Mysql——Explain详解与索引实践注意事项
-
Explain工具介绍
使用EXPLAIN关键字可以模拟优化器执行SQL语句,分析你的查询语句或是结构的性能瓶颈
在select语句之前增加explain关键字,MySQL会在查询上设置一个标记,执行查询会返回执行计划的信息,而不是执行这条SQL
注意:如果from中包含子查询,仍会执行该子查询,将结果放入临时表中
-
Explain两个变种
-
explain extended :会在 explain 的基础上额外提供一些查询优化的信息。紧随其后通过 show warnings 命令可以得到优化后的查询语句,从而看出优化器优化了什么。额外还有 filtered 列,是一个半分比的值,rows * filtered/100 可以估算 出将要和 explain 中前一个表进行连接的行数(前一个表指 explain 中的id值比当前表id值小的表)。
- explain partitions:相比 explain 多了个 partitions 字段,如果查询是基于分区表的话,会显示查询将访问的分区。
-
Explain中的列
1、id列
2、select_type列
1)simple:简单查询。查询不包含子查询和union
2)primary:复杂查询中最外层的select
3)subquery:包含在select中的子查询(不在from子句中)
4)derived:包含在from子句中的子查询。MySQL会将结果存放在一个临时表中,也称为派生表(derived的英文含义)
5)union:在union中的第二个和随后的select
3、table列
4、type列
NULL:mysql能够在优化阶段分解查询语句,在执行阶段用不着再访问表或索引。例如:在索引列中选取最小值,可 以单独查找索引来完成,不需要在执行时访问表。
5、possible_keys列
6、key列
7、key_len列
这一列显示了mysql在索引里使用的字节数,通过这个值可以算出具体使用了索引中的哪些列。
8、ref列
9、rows列
10、Extra列
这一列展示的是额外信息。常见的重要值如下:
1)Using index:使用覆盖索引;
覆盖索引定义:
mysql执行计划explain结果里的key有使用索引,如果select后面查询的字段都可以从这个索引的树中获取,这种情况一般可以说是用到了覆盖索引,extra里一般都有using index;覆盖索引一般针对的是辅助索引,整个查询结果只通过辅助索引就能拿到结果,不需要通过辅助索引树找到主键,再通过主键去主键索引树里获取其它字段值
2)Using where:使用where语句来处理结构,并且查询的列未被索引覆盖;
3)Using index condition:查询的列不完全被索引覆盖,where条件中是一个前导列的范围;
4)Using temporary:MySQL需要创建一张临时表来处理查询。出现这种情况一般是要进行优化的,首先是想到用索引来优化。
-
索引实践注意事项
1、全值匹配
2、最左前缀匹配
3、不在索引列上做任何操作(计算、函数、(自动or手动)类型转换),会导致索引失效而转向全表扫描
4、存储引擎不能使用索引中范围条件右边的列
5、尽量使用覆盖索引(只访问索引的查询(索引列包含查询列)),减少select*语句
6、mysql在使用不等于(!=或者<>),not in,not exists的时候无法使用索引会导致全表扫描
<小于,>大于、<=、>=这些,mysql内部优化器会根据检索比例、表大小等多个因素整体评估是否使用索引
7、is null,is not null一般情况下也无法使用索引
8、like以通配符开头(’$abc...‘)mysql索引失效会变成全表扫描操作
9、字符串不加单引号导致索引失效
10、少用or或in,用它查询时,mysql不一定使用索引,mysql内部优化器会根据检索比例、表大小等多个因素整体评估是否使用索引,详见范围查询优化
11、范围查询优化
一些情况下没走索引原因:mysql内部优化器会根据检索比例、表大小等多个因素整体评估是否使用索引。
优化方法:可以将大的范围拆分成多个小范围
-
索引使用总结
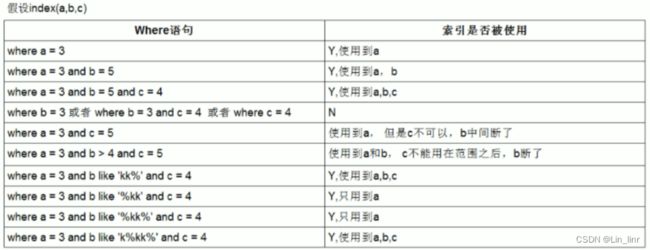
like KK%相当于=常量,%KK和%KK% 相当于范围