前端大文件下载方案
前端大文件下载方案
文章目录
- 前端大文件下载方案
-
- JSZip
- StreamSaver.js
-
- 与 JSZip 结合使用?
- mitm + sw 配置
tags:
- Streams API
- Service Worker
- StreamSaver.js
- JSZip
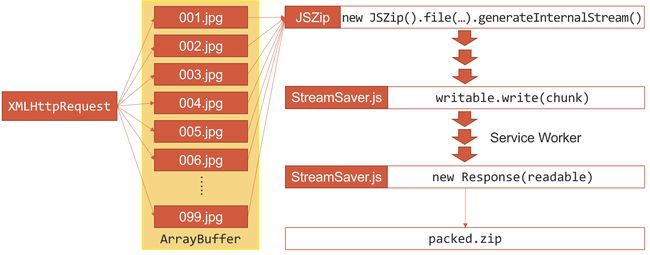
在业务中遇到需要用户下载一个很巨大的 zip 包的场景,内容通常是一堆很小的(图片)文件打包到一起。传统的下载方案是直接修改 window.location.href=后端提供的下载链接,之后后端一边去下载要打包的文件,一边把打包好的东西写入这个链接。
存在的问题是,如果文件很大,这个链接需要一直保持,相当于这个接口一直开着没有结束(运维同学很不开心);而且一旦中间出了什么问题,已经下载的东西也全部废了,下次还要重新开始(可以通过设置 http range 头等方法实现断点续传)。
那么,反正后端也没有存这个大文件,也是现用现生成的,可不可以把这个工作转移到前端?如果把请求一堆小文件的工作转移到浏览器,那就绕开了下载接口的时间限制,而且我们知道哪些文件已经下载了,是不是也可以通过一些操作保留住已经下载的文件?
JSZip
在知道 Streams API 这种高级玩意之前,我一直以为浏览器中的 js 代码是不能做流操作的,也就是不能一边下一边往本地写。那么一个最直接的想法就是把文件都下到内存中,之后调用 JSZip 统一打包,再调用 FileSaver.js 触发保存操作。文件数据一直是以 blob 方式传递的,简单的代码示意如下:
import { saveAs } from 'file-saver'
import JSZip from 'jszip'
const urls = [xxx] // 一堆需要下载的文件 url
const ZIP = new JSZIP()
Promise.all(urls.map((url, index) => new Promise((resolve, reject) => {
fetch(url).then(response => {
if (response.status === 200) {
zip.file(url, response.blob()) // blob 哦
resolve()
}
})
}))).then(() => {
zip.generateAsync({ type: 'blob' }).then(content => {
saveAs(content, 'hello.zip')
})
})
很容易想象,这种方式对内存消耗非常大,而且随着文件数量的增长,打包 zip 这个过程会越来越慢,时间当然也不是线性增长那么简单。实际测试结果也如此(不过实际测试,能处理的文件大小超出了我的想象,几个 G 都不是问题,就是慢而已)。
StreamSaver.js
前置阅读:从 Fetch 到 Streams —— 以流的角度处理网络请求
啊,流,完美的解决方案。
有了读写流的能力,还需要解决的一个问题就是如何维持一个持续的通道,保证能够一边在下载,一边把下载的东西写到本地。
啊哈,我们也可以模仿后端,制造一个(不存在的)下载链接,然后用 Service Worker 去拦截对这个链接的请求,持续往这里面写就可以了!
这就是 StreamSaver.js 所做的事情。简单的代码示意如下:
import StreamSaver from 'streamsaver'
import ZipStream from './zip-stream.js' // 作者提供的 zip 工具
const urls = [xxx] // 一堆需要下载的文件 url
const fileStream = StreamSaver.createWriteStream('hello.zip')
const readableZipStream = new ZipStream({
async pull(control) {
const it = url.next()
if (it.done) {
control.close()
} else {
const response = await fetch(url)
control.enqueue({
name: url,
stream: () => response.body // 这个是 ReadableStream 类型!web 标准万岁!
