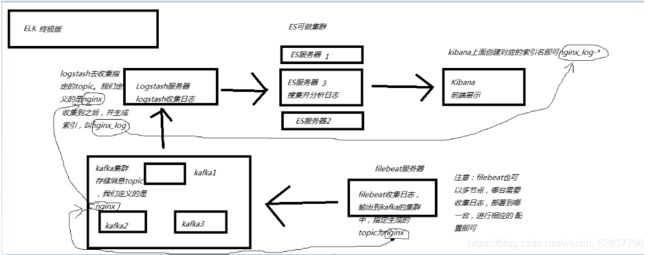
ELK+kafka+filebeat7.8.0监控nginx和tomcat
ELK+kafka+filebeat7.8.0监控nginx和tomcat
环境介绍:
| 安装软件 | 主机名 | IP地址 | 系统版本 |
|---|---|---|---|
| Elasticsearch/kafka | es-kafka | 10.8.161.2 | centos7.4--4G |
| head/Kibana/kafka | head-kibana-kafka | 10.8.161.5 | centos7.4--2G |
| zookeeper/kafka/Logstash | zoo-kafka-logstash | 10.8.161.56 | centos7.4---2G |
实施部署
1、 Elasticsearch部署
软件版本:jdk-8u191-linux-x64.tar.gz、elasticsearch-7.8.0.tar.gz
1、安装配置jdk8
es运行依赖jdk8
[root@mes-1 ~]# tar xzf jdk-8u191-linux-x64.tar.gz -C /usr/local/
[root@mes-1 ~]# cd /usr/local/
[root@mes-1 local]# mv jdk1.8.0_191/ java
[root@mes-1 local]# echo '
JAVA_HOME=/usr/local/java
PATH=$JAVA_HOME/bin:$PATH
export JAVA_HOME PATH
' >>/etc/profile
[root@mes-1 ~]# source /etc/profile
[root@mes-1 local]# java -version
java version "1.8.0_211"
Java(TM) SE Runtime Environment (build 1.8.0_211-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.211-b12, mixed mode)2、安装配置ES----只在第一台操作操作下面的部分
(1)创建运行ES的普通用户--默认不让root登录
[root@mes-1 ~]# useradd elsearch
[root@mes-1 ~]# echo "123456" | passwd --stdin "elsearch"
(2)安装配置ES
[root@mes-1 ~]# tar xzf elasticsearch-7.8.0.tar.gz -C /usr/local/
[root@mes-1 ~]# cd /usr/local/elasticsearch-7.8.0/config/
[root@mes-1 config]# ls
elasticsearch.yml log4j2.properties roles.yml users_roles
jvm.options role_mapping.yml users
[root@mes-1 config]# cp elasticsearch.yml elasticsearch.yml.bak
[root@mes-1 config]# vim elasticsearch.yml ----找个地方添加如下内容
cluster.name: elk
node.name: elk01
node.master: true #es集群(三台),只需有一个主节点就好
node.data: true #es集群,只需要有两个记录日志
path.data: /data/elasticsearch/data
path.logs: /data/elasticsearch/logs
bootstrap.memory_lock: false
bootstrap.system_call_filter: false
network.host: 0.0.0.0
http.port: 9200
#做es集群时需要打开心跳检测
#discovery.zen.ping.unicast.hosts: ["10.8.161.2", "10.8.161.5","10.8.161.56"] #es集群的IP地址,ping 心跳检测
#discovery.zen.minimum_master_nodes: 2 #es集群的主节点数
#discovery.zen.ping_timeout: 150s #心跳检测的超时时间
#discovery.zen.fd.ping_retries: 10 #心跳检测失败,重试的次数
#client.transport.ping_timeout: 60s #客户端连接的超时时间
http.cors.enabled: true
http.cors.allow-origin: "*"
#最后两行复制上后会自动被注释,需要删掉注释符号
cluster.initial_master_nodes: ["elk01"] #7.8版本需要加上
即为:
cluster.name: elk
node.name: elk01
node.master: true
node.data: true
path.data: /data/elasticsearch/data
path.logs: /data/elasticsearch/logs
bootstrap.memory_lock: false
bootstrap.system_call_filter: false
network.host: 0.0.0.0
http.port: 9200
#discovery.zen.ping.unicast.hosts: ["*"]
##discovery.zen.minimum_master_nodes: 2
##discovery.zen.ping_timeout: 150s
##discovery.zen.fd.ping_retries: 10
##client.transport.ping_timeout: 60s
http.cors.enabled: true
http.cors.allow-origin: "*"
cluster.initial_master_nodes: ["elk01"]
配置项含义:
cluster.name 集群名称,各节点配成相同的集群名称。
node.name 节点名称,各节点配置不同。
node.master 指示某个节点是否符合成为主节点的条件。是否为主节点
node.data 指示节点是否为数据节点。数据节点包含并管理索引的一部分。是否存放数据
path.data 数据存储目录。 需要创建该目录
path.logs 日志存储目录。
bootstrap.memory_lock 内存锁定,是否禁用交换。内存不够用时,会使用交换分区,不能禁用
bootstrap.system_call_filter 系统调用过滤器。
network.host 绑定节点IP。
http.port 端口。
discovery.zen.ping.unicast.hosts 提供其他 Elasticsearch 服务节点的单点广播发现功能。
discovery.zen.minimum_master_nodes 集群中可工作的具有Master节点资格的最小数量,官方的推荐值是(N/2)+1,其中N是具有master资格的节点的数量。
discovery.zen.ping_timeout 节点在发现过程中的等待时间。
discovery.zen.fd.ping_retries 节点发现重试次数。
http.cors.enabled 是否允许跨源 REST 请求,表示支持所有域名,用于允许head插件访问ES。 查看ES集群中数据(索引)需要用head插件
http.cors.allow-origin 允许的源地址。可写固定的IP
(3)设置JVM堆大小
[root@mes-1 config]# vim jvm.options ----将
-Xms1g ----修改成 -Xms2g
-Xmx1g ----修改成 -Xms2g
或者:
推荐设置为4G,请注意下面的说明:改成物理内存大小的一半
sed -i 's/-Xms1g/-Xms4g/' /usr/local/elasticsearch-6.5.4/config/jvm.options
sed -i 's/-Xmx1g/-Xmx4g/' /usr/local/elasticsearch-6.5.4/config/jvm.options注意: 确保堆内存最小值(Xms)与最大值(Xmx)的大小相同,防止程序在运行时改变堆内存大小。 堆内存大小不要超过系统内存的50%
(4)创建ES数据及日志存储目录
[root@mes-1 ~]# mkdir -p /data/elasticsearch/data (/data/elasticsearch)
[root@mes-1 ~]# mkdir -p /data/elasticsearch/logs (/log/elasticsearch)(5)修改安装目录及存储目录权限
[root@mes-1 ~]# chown -R elsearch.elsearch /data/elasticsearch #递归修改
