基于libtorch的Alexnet深度学习网络实现——Cifar-10数据集分类
“上篇文章我们讲了Alexnet神经网络的结构与原理,我们知道该网络主要由5个卷积层、3个池化层、3个Affine层和1个Softmax层构成。本文我们将基于libtorch来实现该网络,并对Cifar-10数据进行训练、分类。”
由于原Alexnet网络的输入是3通道227*227图像,而Cifar-10数据集是3通道的32*32图像,如果直接输入3*32*32的图像到Alexnet网络,边缘需要填充大量0值才凑成227*227图像,这既麻烦又增加计算量。同时Cifar-10数据集只有10个种类,输出层的尺寸也需要修改。因此我们对Alexnet网络的输入层尺寸、中间层尺寸和输出层尺寸都稍作修改,以便可以直接输入3*32*32图像而不需要边缘填充大量0值,并且可以输出对应10个种类的10个概率值。修改尺寸之后的网络结构如下图所示:
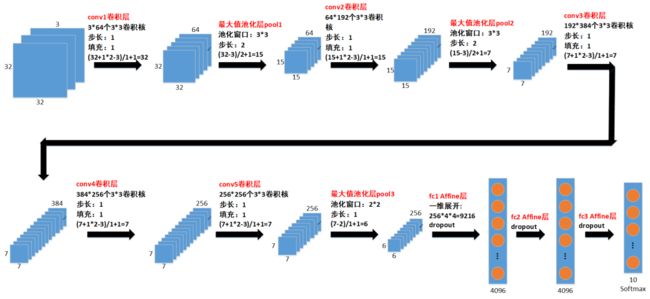
01
—
训练策略
前文我们使用Lenet-5网络来训练Cifar-10数据集时,每次往神经网络输入一个样本,Cifar-10数据集有50000个样本,那么一个epoch总共有50000次循环,对应的需要更新50000次参数,这个过程非常耗时,且收敛速度也慢。
| PS:这里说的样本,是指输入的一张图像包含的数据量,比如输入单通道32*32图像,那么一张单通道的32*32图像就是一个样本,又比如输入三通道32*32图像,那么一张三通道的32*32图像(3*32*32)就是一个样本。 |
为解决以上训练问题,人们想出了批量(batch)训练的方法,也即每次从训练数据集中取n(n > 1,n通常称为batch size)个样本,然后n个样本分别输入神经网络执行前向传播,得到对应的n个损失函数值Yi(0 ≤ i < n),再计算这n个损失函数值的均值Y作为本轮迭代的损失函数值,再使用Y进行误反向传播法,计算梯度进行网络参数更新。批量训练的示意图如下图所示:

批量训练不仅可以加快收敛速度,还能使训练过程更加稳定地朝减小损失函数值的方向进行。此外,这样训练更有利于GPU并行执行,比如开启GPU多线程运算,每个线程计算一个样本的前向传播,多个线程并行执行,这样可明显加快训练速度。
| PS:batch size要取合适的值,不能太小也不能太大,通常取16~128之间就好。 |
由上述可知,训练过程分为多个epoch,每个epoch又分为多个batch。如果每个epoch都按照同样的顺序取batch样本,这是训练的大忌,会导致灾难性的训练结果。因此我们需要在每个epoch开始之前打乱全部样本的顺序,如下图所示:

02
—
网络结构体定义
按照本文开头的网络结构图,我们使用libtorch来定义该网络,并实现前向传播函数:
struct AlexNet : torch::nn::Module
{
AlexNet(int arg_padding = 0)
//conv1卷积层,3*64个3*3卷积核,步长1,填充1
: conv1(register_module("conv1", torch::nn::Conv2d(torch::nn::Conv2dOptions(3, 64, { 3,3 }).padding(arg_padding).stride({ 1,1 }))))
//conv2卷积层,64*192个3*3卷积核,步长1,填充1
, conv2(register_module("conv2", torch::nn::Conv2d(torch::nn::Conv2dOptions(64, 192, { 3,3 }).padding(1).stride({ 1,1 }))))
//conv3卷积层,192*384个3*3卷积核,步长1,填充1
, conv3(register_module("conv3", torch::nn::Conv2d(torch::nn::Conv2dOptions(192, 384, { 3,3 }).padding(1).stride({ 1,1 }))))
//conv4卷积层,384*256个3*3卷积核,步长1,填充1
, conv4(register_module("conv4", torch::nn::Conv2d(torch::nn::Conv2dOptions(384, 256, { 3,3 }).padding(1).stride({ 1,1 }))))
//conv5卷积层,256*256个3*3卷积核,步长1,填充1
, conv5(register_module("conv5", torch::nn::Conv2d(torch::nn::Conv2dOptions(256, 256, { 3,3 }).padding(1).stride({ 1,1 })))) //256*4*4
//fc1 Affine层,256*6*6-->4096,dropout 0.5
, fc1(register_module("fc1", torch::nn::Linear(256*6*6, 4096)))
//fc2 Affine层,4096-->4096,dropout 0.5
, fc2(register_module("fc2", torch::nn::Linear(4096, 4096)))
//fc3 Affine层,4096-->10,dropout 0.5
, fc3(register_module("fc3", torch::nn::Linear(4096, 10)))
{
}
~AlexNet()
{
}
//前向传播函数
torch::Tensor forward(torch::Tensor input)
{
namespace F = torch::nn::functional;
//conv1-->relu-->pool1
auto x = F::max_pool2d(F::relu(conv1(input)), F::MaxPool2dFuncOptions(3).stride({ 2, 2 })); //(32+1*2-3)/1+1=32 --> (32-3)/2+1=15
//conv2-->relu-->pool2
x = F::max_pool2d(F::relu(conv2(x)), F::MaxPool2dFuncOptions(3).stride({ 2, 2 })); //(15+1*2-3)/1+1=15 --> (15-3)/2+1=7
