mongodb(让你成为高手高高手)
文章目录
-
- linux下的安装
- 常用命令语句
- 安全
- 原生java客户端的简单使用
- 与Springboot的整合
- MongoDB数据类型
- 查询
- 聚合
- 更新
- 删除
- 连接池
- 存储引擎
- 索引
- 集群部署
- mongoDB的使用场景与总结
- springboot的综合使用
linux下的安装
-
CentOs7-64位
#下载安装包 wget https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-3.4.23.tgz #解压 mkdir /usr/local/mongodb tar -zxvf mongodb-linux-x86_64-3.4.23.tgz -C /usr/local/mongodb #创建必要的文件与文件夹 cd /usr/local/mongodb/mongodb-linux-x86_64-3.4.23/ mkdir data mkdir logs touch logs/mongodb.log chmod -R 777 /usr/local/mongodb/ #创建配置文件并添加配置内容 vim ./bin/mongodb.conf #简单的配置内容如下 > storage: dbPath: "/usr/local/mongodb/mongodb-linux-x86_64-3.4.23/data" systemLog: destination: file path: "/usr/local/mongodb/mongodb-linux-x86_64-3.4.23/logs/mongodb.log" net: port: 27022 http: RESTInterfaceEnabled: true processManagement: fork: false > #启动mongodb nohup ./mongod -f mongodb.conf & #安全启动mongodb nohup ./mongod -f mongodb.conf --auth & #连接客户端 ./mongo localhost:27022 #优雅的关机 第一种方式: ./mongod --shutdown -f mongodb.conf 第二种方式: use admin db.shutdownServer() -
自定义的mongodb.conf配置文件详情
storage: journal: enabled: true dbPath: "/usr/local/mongodb/mongodb-linux-x86_64-3.4.23/data" ##是否一个库一个文件夹 directoryPerDB: true ##数据引擎 engine: wiredTiger ##WT引擎配置 wiredTiger: engineConfig: ##WT最大使用cache(根据服务器实际情况调节) cacheSizeGB: 1 ##是否将索引也按数据库名单独存储 directoryForIndexes: true journalCompressor:none (默认snappy) ##表压缩配置 collectionConfig: blockCompressor: zlib (默认snappy,还可选none、zlib) ##索引配置 indexConfig: prefixCompression: true systemLog: destination: file path: "/usr/local/mongodb/mongodb-linux-x86_64-3.4.23/logs/mongodb.log" net: port: 27022 http: RESTInterfaceEnabled: true processManagement: fork: false #压缩算法 Tips: #性能: none > snappy >zlib #压缩比: zlib > snappy > none #none表示不压缩
常用命令语句
-
mongoDB命令脚本
#内置帮助,显示各种方法说明 > db.help() , db.collection().help() #查看当前所在的库 > db #查看所有库 > show dbs #进入指定的库 > use test #显示数据库信息 > db.stats() #查看服务器状态 > db.serverStatus() #删除数据库 > db.dropDatabase() #查询集合数量 > db.users.find().size() #查看当前所在库所有的集合(表) > show collections #添加数据 > var user1 = { "userName":"Jaye", "age": 18, "country":"heNan" }; db.users.insert(user1); > #查询所有的表中所有数据 > db.users.find() #通过用户名查询数据 > db.users.find({"userName":"Jaye"}) #以JSON格式展示返回数据 > db.users.find({"userName":"Jaye"}).pretty() #删除表中所有数据 > db.users.drop()
安全
-
数据备份、恢复、导出、导入
# 数据备份 mongodump # -h :指定ip和端口; -d :备份的数据库名称 ; -o:指定备份的路径 # 其本质为:执行查询,然后写入文件; ./mongodump -h localhost:27022 -d test -o /usr/local/mongodb/mongodb-linux-x86_64-3.4.23/backup # 数据恢复 mongorestore # --drop 已存在test库则删除原数据库,去掉--drop则是合并 ./mongorestore -h localhost:27022 -d test /usr/local/mongodb/mongodb-linux-x86_64-3.4.23/backup/test --drop #数据导出 mongoexport(针对集合) #-c :指定导出的集合; -f :要导出的字段; --type:导出的文件格式类型[csv,json] ./mongoexport -h localhost:27022 -d test -c users -f id,username,age,salary --type=csv -o /usr/local/mongodb/mongodb-linux-x86_64-3.4.23/backup/users.csv #数据导入 mongoimport(针对集合) #--upsert 表示更新现有数据,如果不适用—upsert,则导入时已经存在的文档会报id重复,数据不再插入,也可以使用—drop删除原有数据 ./mongoexport -h localhost:27022 -d test -c users /usr/local/mongodb/mongodb-linux-x86_64-3.4.23/backup/users.csv --upsert -
安全启动、权限初始化
# 1.安全启动MongoDB nohup ./mongod -f mongodb.conf --auth & # 2.连接客户端创建初始化一个userAdminAnyDatabase权限用户 db.createUser({'user':'boss', 'pwd':'boss', 'roles':[{'role':'userAdminAnyDatabase', 'db':'admin'}]}) # 3.使用初始化的userAdminAnyDatabase权限用户登录, db.auth("boss","boss"); # 4.切换至test库,并创建test库的readWrite权限用户 use test db.createUser({'user':'JayeTian','pwd':'abc.123','roles':[{'role':'readWrite','db':'test'}]}) -
查询已经创建的权限用户
