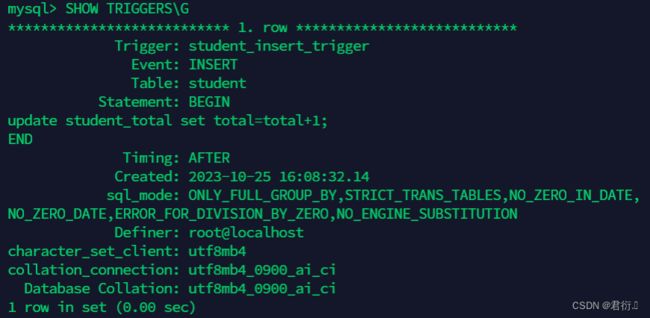
- 通过SHOW TRIGGERS语句查看
SHOW TRIGGERS\G
-
- 通过系统表triggers查看
USE information_schema
SELECT * FROM triggers\G
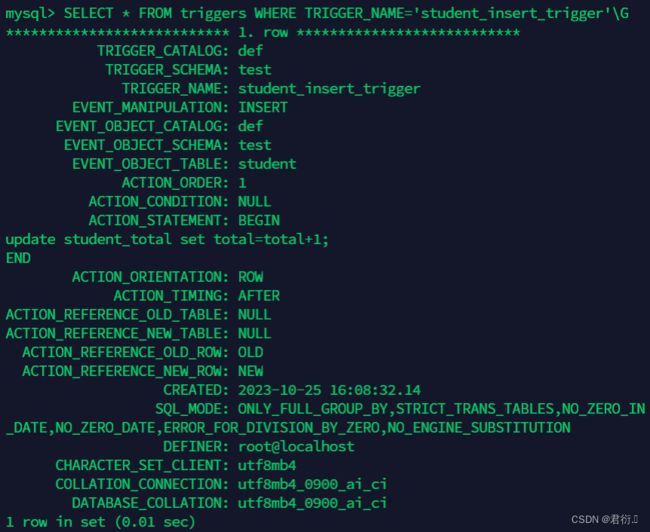
SELECT * FROM triggers WHERE TRIGGER_NAME='触发器名称'\G

删除触发器
通过DROP TRIGGERS语句删除
sql> DROP TRIGGER 解发器名称
2、示例2
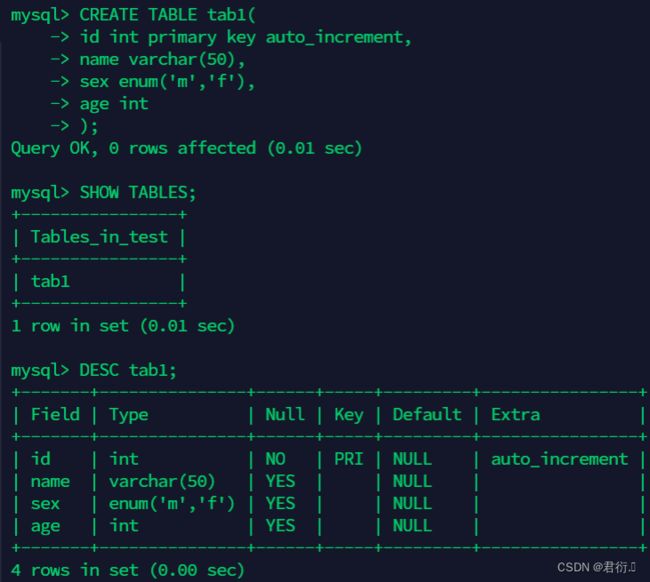
- 1、创建表tab1
DROP TABLE IF EXISTS tab1;
CREATE TABLE tab1(
id int primary key auto_increment,
name varchar(50),
sex enum('m','f'),
age int
);
- 2、创建表tab2
DROP TABLE IF EXISTS tab2;
CREATE TABLE tab2(
id int primary key auto_increment,
name varchar(50),
salary double(10,2)
);

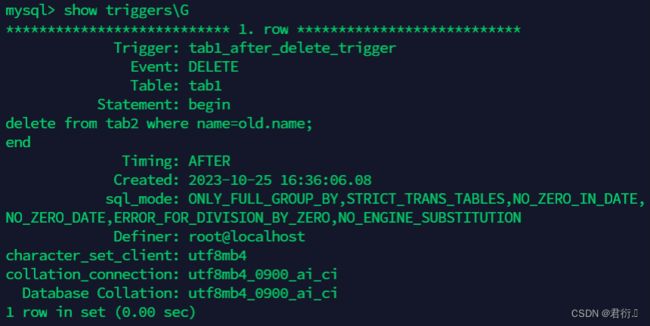
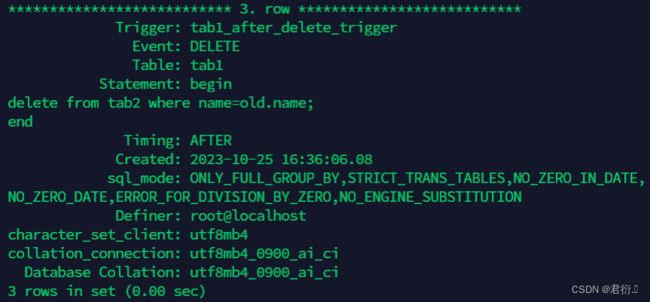
触发器tab1_after_delete_trigger
作用:tab1表删除记录后,自动将tab2表中对应记录删除
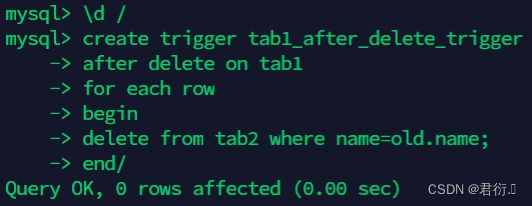
mysql> \d /
mysql> create trigger tab1_after_delete_trigger
after delete on tab1
for each row
begin
delete from tab2 where name=old.name;
end/
触发器tab1_after_update_trigger
作用:当tab1更新后,自动更新tab2
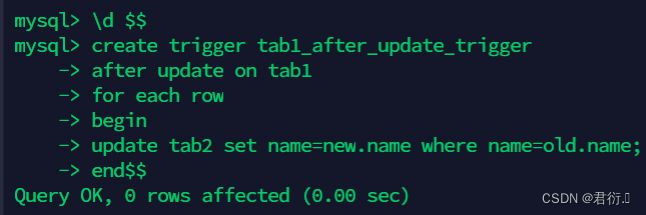
mysql> \d $$
mysql> create trigger tab1_after_update_trigger
after update on tab1
for each row
begin
update tab2 set name=new.name where name=old.name;
end$$
触发器tab1_after_insert_trigger
作用:当tab1增加记录后,自动增加到tab2
mysql> \d /
mysql> create trigger tab1_after_insert_trigger