//conv3-->relu
x = F::relu(conv3(x)); //(7+1*2-3)/1+1=7
//conv4-->relu
x = F::relu(conv4(x)); //(7+1*2-3)/1+1=7
//conv5-->relu-->pool3
x = F::max_pool2d(F::relu(conv5(x)), F::MaxPool2dFuncOptions(2).stride({ 1, 1 })); //(7+1*2-3)/1+1=7 --> (7-2)/1+1=6
//一维展开
x = x.view({ x.size(0), -1 });
//dropout 0.5
x = F::dropout(x, F::DropoutFuncOptions().p(0.5));
//fc1-->relu
x = F::relu(fc1(x));
//dropout 0.5
x = F::dropout(x, F::DropoutFuncOptions().p(0.5));
//fc2-->relu
x = F::relu(fc2(x));
//dropout 0.5
x = F::dropout(x, F::DropoutFuncOptions().p(0.5));
//fc3-->relu
x = fc3(x); //注意这里不需要计算softmax,因为后续的交叉熵误差函数里面有计算了
return x;
}
torch::nn::Conv2d conv1;
torch::nn::Conv2d conv2;
torch::nn::Conv2d conv3;
torch::nn::Conv2d conv4;
torch::nn::Conv2d conv5;
torch::nn::Linear fc1;
torch::nn::Linear fc2;
torch::nn::Linear fc3;
};
03
—
训练、测试数据集准备
Cifar-10数据集总共有6个文件,其中5个文件用于训练,一个文件用于测试验证。我们在前文已对Cifar-10数据集有过详细介绍:
基于libtorch的LeNet-5卷积神经网络实现(2)--Cifar-10数据分类
由于5个用于训练的文件总共包含了5*10000张三通道图像,如果要全部读出来训练,所占用的内存非常大,可能会超出限制导致程序崩溃,所以我们想办法每次只读取batch size个图像样本用于训练,相当于每次只加载batch size张三通道图像到内存进行训练,这比起全部加载来说,占用的内存资源大大减少。
1. 首先,我们将5个用于训练的文件中包含的所有三通道图像都解析出来,并按照文件1-->文件-->文件-->文件-->文件5的顺序把解析出来的图像保存为tif文件,依次命名1.tif~49999.tif。

对应1.tif~49999.tif这50000张三通道图像,有50000个0~9的标签,我们也将这50000个标签按照顺序保存到100行500列、名为label.tif的标签图像中,方便我们随机取batch的时候也可以取到对应的标签。秉着图像对应标签的原则,训练图像的文件名(序号)与label.tif的坐标点有如下对应关系,其中index为训练图像的序号,col为label.tif的列数,也即500。
y = index / col
x = index % col
比如对于5000.tif这张图像,它对应label.tif的坐标点为:
y = 5001 / 500 = 10
x = 5001 % 500 = 1
那么label.tif中点(1, 10)的像素值就是5000.tif的标签。
从Cifar-10文件中解析图像与标签的代码实现如下:
#define CIFAT_10_OENFILE_DATANUM 10000
#define CIFAT_10_FILENUM 5
#define CIFAT_10_TOTAL_DATANUM (CIFAT_10_OENFILE_DATANUM*CIFAT_10_FILENUM)
//bin_path为cifar-10文件的路径,注意文件名中的序号要替换成%d
//比如:"D:/cifar-10/data_batch_%d.bin"
void read_cifar_to_file(char *bin_path)
{
const int img_num = CIFAT_10_OENFILE_DATANUM;
const int img_size = 3073; //第一字节是标签
const int img_size_1 = 1024;
const int data_size = img_num * img_size;
const int row = 32;
const int col = 32;
uchar *labels = (uchar *)malloc(CIFAT_10_TOTAL_DATANUM);
uchar *cifar_data = (uchar *)malloc(data_size);
for (int i = 0; i < CIFAT_10_FILENUM; i++) //总共5个文件
{
char str[200] = {0};
sprintf(str, bin_path, i+1);
FILE *fp = fopen(str, "rb");
fread(cifar_data, 1, data_size, fp); //读取一个文件的全部数据
//每个文件总共有10000张三通道图像
for (int j = 0; j < CIFAT_10_OENFILE_DATANUM; j++)
{
long int offset = j * img_size;
long int offset0 = offset + 1; //红
long int offset1 = offset0 + img_size_1; //绿
long int offset2 = offset1 + img_size_1; //蓝
long int idx = i * CIFAT_10_OENFILE_DATANUM + j;
labels[idx] = cifar_data[offset]; //将标签按照0~49999的索引写到申请的数组中
Mat img(row, col, CV_8UC3);
for (int y = 0; y < row; y++)
{
for (int x = 0; x < col; x++)
{
