以大语言模型ChatGLM2-6B为后台,打造个人语音交互机器人Demo
引言
随着以ChatGLM2-6B为代表的开源大型语言模型的兴起,人工智能革命正席卷全球……
ChatGLM2-6B这一代表性的开源大型模型,以其易于部署、适度的参数量和强大的中文处理能力,为个人用户提供了在个人显卡上部署大型模型的便捷途径。
然而,在大型语言模型领域,人机交互仍然主要以传统的文字输入为主,这种方式难以满足人们对实时性和高效率的需求。在许多情景下,人们更期望能够直接与一个语音交互的智能助手互动。
本文将结合STT(自动语音识别)、大型模型和TTS(文本到语音合成)等人工智能技术,创建一个具备语音交互功能的智能机器人演示。
环境准备
- 在开始之前,我们需要准备好开发环境。本文的代码主要采用Python语言编写,建议使用Python版本3.9以上。作者在Windows10操作系统上使用Python 3.9进行了测试。
- 请安装一些python库,主要有:
- 录音库:Pyaudio,及相关音频处理库wave。
- TTS库:edge-tte,一款免费的TTS库。
- 音频播放库:pygame,实现代码播放音频文件。
- openai:调用大语言模型API需要用到。
- uuid:用于生成唯一的文件名。
请参考以下Python库的导入列表,并根据需要使用pip进行安装。
import pyaudio
import wave
import requests
import json
import base64
import os
import edge_tts
import asyncio
import pygame
import openai
import uuid # 用于生成唯一的文件名3. 在百度AI开发平台开通短语识别标准版服务,可以领取免费额度,赠送15万次调用,很香。
短语音识别标准版_短语音识别-百度AI开放平台 (baidu.com)
按照官网给出的操作指引一步一步来就OK了。
提醒:调用百度语音识别API之前一定要先创建应用。
4. 一台可以跑ChatGLM2-6B的服务器或个人电脑。模型的下载、部署这里不做赘述,可以参考网络上的教程。命令行运行ChatGLM2-6B-main目录下面的openai_api.py。
python openai_api.py 运行成功会给出一串地址,后面需要在调用方的主机上ssh这个地址。
具体操作是:
Win+R 打开cmd
输入命令:
ssh -L 8000:0.0.0.0:8000 <你的服务器用户名>@<你的服务器的IP地址>
回车
输入密码:
<你的服务器密码>核心代码
1.录音模块
我们首先使用PyAudio库来录制音频,将其保存为.wav文件。这个步骤包括设置音频参数,如采样频率、数据流块等。录制完成后,音频文件将被保存在当前目录下。代码内有详细注释,请结合注释进一步理解代码。
#1.录音
#用Pyaudio录制音频(生成wav文件)
def audio_record(rec_time,filename):
"""
:param rec_time : 音频录制时间
:param filename : 输出音频文件
:返回值:在当前目录输出一个音频文件
"""
CHUNK=1024 #定义数据流块
FORMAT = pyaudio.paInt16 #16bit编码格式
CHANNELS = 1 #单声道
RATE = 16000 #16000采样频率
#创建一个音频对象
p = pyaudio.PyAudio()
#创建音频数据流
stream = p.open(format=FORMAT,
channels=CHANNELS,
rate=RATE,
input=True,
frames_per_buffer=CHUNK)
print('Start recording...')
frames=list() #空列表用于保存录制的音频流
#录制音频数据
for i in range(0,int(RATE/CHUNK*rec_time)):
data=stream.read(CHUNK)
frames.append(data)
#录制完成
# print(frames)
#停止数据流
stream.stop_stream()
stream.close()
#关闭pyaudio
p.terminate()
print('recording done...')