[root@mes-1 ~]# chown -R elsearch:elsearch /usr/local/elasticsearch-6.5.4 #es安装目录3、系统优化
(1)增加最大文件打开数
永久生效方法:
echo "* - nofile 65536" >> /etc/security/limits.conf
(2)增加最大进程数
[root@mes-1 ~]# vim /etc/security/limits.conf ---在文件最后面添加如下内容
* soft nofile 65536
* hard nofile 131072
* soft nproc 2048
* hard nproc 4096
更多的参数调整可以直接用这个
解释:
soft xxx : 代表警告的设定,可以超过这个设定值,但是超过后会有警告。继续会处理
hard xxx : 代表严格的设定,不允许超过这个设定的值。超出后不处理
nofile : 是每个进程可以打开的文件数的限制
nproc : 是操作系统级别对每个用户创建的进程数的限制(3)增加最大内存映射数(调整使用交换分区的设置)
永久修改:
[root@mes-1 ~]# vim /etc/sysctl.conf ---添加如下
vm.max_map_count=262144 #elasticsearch用户拥有的内存权限太小,至少需要262144;
vm.swappiness=0 #表示最大限度使用物理内存,在内存不足的情况下(内存用完),然后才是swap空间
[root@mes-1 ~]# sysctl -p
# vm.swappiness=100的时候表示积极的使用swap分区,并且把内存上的数据及时的搬运到swap空间里面。生效配置文件中的设置
或者:
临时修改:
[root@mes-1 ~]# sysctl -w vm.max_map_count=262144
增大用户使用内存的空间(临时)启动如果报下列错误
memory locking requested for elasticsearch process but memory is not locked
elasticsearch.yml文件
bootstrap.memory_lock : false
/etc/sysctl.conf文件
vm.swappiness=0
错误:
max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536]
意思是elasticsearch用户拥有的客串建文件描述的权限太低,至少需要65536个
解决:
切换到root用户下面,
vim /etc/security/limits.conf
在最后添加
* hard nofile 65536
* hard nofile 65536
重新启动elasticsearch,还是无效?
必须重新登录启动elasticsearch的账户才可以,例如我的账户名是elasticsearch,退出重新登录。
另外*也可以换为启动elasticsearch的账户也可以,* 代表所有,其实比较不合适
启动还会遇到另外一个问题,就是
max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
意思是:elasticsearch用户拥有的内存权限太小了,至少需要262114。这个比较简单,也不需要重启,直接执行
# sysctl -w vm.max_map_count=262144
就可以了
4、启动ES
[root@mes-1 ~]# su - elsearch
Last login: Sat Aug 3 19:48:59 CST 2020 on pts/0
[root@mes-1 ~]$ cd /usr/local/elasticsearch-6.5.4/
[root@mes-1 elasticsearch-7.8.0]$ ./bin/elasticsearch #先启动看看报错不,需要多等一会 看是否可正常启动
用Ctrl+C终止
终止之后
[root@mes-1 elasticsearch-7.8.0]$ nohup ./bin/elasticsearch & #放后台启动,关了终端也不会有影响
[1] 11462
nohup: ignoring input and appending output to ‘nohup.out’
[root@mes-1 elasticsearch-7.8.0]$ tail -f nohup.out #看一下是否启动 用了nohup,在当前也会出现日志
或者:
su - elsearch -c "cd /usr/local/elasticsearch-7.8.0 && nohup bin/elasticsearch &"
测试:浏览器访问
cluster_uuid 显示出来--->启动成功
5.安装配置head监控插件(Web前端)----只需要安装一台就可以了。10.8.161.5
1)安装node
此处版本号可不做要求
[root@es-3-head-kib ~]# wget https://npm.taobao.org/mirrors/node/latest-v4.x/node-v4.4.7-linux-x64.tar.gz
[root@es-3-head-kib ~]# tar -zxf node-v4.4.7-linux-x64.tar.gz –C /usr/local
[root@es-3-head-kib ~]# vim /etc/profile #添加如下变量
NODE_HOME=/usr/local/node-v4.4.7-linux-x64
PATH=$NODE_HOME/bin:$PATH
export NODE_HOME PATH
[root@es-3-head-kib ~]# source /etc/profile
[root@es-3-head-kib ~]# node --version #检查node版本号
v4.4.7(2)下载head插件
[root@es-3-head-kib ~]# wget https://github.com/mobz/elasticsearch-head/archive/master.zip
[root@es-3-head-kib ~]# cp master.zip /usr/local/
[root@es-3-head-kib ~]# yum -y install unzip
[root@es-3-head-kib ~]# cd /usr/local
[root@es-3-head-kib ~]# unzip master.zip(3)安装grunt
[root@es-3-head-kib ~]# cd elasticsearch-head-master/
[root@mes-3-head-kib elasticsearch-head-master]# npm install -g grunt-cli #时间会很长
[root@es-3-head-kib elasticsearch-head-master]# grunt --version #检查grunt版本号
grunt-cli v1.3.2
(4)修改head源码
[root@es-3-head-kib elasticsearch-head-master]# vim /usr/local/elasticsearch-head-master/Gruntfile.js (95左右)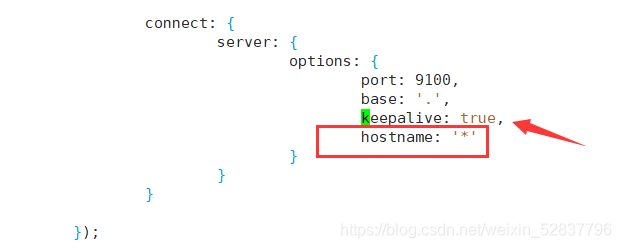
添加hostname,注意在上一行末尾添加逗号,hostname 不需要添加逗号
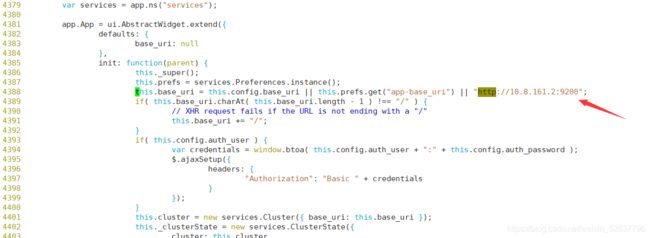
[root@es-3-head-kib elasticsearch-head-master]# vim /usr/local/elasticsearch-head-master/_site/app.js (4359左右)如果在一台机器上面可以不修改下面的操作。保持原来的就可以了
如果是集群需要修改如下信息:改为es的IP地址,集群的话加上主节点IP地址即可
原本是http://localhost:9200 ,如果head和ES不在同一个节点,注意修改成ES的IP地址
(5)下载head必要的文件
[root@es-3-head-kib ~]# wget https://github.com/Medium/phantomjs/releases/download/v2.1.1/phantomjs-2.1.1-linux-x86_64.tar.bz2
[root@es-3-head-kib ~]# yum -y install bzip2
[root@es-3-head-kib ~]# tar -jxf phantomjs-2.1.1-linux-x86_64.tar.bz2 -C /tmp/ #解压(6)运行head
[root@es-3-head-kib ~]# cd /usr/local/elasticsearch-head-master/
[root@es-3-head-kib ~]# npm config set registry https://registry.npm.taobao.org #配置淘宝的npm源地址
[root@es-3-head-kib elasticsearch-head-master]# npm install
...