int index = y * col + x;
//解析为BGR图像
img.at(y, x) = Vec3b(cifar_data[offset2 + index], cifar_data[offset1 + index], cifar_data[offset0 + index]); //BGR
}
}
//按照0~49999的序号写图像到tif文件
char str1[200] = {0};
sprintf(str1, "D:/Program Files (x86)/Microsoft Visual Studio/2017/Community/prj/libtorch_test1_gpu2/libtorch_test/cifar-10/img/%d.tif", idx);
imwrite(str1, img);
}
fclose(fp);
}
Mat label_mat(100, 500, CV_8UC1, labels); //将标签保存到100行500列的矩阵中,并保存矩阵到tif文件
imwrite("D:/Program Files (x86)/Microsoft Visual Studio/2017/Community/prj/libtorch_test1_gpu2/libtorch_test/cifar-10/label/label.tif", label_mat);
free(labels);
free(cifar_data);
}
运行上述程序之后,我们将得到0.tif~49999.tif这50000张三通道的图像,以及一张保存标签的label.tif图像。
04
—
batch样本的获取
经过上一步,我们有0.tif~49999.tif这50000张训练图像,以及一张保存标签的label.tif图像。接下来我们按照将0~49999打乱之后的顺序依次获取batch样本。
每个epoch开始之前,首先要打乱读取顺序:
vector train_image_shuffle_set; //保存读取样本顺序的数组
train_image_shuffle_set.clear(); //清除数组
for (size_t i = 0; i < CIFAT_10_TOTAL_DATANUM; i++)
{
train_image_shuffle_set.push_back(i); //将数组初始化为0~49999的值
}
std::random_device rd;
std::mt19937_64 g(rd());
//使用随机数打乱0~49999这些值在数组中的保存顺序
std::shuffle(train_image_shuffle_set.begin(), train_image_shuffle_set.end(), g); //打乱顺序
接着,我们按照打乱之后的顺序依次获取batch 0、batch 1、batch 2......假设batch size为32,获取batch的过程如下图所示:

然后根据batch中样本的序号index(该样本的文件名为index.tif)来从label.tif中获取对应的标签:
y = index / 500
x = index % 500
标签=label(x, y)
代码如下:
//bin_path为tif文件的路径,注意文件名中的序号要替换成%d
//比如:"cifar-10/img/%d.tif"
//这里的shuffle_idx为数组train_image_shuffle_set中某一元素的地址:
//假如batch_size=32,传入train_image_shuffle_set,则取0~31地址中保存的顺序
//如果传入&train_image_shuffle_set[32],则取32~63地址中保存的顺序,以此类推
void read_cifar_batch(char *bin_path, Mat labels, size_t *shuffle_idx, int batch_size, vector &img_list, vector &label_list)
{
img_list.clear();
label_list.clear();
for (int i = 0; i < batch_size; i++)
{
char str[200] = {0};
sprintf(str, bin_path, shuffle_idx[i]);
Mat img = imread(str, CV_LOAD_IMAGE_COLOR); //以BGR方式读取tif文件
//将BGR转换RGB
cvtColor(img, img, COLOR_BGR2RGB);
img.convertTo(img, CV_32F, 1.0/255.0);
img = (img - 0.5) / 0.5; //将图像数据值转换为-1.0~1.0之间
img_list.push_back(img.clone()); //将图像保存到数组中
//计算对应标签label.tif文件中的坐标
int y = shuffle_idx[i] / labels.cols;
int x = shuffle_idx[i] % labels.cols;
label_list.push_back((long long)labels.ptr(y)[x]); //将标签保存到数组中,注意标签需要强制转换为long long型数据
}
}
05
—
训练过程
经过上面的步骤,我们已经获取到batch size张batch样本,以及对应的batch size个0~9的标签,那么首先需要将batch样本和标签转换为libtorch的Tensor张量,接着才能开始训练:
//读取batch样本和标签,分别保存在img_list、label_list中
read_cifar_batch("cifar-10/img/%d.tif", label_mat, &train_image_shuffle_set[k*batch_size], batch_size, img_list, label_list);
//定义batch_size个样本张量,也可以理解成batch_size*3*32*32的数组
auto inputs = torch::ones({ batch_size, 3, 32, 32 });
//将读取的每个batch样本依次幅值给inputs张量的第0维
for (int b = 0; b < batch_size; b++)
{