#保存音频文件
with wave.open(filename,'wb') as f:
f.setnchannels(CHANNELS) #设置音频声道数
f.setsampwidth(p.get_sample_size(FORMAT)) #以字节为样本返回样本宽度
f.setframerate(RATE) #设置采样频率
f.writeframes(b''.join(frames))
f.close()2.获取百度ASR access token
为了进行语音识别,我们需要获取百度语音识别的Access Token。这个Token用于访问百度的语音识别API。您需要提供API_KEY和SECRET_KEY,然后使用这些密钥生成Access Token。
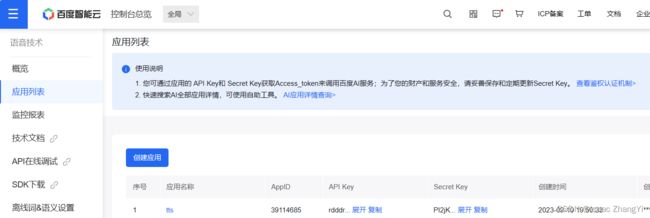
如何查看自己的API_KEY和SECRET_KEY?登录百度AI开放平台,选择应用列表即可查看。
此函数向百度服务器发送API_KEY和SECRET_KEY,返回access token,用于识别对应的服务和用户。
API_KEY = "XXX" # 这里请替换为你的API_KEY
SECRET_KEY = "XXX" # 这里请替换为你的SECRET_KEY
def get_access_token():
"""
使用 AK,SK 生成鉴权签名(Access Token)
:return: access_token,或是None(如果错误)
"""
url = "https://aip.baidubce.com/oauth/2.0/token"
params = {"grant_type": "client_credentials", "client_id": API_KEY, "client_secret": SECRET_KEY}
return str(requests.post(url, params=params).json().get("access_token"))3.调用百度ASR API,上传录音文件,获得转换后的文本。
使用获取的Access Token,我们将录音文件上传到百度语音识别API,以将音频转换为文本。这里需要设置一些参数,如采样频率、格式等。最终,我们将获得从录音中识别出的文本。
# 3.上传录音文件
def BaiduYuYin(file_url,token):
"""
:param file_url: 录音文件路径
:param token: 获取的access token
:return: 录音识别出来的文本
"""
try:
RATE='16000'
FORMAT='wav'
CUID='rvs7K414cquxm4f62jtasIRi6iNRNXR6'
DEV_PID='1536' # 普通话,支持简单的英文识别
file_url=file_url
token=token
#以字节格式读取文件之后进行编码
with open(file_url,'rb') as f:
speech=base64.b64encode(f.read()).decode('utf-8')
size = os.path.getsize(file_url)# 语音文件的字节数
headers={'Content-Type':'application/json',
'Accept':'application/json'} # json格式post上传本地文件
url='https://vop.baidu.com/server_api'
data={
"format":FORMAT,#格式
"rate":RATE,#取样频率,固定值16000
"dev_pid":DEV_PID,#语音识别类型
"speech":speech,#本地语音文件的二进制数据,需要进行base64编码
"cuid":CUID,#用户唯一标识,用来区分用户 建议填写能区分用户的机器MAC地址或IMEI码,长度为60字符以内。
"len":size,#语音文件的字节数
"channel":1,#声道数,仅支持单声道,固定值为1
"token":token,
}
req=requests.request("POST",url,data=json.dumps(data),headers=headers) #request.post 改为requests.request("POST"……)
data_dict=json.loads(req.text)
# print(data_dict['result'][0])
return data_dict['result'][0] # 返回文本
except:
return '识别不清楚'4.调用大语言模型的API,实现问答。
我们使用ChatGLM2-6B大语言模型来生成回复文本。在这一步中,我们向模型提供之前识别的文本,然后等待模型生成回复。
# 4.接入大语言模型
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv()) # read local .env file
os.environ['OPENAI_API_KEY'] = 'EMPTY'
os.environ['OPENAI_API_BASE'] = 'http://localhost:8000/v1'
openai.api_key = 'none'
openai.api_base = 'http://localhost:8000/v1'
def get_completion(prompt, model="gpt-3.5-turbo"):
"""
:param prompt:输入提示词
:param model:模型名称(使用默认参数即可)
:return: 大模型的回复文本
"""
messages = [{"role": "user", "content": prompt}]
response = openai.ChatCompletion.create(
model=model,
messages=messages,
temperature=0,
)
return response.choices[0].message["content"]
5. 文本转语音TTS
将生成的文本转换为语音,我们使用edge_tts库。这个库可以将文本转换为语音文件(.mp3格式)。可以选择不同的语音和参数,以获得不同风格的语音。
# 5.文本转语音TTS:edge-tts
async def generate_audio_from_text(text,file_url):
"""
:param text:需要进行转换的文本
:file_url:转换后输出的音频文件地址
:return:无
"""
voice = 'zh-CN-YunxiNeural'
output = file_url
rate='-4%'
volume = '+0%'
tts = edge_tts.Communicate(text=text,voice=voice,rate=rate,volume=volume)
await tts.save(output)注意,调用此函数时,要使用asyncio.run:
#调用示例
asyncio.run(generate_audio_from_text(model_response,filename))6.播放音频文件
最后,我们使用pygame库来播放生成的语音文件。这使得大模型的回复能够以声音的方式呈现给用户。
# 6.播放音频文件:pygame
def play_mp3(mp3_file):
"""
:param mp3_file:需要播放的录音文件地址
:return:无
"""
pygame.init() # 初始化pygame
pygame.mixer.init() # 初始化音频混合器
pygame.mixer.music.load(mp3_file) # 加载指定MP3文件
pygame.mixer.music.play() # 播放
clock = pygame.time.Clock()
while pygame.mixer.music.get_busy(): # 使用一个循环来等待音频播放完毕,保证程序不会在播放结束前退出
clock.tick(3)7.整体的函数调度顺序
如何运行?