[email protected] node_modulees/grunt-contrib-jasmine
├── [email protected]
├── [email protected]
├── [email protected]
├── [email protected] ([email protected], [email protected], [email protected], [email protected], [email protected])
├── [email protected]
├── [email protected] ([email protected])
└── [email protected] ([email protected], [email protected], [email protected], phan
[root@es-3-head-kib elasticsearch-head-master]#
[root@es-3-head-kib elasticsearch-head-master]# tail -f nohup.out
Running "connect:server" (connect) task
Waiting forever...
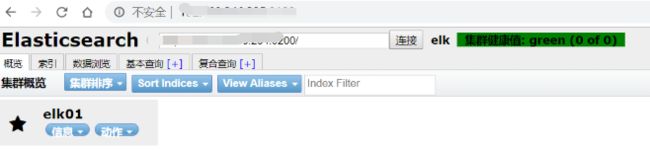
Started connect web server on http://localhost:9100(7)测试
访问 :10.8.161.8.5:9100
2、 Kibana部署
1. 安装配置Kibana
(1)安装
[root@es-3-head-kib ~]# tar zvxf kibana-7.8.0-linux-x86_64.tar.gz -C /usr/local/(2)配置
[root@es-3-head-kib ~]# cd /usr/local/kibana-6.5.4-linux-x86_64/config/
[root@es-3-head-kib config]# vim kibana.yml
server.port: 5601
server.host: "10.8.161.5"
server.name: "kibana"
elasticsearch.hosts: ["http://10.8.161.2:9200"] #ES主节点地址+端口(7.8版本写法)
kibana.index: ".kibana"配置项含义:
server.port kibana 服务端口,默认5601
server.host kibana 主机IP地址,默认localhost
elasticsearch.url 用来做查询的ES节点的URL,默认http://localhost:9200
kibana.index kibana在Elasticsearch中使用索引来存储保存的searches, visualizations和dashboards,默认.kibana
(3)启动
[root@es-3-head-kib config]# cd ..
7.8版本启动
[root@es-3-head-kib kibana-6.5.4-linux-x86_64]# nohup ./bin/kibana --allow-root &
[root@es-3-head-kib kibana-6exit.5.4-linux-x86_64]# nohup: ignoring input and appending output to ‘nohup.out’
2. 安装配置Nginx反向代理
(1)配置YUM源:
[root@es-3-head-kib ~]# rpm -ivh http://nginx.org/packages/centos/7/noarch/RPMS/nginx-release-centos-7-0.el7.ngx.noarch.rpm(2)安装:
[root@es-3-head-kib ~]# yum install -y nginx (3)配置反向代理 ,此处对head配置的反向代理并未生效
[root@es-3-head-kib ~]# cd /etc/nginx/conf.d/
[root@es-3-head-kib conf.d]# cp default.conf nginx.conf
[root@es-3-head-kib conf.d]# mv default.conf default.conf.bak
[root@es-3-head-kib conf.d]# vim nginx.conf
[root@es-3-head-kib conf.d]# cat nginx.confserver {
listen 80;
server_name 10.8.161.5;
location / {
proxy_pass http://10.8.161.5:5601;
proxy_set_header Host $host:5601;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header Via "nginx";
}
location /status {
stub_status on; #开启网站监控状态
access_log /var/log/nginx/kibana_status.log; #监控日志
auth_basic "NginxStatus"; }
location /head/{
proxy_pass http://10.8.161.5:9100;
proxy_set_header Host $host:9100;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header Via "nginx";
}
}
(4)配置nginx
1.将原来的log_format注释掉,添加json格式的配置信息,如下:
[root@es-3-head-kib conf.d]# vim /etc/nginx/nginx.conf