after insert on tab1
for each row
begin
insert into tab2 values(null, name, 5000);
end/

二、存储过程
1、什么是存储过程或者函数
存储过程和函数是事先经过编译并存储在数据库中的一段sql语句集合,调用存储过程函数可以简化应用开发人员的很多工作,减少数据在数据库和应用服务器之间的传输,对于提高数据处理的效率是有好处的。
存储过程和函数的区别:
- 函数必须有返回值,而存储过程没有。
- 存储过程的参数可以是IN、OUT、INOUT类型,函数的参数只能是IN
2、优点
- 存储过程只在创建时进行编译;而SQL语句每执行一次就编译一次,所以使用存储过程可以提高数据库执行速度
- 简化复杂操作,结合事务一起封装
- 复用性好
- 安全性高,可指定存储过程的使用权
注意:并发量少的情况下,很少使用存储过程。并发量高的情况下,为了提高效率,用存储过程比较多。
3、存储过程创建与调用
创建存储过程语法 :
create procedure sp_name(参数列表)
[特性...]过程体
存储过程的参数形式:[IN | OUT | INOUT]参数名 类型
IN 输入参数
OUT 输出参数
INOUT 输入输出参数
delimiter $$
create procedure 过程名(参数列表)
begin
SQL语句
end $$
delimiter ;
调用:
call 存储过程名(实参列表)
存储过程三种参数类型:IN, OUT, INOUT:
===================NONE========================
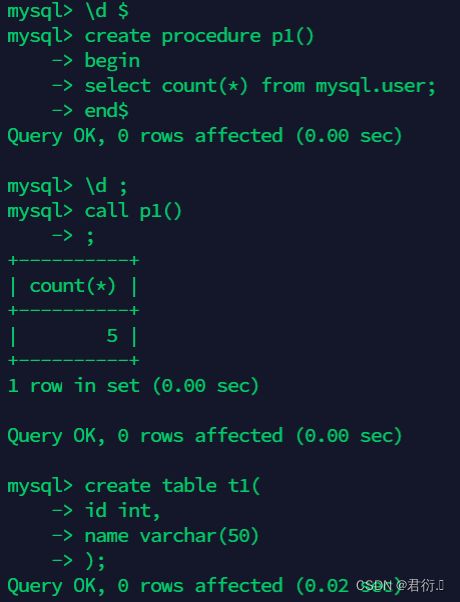
mysql> \d $
mysql> create procedure p1()
begin
select count(*) from mysql.user;
end$
mysql> \d ;
mysql> call p1();
mysql> create table t1(
id int,
name varchar(50)
);
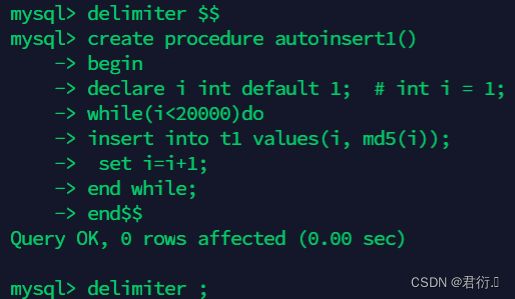
mysql> delimiter $$
mysql> create procedure autoinsert1()
begin
declare i int default 1; # int i = 1;
while(i<20000)do
insert into t1 values(i, md5(i));
set i=i+1;
end while;
end$$
mysql> delimiter ;
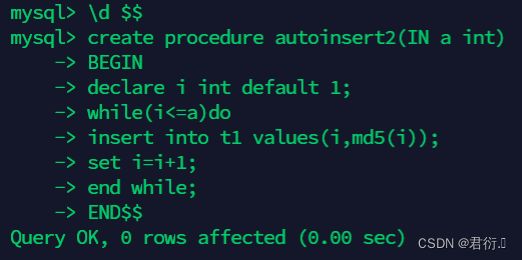
====================IN==========================
mysql> create procedure autoinsert2(IN a int)
BEGIN