要运行这个语音交互demo,只需运行main()函数。等待您的发言,然后进行录音、语音识别、文本生成、语音合成和播放,最后询问是否继续对话或退出。
def main():
while True:
# 1. 提示用户发言
print('请发言,谢谢!')
# 2. 录制音频
audio_record(5, 'user_audio.wav')
print('Audio recording complete.')
# 3. 获取百度语音识别的access token
baidu_token = get_access_token()
print('Baidu access token obtained.')
# 4. 上传录音文件并进行语音识别
baidu_result = BaiduYuYin('user_audio.wav', baidu_token)
print('Baidu speech recognition result:', baidu_result)
# 5. 调用大语言模型进行文本生成
model_response = get_completion(baidu_result)
print('Model response:', model_response)
# 6. 将文本转换为语音,保存到唯一的文件名
unique_audio_filename = str(uuid.uuid4()) + '.mp3' # 保存为不同的文件名以避免访问冲突
asyncio.run(generate_audio_from_text(model_response,unique_audio_filename))
# 7. 播放生成的语音
play_mp3(unique_audio_filename)
# 8. 提示用户继续对话或退出
user_input = input('继续对话或输入"退出"退出: ')
if user_input == '退出':
break
注意,为了避免多轮对话产生的文件访问冲突,请为TTS转换后的音频文件设置不同的文件名,这里使用了uuid库为每个音频文件生成唯一的文件名。
运行结果:

完整代码:
import pyaudio
import wave
import requests
import json
import base64
import os
import edge_tts
import asyncio
import pygame
import openai
import uuid # 用于生成唯一的文件名
#1.录音
#用Pyaudio录制音频(生成wav文件)
def audio_record(rec_time,filename):
"""
:param rec_time : 音频录制时间
:param filename : 输出音频文件
:返回值:在当前目录输出一个音频文件
"""
CHUNK=1024 #定义数据流块
FORMAT = pyaudio.paInt16 #16bit编码格式
CHANNELS = 1 #单声道
RATE = 16000 #16000采样频率
#创建一个音频对象
p = pyaudio.PyAudio()
#创建音频数据流
stream = p.open(format=FORMAT,
channels=CHANNELS,
rate=RATE,
input=True,
frames_per_buffer=CHUNK)
print('Start recording...')
frames=list() #空列表用于保存录制的音频流
#录制音频数据
for i in range(0,int(RATE/CHUNK*rec_time)):
data=stream.read(CHUNK)
frames.append(data)
#录制完成
# print(frames)
#停止数据流
stream.stop_stream()
stream.close()
#关闭pyaudio
p.terminate()
print('recording done...')