inputs[b] = torch::from_blob(img_list[b].data, { img_list[b].channels(), img_list[b].rows, img_list[b].cols }, torch::kFloat).clone();
}
//将数值类型的vector数组直接转换Tensor张量
torch::Tensor labels = torch::tensor(label_list);
完整的训练代码如下:
void tran_alexnet_cifar_10_batch(void)
{
vector train_img_total;
vector train_label_total;
AlexNet net1(1); //定义Alexnet网络结构体
net1.to(device_type); //将网络类型切换到GPU,以加速运行
//定义交叉熵函数
auto criterion = torch::nn::CrossEntropyLoss();
//训练300个spoch
int kNumberOfEpochs = 300;
//学习率
double alpha = 0.001;
int batch_size = 32; //batch size
vector img_list;
vector label_list;
//读取存储标签的tif文件
Mat label_mat = imread("cifar-10/label/label.tif", CV_LOAD_IMAGE_GRAYSCALE);
//定义梯度下降优化器,momentum模式
auto optimizer = torch::optim::SGD(net1.parameters(), torch::optim::SGDOptions(alpha).momentum(0.9));
for (int epoch = 0; epoch < kNumberOfEpochs; epoch++)
{
printf("epoch:%d\n", epoch + 1);
//batch训练之前打乱读取数据的顺序
train_image_shuffle_set.clear();
for (size_t i = 0; i < CIFAT_10_TOTAL_DATANUM; i++)
{
train_image_shuffle_set.push_back(i);
}
std::random_device rd;
std::mt19937_64 g(rd());
std::shuffle(train_image_shuffle_set.begin(), train_image_shuffle_set.end(), g); //打乱顺序
auto running_loss = 0.;
//总共有CIFAT_10_TOTAL_DATANUM/batch_size个batch
for (int k = 0; k < CIFAT_10_TOTAL_DATANUM/batch_size; k++)
{
//按照打乱之后的顺序读取batch样本、标签
read_cifar_batch("cifar-10/img/%d.tif", label_mat, &train_image_shuffle_set[k*batch_size], batch_size, img_list, label_list);
auto inputs = torch::ones({ batch_size, 3, 32, 32 });
for (int b = 0; b < batch_size; b++)
{
inputs[b] = torch::from_blob(img_list[b].data, { img_list[b].channels(), img_list[b].rows, img_list[b].cols }, torch::kFloat).clone();
}
torch::Tensor labels = torch::tensor(label_list);
//将样本、标签张量由CPU类型切换到GPU类型,对应于GPU类型的网络
inputs = inputs.to(device_type);
labels = labels.to(device_type);
auto outputs = net1.forward(inputs); //前向传播
auto loss = criterion(outputs, labels); //计算交叉熵误差
optimizer.zero_grad(); //清零梯度
loss.backward(); //误反向传播
optimizer.step(); //更新参数
running_loss += loss.item().toFloat();
if ((k + 1) % 50 == 0)
{
printf("loss: %f\n", running_loss/50);
running_loss = 0.;
}
}
}
remove("mnist_cifar_10_alexnet.pt");
printf("Finish training!\n");
torch::serialize::OutputArchive archive;
net1.save(archive);
archive.save_to("mnist_cifar_10_alexnet.pt"); //保存训练好的模型
printf("Save the training result to mnist_cifar_10_alexnet.pt.\n");
}
训练过程中,损失函数值具有一定的波动现象,但整体来说还是下降趋势:

06
—
模型验证
经过上一步的训练,我们得到了保存训练模型的文件mnist_cifar_10_alexnet.pt,在验证模型或实际使用模型时,只需要加载该文件即可,不需要再重复训练。我们使用Cifar-10数据集的test_batch.bin文件来验证训练模型,该文件同样包含10000张三通道的图像,我们只需要根据前文讲的文件格式把这些图像与其对应的标签解析出来即可,然后将图像输入网络并执行前向传播、获取预测值,并于实际标签比较是否一致,就可以知道预测是否准确了。
解析test_batch.bin文件的代码如下:
//bin_path就是test_batch.bin文件的完整路径
void read_cifar_bin_rgb(char *bin_path, vector &img_liat, vector &label_list)