declare i int default 1;
while(i<=a)do
insert into t1 values(i,md5(i));
set i=i+1;
end while;
END$$
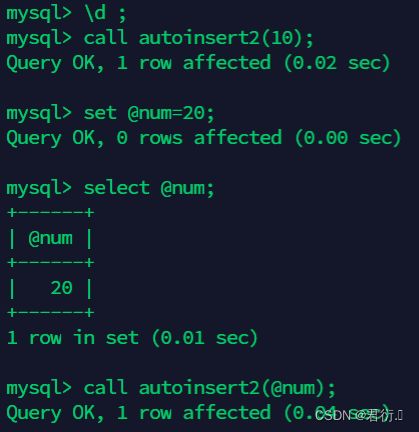
mysql> call autoinsert2(10);
mysql> set @num=20;
mysql> select @num;
+------+
| @num |
+------+
| 20 |
+------+
mysql> call autoinsert2(@num);
====================OUT=======================
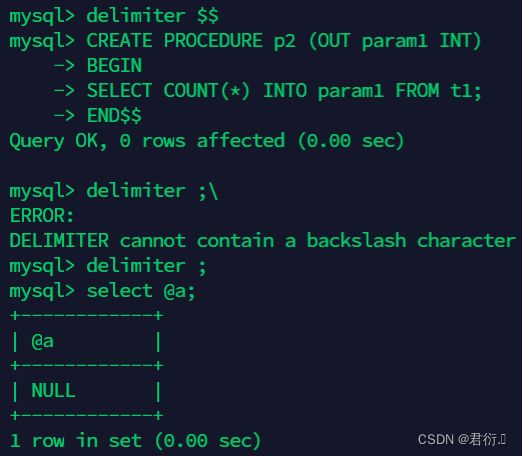
mysql> delimiter $$
mysql> CREATE PROCEDURE p2 (OUT param1 INT)
BEGIN
SELECT COUNT(*) INTO param1 FROM t1;
END$$
mysql> delimiter ;
mysql> select @a;
+------+
| @a |
+------+
| NULL |
+------+
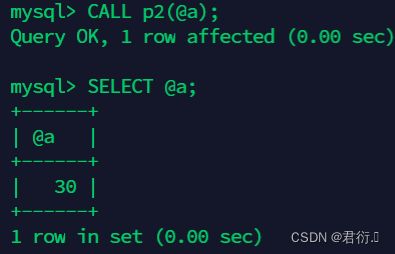
mysql> CALL p2(@a);
mysql> SELECT @a;
+------+
| @a |
+------+
| 30 |
+------+
===================IN 和 OUT=====================
作用:统计指定部门的员工数
mysql> create procedure count_num(IN p1 varchar(50), OUT p2 int)
BEGIN
select count(*) into p2 from employee where post=p1;
END$$
mysql> \d ;
mysql> call count_num('hr',@a);
mysql>select @a;


作用:统计指定部门工资超过例如5000的总人数
mysql> create procedure count_num(IN p1 varchar(50), IN p2 float(10,2), OUT p3 int)
BEGIN
select count(*) into p3 from employee where post=p1 and salary>=p2;
END$$
mysql> \d ;
mysql> call count_num('hr',5000,@a);
====================INOUT======================
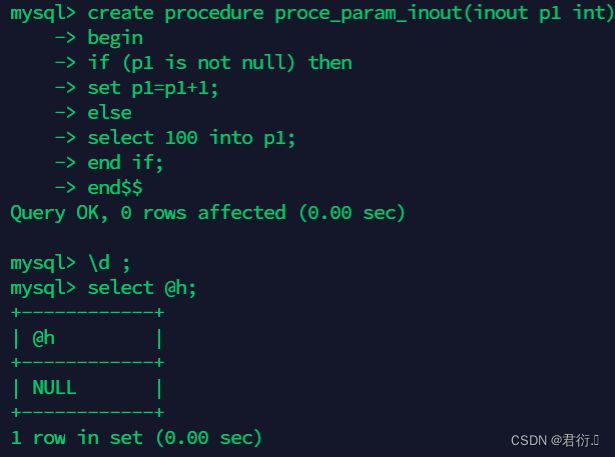
mysql> create procedure proce_param_inout(inout p1 int)