use admin #查看当前库内已有用户 show users #查看当前库内可用的roles,默认只有built-in roles show roles -
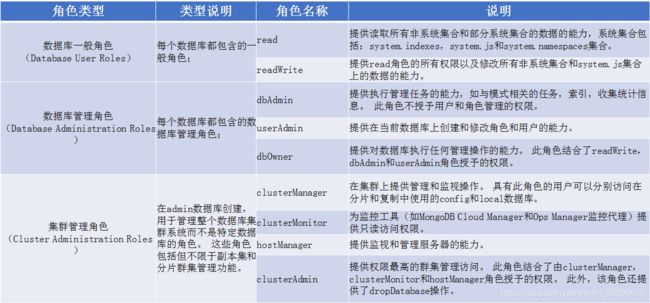
角色权限

原生java客户端的简单使用
-
引入pom
<dependency> <groupId>org.mongodbgroupId> <artifactId>mongo-java-driverartifactId> <version>3.9.0version> dependency>3.5.0版本开始加入了对pojo的支持
3.5.0版本增强对json的支持
mongodb原生客户端支持两种document和pojo模式的开发 -
客户端的基本使用
package com.example.mongodb.controller; import com.example.mongodb.constant.UsersMongoEnum; import com.mongodb.MongoClient; import com.mongodb.client.MongoCollection; import com.mongodb.client.MongoDatabase; import org.bson.Document; public class MongodbDocumentTest { //客户端(内置连接池) private static final MongoClient client; //数据库 private static final MongoDatabase db; //文档集合(表) private static final MongoCollection<Document> doc; static { client = new MongoClient("192.168.227.131", 27022); db = client.getDatabase("test"); doc = db.getCollection("users"); } public static void main(String[] args) { insertData(); } public static void insertData() { Document userDocument = new Document(); userDocument.append(UsersMongoEnum.userName.name(), "田杰熠"); userDocument.append(UsersMongoEnum.age.name(), 18); userDocument.append(UsersMongoEnum.country.name(), "长垣"); doc.insertOne(userDocument); } public static void findData() { FindIterable<Document> documents = doc.find(); documents.forEach((Consumer<? super Document>) x -> System.out.println(x.toString())); } }
与Springboot的整合
-
pom引用
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-mongodb</artifactId> </dependency> -
添加.properties配置
spring.data.mongodb.uri=mongodb://192.168.227.131:27022/test -
客户端的使用
//@Document(collection= "") , collection代表对应的集合名(表名) //@Field(value= "") , value定义mongodb集合字段与pojo类字段的映射关系 package com.example.mongodbspring.bean; import lombok.Data; import org.springframework.data.mongodb.core.mapping.Document; @Data @Document(collection = "users") public class User { private String id; @Field(value = "user_name") private String userName; private int age; private String country; }//mongoTemplate的简单使用 @RestController public class MongodbController { @Autowired private MongoTemplate mongoTemplate; @RequestMapping(value = "/test") public void test() { List<User> all = mongoTemplate.findAll(User.class); all.forEach(x -> System.out.println(x.toString())); } }
MongoDB数据类型
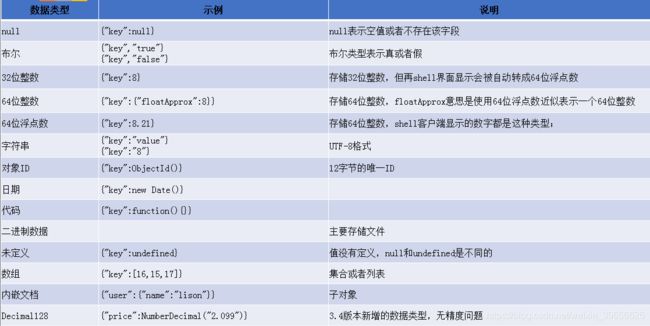
- 数据类型
查询
-
查询选择器
属性 属性值 描述 范围 $eq 等于 $lt 小于 $gt 大于 $lte 小于等于 $gte 大于等于 $in 判断元素是否在指定的集合范围里 $all 判断数组中是否包含某几个元素,无关顺序 $nin 判断元素是否不在指定的集合范围里 布尔运算 $ne 不等于,不匹配参数条件 $not 不匹配结果 $or 有一个条件成立则匹配 $nor 所有条件都不匹配 $and 所有条件都必须匹配 $exists 判断元素是否存在 其他 $regex 正则表达式匹配 -
查询喜欢的城市包含东莞和东京的用户
#mongo脚本 db.users.find({"heart_love.city":{"$all":["东莞","东京"]}}).pretty()#原生java客户端 Bson all = all("heart_love.city", Arrays.asList("东莞", "东京")); FindIterable<Document> documents = doc.find(all);#springboot Criteria all = where("heart_love.city").all(Arrays.asList("东莞", "东京")); List<User> userList = mongoTemplate.find(query(all),User.class); -
查询姓名为Jaye,WanCan,WangYaJie的用户