log_format json '{"@timestamp":"$time_iso8601",'
'"@version":"1",'
'"client":"$remote_addr",'
'"url":"$uri",'
'"status":"$status",'
'"domain":"$host",'
'"host":"$server_addr",'
'"size":$body_bytes_sent,'
'"responsetime":$request_time,'
'"referer": "$http_referer",'
'"ua": "$http_user_agent"'
'}';
2.引用定义的json格式的日志:
access_log /var/log/nginx/access_json.log json;(5)启动nginx
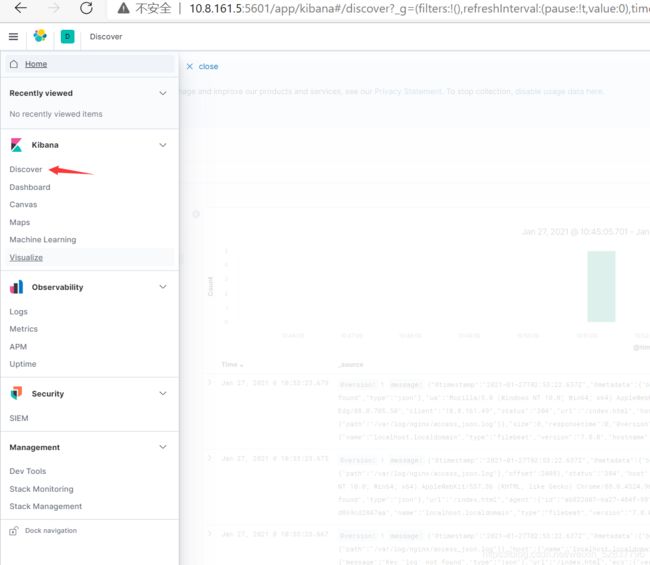
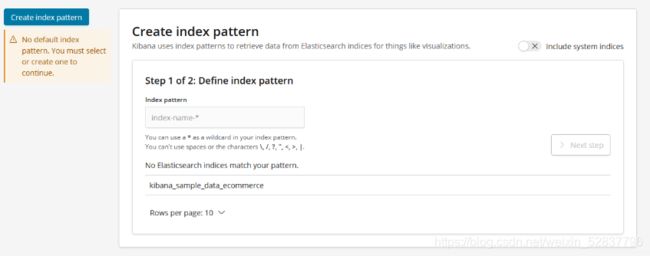
[root@es-3-head-kib ~]# systemctl start nginx浏览器访问http://10.8.161.5 刚开始没有任何数据,会提示你创建新的索引。
若kibana启用失败,可尝试先关闭kibana
再将head页面的

删除
再启用kibana
3、 Logstash部署----10.8.161.56
1.安装配置Logstash
Logstash运行同样依赖jdk,需要配置jdk环境
[root@es-2-zk-log ~]# tar -xvzf jdk-8u211-linux-x64.tar.gz -C /usr/local/
[root@es-2-zk-log ~]# cd /usr/local/
[root@es-2-zk-log ~]# mv jdk1.8.0_211/ java
[root@es-2-zk-log ~]# vim /etc/profile
[root@es-2-zk-log elk_packages]# tail -3 /etc/profile
JAVA_HOME=/usr/local/java
PATH=$JAVA_HOME/bin:$PATH
export JAVA_HOME PATH(1)安装
[root@es-2-zk-log ~]# tar xvzf logstash-6.5.4.tar.gz -C /usr/local/(2)配置
创建目录,我们将所有input、filter、output配置文件全部放到该目录中。
1.安装nginx:
[root@es-2-zk-log ~]# rpm -ivh http://nginx.org/packages/centos/7/noarch/RPMS/nginx-release-centos-7-0.el7.ngx.noarch.rpm
[root@es-2-zk-log ~]# yum install -y nginx
将原来的日志格式注释掉定义成json格式:
[root@es-2-zk-log conf.d]# vim /etc/nginx/nginx.conf
log_format json '{"@timestamp":"$time_iso8601",'
'"@version":"1",'
'"client":"$remote_addr",'
'"url":"$uri",'
'"status":"$status",'
'"domain":"$host",'
'"host":"$server_addr",'
'"size":$body_bytes_sent,'
'"responsetime":$request_time,'
'"referer": "$http_referer",'
'"ua": "$http_user_agent"'
'}';
2.引用定义的json格式的日志:
access_log /var/log/nginx/access_json.log json;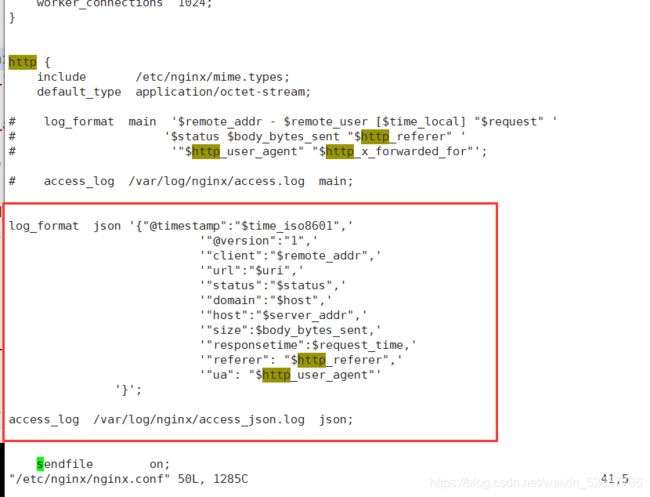
监控nginx和tomcat服务
给nginx和Tomcat定义不同的topic
分别定义索引为nginxqf和tomcatqf
[root@es-2-zk-log ~]# systemctl start nginx
[root@es-2-zk-log ~]# systemctl enable nginx
浏览器多访问几次
[root@es-2-zk-log ~]# mkdir -p /usr/local/logstash-6.5.4/etc/conf.d
[root@es-2-zk-log ~]# cd /usr/local/logstash-6.5.4/etc/conf.d/
#可定义名字为nginx.conf
[root@es-2-zk-log conf.d]# vim nginx.conf #---在下面添加
input{
kafka{
type => "nginxqf"
# codec => "json
topics => "nginx"
# decorate_events => true
bootstrap_servers => "10.8.161.2:9092, 10.8.161.5:9092, 10.8.161.56:9092"
}
kafka{
type => "tomcatqf"
codec => "json"
topics => "tomcat"
# decorate_events => true
bootstrap_servers => "10.8.161.2:9092, 10.8.161.5:9092, 10.8.161.56:9092"
}
}
output{
elasticsearch {
hosts => ["10.8.161.2:9200"]
index => ["%{type}-%{+YYYY.MM.dd}"]
}
}
启动:
[root@es-2-zk-log conf.d]# cd /usr/local/logstash-7.8.0/
