SQL中:语法总结(group by,having ,distinct,top,order by,like等等)
语法总结:group by,distinct ......
- 1.group by
- 2.聚集函数
-
- count
- 3.order by
- 4.增insert、删(drop、delete)、改(update、alter)
- 5.查select
-
- 嵌套查询
- 不相关子查询
- 相关子查询
-
- 使用的谓词
- 使用的谓词
- 子查询的相关谓词
- 集合查询
- 待续、更新中
1.group by
作用:给列划分成组
对表中某列属性成组划分,一个列中按其属性可划分成多个组
或
按指定的一列或多列值分组,值相等的为一组
注意:
使用条件时,用having
例:
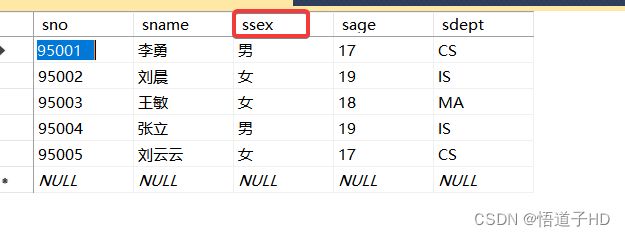 图1
图1
sex 性别,可划分为:男、女 两组
以此类推:
上表也可以按sage 年龄分组,分为17、18、19三组
也可以按sno 学号分组,分为95001、95002等等五组,但这样分就没有意义了。
具体查询结果看 2.聚集函数中图2
2.聚集函数
第二个就写聚集函数,那肯定和上面的group by有点关联了;
1.一般聚集函数 常与group by 连用
2.聚集函数中可使用distinct 去掉重复值,如count(distinct 列名)等
3.聚集函数也可按情况单独使用,不用group by分组
若对查询结果分组后,聚集函数将分别作用于每个组
例:
查询结果如下图所示(查询表上图一):
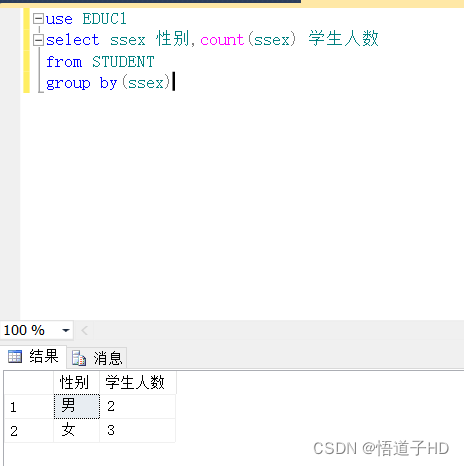
图2
count
计数,求表中行的个数
用法:
count(列名)
count(distinct 列名)
3.order by
例:
select *
from student
where sno=1
order by 列名 desc,列名 asc
注意:嵌套查询的子查询中不能使用order by子句
4.增insert、删(drop、delete)、改(update、alter)
向表中添加数据
例:
use xmgl -- 使用数据库
insert into sjproject -- 字段名
values --字段值
('2001','J001','项目总监'),
('2001','J008','项目总监'),
('2002','J001','项目员工'); -- 一次插入多条数据
5.查select
语法:
select distinct 或 top 列名
from student (student 为表名)
嵌套查询
外层查询 与 内层查询
例:
select * /* 查询所有列 ,此select为 外层查询 */
from student
where sno in
(
select sno /* 此select为内层查询 ,不可使用order by子句 */
from student
sno=1 or sno =2
)
内层查询 与 外层查询中:
where 列名1 < any
(
select 列名1
from sc
where ssex=‘男’
)
列名一样
不相关子查询
子查询的查询条件不依赖于父查询
过程:
由里向外逐层处理
即每个子查询在上一级查询处理之前求解,子查询的结果用于建立其父查询的查找条
件。
相关子查询
子查询的查询条件依赖于父查询
过程
1.首先取外层查询中表的第一个元组,根据它与内层查询相关的属性值处理内层查询,若where子句返回值为真,则取此元组放入结果表
2.再取外层表的下一个元组
3.重复这一过程,直至外层表全部检查完为止
外查询、内查询、外查询
使用的谓词
1.in谓词 (一般专有使用)
为什么不用等号=
等号=, 仅仅一个结果
in谓词,子查询中有多个结果
2.比较运算符
不等于:
!= 或 <>
结果:
true 或 false
使用的谓词
1.exist / not exitst (一般专有使用)
使用:
exists 存在true ,子查询中存在,结果:true
exists 存在true,子查询中不存在,结果:false
not exists 不存在false,子查询中存在true,结果:false
not exists 不存在false,子查询中不存在false,在结果:true
结果:
true 或 false
2.比较运算符
子查询的相关谓词
any(some)或all谓词
语法:
any(some):
子查询中某个值
all:
子查询中所有值
集合查询
UNION:将多个查询结果合并起来时,系统自动去掉重复元组
UNION ALL:将多个查询结果合并起来时,保留重复元组
待续、更新中
—————————————————————
以上就是今日博客的全部内容了
创作不易,若对您有帮助,可否点赞、关注一二呢,感谢支持.