begin
if (p1 is not null) then
set p1=p1+1;
else
select 100 into p1;
end if;
end$$
mysql> \d ;
mysql> select @h;
+------+
| @h |
+------+
| NULL |
+------+
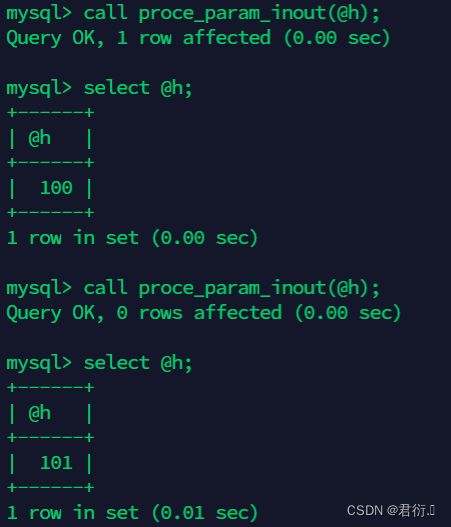
mysql> call proce_param_inout(@h);
mysql> select @h;
+------+
| @h |
+------+
| 100 |
+------+
mysql> call proce_param_inout(@h);
mysql> select @h;
+------+
| @h |
+------+
| 101 |
+------+
三、存储函数
MySQL存储函数(自定义函数),函数一般用于计算和返回一个值,可以将经常需要使用的计算或功能写成一个函数。函数和存储过程类似。
存储过程和函数的区别:
- 函数必须有返回值,而存储过程可以没有。
- 存储过程的参数可以是IN、OUT、INOUT类型,函数的参数只能是IN
1、存储函数创建和调用
创建存储函数
在MySQL中,创建存储函数使用CREATE FUNCTION关键字,其基本形式如下:
CREATE FUNCTION func_name ([param_name type[,...]])
RETURNS type
[characteristic ...]
BEGIN
routine_body
END;
参数说明:
- (1)func_name :存储函数的名称。
- (2)param_name type:可选项,指定存储函数的参数。type参数用于指定存储函数的参数类型,该类型可以是MySQL数据库中所有支持的类型。
- (3)RETURNS type:指定返回值的类型。
- (4)characteristic:可选项,指定存储函数的特性。
- (5)routine_body:SQL代码内容。
调用存储函数
在MySQL中,存储函数的使用方法与MySQL内部函数的使用方法基本相同。用户自定义的存储函数与MySQL内部函数性质相同。区别在于,存储函数是用户自定义的。而内部函数由MySQL自带。其语法结构如下:
SELECT func_name([parameter[,…]]);
常见示例
MySQL开启bin-log后,调用存储过程或者函数以及触发器时,会出现错误号为1418的错误:
在MySQL中创建函数时出现这种错误的解决方法:
- 方法1:第一种是在创建子程序(存储过程、函数、触发器)时,声明为DETERMINISTIC或NO SQL与READS SQL DATA中的一个, 例如:
CREATE DEFINER = CURRENT_USER PROCEDURE `NewProc`()
DETERMINISTIC
BEGIN
#Routine body goes here...
