blip2:Bootstrapping lanuage-image pre-training with frozen image encoders and large lanuage models
中文BLIP2 https://modelscope.cn/models/xiajinpeng123/BLIP2-Chinese/summaryBLIP-2: 多模态与大模型结合的基础范式 - 知乎写在前面:本人是一名小红书算法工程师,主要在小红书做多模态内容理解相关的工作,关注多模态相关的工作很多年了,个人认为多模态步入快速发展是从VisualBert这项工作开始的,VisualBert 将图像的关键目标作为图…https://zhuanlan.zhihu.com/p/663371797BLIP2结合LLM模型做多模态模型的对齐,同时多模态模型的主要任务也从理解转成生成。BLIP2之前多模态任务主要还是以理解为主,对齐融合两个关键点,传统的以clip为主衍生的视觉大模型任务不涉及生成,vlm这类的多模态大语言模型的出现主要就是如何利用模态的对齐,融合部分交给了LLM做生成。
https://modelscope.cn/models/xiajinpeng123/BLIP2-Chinese/summaryBLIP-2: 多模态与大模型结合的基础范式 - 知乎写在前面:本人是一名小红书算法工程师,主要在小红书做多模态内容理解相关的工作,关注多模态相关的工作很多年了,个人认为多模态步入快速发展是从VisualBert这项工作开始的,VisualBert 将图像的关键目标作为图…https://zhuanlan.zhihu.com/p/663371797BLIP2结合LLM模型做多模态模型的对齐,同时多模态模型的主要任务也从理解转成生成。BLIP2之前多模态任务主要还是以理解为主,对齐融合两个关键点,传统的以clip为主衍生的视觉大模型任务不涉及生成,vlm这类的多模态大语言模型的出现主要就是如何利用模态的对齐,融合部分交给了LLM做生成。
1.introduction
blip2将多模态混合数据(image+text)转化为LLM可理解的soft-prompt,LLM需要输入指令,当想让llm理解其他模态数据时比较难,在blip2之前,只能先让其他模态转成人类语言,在变成llm的instruct,blip2通过与llm联合训练的方式,将多模态数据转成embedding,该embedding既可以输入llm用于内容生成,也可以支持下游任务。
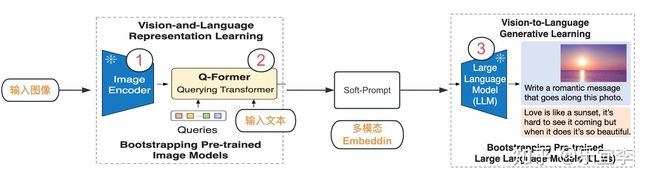
blip2的整个架构分成2部分,左边是多模态理解,右边可以称为基于理解的内容生成。从参数上看,可以分为三部分,只有2是可训练的,其他参数都是冻结的,其中1用来提取输入图像特征的embedding(clip的图像encoder,ViT-L/14),2是需要学习的Q-former,用于连接图像encoder和LLM,3是LLM。
2.method
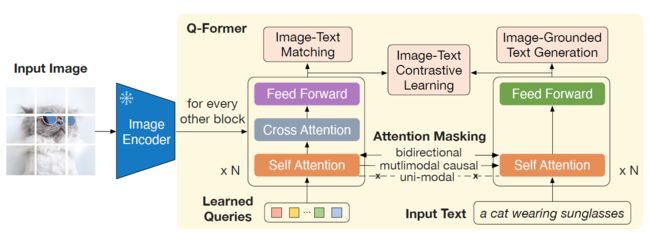
2.1 model architecture
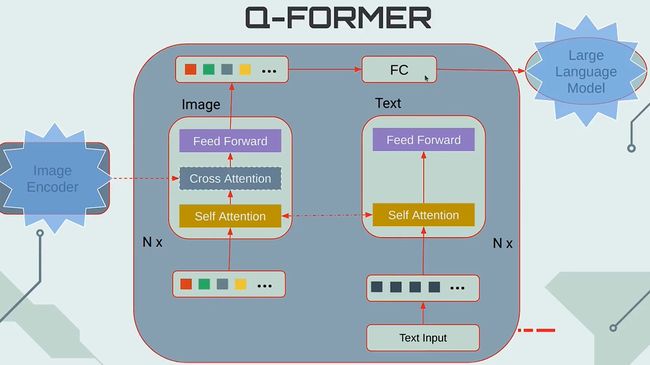
Q-former作为可训练模块,以弥合固定图像编码器和固定LLM之间的差距,它从图像编码器中提取出一定数量的输出特征,独立于输入图像的分辨率,Q-former由两个transformer子模块组成,他们共享相同的自注意力层:1.与固定图像编码器进行交互以进行视觉特征提取的图像transformer,2.可充当文本编码器和和文本解码器的文本transformer。可以理解为三个多任务预训练和一个learned-queries,Q-former可以认为是简化版的BERT和一组可学习的learned-queries参数,使用BERTbase的预训练权重初始化Q-former,cross-attention则采用随机初始化。Q-former一共有188M参数。