#保存音频文件
with wave.open(filename,'wb') as f:
f.setnchannels(CHANNELS) #设置音频声道数
f.setsampwidth(p.get_sample_size(FORMAT)) #以字节为样本返回样本宽度
f.setframerate(RATE) #设置采样频率
f.writeframes(b''.join(frames))
f.close()
#2 获取token
API_KEY = "XXX" # 这里请替换为你的API_KEY
SECRET_KEY = "XXX" # 这里请替换为你的SECRET_KEY
def get_access_token():
"""
使用 AK,SK 生成鉴权签名(Access Token)
:return: access_token,或是None(如果错误)
"""
url = "https://aip.baidubce.com/oauth/2.0/token"
params = {"grant_type": "client_credentials", "client_id": API_KEY, "client_secret": SECRET_KEY}
return str(requests.post(url, params=params).json().get("access_token"))
# 3.上传录音文件
def BaiduYuYin(file_url,token):
"""
:param file_url: 录音文件路径
:param token: 获取的access token
:return: 录音识别出来的文本
"""
try:
RATE='16000'
FORMAT='wav'
CUID='rvs7K414cquxm4f62jtasIRi6iNRNXR6'
DEV_PID='1536' # 普通话,支持简单的英文识别
file_url=file_url
token=token
#以字节格式读取文件之后进行编码
with open(file_url,'rb') as f:
speech=base64.b64encode(f.read()).decode('utf-8')
size = os.path.getsize(file_url)# 语音文件的字节数
headers={'Content-Type':'application/json',
'Accept':'application/json'} # json格式post上传本地文件
url='https://vop.baidu.com/server_api'
data={
"format":FORMAT,#格式
"rate":RATE,#取样频率,固定值16000
"dev_pid":DEV_PID,#语音识别类型
"speech":speech,#本地语音文件的二进制数据,需要进行base64编码
"cuid":CUID,#用户唯一标识,用来区分用户 建议填写能区分用户的机器MAC地址或IMEI码,长度为60字符以内。
"len":size,#语音文件的字节数
"channel":1,#声道数,仅支持单声道,固定值为1
"token":token,
}
req=requests.request("POST",url,data=json.dumps(data),headers=headers) #request.post 改为requests.request("POST"……)
data_dict=json.loads(req.text)
# print(data_dict['result'][0])
return data_dict['result'][0] # 返回文本
except:
return '识别不清楚'
# 4.接入大语言模型
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv()) # read local .env file
os.environ['OPENAI_API_KEY'] = 'EMPTY'
os.environ['OPENAI_API_BASE'] = 'http://localhost:8000/v1'
openai.api_key = 'none'
openai.api_base = 'http://localhost:8000/v1'
def get_completion(prompt, model="gpt-3.5-turbo"):
"""
:param prompt:输入提示词
:param model:模型名称(使用默认参数即可)
:return: 大模型的回复文本
"""
messages = [{"role": "user", "content": prompt}]
response = openai.ChatCompletion.create(
model=model,
messages=messages,
temperature=0,
)
return response.choices[0].message["content"]
# 5.文本转语音TTS:edge-tts
async def generate_audio_from_text(text,file_url):
"""
:param text:需要进行转换的文本
:file_url:转换后输出的音频文件地址
:return:无
"""
voice = 'zh-CN-YunxiNeural'
output = file_url
rate='-4%'
volume = '+0%'
tts = edge_tts.Communicate(text=text,voice=voice,rate=rate,volume=volume)
await tts.save(output)
# 6.播放音频文件:pygame
def play_mp3(mp3_file):
"""
:param mp3_file:需要播放的录音文件地址
:return:无
"""
pygame.init() # 初始化pygame
pygame.mixer.init() # 初始化音频混合器
pygame.mixer.music.load(mp3_file) # 加载指定MP3文件
pygame.mixer.music.play() # 播放
clock = pygame.time.Clock()
while pygame.mixer.music.get_busy(): # 使用一个循环来等待音频播放完毕,保证程序不会在播放结束前退出
clock.tick(3)
def main():
while True:
# 1. 提示用户发言
print('请发言,谢谢!')
# 2. 录制音频
audio_record(5, 'user_audio.wav')
print('Audio recording complete.')
# 3. 获取百度语音识别的access token
baidu_token = get_access_token()
print('Baidu access token obtained.')
# 4. 上传录音文件并进行语音识别
baidu_result = BaiduYuYin('user_audio.wav', baidu_token)
print('Baidu speech recognition result:', baidu_result)
# 5. 调用大语言模型进行文本生成
model_response = get_completion(baidu_result)
print('Model response:', model_response)
# 6. 将文本转换为语音,保存到唯一的文件名
unique_audio_filename = str(uuid.uuid4()) + '.mp3' # 保存为不同的文件名以避免访问冲突
asyncio.run(generate_audio_from_text(model_response,unique_audio_filename))
# 7. 播放生成的语音
play_mp3(unique_audio_filename)
# 8. 提示用户继续对话或退出
user_input = input('继续对话或输入"退出"退出: ')
if user_input == '退出':
break
if __name__ == "__main__":
main()
局限性
- ChatGLM2-6B的api存在局限性,调用此api只能一问一答,没有记忆性。
- api不能部署到公网上,只能本地访问。运行上面的代码之前,一定要先ssh到运行大模型的服务器上。
结语
看到了这里,你一定是个热爱学习编程的极客,令人钦佩。在这个知识无边界的时代,你的点赞和收藏是我创作的最大动力。让我们携手前行,探索更多的学习和创新,为共同的热爱努力,因为在知识的海洋里,我们永不止步,共同谱写着学习的精彩篇章。感谢你的支持!点赞、收藏!