#mongo脚本 db.users.find({"userName":{"$in":["Jaye","WangCan","WangYaJie"]}}).pretty()#原生java客户端 Bson in = in("userName", Arrays.asList("Jaye", "WangCan", "WangYaJie")); FindIterable<Document> documents = doc.find(in);#springboot Criteria in = where("userName").in("Jaye", "WangCan", "WangYaJie"); List<User> userList = mongoTemplate.find(query(in),User.class); -
判断文档有没有关心的字段
#mongo脚本 db.users.find({ "heart_love" : {"$exists" : true} }).pretty()#原生java客户端 Bson exists = exists("heart_love", true); FindIterable<Document> documents = doc.find(exists);#springboot Criteria exists = where("heart_love").exists(true); List<User> userList = mongoTemplate.find(query(exists),User.class); -
查询年龄小于18,或者没有年龄的人
#mongo脚本 db.users.find({"$or":[{"age":{"$lt":18}},{"age":{"$exists":false}}]}).pretty() 或者 db.users.find({"age":{"$not":{"$gte":18}}}).pretty()#原生java客户端 Bson lt = lt("age", 18); Bson exists = exists("age", false); FindIterable<Document> documents = doc.find(or(lt, exists)); 或者 Bson gte = gte("age", 18); FindIterable<Document> documents = doc.find(not(gte));#springboot Criteria criteria = new Criteria(); criteria.orOperator(where("age").lt(18),where("age").exists(false)); List<User> userList = mongoTemplate.find(query(criteria), User.class); 或者 Criteria criteria = where("age").not().gte(18); List<User> userList = mongoTemplate.find(query(criteria), User.class); -
只查询名称和年龄两个字段
#mongo脚本 db.users.find({},{userName:1,age:1}).pretty()#原生java客户端 Bson include = include("userName", "age"); FindIterable<Document> documents = doc.find().projection(include);#springboot Query query = query(new Criteria()); query.fields().include("userName").include("age"); List<User> userList = mongoTemplate.find(query, User.class); -
排序
#mongo脚本 db.users.find().sort({age:1}).pretty() //ASC 正序 db.users.find().sort({age:-1}).pretty() //DESC 反序#java原生客户端 Bson ascending = ascending("age"); //ASC 正序 Bson descending = descending("age"); //DESC 反序 FindIterable<Document> documents = doc.find().sort(ascending);#Spring Sort sortBy = Sort.by(Sort.Direction.ASC, "age"); Query query = query(new Criteria()).with(sortBy); List<User> userList = mongoTemplate.find(query, User.class); -
分页
#mongo脚本 skip : 从第几条数据开始查询 limit : 查询几条数 db.users.find().skip(1).limit(2).pretty()#java原生客户端 FindIterable<Document> documents = doc.find().skip(1).limit(2);#springboot Query query = query(new Criteria()).skip(1).limit(2); List<User> userList = mongoTemplate.find(query, User.class); -
查询唯一值
#mongo脚本 db.users.distinct("user_name") //查询结果 [ "张三", "李四", "" ]#java原生客户端 DistinctIterable<Integer> ageDistinct = doc.distinct("age", Integer.class); ageDistinct.forEach((Consumer<? super Integer>) x-> System.out.println( "age: " + x));#springboot List<Integer> ageList = mongoTemplate.findDistinct("age", User.class, Integer.class); -
数组单元素查询(查询喜欢的电影包含西游记)
db.users.find({"heart_love.movies" : "西游记"}).pretty()Bson eq = eq("heart_love.movies", "西游记"); FindIterable<Document> documents = doc.find(eq); documents.forEach((Consumer<? super Document>) x -> System.out.println(x.toString()));Criteria is = where("heart_love.movies").is("西游记"); List<User> userList = mongoTemplate.find(query(is), User.class); -
数组精确查询(查询喜欢的电影等于西游记,一路向西 的用户. 顺序,数量完全一致 )
db.users.find({"heart_love.movies" : ["西游记","一路向西"]}).pretty()Bson eqb = eq("heart_love.movies", Arrays.asList("西游记","一路向西")); FindIterable<Document> documents = doc.find(eqb);Criteria all = where("heart_love.movies").is(Arrays.asList("西游记","一路向西")); List<User> userList = mongoTemplate.find(query(all), User.class); -