leared-queries是一个参数矩阵,本文中是32x768,即32个token,每个token的维度是768,远小于冻结图像特征的大小,例如ViT-L/14为257x1024,该参数作为transformer的Q,image encoder输出的图像特征一般也是768维度,token数量是N,输出N*768,作为transformer的K,V,有了QKV之后,三者就可以做cross-attention,从而完成图像特征的提取,可以将learned-queries理解为提取与文本最相关的视觉信息。
2.2 bootstrap vision-lanuage representation learning from a frozen image encoder
将Q-former连接到一个冻结的图像编码器,并使用图像-文本对进行预训练,目标是训练Q-former使得query可以学习提取最具信息性的视觉表示。
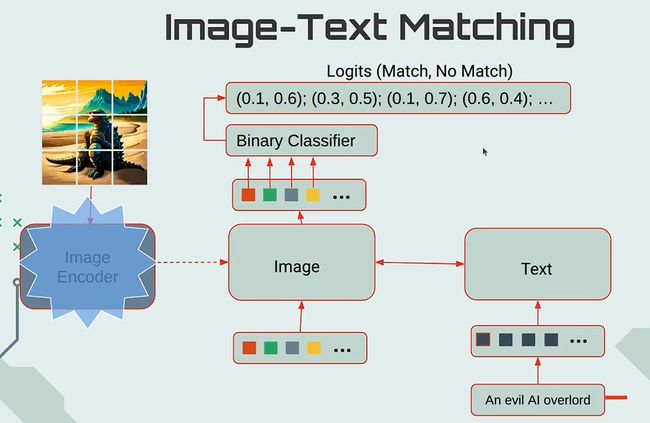
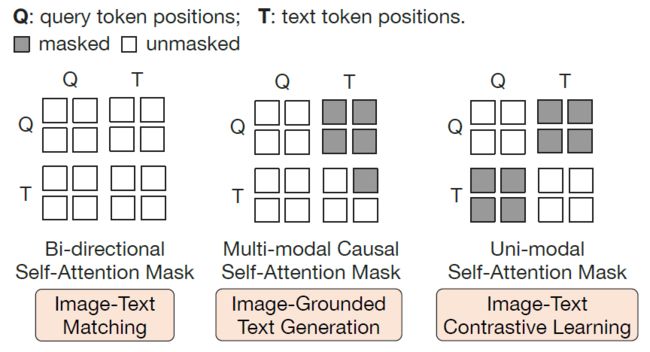
image-text matching:该任务是判断输入的图像和文本对是否匹配,这里learned-queries和输入文本在self-attention层进行双向特征交互,最终产出的隐形特征Z(32x768),进过一个head做2分类,然后32个二分类的logits求平均作为最终的logits。
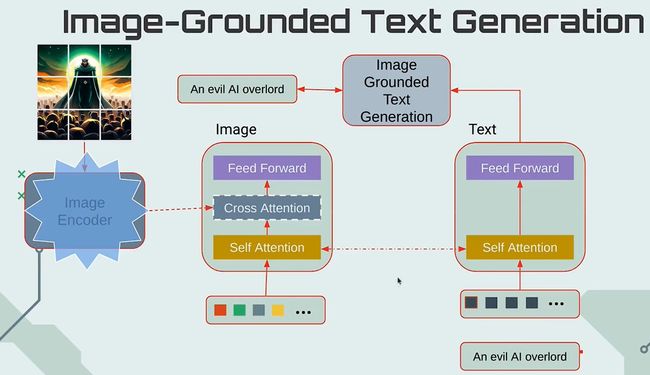
image-grounded text generation:该任务是根据图像,预测输入的文本,GPT的训练方式,learned-queries和input text在attention层是单向可见的。

image-text contrastive learning:图文对比学习,和clip相似,图像产出的embedding维度是Nx768,文本采用[cls]token的特征维度是1x768,因此计算的相似度是1x32,论文提出使用32个score中最大分数为similiarity,为了防止信息泄露,learned-queries和input text在attention层是双向不可见的。
以上三个预训练损失函数,对应三种不同的数据mask方式,具体实现中,一个样本要3次推理,计算复杂度很高。
2.3 bootstrap vision-to-language generative learning from a frozen llm
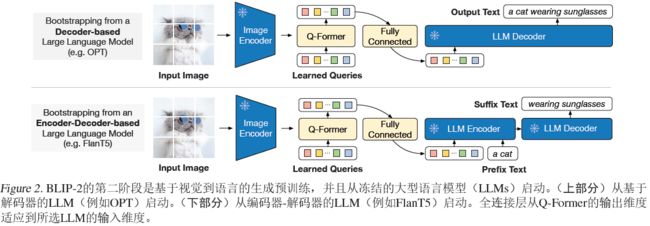
在生成式预训练阶段,将带有冻结图像编码器的Q-former连接到一个冻结的llm上,以获得llm的生成语言能力,使用FC层将输出queries的embedding Z线性投影到与LLM的文本embedding相同维度上,将投影的queries的embedding前置到输入文本embedding之前,充当soft prompt,对LLM进行条件约束,目的是将Q-former的特征空间与LLM的特征空间对齐。上半图,LLM模型可以是单独的一个解码器,这种情况不需要输入prompt,也可以是encoder-decoder形式,可以输入prompt。
2.4 model pre-training
预训练数据:使用blip数据集,1.29亿张图像,包括COCO,Visual Genome,CC3M,CC12M,SBU以及LAION400M数据集的1.15张图像,每张图像2个标题。
预训练的图像编码器和LLM:CLIP中的ViT-L/14或EVA-CLLIP中的ViT-g/14,移除了ViT的最后一层,并使用倒数第二层的输出特征。OPT系列的LLM来进行基于解码器的LLM以及使用指令训练的FlanT5的encoder-decoder系列的LLM
预训练设置:第一阶段250k预选连,第二阶段80k的预训练,16xa100 40G。