[root@es-2-zk-log logstash-7.8.0]# nohup bin/logstash -f etc/conf.d/ --config.reload.automatic &查看日志的出现
[root@es-2-zk-log logstash-7.8.0]# tail -f nohup.out
[2019-08-04T01:39:24,671][INFO ][logstash.outputs.elasticsearch] Attempting to install template {:manage_template=>{"template"=>"logstash-*", "version"=>60001, "settings"=>{"index.refresh_interval"=>"5s"}, "mappings"=>{"_default_"=>{"dynamic_templates"=>[{"message_field"=>{"path_match"=>"message", "match_mapping_type"=>"string", "mapping"=>{"type"=>"text", "norms"=>false}}}, {"string_fields"=>{"match"=>"*", "match_mapping_type"=>"string", "mapping"=>{"type"=>"text", "norms"=>false, "fields"=>{"keyword"=>{"type"=>"keyword", "ignore_above"=>256}}}}}], "properties"=>{"@timestamp"=>{"type"=>"date"}, "@version"=>{"type"=>"keyword"}, "geoip"=>{"dynamic"=>true, "properties"=>{"ip"=>{"type"=>"ip"}, "location"=>{"type"=>"geo_point"}, "latitude"=>{"type"=>"half_float"}, "longitude"=>{"type"=>"half_float"}}}}}}}}在浏览器中访问本机的nginx和tomcat的网站
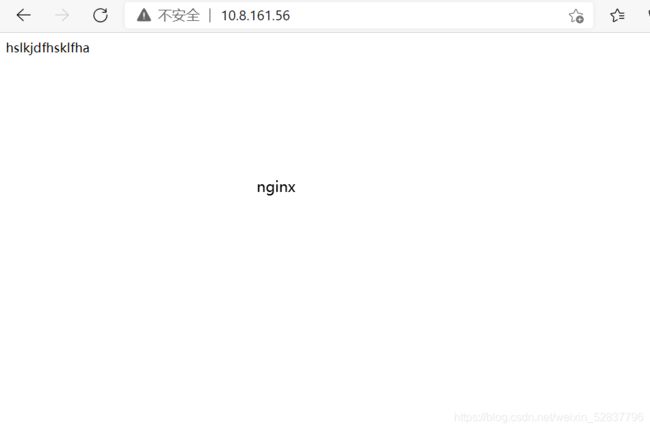
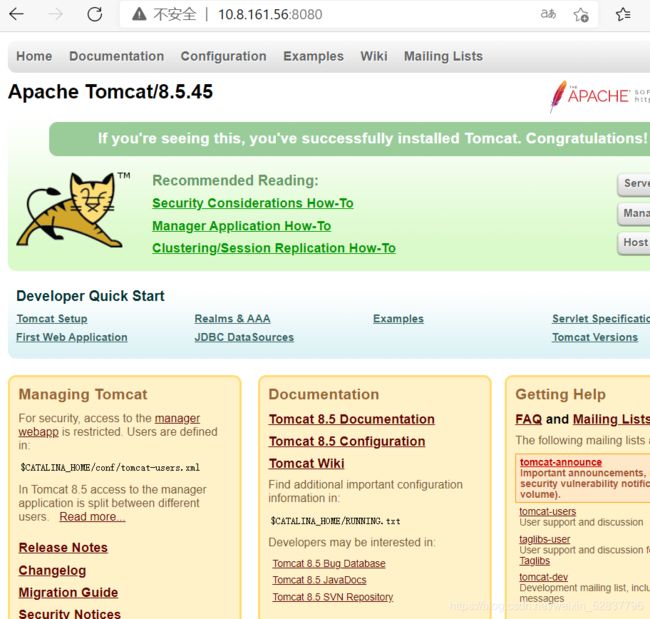
然后去head插件页面查看是否有nginxqf和tomcatqf索引出现
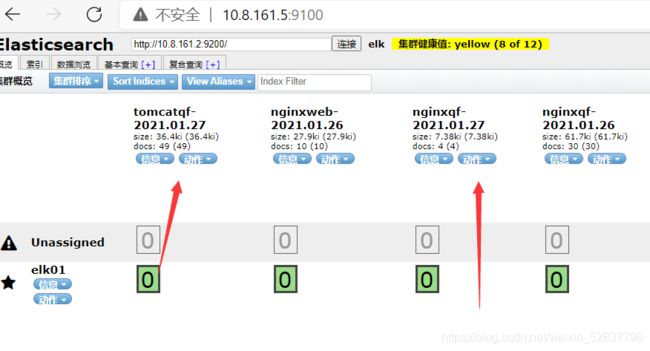
发现之后,去配置kibana添加索引
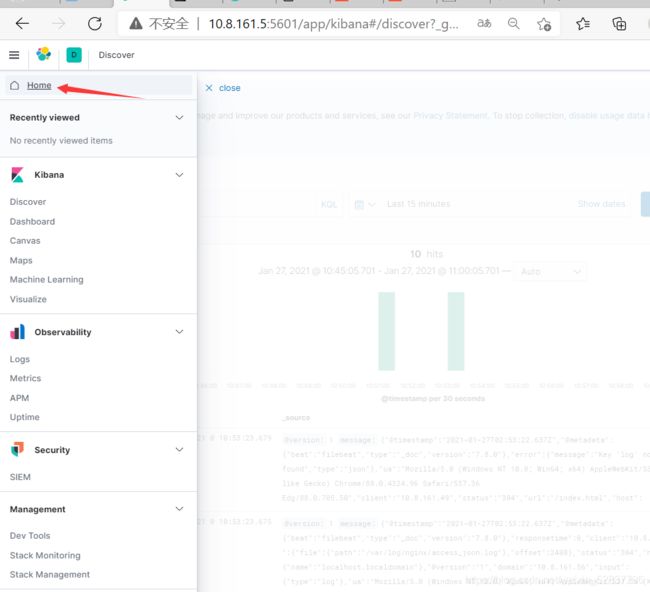

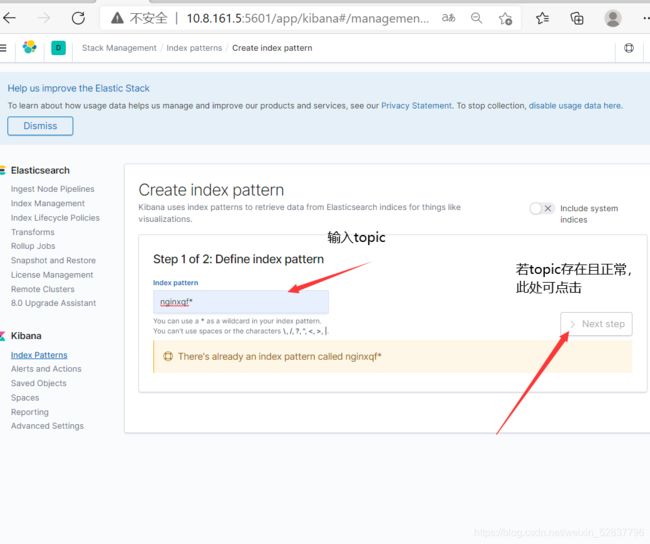
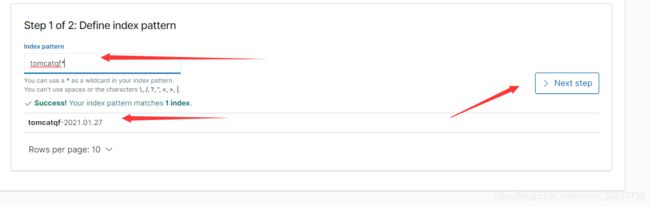
选择时间戳,并创建索引
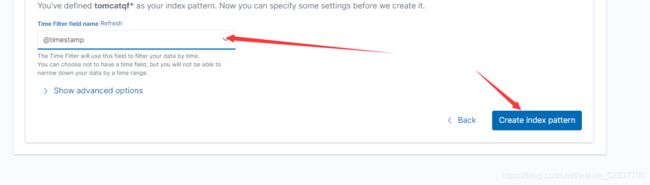
选择需要查看的话题
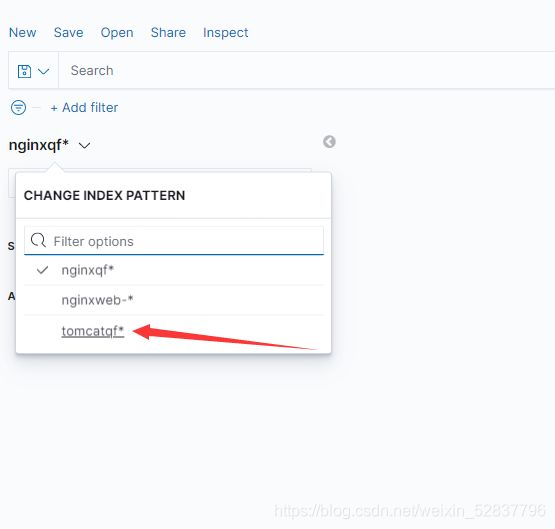
可以根据某个特定的值,来查看记录,比如
多刷新几次本机的nginx和tomcat页面,可以看到相应的日志记录,此处tomcat选用的是启动日志,当关闭或开启时,才会有日志产生
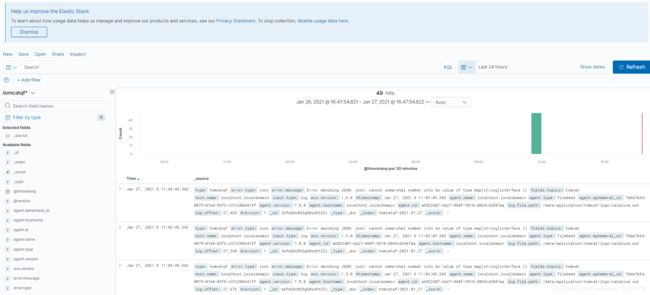
注意:如果进程关闭,页面将会访问失败,需要重启head,kibana,logstash
注意:如果出不来通过界面提示打开时间管理器,设置时间为本星期**
过程: 通过nginx的访问日志和tomcat的开启获取日志--->传输到logstach ----传输到--elasticsearch--传输到---kibana (通过nginix反代)
4、 Kafka部署
1.安装配置jdk8
(1)Kafka、Zookeeper(简称:ZK)运行依赖jdk8
tar zxvf /usr/local/package/jdk-8u121-linux-x64.tar.gz -C /usr/local/
echo '
JAVA_HOME=/usr/local/jdk1.8.0_121
PATH=$JAVA_HOME/bin:$PATH
export JAVA_HOME PATH
' >>/etc/profile
source /etc/profile2.安装配置ZK
Kafka运行依赖ZK,Kafka官网提供的tar包中,已经包含了ZK,这里不再额下载ZK程序。
配置相互解析---三台机器(可不配置)
[root@es-2-zk-log ~]# vim /etc/hosts
10.8.161.2 mes-1
10.8.161.5 es-2-zk-log
10.8.161.56 es-3-head-kib(1)安装
[root@es-2-zk-log ~]# tar xzvf kafka_2.11-2.1.0.tgz -C /usr/local/(2)配置
第一台
[root@mes-1 ~]# sed -i 's/^[^#]/#&/' /usr/local/kafka_2.11-2.1.0/config/zookeeper.properties #注释
[root@mes-1 ~]# vim /usr/local/kafka_2.11-2.1.0/config/zookeeper.properties #添加如下配置
dataDir=/opt/data/zookeeper/data
dataLogDir=/opt/data/zookeeper/logs
clientPort=2181
tickTime=2000
initLimit=20
syncLimit=10
server.1=10.8.161.2:2888:3888
server.2=10.8.161.5:2888:3888
server.3=10.8.161.56:2888:3888[root@mes-1 ~]# mkdir -p /opt/data/zookeeper/{data,logs}