索引查询(喜欢的电影第一个是东游记)
db.users.find({"heart_love.movies.0" : "东游记"}).pretty() -
返回数组子集(查询)
db.users.find({},{"heart_love.movies":{"$slice":[1,1]}}).pretty(); -
查询喜欢的电影有东游记或者一路向西的用户
db.users.find({"heart_love.movies":{"$in":["东游记","一路向西"]}}).pretty(); -
查询喜欢的电影名称中含有苍老师字和喜欢的城市是东京的用户
数据模型
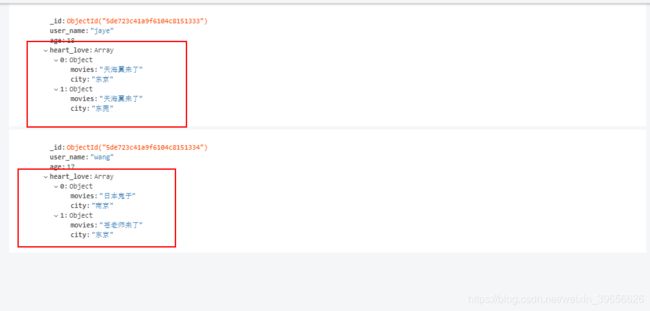
db.users.find({"heart_love":{"$elemMatch":{"city":"东京","movies":{"$regex":".*苍老师.*"}}}}).pretty()
聚合
-
什么是聚合
聚合框架就是定义一个管道,管道里的每一步都为下一步输出数据
-
聚合常用的操作
$project:投影,指定输出文档中的字段; $match:用于过滤数据,只输出符合条件的文档。$match使用MongoDB的标准查询操作 $limit:用来限制MongoDB聚合管道返回的文档数。 $skip:在聚合管道中跳过指定数量的文档,并返回余下的文档。 $unwind:将文档中的某一个数组类型字段拆分成多条,每条包含数组中的一个值。 $group:将集合中的文档分组,可用于统计结果。(分组后的数据可执行如下的表达式计算) $sum:计算总和。 $avg:计算平均值。 $min:根据分组,获取集合中所有文档对应值得最小值。 $max:根据分组,获取集合中所有文档对应值得最大值。 $sort:将输入文档排序后输出。 -
聚合操作实战
数据结构
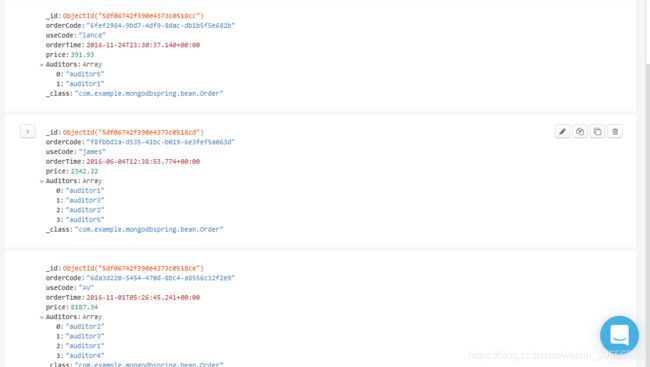
#查询2015年4月3号之前,每个用户每个月消费的总金额,并按用户名进行排序 db.orders.aggregate([{"$match":{"orderTime":{"$lt":new Date("2015-04-03T16:00:00.000Z")}}},{"$group":{"_id":{"useCode":"$useCode","month":{"$month":"$orderTime"}},"total":{"$sum":"$price"}}},{"$sort":{"_id":1}}]).pretty()#查询2015年4月3号之前,每个审核员分别审批的订单总金额,按审核员名称进行排序 db.orders.aggregate([{"$match":{"orderTime":{"$lt":new Date("2015-04-03T16:00:00.000Z")}}},{"$unwind":"$Auditors"},{"$group":{"_id":{"Auditors":"$Auditors"},"total":{"$sum":"$price"}}},{"$sort":{"_id":1}}]).pretty()
更新
-
语法
update() 方法用于更新已存在的文档。语法格式如下: db.collection.update( <query>, <update>, { upsert: <boolean>, multi: <boolean>, writeConcern: <document> } ) 参数说明: query : update的查询条件,类似sql update查询内where后面的; update : update的对象和一些更新的操作符(如$,$inc...)等,也可以理解为sql update查询内set后面的 upsert : 可选,这个参数的意思是,如果不存在update的记录,是否插入,true为插入,默认是false,不插入。 multi : 可选,mongodb 默认是false,只更新找到的第一条记录,如果这个参数为true,就把按条件查出来多条记录全部更新。 writeConcern :可选,写策略配置。 -
更新操作符
属性 属性值 描述 操作符 $inc 指定值加n $set 更新指定字段 $unset 删除指定字段 $rename 更新字段名称 数组操作符 $push 添加值到数组中 $addToSet 添加到数组中,有重复则不添加 $pop 删除数组第一个或者最后一个 $pull 从数组中删除匹配查询条件 $pullAll 从数组中删除多个值 数组运算修饰符 $each 与$push和$addToSet等一起使用来操作多个值 $slice 与$push和$each一起使用来操作用来缩小更新后数组的大小 $sort 与$push 、$each 和 $slice 一起使用来对数组进行排序 -
删除用户名为jaye的 heart_love和 age 两个字段
db.users.updateMany({"user_name":"jaye"},{"$unset":{"heart_love":"","age":""}}) -
更新用户名为wang的 user_name字段为username 和 heart_love字段为heartlove
db.users.updateMany({"user_name":"wang"},{"$rename":{"heart_love":"heartlove","user_name":"username"}}) -
$each作用示例
不使用$each效果
db.users.updateMany({"user_name":"jaye"},{"$push":{"game":["古剑奇谭","仙剑"]}})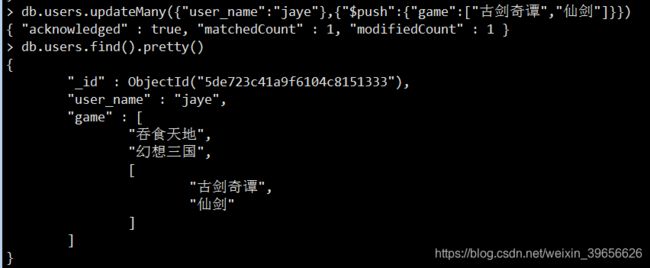
使用$each效果#mongodb脚本 db.users.updateMany({"user_name":"jaye"},{"$push":{"game":{"$each":["古剑奇谭","仙剑"]}}})#java原生客户端 Bson q = eq("username", "jaye"); Bson u = pushEach("game", Arrays.asList("古剑奇谭3","仙剑6")); doc.updateMany(q,u);#spring Criteria q = where("username").is("jaye"); Update u = new Update().push("game").each("古剑奇谭","仙剑"); mongoTemplate.updateMulti( query(q), u, User.class);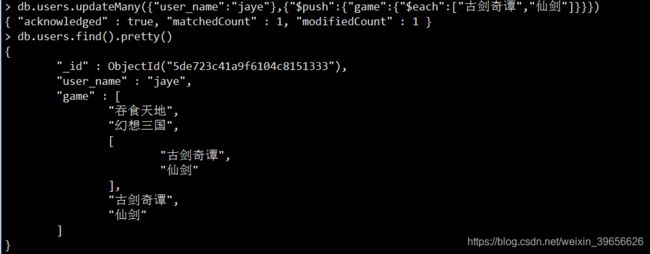
-
删除字符串数组中元素示例
#删除用户名为jaye的文档中 game字段中等于["古剑奇谭","仙剑"]的数据 db.users.updateMany({"user_name":"jaye"},{"$pull":{"game":["古剑奇谭","仙剑"]}})#删除用户名为jaye的文档中 game字段中等于 "古剑奇谭" 或者 "仙剑" 的数据 db.users.updateMany({"user_name":"jaye"},{"$pullAll":{"game":["古剑奇谭","仙剑"]}}) -
对象数组更新示例
