2.Kafka入门
快速启动
运行kafka需要使用Zookeeper,所以需要先启动Zookeeper,如果没有Zookeeper,可以使用kafka自带打包和配置好的Zookeeper。
zookeeper基本概念
zookeeper在Kafka中的作用
单机模式
1.启动zk
linux中单一个& 符号,且放在完整指令列的最后端,即表示将该指令列放入后台中工作。
bin/zookeeper-server-start.sh config/zookeeper.properties &
查询是否启动,如果有返回说明启动成功
ps -aux|grep zookeeper
2.启动kafka
首先配置Kafka配置文件/conf/server.properties。主要关注以下几个配置参数即可:
# broker的编号,如果集群中有多个broker,则每个broker的编号需要设置的不同
broker.id=0
# broker对外提供的服务入口地址
listeners=PLAINTEXT://localhost:9092
# 存放消息日志文件的地址
log.dirs=/tmp/kafka-logs
# Kafka所需的ZooKeeper集群地址,为了方便演示,我们假设Kafka和ZooKeeper都安装在本机
zookeeper.connect=localhost:2181/kafka
如果是单机模式,那么修改完上述配置参数之后就可以启动服务。如果是集群模式,那么只需要对单机模式的配置文件做相应的修改即可:确保集群中每个 broker 的 broker.id 配置参数的值不一样,以及 listeners 配置参数也需要修改为与 broker 对应的IP地址或域名,之后就可以各自启动服务。注意,在启动 Kafka 服务之前同样需要确保 zookeeper.connect 参数所配置的 ZooKeeper 服务已经正确启动,如果是多个zookeeper集群那么zookeeper.connect值用","隔开
bin/kafka-server-start.sh config/server.properties &
&符号代表后台启动,运行命令后服务确实后台启动了,但日志会打印在控制台,而且关掉命令行窗口,服务就会随之停止。解决方法:
sh kafka-server-start.sh ../config/server.properties 1>/dev/null 2>&1 &
其中1>/dev/null 2>&1 是将命令产生的输入和错误都输入到空设备,也就是不输出的意思。
/dev/null代表空设备。
3.创建一个名为“test”的Topic,一个主题一个分区和一个备份:
如果有多个broker,那么Kafka会根据算法将分区以及副本分配到不同的 broker 提高容错和高可用能力
如果有多个 zookeeper 那么–zookeeper 命令后用 逗号隔开地址
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
查看已经创建好的topic信息:
bin/kafka-topics.sh --list --zookeeper localhost:2181
删除主题
bin/kafka-topics.sh --delete --topic test --zookeeper localhost:2181
4.发送消息 消费消息
使用控制台的生产者脚本启动一个命令行模式的生产者,并往指定的主题生产一条消息:
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
按ctrl+c退出消息发送。
使用控制台的消息者脚本启动一个命令行模式的消息者,并从分区的最开始位置开始读取消息 如果需要从头开始接收数据,需要添加–from-beginning参数:
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning
打印出的消息为生产者输入的消息

4.创建多个分区,然后使用describe命令查看指定主题的详细信息,验证一共有3个分区,并且每个分区都有以下5个属性,一个主题多个分区一个备份
Topic:主题名称,如果没有事先创建主题,Kafka也可以帮我们创建。
Partition:分区编号,从0开始。
Leader:当前分区负责读写的节点,只有主副本才接受消息的读写。
Replicas:分区的复制节点列表,它与主题的副本数量有关,默认只有一个副本,即主副本。
Isr:同步状态的副本,是Replicas的子集,必须是存活的,并且都能赶上主副本。
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 3 --test2
使用describe命令查看指定主题的详细信息
bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic test
输出解释:第一行是所有分区的摘要,其次,每一行提供一个分区信息,因为我们只有一个分区,所以只有一行。
“leader”:该节点负责该分区的所有的读和写,每个节点的leader都是随机选择的。
“replicas”:备份的节点列表,无论该节点是否是leader或者目前是否还活着,只是显示。
“isr”:“同步备份”的节点列表,也就是活着的节点并且正在同步leader。

bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic test2

5.为了验证消息是否写到主题分区的日志目录中,可以查看日志文件目录,其中以log结尾的文件是二进制的日志格式,可以使用Linux的strings命令查看文件内容。
tmp为根目录的tmp
tree /tmp/kafka-logs/
可以看到,虽然test主题还没有消息产生,但是Kafka已经提前创建好了文件夹和对应文件