#创建myid文件
[root@mes-1 ~]# echo 1 > /opt/data/zookeeper/data/myid #myid号按顺序排 集群节点的标识,和server.*对应第二台
[root@es-2-zk-log ~]# sed -i 's/^[^#]/#&/' /usr/local/kafka_2.11-2.1.0/config/zookeeper.properties
[root@es-2-zk-log ~]# vim /usr/local/kafka_2.11-2.1.0/config/zookeeper.properties
dataDir=/opt/data/zookeeper/data
dataLogDir=/opt/data/zookeeper/logs
clientPort=2181
tickTime=2000
initLimit=20
syncLimit=10
server.1=10.8.161.2:2888:3888
server.2=10.8.161.5:2888:3888
server.3=10.8.161.56:2888:3888
#创建data、log目录
[root@es-2-zk-log ~]# mkdir -p /opt/data/zookeeper/{data,logs}
#创建myid文件
[root@es-2-zk-log ~]# echo 2 > /opt/data/zookeeper/data/myid第三台
[root@es-3 ~]# sed -i 's/^[^#]/#&/' /usr/local/kafka_2.11-2.1.0/config/zookeeper.properties
[root@es-3-head-kib ~]# vim /usr/local/kafka_2.11-2.1.0/config/zookeeper.properties
dataDir=/opt/data/zookeeper/data
dataLogDir=/opt/data/zookeeper/logs
clientPort=2181
tickTime=2000
initLimit=20
syncLimit=10
server.1=10.8.161.2:2888:3888
server.2=10.8.161.5:2888:3888
server.3=10.8.161.56:2888:3888#创建data、log目录
[root@es-3-head-kib ~]# mkdir -p /opt/data/zookeeper/{data,logs}
#创建myid文件
[root@es-3-head-kib ~]# echo 3 > /opt/data/zookeeper/data/myid配置项含义:
dataDir ZK数据存放目录。
dataLogDir ZK日志存放目录。
clientPort 客户端连接ZK服务的端口。
tickTime ZK服务器之间或客户端与服务器之间维持心跳的时间间隔。
initLimit 允许follower连接并同步到Leader的初始化(第一次)连接时间,当初始化连接时间超过该值,则表示连接失败。
syncLimit Leader与Follower之间发送消息时如果follower在设置时间内不能与leader通信,那么此follower将会被丢弃。
server.1=172.16.244.31:2888:3888 2888是follower与leader交换信息的端口,3888是当leader挂了时用来执行选举时服务器相互通信的端口。
3.配置Kafka
(1)配置
第一台
[root@mes-1 ~]# sed -i 's/^[^#]/#&/' /usr/local/kafka_2.11-2.1.0/config/server.properties
[root@mes-1 ~]# vim /usr/local/kafka_2.11-2.1.0/config/server.properties #在最后添加
broker.id=1
listeners=PLAINTEXT://10.8.161.2:9092
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/opt/data/kafka/logs
num.partitions=6
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=2
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.segment.bytes=536870912
log.retention.check.interval.ms=300000
zookeeper.connect=10.8.161.2:2181,10.8.161.5:2181,10.8.161.56:2181
zookeeper.connection.timeout.ms=6000
[root@mes-1 ~]# mkdir -p /opt/data/kafka/logs第二台
[root@mes-1 ~]# sed -i 's/^[^#]/#&/' /usr/local/kafka_2.11-2.1.0/config/server.properties
[root@mes-1 ~]# vim /usr/local/kafka_2.11-2.1.0/config/server.properties #在最后添加
broker.id=2
listeners=PLAINTEXT://10.8.161.5:9092
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/opt/data/kafka/logs
num.partitions=6
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=2
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.segment.bytes=536870912