})
}
}
if (window.WritableStream && readableZipStream.pipeTo) {
return readableZipStream.pipeTo(fileStream).then(() => {
that.dialogExportProcess = false;
});
}
})
上述的代码实现了每次下载一个文件 -> 向流中写入一个文件这样类似单线程(?)的处理过程,那么能否实现如从 Fetch 到 Streams —— 以流的角度处理网络请求这篇中所说,结合 JSZip,在一次 pull 过程中下载好几个,然后用 JSZip 把这好几个文件压成一块流一口气写入呢?
与 JSZip 结合使用?
首先,使用文章里描述的 generateInternalStream() 这个方法是行不通的,JSZip 的 StreamHelper API 只是模拟了流的实现,但返回值并不是符合 Stream API 标准的 ReadableStream/WritableStream 类型。
不过 blob 总是可行的,如果在 JSZip 里面用 blob 处理,到时候再用 blob.stream() 这种方法转成 ReadableStream 写入流中,似乎听上去不错。不过我在实际操作的过程中遇到的一个问题就是,control.enqueue() 时文件名怎么处理?我试着写成以 / 结尾表示我要写入一个文件夹,不过似乎并不能达到预想效果…
mitm + sw 配置
最后写一下实际使用 StreamSaver 时所需的 sw 配置。
直接跑作者给出的示例代码会发现,运行下载之后页面上会多出两个这样的 iframe
<iframe hidden="" src="https://jimmywarting.github.io/StreamSaver.js/mitm.html?version=2.0.0" name="iframe">iframe>
<iframe hidden="" src="https://jimmywarting.github.io/StreamSaver.js/null/637501/archive.zip" name="iframe">iframe>
emm,第二个看起来像是下载链接的样子(当然是我们制造的,实际打开里面什么都没有),第一个的话打开发现里面有一些 js 代码,似乎是注册了 sw 的样子。
但是这域名,这前缀,都是啥?能不能搞到自己本地?到时候项目上线还带着别人的 github.io 可不行…
来看下作者的解释:
So the one and only other solution is to do what the server does: Send a stream with Content-Disposition header to tell the browser to save the file. But we don’t have a server or the content isn’t on a server! So the solution is to create a service worker that can intercept request and use respondWith() and act as a server.
But a service workers are only allowed in secure contexts and it requires some effort to put up. Most of the time you are working in the main thread and the service worker are only alive for < 5 minutes before it goes idle.
1.So StreamSaver creates a own man in the middle that installs the service worker in a secure context hosted on github static pages. either from a iframe (in secure context) or a new popup if your page is insecure.
2.Transfer the stream (or DataChannel) over to the service worker using postMessage.
3.And then the worker creates a download link that we then open.
if a “transferable” readable stream was not passed to the service worker then the mitm will also try to keep the service worker alive by pinging it every x second to prevent it from going idle.
嗯,这个 mitm.html 确实是在完成 service worker 注册的工作。而 service worker 注册有很多限制:(为方便说明,下文中 mitm.html 代表“注册 service worker 的位置“,sw.js 代表“service worker 所在的位置“)
- 只能在 HTTPS/localhost 环境下注册(否则报错如
Failed to register a ServiceWorker: An SSL certificate error occurred when fetching the script.) - 要注册的 sw.js 文件必须和注册它的 mitm.html 同源(否则报错如
Failed to register ServiceWorker. The origin of the provider scriptURL('sw.js 所在的域') does not match the current origin ('mitm.html 所在的域').) - service worker 的作用域不能超出 sw.js 自己所在位置(否则报错如
Failed to register a ServiceWorker: The path of the provided scope ('mitm.html 所在的路径') is not under the max scope allowed ('sw.js 所在的路径'). Adjust the scope, move the Service Worker script, or use the Service-Worker-Allowed HTTP header to allow the scope.)
所以作者默认把 sw 注册在了他自己的的 github 静态页面上,而如果我们想在自己的域名上注册 sw,就需要注意上面三点限制:
- https 环境限制:如为 http,可以把网站改成 https 然后手动信任下证书
- 同源限制:如果不同源,可以采用配置 nginx 代理让它们看上去是同源的
- 作用域限制:如果不想修改这两个文件的位置,可以通过 nginx 在 sw.js 的 response header 中加入
Service-Worker-Allowed这个头