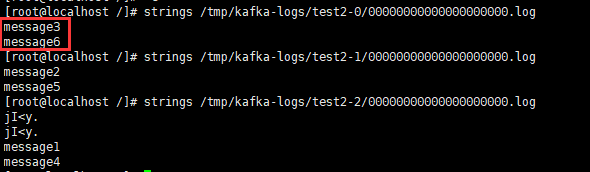
查看test主题已发送的消息
strings /tmp/kafka-logs/test-0/00000000000000000000.log

6.启动一个控制台的生产者,然后往test2主题模拟生产6条消息。
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test2

查看日志文件会发现这6条消息会被均匀的发送到3个分区日志文件中
strings /tmp/kafka-logs/test2-0/00000000000000000000.log

7.读取test2主题的数据,可以发现消息的顺序是不一致的。这是因为,Kafka不保证全局的消息顺序,只保证分区级别的消息顺序。
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test2 --from-beginning

可以看到,每个分区的消息一定是有序的
8.在日志中查看主题分区偏移量
/tmp/kafka-logs目录下还会记录所有分区的偏移量全局状态数据,比如检查点(checkpoint)和恢复点(recomver)。这些文件并不在每个分区下,而是在分区的父目录中(因为要记录所有分区,如果在分区目录下,就只能记录当前分区状态)。
recovery-point-offset-checkpoint 负责记录topic已经被写入磁盘的offset
replication-offset-checkpoint 负责记录已经被复制到别的topic上的文件
test2中,因为新加入了两个数据,所以1分区检查点偏移量为2,0和2分区检查点偏移量为3;test只有1个分区,检查点偏移量为8:
cat /tmp/kafka-logs/replication-offset-checkpoint

恢复点(recomver)都是0
恢复点是异常关闭时用来恢复数据的。如果数据目录下有.kafka_cleanshutdown文件就表示不是异常关闭,就用不上恢复点了。如果上一次关闭时异常关闭的,kafka就会利用checkpoint来修复日志了。
cat /tmp/kafka-logs/recovery-point-offset-checkpoint

集群模式
多个broker+多个zookeeper
1.复制三个配置文件
config/server1.properties:
broker.id=1
listeners=PLAINTEXT://:9092
log.dir=/tmp/kafka-logs-1
config/server2.properties:
broker.id=2
listeners=PLAINTEXT://:9093
log.dir=/tmp/kafka-logs-2
config/server3.properties:
broker.id=3
listeners=PLAINTEXT://:9094
log.dir=/tmp/kafka-logs-3
3.启动三个Kafka
bin/kafka-server-start.sh config/server1.properties &
bin/kafka-server-start.sh config/server2.properties &
bin/kafka-server-start.sh config/server3.properties &
4.创建三个主题,主题副本数都是3,分区数分别是1个、3个和5个
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 --partitions 1 --topic test10
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 --partitions 3 --topic test11
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 --partitions 5 --topic test12
5.查看新建的主题信息 因为副本数为3,所以每个分区都会分布在3个broker上,不同的是每个分区的leader不同
bin/kafka-topics.sh --describe -zookeeper localhost:2181 --topic test10
bin/kafka-topics.sh --describe -zookeeper localhost:2181 --topic test11
bin/kafka-topics.sh --describe -zookeeper localhost:2181 --topic test12

从日志目录也可以看出来

6.测试容错
还是之前环境,新创建个主题,我们来发布一些信息在新的topic上
Leader为3
![]()
发送消息
![]()
现在,消费这些消息。

我们要测试集群的容错,kill掉leader,Broker3作为当前的leader,也就是kill掉Broker3。
ps -ef|grep config/server3.properties

kill -9 3968
Leader变为了2

消费消息,发现消息并未丢失

查看主题 test12 信息,可以看到由于刚刚清掉了原先主副本编号为3的节点,分区的主副本会转移。比如,test12主题的P1分区,主副本原先是3现在是1。另外,虽然每个分区的Replicas没有变化,但是Isr都不在包含3:

重启编号为3的服务器,副本数量不足的分区,它们的Isr都会进行扩展,都会添加上3。服务器挂掉后又重启,分区的主副本并没有变化。为了保证主副本会负载均衡到所有的服务器。可以执行preferred-replica-election脚本来手动执行平衡操作,即选择Replicas的第一个副本作为分区的主副本。比如,分区P1的副本集【3,2,0】,当前的主副本编号为2,那么会将P1分区的主副本从现有的2迁移到3上。
bin/kafka-preferred-replica-election.sh --zookeeper localhost:2181
注意:上面的消费者启动使用的命令是 --bootstrap-server localhost:9092 而在容错这里又使用了 --zookeeper localhost:2181。0.8 以前,消费进度是直接写到 zookeeper 的,consumer 必须知道 zookeeper 的地址。这个方案有性能问题,0.9 的时候整体大改了一次,Brokers 接管了消费进度,consumer 不再需要和 zookeeper 通信了。需要注意的是,如果使用了–bootstrap-server那么会从Kafka的所有节点获取消息,此时如果某个节点挂掉又使用了 --from-beginning 从头开始获取,里面还有消息那么是获取不到的,只能通过zookeeper获取。(–bootstrap-server:通过Kafka节点获取消息,–zookeeper:通过zookeeper获取消息)。
消费组实例
默认的控制台消费者在启动时,都会分配到一个随机的消费组编号,即一个消费组只有一个消费者。为了模拟一个消费组下有多个消费者的情况,通过指定消费者的配置文件,并在配置文件中配置消费组编号,比如这里会设置group.id等于test-consumer-group
新建一个主题 写入3条消息,可以看到如果指定消费组,那么当同一个消费组的消息者读取消息后,重新创建一个消费者是不会重新读取的。但是,如果不指定消费组,那么对于消费者来说就是不同的消费组,消息被重新读取。
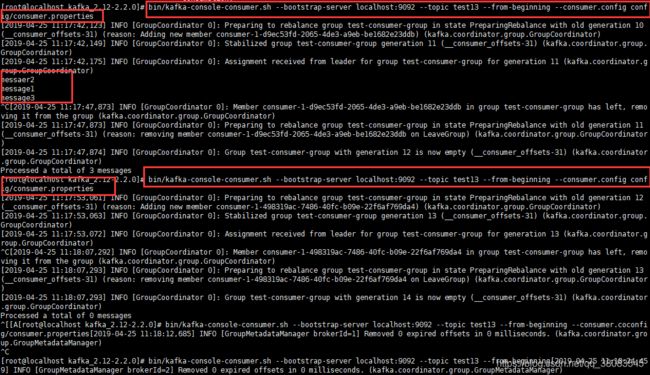

命令查下消费组详情
bin/kafka-consumer-groups.sh --bootstrap-server 172.16.15.89:9092 --describe --group aa