log.retention.check.interval.ms=300000
zookeeper.connect=10.8.161.2:2181,10.8.161.5:2181,10.8.161.56:2181
zookeeper.connection.timeout.ms=6000
group.initial.rebalance.delay.ms=0
[root@mes-1 ~]# mkdir -p /opt/data/kafka/logs第三台
[root@es-3-head-kib ~]# sed -i 's/^[^#]/#&/' /usr/local/kafka_2.11-2.1.0/config/server.properties
[root@es-3-head-kib ~]# vim /usr/local/kafka_2.11-2.1.0/config/server.properties
broker.id=3
listeners=PLAINTEXT://10.8.161.56:9092
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/opt/data/kafka/logs
num.partitions=6
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=2
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.segment.bytes=536870912
log.retention.check.interval.ms=300000
zookeeper.connect=10.8.161.2:2181,10.8.161.5:2181,10.8.161.56:2181
zookeeper.connection.timeout.ms=6000
group.initial.rebalance.delay.ms=0[root@es-3-head-kib ~]# mkdir -p /opt/data/kafka/logs配置项含义:
#每个server需要单独配置broker id,如果不配置系统会自动配置。
broker.id
#监听地址,格式PLAINTEXT://IP:端口。
listeners
#处理网络请求的线程数量,也就是接收消息的线程数。
num.network.threads
#消息从内存中写入磁盘是时候使用的线程数量。
num.io.threads
#发送套接字的缓冲区大小
socket.send.buffer.bytes
#当消息的尺寸不足时,server阻塞的时间,如果超时,
#消息将立即发送给consumer
socket.receive.buffer.bytes
服务器将接受的请求的最大大小(防止OOM)
socket.request.max.bytes
日志文件目录。
log.dirs
#topic在当前broker上的分片个数
num.partitions
#用来设置恢复和清理data下数据的线程数量
num.recovery.threads.per.data.dir
offsets.topic.replication.factor
#超时将被删除
log.retention.hours
#日志文件中每个segment的大小,默认为1G
log.segment.bytes
#上面的参数设置了每一个segment文件的大小是1G,那么
#就需要有一个东西去定期检查segment文件有没有达到1G,
#多长时间去检查一次,就需要设置一个周期性检查文件大小
#的时间(单位是毫秒)
log.retention.check.interval.ms
#ZK主机地址,如果zookeeper是集群则以逗号隔开
zookeeper.connect
#连接到Zookeeper的超时时间。
zookeeper.connection.timeout.ms
4、其他节点配置
只需把配置好的安装包直接分发到其他节点,Kafka的broker.id和listeners就可以了。
5、启动、验证ZK集群
(1)启动
在三个节点依次执行:
[root@mes-1 ~]# cd /usr/local/kafka_2.11-2.1.0/
[root@mes-1 kafka_2.11-2.1.0]# nohup bin/zookeeper-server-start.sh config/zookeeper.properties &(2)验证
查看端口
root@mes-1 ~]# netstat -lntp | grep 2181
tcp6 0 0 :::2181 :::* LISTEN 1226/java
[root@mes-1 ~]# yum -y install nmap
[root@mes-1 ~]# echo stat | nc 127.0.0.1 2181可用telnet测试端口,可直接测试其他服务器的端口,
telnet IP地址 端口号
[root@mes-1 ~]# telnet 127.0.0.1 2181
Trying 127.0.0.1...
Connected to 127.0.0.1.
Escape character is '^]'.
conf
6、启动、验证Kafka
(1)启动
在三个节点依次执行(所有节点均操作):
[root@mes-1 ~]# cd /usr/local/kafka_2.11-2.1.0/
[root@mes-1 kafka_2.11-2.1.0]# nohup bin/kafka-server-start.sh config/server.properties &(2)验证 是否有一致性
在10.8.161.5上创建topic
[root@es-2-zk-log kafka_2.11-2.1.0]# bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic testtopic
Created topic "testtopic".