END;
- 方法2:第二种是信任子程序的创建者,禁止创建、修改子程序时对SUPER权限的要求,设置log_bin_trust_routine_creators全局系统变量为1。
-
- (1)在客户端上执行 SET GLOBAL log_bin_trust_function_creators = 1。
-
- (2)MySQL启动时,加上–log-bin-trust-function-creators选项,参数设置为1。
-
- (3)在MySQL配置文件my.ini或my.cnf中的[mysqld]段上加log-bin-trust-function-creators=1。
################1、无参有返回值#########################
# 统计emp表中员工个数
mysql> \d $
mysql> CREATE FUNCTION myf1()
RETURNS int
BEGIN
DECLARE c INT DEFAULT 0;
SELECT COUNT(1) INTO c FROM emp;
RETURN c;
END$
mysql> \d;
mysql> select myf1();
+--------+
| myf1() |
+--------+
| 15 |
+--------+
#################2、有参有返回值#####################
示例1:根据员工名返回工资
mysql> \d $
mysql> CREATE FUNCTION myf2(empName varchar(20))
RETURNS INT
BEGIN
DECLARE sal INT;
SELECT sai INTO sal FROM emp WHERE ename=empName;
RETURN sal;
END $
mysql> \d;
mysql> select myf2('刘备');
+----------------+
| myf2('刘备') |
+----------------+
| 29750 |
+----------------+
示例2:根据部门编号,返回平均工资
mysql> \d $
mysql> CREATE FUNCTION myf3(d_No int)
RETURNS DOUBLE
BEGIN
DECLARE avg_sal DOUBLE;
SELECT AVG(sai) INTO avg_sal FROM emp WHERE deptno=d_No;
RETURN avg_sal;
END $
mysql> \d ;
mysql> select myf3(20);
+----------+
| myf3(20) |
+----------+
| 21750 |
+----------+
2、修改存储函数
MySQL中,通过ALTER FUNCTION 语句来修改存储函数,其语法格式如下:
ALTER FUNCTION func_name [characteristic ...]
