Python全栈开发-Python爬虫-03 正则表达式详解
正则表达式
一. 什么是正则表达式
正则表达式,又称规则表达式,通常被用来检索、替换那些符合某个模式(规则)的文本。
正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个"规则字符串",这个"规则字符串"用来表达对字符串的一种过滤逻辑。
给定一个正则表达式和另一个字符串,我们可以达到如下的目的:
- 给定的字符串是否符合正则表达式的过滤逻辑(“匹配”);
- 通过正则表达式,从文本字符串中获取我们想要的特定部分(“过滤”)
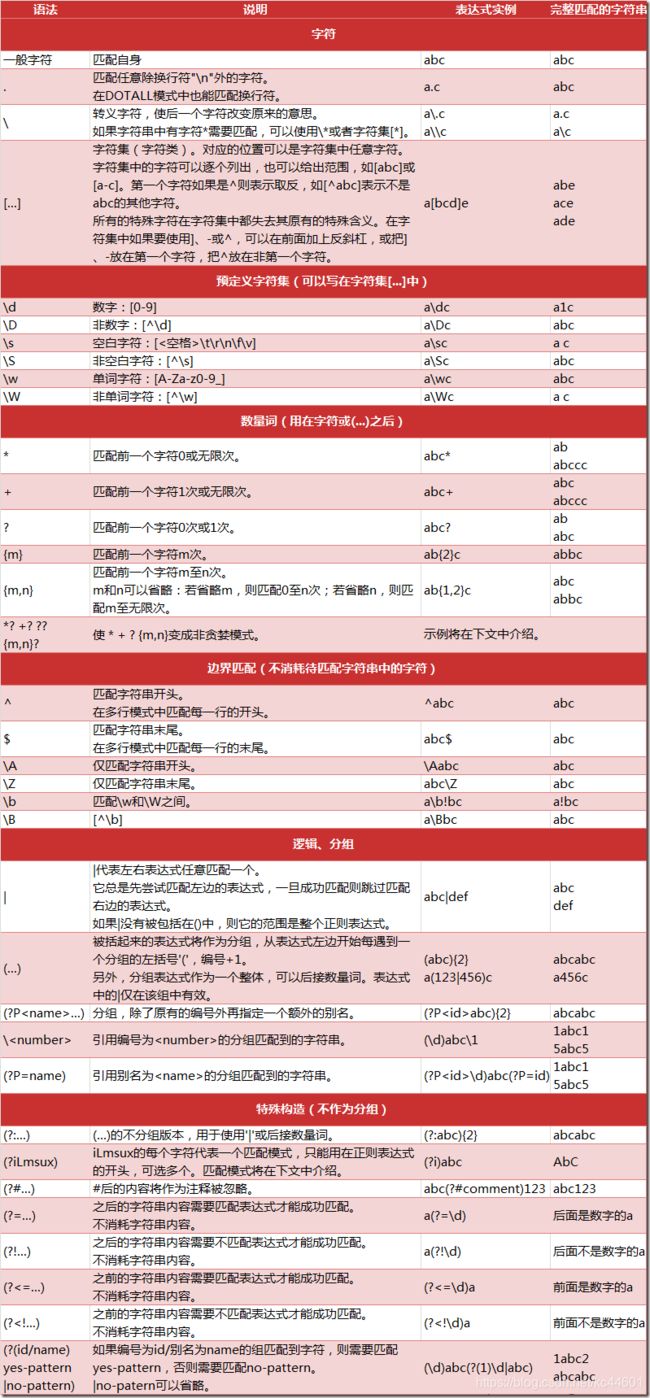
二. 正则表达式的常见语法
三. Python 的 re 模块
在 Python 中,我们可以使用内置的 re 模块来使用正则表达式。
有一点需要特别注意的是,正则表达式使用 对特殊字符进行转义,所以如果我们要使用原始字符串,只需加一个 r 前缀,示例:
r'chuanzhiboke\t\.\tpython'
四. re 模块的一般使用步骤如下:
- 使用
compile()函数将正则表达式的字符串形式编译为一个Pattern对象 - 通过
Pattern对象提供的一系列方法对文本进行匹配查找,获得匹配结果,一个 Match 对象。 - 最后使用
Match对象提供的属性和方法获得信息,根据需要进行其他的操作
五. re.match()方法的使用
-
re.match()尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回None。 -
re.match(pattern, string, flags=0)
pattern : 正则表达式
string : 要匹配的字符
flags : 设置匹配模式
5.1 最常规匹配
当你要匹配某一个内容的时候,你要告诉他前一个字符的特征和后一个字符的特征,给了范围才能精准匹配到
import re
content = 'Hello 123 456789 World_This is a Regex Demo'
# 精准匹配
# 一个\d匹配模式匹配一个字符串
res = re.match('^Hello\s\d\d\d\s\d{6}\s\w{10}.*Demo$', content) # Hello精准匹配 字符串是可以去匹配字符串的
print(res) #返回的是一个匹配对象
print(res.group()) # .group() 获取匹配内容
print(res.span()) # 匹配长度
print(len(content)) # len统计字符串数量
运行结果如下:
<re.Match object; span=(0, 43), match='Hello 123 456789 World_This is a Regex Demo'>
Hello 123 456789 World_This is a Regex Demo
(0, 43)
43
import re
a_str = 'qwe 123 ghj'
res = re.match('^q\w{2}\s\d{3}.*j$',a_str)
print(res.group())
运行结果如下:
qwe 123 ghj
5.2 泛匹配
import re
content = 'Hello 123 4567 World_This is a Regex'
# 开头词 结尾词
# 熟练后可以很精简的写
result = re.match('^H.*?Regex$',content)
print(result.group()) # 获取匹配内容
print(result.span()) # 获取匹配长度
运行结果如下:
Hello 123 4567 World_This is a Regex
(0, 36)
5.3 匹配目标 – 分组匹配
为了匹配字符串中具体的目标,可以使用()进行分组匹配
import re