#为用户名为wang的文档添加一条喜好信息 db.users.updateMany({"username":"wang"},{"$push":{"heartlove":{"movies":"善良的小姨子","city":"东莞"}}})#为用户名为wang的文档添加多条喜好信息 db.users.updateMany({"username":"wang"},{"$push":{"heartlove":{"$each":[{"movies":"前辈的女朋友","city":"首尔"},{"movies":"表妹","city":"东莞"}]}}})#为用户名为wang的文档添加多条喜好信息,并进行排序 db.users.updateMany({"username":"wang"},{"$push":{"heartlove":{"$each":[{"movies":"前辈的女朋友","city":"首尔"},{"movies":"表妹","city":"东莞"}],"$sort":{"city":-1}}}})#删除用户名为wang的文档中喜好城市为东莞的信息 db.users.updateMany({"username":"wang"},{"$pull":{"heartlove":{"city":"东莞"}}})#删除用户名为wang的文档中喜好city为南京且movies为日本鬼子的信息 db.users.updateMany({"username":"wang"},{"$pull":{"heartlove":{"city":"南京","movies":"日本鬼子"}}})#修改喜好的内容,如果多个符合条件的数据,则修改第一条数据。 无法批量修改 db.users.updateMany({"username":"wang","heartlove.city":"首尔"},{"$set":{"heartlove.$.movies":"表妹","heartlove.$.city":"东莞"}})#为用户名为wang的文档age字段加1 db.users.updateMany({"username":"wang"},{"$inc":{"age":1}})db.users.update() 更新一条数据
db.users.updateMany() 更新多条数据
db.users.findAndModify({query:{},update:{},‘new’:true }) 更新数据并返回更新前和更新后的数据
db.users.upsert() 有则更新,无则插入
删除
-
删除脚本
deleteOne(query) //删除单个文档 deleteMany(query) //删除多个文档 ## 删除操作是不会删除索引的,就算你把数据全部删除
连接池
-
字段说明
数名 默认值 说明 minConnectionsPerHost 最小连接数, Connections-Per-Host font color=red> connectionsPerHost 100 最大连接数 ont color=red> threadsAllowedToBlockForConnectionMultiplier 5 此参数与 connectionsPerHost 的乘机为一个线程变为可用的最大阻塞数,所有线程将及时获取一个异常 maxWaitTime 1000 * 60 * 2 一个线程等待连接可用的最大等待毫秒数,0表示不等待 onnectTimeout 1000 * 10 连接超时时间 (建立连接时,超过该时间还没有建立成功则连接超时) axConnectionIdleTime 0 设置池连接的最大空闲时间,0表示没有限制 axConnectionLifeTime 0 设置池连接的最大使用时间,0表示没有限制 waysUseMBeans false 是否打开JMX监控 artbeatFrequency 10000 设置心跳频率。 这是驱动程序尝试确定群集中每个服务器的当前状态的频率。 nHeartbeatFrequency 500 设置最低心跳频率。 如果驱动程序必须经常重新检查服务器的可用性,那么至少要等上一次检查以避免浪费。 artbeatConnectTimeout 20000 心跳检测连接超时时间 artbeatSocketTimeout 20000 心跳检测Socket超时时间 decRegistry MongoClient.getDefaultCodecRegistry() 编解码类,实现Codec接口 iteConcern ACKNOWLEDGED 写入安全机制,是一种客户端设置,用于控制写入安全的级别:
ACKNOWLEDGED 默认选项,数据写入到Primary就向客户端发送确认
0 Unacknowledged 对客户端的写入不需要发送任何确认,适用于性能要求高,但不关注正确性的场景;
1 W1 数据写入后,会等待集群中1台发送确认
2 W2 数据写入后,会等待集群中两台台发送确认
3 W3 数据写入后,会等待集群中3台台发送确认
JOURNALED 确保所有数据提交到 journal file
MAJORITY 等待集群中大多数服务器提交后确认;
存储引擎
-
mongoDB的存储引擎简介
MongoDB从3.0开始引入可插拔存储引擎的概念。目前主要有MMAPV1、WiredTiger存储引擎可供选择。在3.2版本之前MMAPV1是默认 的存储引擎,其采用linux操作系统内存映射技术,但一直饱受诟病;3.4以上版本默认的存储引擎是wiredTiger,相对于MMAPV1其有如下优势: 1、读写操作性能更好,WiredTiger能更好的发挥多核系统的处理能力; 2、MMAPV1引擎使用表级锁,当某个单表上有并发的操作,吞吐将受到限制。WiredTiger使用文档级锁,由此带来并发及吞吐的提高 3、相比MMAPV1存储索引时WiredTiger使用前缀压缩,更节省对内存空间的损耗; 4、提供压缩算法,可以大大降低对硬盘资源的消耗,节省约60%以上的硬盘资源; -
mongDB ,WiredTiger存储引擎的写入原理
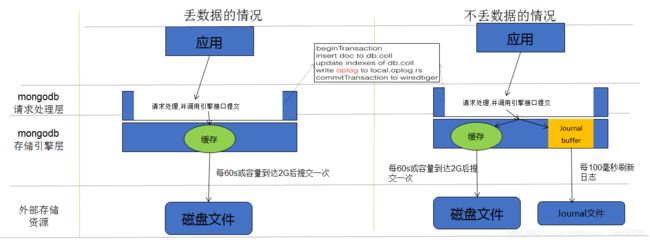
-
mongDB ,写入策略
写策略配置:{ w:, j: , f: ,wtimeout: } w: 数据写入到number个节点才向用客户端确认 {w: 0} 对客户端的写入不需要发送任何确认,适用于性能要求高,但不关注正确性的场景 {w: 1} 默认的writeConcern,数据写入到Primary就向客户端发送确认 {w: “majority”} 数据写入到副本集大多数成员后向客户端发送确认,适用于对数据安全性要求比较高的场景,该选项会降低写入性能 j: 写入操作的journal持久化后才向客户端确认 默认为{j: false},如果要求写入持久化了才向客户端确认,则指定该选项为true f: 写入操作等待服务器将数据刷新到磁盘,才向客户端确认 默认为{f: null},如果要求写入了磁盘才向客户端确认,则指定该选项为true wtimeout: 写入超时时间,仅w的值大于1时有效。 当指定{w: }时,数据需要成功写入number个节点才算成功,如果写入过程中有节点故障,可能导致这个条件一直不能满足,从而一直不能向客户端发送确认结果,针对这种情况,客户端可设置wtimeout选项来指定超时时间,当写入过程持续超过该时间仍未结束,则认为写入失败。 java代码中写策略配置相关的类是 com.mongodb.WriteConcern WriteConcern提供了以下的默认策略 UNACKNOWLEDGED:不等待服务器返回或确认,仅可以抛出网络异常; ACKNOWLEDGED:默认配置,等待服务器返回结果; JOURNALED:等待服务器完成journal持久化之后返回; W1 :等待集群中一台服务器返回结果; W2 :等待集群中两台服务器返回结果; W3 :等待集群中三台服务器返回结果; MAJORITY:等待集群中多数服务器返回结果