characteristic:
COMMENT 'string'
| LANGUAGE SQL
| { CONTAINS SQL | NO SQL | READS SQL DATA | MODIFIES SQL DATA }
| SQL SECURITY { DEFINER | INVOKER }
上面这个语法结构是MySQL官方给出的,修改的内容可以包SQL语句也可以不包含。
3、删除存储函数
MySQL中使用DROP FUNCTION语句来删除存储函数。
示例:删除存储函数。
DROP FUNCTION IF EXISTS func_user;
四、游标
游标(Cursor)是处理多行数据的,游标需要开启,抓取,关闭的。
在 MySQL 中,存储过程或函数中的查询有时会返回多条记录,而使用简单的 SELECT 语句,没有办法得到第一行、下一行或前十行的数据,这时可以使用游标来逐条读取查询结果集中的记录。游标在部分资料中也被称为光标。
关系数据库管理系统实质是面向集合的,在 MySQL 中并没有一种描述表中单一记录的表达形式,除非使用 WHERE 子句来限制只有一条记录被选中。所以有时我们必须借助于游标来进行单条记录的数据处理。
一般通过游标定位到结果集的某一行进行数据修改。
结果集是符合 SQL 语句的所有记录的集合。
个人理解游标就是一个标识,用来标识数据取到了什么地方,如果你了解编程语言,可以把他理解成数组中的下标。
不像多数 DBMS,MySQL 游标只能用于存储过程和函数。
下面介绍游标的使用,主要包括游标的声明、打开、使用和关闭。
1、声明游标
MySQL 中使用 DECLARE 关键字来声明游标,并定义相应的 SELECT 语句,根据需要添加 WHERE 和其它子句。其语法的基本形式如下:
DECLARE cursor_name CURSOR FOR select_statement;
其中,cursor_name 表示游标的名称;select_statement 表示 SELECT 语句,可以返回一行或多行数据。
下面声明一个名为 nameCursor 的游标,代码如下:
mysql> DELIMITER //
mysql> CREATE PROCEDURE processnames()
BEGIN
DECLARE nameCursor CURSOR
FOR
SELECT name FROM tb_student;
END//

以上语句定义了 nameCursor 游标,游标只局限于存储过程中,存储过程处理完成后,游标就消失了。
2、打开游标
声明游标之后,要想从游标中提取数据,必须首先打开游标。在 MySQL 中,打开游标通过 OPEN 关键字来实现,其语法格式如下:
OPEN cursor_name;
其中,cursor_name 表示所要打开游标的名称。需要注意的是,打开一个游标时,游标并不指向第一条记录,而是指向第一条记录的前边。
在程序中,一个游标可以打开多次。用户打开游标后,其他用户或程序可能正在更新数据表,所以有时会导致用户每次打开游标后,显示的结果都不同。
3、使用游标
游标顺利打开后,可以使用 FETCH…INTO 语句来读取数据,其语法形式如下:
FETCH cursor_name INTO var_name [,var_name]...