content = 'qwe Hello 1234567 World_This is a Regex Demo'
# (\w+) +至少匹配一个或者多个,是一种贪婪模式
# 前后写\s是为了给他做限制,匹配范围为你的前后都为空格
# ()表示一个组,为了方便内容提取,这个组使用group()提取
result = re.match('^qwe\s(\w+)\s(\d{7}).*Demo$',content)
# result = re.match('^qwe\s(\w+)\s(\d{3}).*Demo$',content)
print(result.group())
print(result.group(1)) # 提取第一组表达式内匹配到的字符
print(result.group(2)) # 提取第二组表达式内匹配的字符
运行结果如下:
qwe Hello 1234567 World_This is a Regex Demo
Hello
1234567
import re
sssd = 'dasdjskL22222adjlsakjddd66666dassssssa'
# \d只能匹配数字,所以需要.*泛匹配后面内容,匹配到ddd为止
result = re.match('^d.*L(\d+).*ddd(\d+)da.*sa$',sssd)
print(result)
print(result.group())
print(result.group(1))
print(result.group(2))
运行结果如下:
<re.Match object; span=(0, 38), match='dasdjskL22222adjlsakjddd66666dassssssa'>
dasdjskL22222adjlsakjddd66666dassssssa
22222
66666
5.4 贪婪匹配
尽可能多的去匹配
意思是一直匹配,匹配到不能匹配为止
import re
# 匹配尽可能多的字符
content = 'Hello 1234567 World_This is a Regex Demo'
# 出现结果为7是因为:被前面的.*给匹配掉了,只剩下一个数字,这就是贪婪匹配
result = re.match('^He.*(\d+)\s.*Demo$', content) #7
# result = re.match('^He.*(\d{2})\s.*Demo$', content) # 匹配到67
print(result)
print(result.group())
print(result.group(1))
运行结果如下:
<re.Match object; span=(0, 40), match='Hello 1234567 World_This is a Regex Demo'>
Hello 1234567 World_This is a Regex Demo
7
5.5 非贪婪匹配
概念与贪婪相反,尽可能少的去匹配
若要非贪婪就是使用 ?
import re
# 匹配尽可能少的字符
content = 'Hello 1234567 World_This is a Regex Demo'
result = re.match('^He.*?(\d+).*Demo$', content)
# print(result)
print(result.group())
print(result.group(1))
运行结果如下:
Hello 1234567 World_This is a Regex Demo
1234567
注意:贪婪模式与非贪婪模式
- 贪婪模式:在整个表达式匹配成功的前提下,尽可能多的匹配 ( * );
- 非贪婪模式:在整个表达式匹配成功的前提下,尽可能少的匹配 ( ? );
- Python里数量词默认是贪婪的。
- 使用贪婪的数量词的正则表达式:.*
- 匹配结果:test1bbtest2
这里采用的是贪婪模式。在匹配到第一个"
test1bbtest2"
- 使用非贪婪的数量词的正则表达式:.*?