索引
-
索引的创建语法
MongoDB使用 ensureIndex() 方法来创建索引db.collection.createIndex(keys, options)options为索引的属性,详情如下

索引的类型#单键索引 在某一个特定的属性上建立索引,例如:db.users. createIndex({age:-1}); mongoDB在ID上建立了唯一的单键索引,所以经常会使用id来进行查询; 在索引字段上进行精确匹配、排序以及范围查找都会使用此索引; #复合索引 在多个特定的属性上建立索引,例如:db.users. createIndex({username:1,age:-1,country:1}); 复合索引键的排序顺序,可以确定该索引是否可以支持排序操作; 在索引字段上进行精确匹配、排序以及范围查找都会使用此索引,但与索引的顺序有关; 为了性能考虑,应删除存在与第一个键相同的单键索引 #多键索引 在数组的属性上建立索引,例如:db.users. createIndex({favorites.city:1});针对这个数组的任意值的查询都会定位到这个文 档,既多个索引入口或者键值引用同一个文档 #哈希索引 不同于传统的B-树索引,哈希索引使用hash函数来创建索引。 例如:db.users. createIndex({username : 'hashed'}); 在索引字段上进行精确匹配,但不支持范围查询,不支持多键hash; Hash索引上的入口是均匀分布的,在分片集合中非常有用; -
索引创建与删除实例
单键唯一索引:db.users. createIndex({username :1},{unique:true}); 单键唯一稀疏索引:db.users. createIndex({username :1},{unique:true,sparse:true}); 复合唯一稀疏索引:db.users. createIndex({username:1,age:-1},{unique:true,sparse:true}); 创建哈希索引并后台运行:db.users. createIndex({username :'hashed'},{background:true}); 根据索引名字删除某一个指定索引:db.users.dropIndex("username_1"); 删除某集合上所有索引:db.users.dropIndexs(); 重建某集合上所有索引:db.users.reIndex(); 查询集合上所有索引:db.users.getIndexes(); -
查询优化
#开启慢查询 - n的取值可选0,1,2 #0是默认值表示不记录; #1表示记录慢速操作,如果值为1,m必须赋值单位为ms,用于定义慢速查询时间的阈值; #2表示记录所有的读写操作; db.setProfilingLevel(n,{m})#查询监控结果 #监控结果保存在一个特殊的盖子集合system.profile里. #这个集合分配了128kb的空间,要确保监控分析数据不会消耗太多的系统性资源. #盖子集合维护了自然的插入顺序,可以使用$natural操作符进行排序. #盖子集合 Tips: #1、大小或者数量固定; #2、不能做update和delete操作; #3、容量满了以后,按照时间顺序,新文档会覆盖旧文档 db.system.profile.find().sort({'$natural':-1}).limit(5)#使用explain分析慢查询语句 #explain的入参可选值为: #"queryPlanner" 是默认值,表示仅仅展示执行计划信息; #"executionStats" 表示展示执行计划信息同时展示被选中的执行计划的执行情况信息; #"allPlansExecution" 表示展示执行计划信息,并展示被选中的执行计划的执行情况信息,还展示备选的执行计划的执行情况信息; db.orders.find({'price':{'$lt':2000}}).explain('executionStats')#explain执行计划各个字段代表的含义 queryPlanner(执行计划描述) winningPlan(被选中的执行计划) stage(可选项:COLLSCAN 没有走索引;IXSCAN使用了索引) rejectedPlans(候选的执行计划) executionStats(执行情况描述) nReturned (返回的文档个数) executionTimeMillis(执行时间ms) totalKeysExamined (检查的索引键值个数) totalDocsExamined (检查的文档个数) #优化目标 根据需求建立索引 每个查询都要使用索引以提高查询效率, winningPlan.stage 必须为IXSCAN 追求totalDocsExamined = nReturned
集群部署
-
可复制集
可复制集是跨多个MongDB服务器(节点)分布和维护数据的方法。mongoDB可以把数据从一个节点复制到其他节点并在修改时进行同步,集群中的节点配置为自动同步数据;旧方法叫做主从复制,mongoDB 3.0以后推荐使用可复制集;
为什么要用可复制集?它有什么重要性?
1、避免数据丢失,保障数据安全,提高系统安全性;
(最少3节点,最大50节点)
2、自动化灾备机制,主节点宕机后通过选举产生新主机;提高系统健壮性;
(7个选举节点上限)
3、读写分离,负载均衡,提高系统性能;
4、生产环境推荐的部署模式;可复制集架构原理
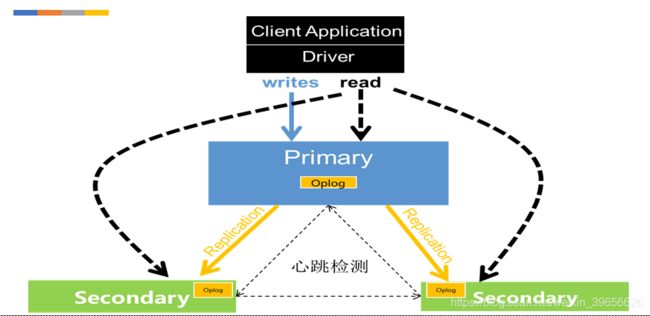
oplog(操作日志):保存操作记录、时间戳 数据同步:从节点与主节点保持长轮询;1.从节点查询本机oplog最新时间戳;2.查询主节点oplog晚于此时间戳的所有文档;3. 加载这些文档,并根据log执行写操作; 阻塞复制:与writeconcern相关,不需要同步到从节点的策略 (acknowledged Unacknowledged 、w1)数据同步都是异步的 其他的策略情况都是同步; 心跳机制:成员之间会每2s 进行一次心跳检测(ping操作),发现故障后进行选举和故障转移; 选举制度:主节点故障后,其余节点根据优先级和bully算法选举出新的主节点,在选出主节点之前,集群服务是只读的;可复制集的搭建
#1.安装好3个以上的MongoDB节点 #2.更新所有节点的配置文档 mongodb.conf,增加以下配置 replication: replSetName: configRS #集群名称 oplogSizeMB: 50 #oplog集合大小 #3、在primary节点上运行可复制集的初始化命令,初始化可复制集. use amdin #进入admin库 rs.initiate({ _id: "configRS", version: 1, members: [{ _id: 0, host : "192.168.1.142:27017" }]}); rs.add("192.168.1.142:27018"); #有几个节点就执行几次方法 rs.add("192.168.1.142:27019"); #有几个节点就执行几次方法 #4、查看可复制集状态 db.isMaster() 或 rs.status() #5、在服务器上通过客户端 在副节点查询数据时都需要先运行 rs.slaveOk() -
分片集群
为什么要用分片集群?数据海量增长,需要更大的读写吞吐量 → 存储分布式
单台服务器内存、cpu等资源是有瓶颈的 → 负载分布式
Tips:分片集群是个双刃剑,在提高系统可扩展性和性能的同时,增大了系统的复杂性,所以在实施之前请确定是必须的。MongoDB是怎么分片的?