上述语句中,将游标 cursor_name 中 SELECT 语句的执行结果保存到变量参数 var_name 中。变量参数 var_name 必须在游标使用之前定义。使用游标类似高级语言中的数组遍历,当第一次使用游标时,此时游标指向结果集的第一条记录。
MySQL 的游标是只读的,也就是说,你只能顺序地从开始往后读取结果集,不能从后往前,也不能直接跳到中间的记录。
4、关闭游标
游标使用完毕后,要及时关闭,在 MySQL 中,使用 CLOSE 关键字关闭游标,其语法格式如下:
CLOSE cursor_name;
CLOSE 释放游标使用的所有内部内存和资源,因此每个游标不再需要时都应该关闭。
在一个游标关闭后,如果没有重新打开,则不能使用它。但是,使用声明过的游标不需要再次声明,用 OPEN 语句打开它就可以了。
如果你不明确关闭游标,MySQL 将会在到达 END 语句时自动关闭它。游标关闭之后,不能使用 FETCH 来使用该游标。
游标案例
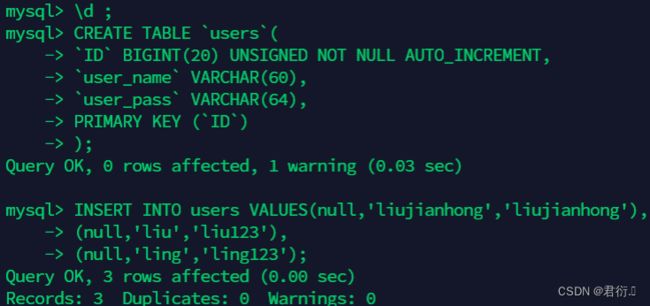
创建 users 数据表,并插入数据,SQL 语句和运行结果如下:
mysql> CREATE TABLE `users`(
`ID` BIGINT(20) UNSIGNED NOT NULL AUTO_INCREMENT,
`user_name` VARCHAR(60),
`user_pass` VARCHAR(64),
PRIMARY KEY (`ID`)
);
mysql> INSERT INTO users VALUES(null,'liujianhong','liujianhong'),
(null,'liu','liu123'),
(null,'ling','ling123');
创建存储过程 test_cursor,并创建游标 cur_test,查询 users 数据表中的第 3 条记录,SQL 语句和执行过程如下:
mysql> DELIMITER //
mysql> CREATE PROCEDURE test_cursor (in param INT(10),out result VARCHAR(90))
BEGIN
DECLARE name VARCHAR(20);
DECLARE pass VARCHAR(20);
DECLARE done INT;
DECLARE cur_test CURSOR FOR SELECT user_name,user_pass FROM users;
DECLARE continue handler FOR SQLSTATE '02000' SET done = 1;
IF param THEN INTO result FROM users WHERE id = param;
ELSE
OPEN cur_test;
repeat
FETCH cur_test into name,pass;
SELECT concat_ws(',',result,name,pass) INTO result;
until done
END repeat;
CLOSE cur_test;
END IF;
END //
mysql> call test_cursor(3,@test)//
mysql> select @test//
+-----------+
| @test |
+-----------+
| ling,ling123 |
+-----------+
创建 pro_users() 存储过程,定义 cur_1 游标,将表 users 中的 user_name 字段全部修改为 MySQL,SQL 语句和执行过程如下。
mysql> CREATE PROCEDURE pro_users()
BEGIN
DECLARE result VARCHAR(100);
DECLARE no INT;
DECLARE cur_1 CURSOR FOR SELECT user_name FROM users;
DECLARE CONTINUE HANDLER FOR NOT FOUND SET no=1;
SET no=0;
OPEN cur_1;
WHILE no=0 do
FETCH cur_1 into result;
UPDATE users SET user_name='MySQL'
WHERE user_name=result;
END WHILE;
CLOSE cur_1;
END //
mysql> call pro_users() //
mysql> SELECT * FROM users //
+----+-----------+-----------+
| ID | user_name | user_pass |
+----+-----------+-----------+
| 1 | MySQL | liujianhon|
| 2 | MySQL | liu123 |
| 3 | MySQL | ying |
+----+-----------+-----------+
3 rows in set (0.00 sec)
结果显示,users 表中的 user_name 字段已经全部修改为 MySQL。