{
const int img_num = 10000;
const int img_size = 3073; //第一字节是标签
const int img_size_1 = 1024;
const int data_size = img_num * img_size;
const int row = 32;
const int col = 32;
uchar *cifar_data = (uchar *)malloc(data_size);
if (cifar_data == NULL)
{
cout << "malloc failed" << endl;
return;
}
FILE *fp = fopen(bin_path, "rb");
if (fp == NULL)
{
cout << "fopen file failed" << endl;
free(cifar_data);
return;
}
fread(cifar_data, 1, data_size, fp);
img_liat.clear();
label_list.clear();
for (int i = 0; i < img_num; i++)
{
long int offset = i * img_size;
long int offset0 = offset + 1; //红
long int offset1 = offset0 + img_size_1; //绿
long int offset2 = offset1 + img_size_1; //蓝
uchar label = cifar_data[offset]; //标签
Mat img(row, col, CV_8UC3);
for (int y = 0; y < row; y++)
{
for (int x = 0; x < col; x++)
{
int idx = y * col + x;
img.at(y, x) = Vec3b(cifar_data[offset2 + idx], cifar_data[offset1 + idx], cifar_data[offset0 + idx]); //BGR
}
}
cvtColor(img, img, COLOR_BGR2RGB);
img.convertTo(img, CV_32F, 1.0/255.0); //0.0~1.0
img = (img - 0.5) / 0.5; //-1~1
img_liat.push_back(img.clone()); //float
label_list.push_back(label); //uchar
}
fclose(fp);
free(cifar_data);
}
预测验证的代码如下:
void test_alexnet_cifar_10(void)
{
AlexNet net1(1);
torch::serialize::InputArchive archive;
archive.load_from("mnist_cifar_10_alexnet.pt"); //从文件加载训练模型
net1.load(archive); //将训练模型加载到网络
net1.to(device_type); //将网络类型切换到GPU,以加速运行
vector test_img;
vector test_label;
read_cifar_bin_rgb("D:/Program Files (x86)/Microsoft Visual Studio 14.0/prj/KNN_test/KNN_test/cifar-10-batches-bin/test_batch.bin", test_img, test_label);
int total_test_items = 0, passed_test_items = 0;
double total_time = 0.0;
for (int i = 0; i < test_img.size(); i++)
{
//将样本、标签转换为Tensor张量
torch::Tensor inputs = torch::from_blob(test_img[i].data, { 1, test_img[i].channels(), test_img[i].rows, test_img[i].cols }, torch::kFloat); //1*1*32*32
torch::Tensor labels = torch::tensor({ (long long)test_label[i] });
//将样本、标签张量由CPU类型切换到GPU类型,对应于GPU类型的网络
inputs = inputs.to(device_type);
labels = labels.to(device_type);
// 用训练好的网络处理测试数据,也即前向传播
auto outputs = net1.forward(inputs);
// 得到预测值,0 ~ 9
auto predicted = (torch::max)(outputs, 1);
// 比较预测结果和实际结果,并更新统计结果
if (labels[0].item() == std::get<1>(predicted).item())
passed_test_items++;
total_test_items++;
printf("label: %d.\n", labels[0].item());
printf("predicted label: %d.\n", std::get<1>(predicted).item());
}
printf("total_test_items=%d, passed_test_items=%d, pass rate=%f\n", total_test_items, passed_test_items, passed_test_items*1.0 / total_test_items);
}
运行上述代码,使用训练好的模型对10000张图像进行分类,准确率仅达到了56.59%,这个准确率更简单的Lenet-5网络都可以达到,所以这个搭建的Alexnet有点失败啊~不过没关系,接下来我们尝试调整网络和参数,试试增加一些额外的层,比如batch norm层、LRN层,或者试试数据去均值归一化等措施,再看看准确率有没有提升。加油!fighting!

欢迎扫码关注以下微信公众号,接下来会不定时更新更加精彩的内容噢~