mongoDB分片集群推荐的模式是:分片集合,它是一种基于分片键的逻辑对文档进行分组,分片键的选择对分片非常重要,分片键一旦确定,mongoDB对数据的分片对应用是透明的
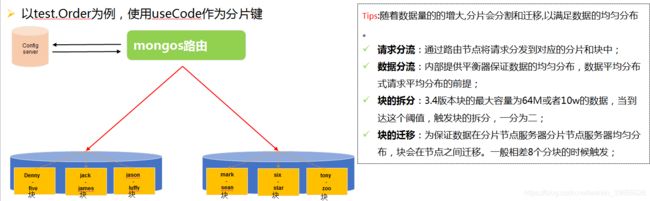
分片的架构与组件
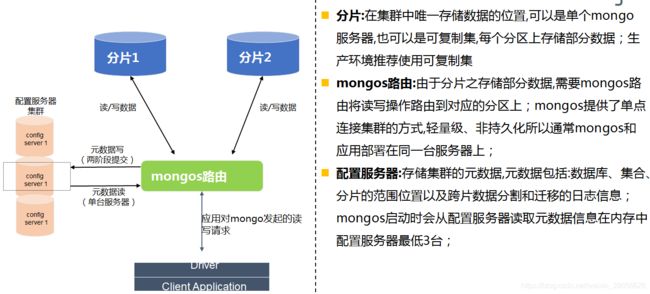
分片注意点与建议

分片集群的搭建(实例)
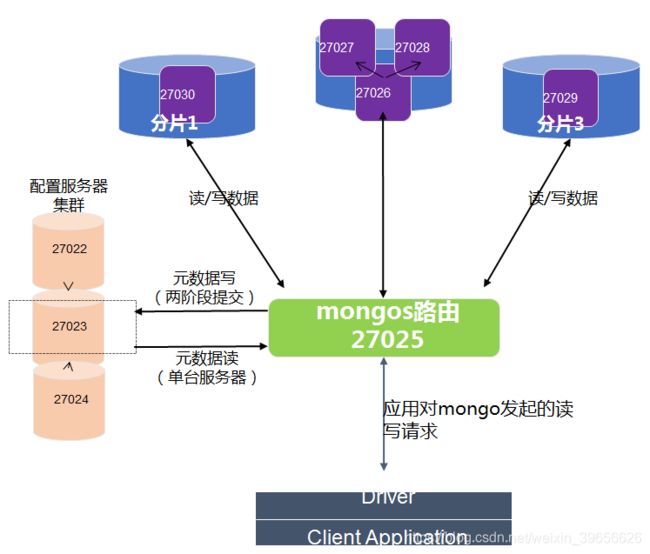
#1、配置服务器配置文件 storage: dbPath: "/usr/local/mongodb/mongodb-27022/data" systemLog: destination: file path: "/usr/local/mongodb/mongodb-27022/logs/mongodb.log" net: port: 27022 http: RESTInterfaceEnabled: true processManagement: fork: false replication: replSetName: configRS oplogSizeMB: 50 sharding: clusterRole: configsvr #2、为配置服务器配置可复制集 rs.initiate({ _id: "configRS", version: 1, members: [{ _id: 0, host : "192.168.227.131:27022"}]}); rs.add("192.168.227.131:27023"); rs.add("192.168.227.131:27024"); #3、存储服务器配置 storage: dbPath: "/usr/local/mongodb/mongodb-27026/data" systemLog: destination: file path: "/usr/local/mongodb/mongodb-27026/logs/mongodb.log" net: port: 27026 http: RESTInterfaceEnabled: true processManagement: fork: false replication: replSetName: dataRS oplogSizeMB: 50 sharding: clusterRole: shardsvr #4、为存储服务器27026,27027,27028三台设置成可复制集 rs.initiate({ _id: "dataRS", version: 1, members: [{ _id: 0, host : "192.168.227.131:27026"}]}); rs.add("192.168.227.131:27027"); rs.add("192.168.227.131:27028"); #5.路由服务器配置(其中 configRS 为配置服务器的可复制集名称) systemLog: destination: file path: "/usr/local/mongodb/mongodb-27025/logs/mongodb.log" net: port: 27025 processManagement: fork: false sharding: configDB: configRS/192.168.227.131:27022,192.168.227.131:27023,192.168.227.131:27024 #6、登录路由服务器,添加分片服务器配置 use admin #添加分片服务器 sh.addShard("192.168.227.131:27029"); sh.addShard("192.168.227.131:27030"); sh.addShard("dataRS/192.168.227.131:27026,192.168.227.131:27027,192.168.227.131:27028"); #为test库设置为具有可分片功能 sh.enableSharding("test") #为test库的orders表 设置为以useCode自动进行分片 sh.shardCollection("test.orders",{"useCode":"hashed"});注意:路由服务器的启动命令为 nohup ./mongos -f mongodb.conf &
mongoDB的使用场景与总结
-
使用场景
并没有某个业务场景必须要使用 MongoDB才能解决,但使用 MongoDB 通常能让你以更低的成本解决问题
(包括学习、开 发、运维等成本)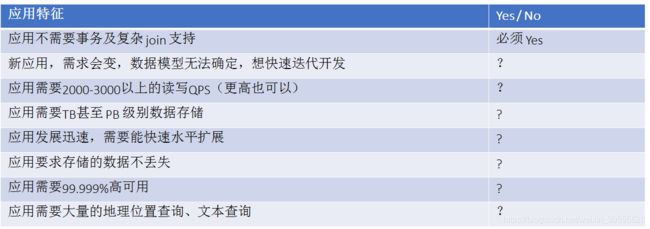
MongoDB 的应用已经渗透到各个领域,比如游戏、物流、电商、内容管理、社交、物联网、视频直播等,
1、游戏场景,使用 MongoDB 存储游戏用户信息,用户的装备、积分等直接以内嵌文档的形式存储,方便查询、更新 2、物流场景,使用 MongoDB 存储订单信息,订单状态在运送过程中会不断更新,以 MongoDB 内嵌数组的形式来存储,一次查询就 能将订单所有的变更读取出来。 3、社交场景,使用 MongoDB 存储存储用户信息,以及用户发表的朋友圈信息,通过地理位置索引实现附近的人、地点等功能 4、物联网场景,使用 MongoDB 存储所有接入的智能设备信息,以及设备汇报的日志信息,并对这些信息进行多维度的分析 5、视频直播,使用 MongoDB 存储用户信息、礼物信息等什么场景不能用MongoDB?