Java客户端
要往Kafka中写入消息 首先要创建一个生产者客户端实例,并设置一些参数。然后构建消息的ProducerRecord对象,其中必须包含所要发往的主题及消息的消息体,进而再通过生产者客户端实例将消息发出,最后可以通close()方法关闭生产者客户端实例并收回相应资源。
//生产者客户端示例代码
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
public class ProducerFastStart {
public static final String brokerList = "localhost:9092";
public static final String topic = "topic-demo";
public static void main(String[] args) {
Properties properties = new Properties();
properties.put("key.serializer",
"org.apache.kafka.common.serialization.StringSerializer");
properties.put("value.serializer",
"org.apache.kafka.common.serialization.StringSerializer");
properties.put("bootstrap.servers", brokerList);
Producer producer = new KafkaProducer<>(props);
try {
producer.send(new ProducerRecord(topic, "hello, Kafka!");
} catch (Exception e) {
e.printStackTrace();
}
producer.close();
}
}
对应消息的消费也比较简单,首先创建一个消费者客户端实例并配置相应的参数,然后订阅主题并消费即可
// 消费者客户端示例代码
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.time.Duration;
import java.util.Arrays;
import java.util.Properties;
public class ConsumerFastStart {
public static final String brokerList = "localhost:9092";
public static final String topic = "topic-demo";
public static final String groupId = "group.demo";
public static void main(String[] args) {
Properties properties = new Properties();
properties.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
properties.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
properties.put("bootstrap.servers", brokerList);
//设置消费组的名称,具体的释义可以参见第3章
properties.put("group.id", groupId);
//创建一个消费者客户端实例
KafkaConsumer consumer = new KafkaConsumer<>(properties);
//订阅主题
consumer.subscribe(Collections.singletonList(topic));
//循环消费消息
while (true) {
ConsumerRecords records =
consumer.poll(Duration.ofMillis(1000));
for (ConsumerRecord record : records) {
System.out.println(record.value());
}
}
}
}
服务端参数配置
下面挑选一些重要的服务端参数来做细致的说明,这些参数都配置在config/server.properties 文件中。
-
zookeeper.connect
该参数指明 broker 要连接的 ZooKeeper 集群的服务地址(包含端口号),没有默认值,且此参数为必填项。可以配置为 localhost:2181,如果 ZooKeeper 集群中有多个节点,则可以用逗号将每个节点隔开,类似于 localhost1:2181,localhost2:2181,localhost3:2181 这种格式。最佳的实践方式是再加一个 chroot 路径,这样既可以明确指明该 chroot 路径下的节点是为 Kafka 所用的,也可以实现多个 Kafka 集群复用一套 ZooKeeper 集群,这样可以节省更多的硬件资源。包含 chroot 路径的配置类似于 localhost1:2181,localhost2:2181,localhost3:2181/kafka 这种,如果不指定 chroot,那么默认使用 ZooKeeper 的根路径。 -
listeners
该参数指明 broker 监听客户端连接的地址列表,即为客户端要连接 broker 的入口地址列表,配置格式为 protocol1://hostname1:port1,protocol2://hostname2:port2,其中 protocol 代表协议类型,Kafka 当前支持的协议类型有 PLAINTEXT、SSL、SASL_SSL 等,如果未开启安全认证,则使用简单的 PLAINTEXT 即可。hostname 代表主机名,port 代表服务端口,此参数的默认值为 null。比如此参数配置为 PLAINTEXT://198.162.0.2:9092,如果有多个地址,则中间以逗号隔开。如果不指定主机名,则表示绑定默认网卡,注意有可能会绑定到127.0.0.1,这样无法对外提供服务,所以主机名最好不要为空;如果主机名是0.0.0.0,则表示绑定所有的网卡。
与此参数关联的还有 advertised.listeners,作用和 listeners 类似,默认值也为 null。不过 advertised.listeners 主要用于 IaaS(Infrastructure as a Service)环境,比如公有云上的机器通常配备有多块网卡,即包含私网网卡和公网网卡,对于这种情况而言,可以设置 advertised.listeners 参数绑定公网IP供外部客户端使用,而配置 listeners 参数来绑定私网IP地址供 broker 间通信使用。
-
broker.id
该参数用来指定 Kafka 集群中 broker 的唯一标识,默认值为-1。如果没有设置,那么 Kafka 会自动生成一个。这个参数还和 meta.properties 文件及服务端参数 broker.id.generation. enable 和 reserved.broker.max.id 有关,相关深度解析可以参考《图解Kafka之核心原理》的相关内容。 -
log.dir和log.dirs
Kafka 把所有的消息都保存在磁盘上,而这两个参数用来配置 Kafka 日志文件存放的根目录。一般情况下,log.dir 用来配置单个根目录,而 log.dirs 用来配置多个根目录(以逗号分隔),但是 Kafka 并没有对此做强制性限制,也就是说,log.dir 和 log.dirs 都可以用来配置单个或多个根目录。log.dirs 的优先级比 log.dir 高,但是如果没有配置 log.dirs,则会以 log.dir 配置为准。默认情况下只配置了 log.dir 参数,其默认值为 /tmp/kafka-logs。 -
message.max.bytes
该参数用来指定 broker 所能接收消息的最大值,默认值为1000012(B),约等于976.6KB。如果 Producer 发送的消息大于这个参数所设置的值,那么(Producer)就会报出 RecordTooLargeException 的异常。如果需要修改这个参数,那么还要考虑 max.request.size(客户端参数)、max.message.bytes(topic端参数)等参数的影响。为了避免修改此参数而引起级联的影响,建议在修改此参数之前考虑分拆消息的可行性。
还有一些服务端参数在本节没有提及,这些参数同样非常重要,它们需要用单独的章节或者场景来描述,比如 unclean.leader.election.enable、log.segment.bytes 等参数都会在后面的章节中提及。