# ReplicationFactor:副本个数。
# Partition:partition 编号,从 0 开始递增在5.56上面查询10.8.161.5上的topic
[root@es-3-head-kib kafka_2.11-2.1.0]# bin/kafka-topics.sh --zookeeper 10.8.161.5:2181 --list
testtopic模拟消息生产和消费 发送消息到10.8.161.5
[root@mes-1 kafka_2.11-2.1.0]# bin/kafka-console-producer.sh --broker-list 10.8.161.5:9092 --topic testtopic
>hello从10.8.161.5接受消息
[root@es-2-zk-log kafka_2.11-2.1.0]# bin/kafka-console-consumer.sh --bootstrap-server 10.8.161.5:9092 --topic testtopic --from-beginning
hellokafka没有问题之后,回到logstash服务器:
#安装完kafka之后的操作:
[root@es-2-zk-log ~]# cd /usr/local/logstash-7.8.0/etc/conf.d/
[root@es-2-zk-log conf.d]# cp input.conf input.conf.bak
[root@es-2-zk-log conf.d]# vim nginx.conf
input{
kafka{
type => "nginxqf"
# codec => "json
topics => "nginx"
# decorate_events => true
bootstrap_servers => "10.8.161.2:9092, 10.8.161.5:9092, 10.8.161.56:9092"
}
kafka{
type => "tomcatqf"
codec => "json"
topics => "tomcat"
# decorate_events => true
bootstrap_servers => "10.8.161.2:9092, 10.8.161.5:9092, 10.8.161.56:9092"
}
}
output{
elasticsearch {
hosts => ["10.8.161.2:9200"]
index => ["%{type}-%{+YYYY.MM.dd}"]
}
}
启动 logstash
[root@es-2-zk-log conf.d]# cd /usr/local/logstash-6.5.4/
[root@es-2-zk-log logstash-7.8.0]# nohup bin/logstash -f etc/conf.d/ --config.reload.automatic &5、Filebeat
(1)下载
(2)解压
[root@es-3-head-kib ~]# tar xzvf filebeat-7.8.0-linux-x86_64.tar.gz -C /usr/local/
[root@es-3-head-kib ~]# cd /usr/local/
[root@es-3-head-kib local]# mv filebeat-7.8.0-linux-x86_64 filebeat
[root@es-3-head-kib local]# cd filebeat/
(3)修改配置
修改 Filebeat 配置,支持收集本地目录日志,并输出日志到 Kafka 集群中
此处监控两个服务,用变量来定义topic
[root@es-3-head-kib filebeat]# mv filebeat.yml filebeat.yml.bak
[root@es-3-head-kib filebeat]# vim filebeat.yml
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/nginx/access_json.log
json.keys_under_root: true
json.add_error_key: true
json.message_key: log
fields:
topics: nginx
- type: log
enabled: true
paths:
- /data/application/tomcat/logs/catalina.out
json.keys_under_root: true
json.add_error_key: true
json.message_key: log
fields:
topics: tomcat
output.kafka:
enabled: true
hosts: ["10.8.161.2:9092","10.8.161.5:9092","10.8.161.56:9092"]
topic: '%{[fields][topics]}'
(4)启动
[root@es-3-head-kib filebeat]# nohup ./filebeat -e -c filebeat.yml &
[root@es-3-head-kib filebeat]# tail -f nohup.out
2019-08-04T16:55:54.708+0800 INFO kafka/log.go:53 kafka message: client/metadata found some partitions to be leaderless
2019-08-04T16:55:54.708+0800 INFO kafka/log.go:53 client/metadata retrying after 250ms... (2 attempts remaining)
...
验证kafka是否生成topic
[root@es-3-head-kib filebeat]# cd /usr/local/kafka_2.11-2.1.0/
[root@es-3-head-kib kafka_2.11-2.1.0]# bin/kafka-topics.sh --zookeeper 10.8.161.56:2181 --list
__consumer_offsets
nginx
tomcat #已经生成topic
testtopic
现在我们去编辑logstach连接kafka的输出文件**
配置完kafka之后查看
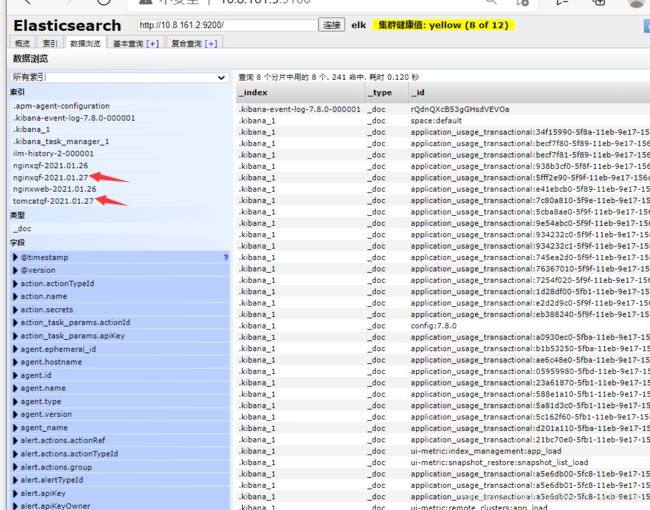
登录到kibana
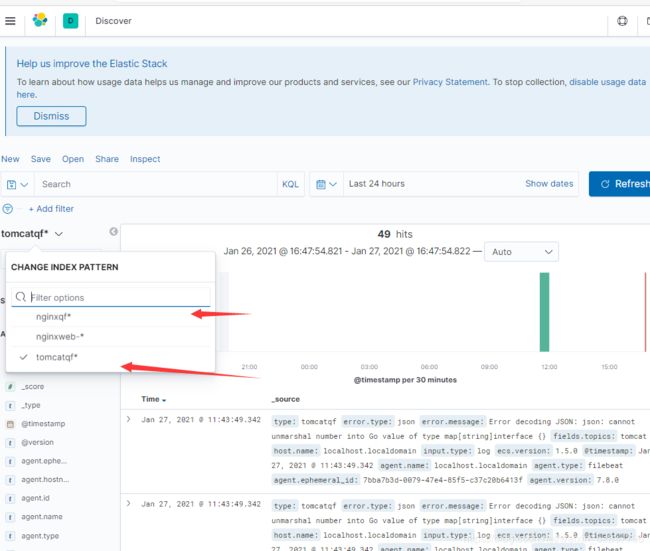
此处只有一个es