1、高度事务性系统:例如银行、财务等系统。MongoDB对事物的支持较弱; 2、传统的商业智能应用:特定问题的数据分析,多数据实体关联,涉及到复杂的、高度优化的查询方式; 3、使用sql方便的时候;数据结构相对固定,使用sql进行查询统计更加便利的时候; -
索引的使用建议
1、索引很有用,但是它也是有成本的——它占内存,让写入变慢; 2、mongoDB通常在一次查询里使用一个索引,所以多个字段的查询或者排序需要复合索引才能更加高效; 3、复合索引的顺序非常重要,例如此脚本所示: 4、在生成环境构建索引往往开销很大,时间也不可以接受,在数据量庞大之前尽量进行查询优化和构建索引; 5、避免昂贵的查询,使用查询分析器记录那些开销很大的查询便于问题排查; 6、通过减少扫描文档数量来优化查询,使用explain对开销大的查询进行分析并优化; 7、索引是用来查询小范围数据的,不适合使用索引的情况: 每次查询都需要返回大部分数据的文档,避免使用索引 写比读多 -
总体总结
1、尽量选取稳定新版本64位的mongodb; 2、数据模式设计;提倡单文档设计,将关联关系作为内嵌文档或者内嵌数组;当关联数据量较大时,考虑通过表关联实现,dbref或 者自定义实现关联; 3、避免使用skip跳过大量数据;(1)通过查询条件尽量缩小数据范围;(2)利用上一次的结果作为条件来查询下一页的结果; 4、避免单独使用不适用索引的查询符($ne、$nin、$where等) 5、根据业务场景,选择合适的写入策略,在数据安全和性能之间找到平衡点; 6、索引建议很重要; 7、生产环境中建议打开profile,便于优化系统性能; 8、生产环境中建议打开auth模式,保障系统安全; 9、不要将mongoDB和其他服务部署在同一台机器上(mongodb占用的最大内存是可以配置的); 10、单机一定要开启journal日志,数据量不太大的业务场景中,推荐多机器使用副本集,并开启读写分离; 11、分片键的注意事项
springboot的综合使用
-
添加配置
spring.data.mongodb.server-addresses=192.168.227.131:27022 spring.data.mongodb.database=test spring.data.mongodb.username=JayeTian spring.data.mongodb.password=abc.123 spring.data.mongodb.min-connections-per-host=5 spring.data.mongodb.connections-per-host=100 spring.data.mongodb.threads-allowed-to-block-for-connection-multiplier=5 spring.data.mongodb.max-wait-time=120000 spring.data.mongodb.connect-time-out=10000 logging.level.org.springframework.data.mongodb.core=debug -
添加配置类
package com.example.mongodbspring.config; import com.example.mongodbspring.convert.BigDecimalToDecimal128Converter; import com.example.mongodbspring.convert.Decimal128ToBigDecimalConverter; import com.mongodb.client.MongoClient; import com.mongodb.client.MongoClients; import org.springframework.beans.factory.annotation.Value; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import org.springframework.core.convert.converter.Converter; import org.springframework.data.mongodb.MongoDbFactory; import org.springframework.data.mongodb.core.MongoTemplate; import org.springframework.data.mongodb.core.SimpleMongoClientDbFactory; import org.springframework.data.mongodb.core.convert.*; import org.springframework.data.mongodb.core.mapping.MongoMappingContext; import java.util.ArrayList; import java.util.List; @Configuration public class MongodbConfig { @Value("${spring.data.mongodb.server-addresses}") private String serverAddr; @Value("${spring.data.mongodb.database}") private String dataName; @Value("${spring.data.mongodb.username}") private String userName; @Value("${spring.data.mongodb.password}") private String password; @Value("${spring.data.mongodb.min-connections-per-host}") private int minPoolSize; @Value("${spring.data.mongodb.connections-per-host}") private int maxPoolSize; @Value("${spring.data.mongodb.threads-allowed-to-block-for-connection-multiplier}") private int waitQueueMultiple; @Value("${spring.data.mongodb.max-wait-time}") private int waitQueueTimeOutMs; @Value("${spring.data.mongodb.connect-time-out}") private int connectTimeOutMs; @Bean public MongoClient mongoClient() { String connectionString = "mongodb://" + userName + ":" + password + "@" + serverAddr + "/" + dataName + "?minpoolsize=" + minPoolSize + "&maxpoolsize=" + maxPoolSize + "&waitqueuemultiple=" + waitQueueMultiple + "&waitqueuetimeoutms=" + waitQueueTimeOutMs + "&connecttimeoutms=" + connectTimeOutMs + "&w=1&journal=true&wtimeoutms=5000" //写策略 + "&readPreference=secondaryPreferred"; //readPreference=secondaryPreferred即可实现读写分离,读请求优先到Secondary节点 //从而实现读写分离的功能 return MongoClients.create(connectionString); } @Bean public MongoDbFactory mongoDbFactory() { return new SimpleMongoClientDbFactory(mongoClient(), dataName); } //添加自定义的转换器 @Bean public MongoConverter mongoConverter() { DbRefResolver dbRefResolver = new DefaultDbRefResolver(mongoDbFactory()); List<Converter<?, ?>> converterList = new ArrayList<>(); converterList.add(new BigDecimalToDecimal128Converter()); converterList.add(new Decimal128ToBigDecimalConverter()); MongoCustomConversions conversions = new MongoCustomConversions(converterList); MongoMappingContext mappingContext = new MongoMappingContext(); mappingContext.setSimpleTypeHolder(conversions.getSimpleTypeHolder()); mappingContext.afterPropertiesSet(); MappingMongoConverter converter = new MappingMongoConverter(dbRefResolver, mappingContext); converter.setCustomConversions(conversions); converter.setCodecRegistryProvider(mongoDbFactory()); converter.afterPropertiesSet(); return converter; } @Bean public MongoTemplate mongoTemplate() { return new MongoTemplate(mongoDbFactory(), mongoConverter()); } } -
自定义的转换类
package com.example.mongodbspring.convert; import org.bson.types.Decimal128; import org.springframework.core.convert.converter.Converter; import java.math.BigDecimal; public class BigDecimalToDecimal128Converter implements Converter<BigDecimal, Decimal128> { @Override public Decimal128 convert(BigDecimal source) { return new Decimal128(source); } }package com.example.mongodbspring.convert; import org.bson.types.Decimal128; import org.springframework.core.convert.converter.Converter; import java.math.BigDecimal; public class Decimal128ToBigDecimalConverter implements Converter<Decimal128, BigDecimal> { @Override public BigDecimal convert(Decimal128 source) { return source.bigDecimalValue(); } }