- 匹配结果:test1
正则表达式二采用的是非贪婪模式,在匹配到第一个"
test1"。
5.6 匹配模式

import re
# re.S 作用:匹配包括换行在内的所有字符
content = '''Hello 1234567 World_This
is a Regex Demo
'''
result = re.match('^He.*?(\d+).*Demo$', content,re.S)
print(result.group())
print(result.group(1))
运行结果如下:
Hello 1234567 World_This
is a Regex Demo
1234567
5.7 转义
import re
# 一对一匹配写法在这不适用,原因:
# $和 .是正则里的特殊匹配符号 遇到这种情况要讲特殊符号转义
content = 'price is $5.00'
result = re.match('price is $5.00', content)
print(result)
运行结果如下:
None
import re
# 在特殊符合前加\转义 ,表示它不是正则里的匹配符号,就只是普通文本
content = 'price is $5.00'
result = re.match('price is \$5\.00', content)
print(result)
print(result.group())
运行结果如下:
<re.Match object; span=(0, 14), match='price is $5.00'>
price is $5.00
总结:尽量使用泛匹配、使用括号得到匹配目标、尽量使用非贪婪模式、有换行符就用re.S
六. re.search()方法的使用
re.search() 扫描整个字符串并返回第一个成功的匹配。
- 不用从字符串开头开始匹配,不需要写字符串结尾
- 但同样需要告诉它前一个字符的特征和后一个字符的特征,给了范围才能精准匹配到
import re
content = 'Extra stings Hello 1234567 World_This is a Regex Demo Extra stings'
result = re.match('He.*?(\d+).*?Wor', content) # 因为没从起始位置开始匹配
# result = re.match('Ex.*?(\d+).*?Wor', content) # 从起始位置开始匹配 加$就报错
print(result)
运行结果如下:
None
import re
content = 'Extroa stings Hello 1234567 World_This is a 66666666 RDemogex Demo Extra stings'
result = re.search('He.*?(\d+).*?Wor', content)
print(result)
print(result.group(1))
运行结果如下:
<re.Match object; span=(14, 31), match='Hello 1234567 Wor'>
1234567
总结:为匹配方便,能用search()就不用match()
七. 匹配演练
例一:
import re
html = ''''''
# 文本里面有引号,所以一一对应
# 规律:如果要取目标值 一定要拿到它前后的特征字符
result = re.search('(.*?).*?' ,html,re.S)
# result = re.search('(.*?).*?',html,re.S) #beyond 光辉岁月
# result = re.search('(.*?).*?', html, re.S) # 陈慧琳 记事本
# 可以写的更精简一些 只要保证拿到目标值的前后特征字符就行
# result = re.search('/6\.mp3.*?="(.*?)".*?(.*?)',html,re.S) # 邓丽君 但愿人长久
# print(result)
# print(result.group())
# for i in result:
# print(i)
print(result.group(1))
print(result.group(2))
运行结果如下:
齐秦
往事随风
例二:
html = ''''''
import re
# 只能匹配到当前第一个
result = re.search('(.*?).*?' ,html,re.S)
print(result.group(1))
print(result.group(2))
运行结果如下:
齐秦
往事随风
八. re.findall()
前面的match()以及search()都只能匹配到第一个
搜索字符串,以列表形式返回全部能匹配的子串。
import re
html = ''''''
pe = '(.*?).*?'
# 精简写法
# pe='href="(.*?)".*?singer="(.*?)">(.*?)' # 歌手 歌曲
res = re.findall(pe,html,re.S) # 能拿到满足该正则表达式的所有数据
print(res)
for i in res:
# print(i)
with open('abc.txt','a') as f:
f.write('链接:'+i[0]+'\n')
f.write('歌手:'+i[1]+'\n')
f.write('歌曲:'+i[2]+'\n')
f.close()
运行结果如下:
[('/2.mp3', '任贤齐', '沧海一声笑'), ('/3.mp3', '齐秦', '往事随风'), ('/4.mp3', 'beyond', '光辉岁月'), ('/5.mp3', '陈慧琳', '记事本'), ('/6.mp3', '邓丽君', '但愿人长久')]
九. re.sub()
替换字符串中每一个匹配的子串后返回替换后的字符串。
例一:
import re
content = 'Extra stings Hello 1234567 World_This is a Regex Demo Extra stings'
# 第一个参数 正则表达式
# 要替换的新字符
# 原字符串
content = re.sub('s', '7', content) # 所有s都替换成了7
print(content)
运行结果如下:
Extra 7ting7 Hello 1234567 World_Thi7 i7 a Regex Demo Extra 7ting7
例二:
import re
content = 'Extra stings Hello 1234567 World_This is a Regex Demo Extra stings'
# 第一个参数 正则表达式
# 要替换的新字符
# 原字符串
content = re.sub('\d+', '6666666', content)
print(content)
运行结果如下:
Extra stings Hello 6666666 World_This is a Regex Demo Extra stings
例三:
import re
content = 'Extra stings Hello 1234567 World_This is a Regex Demo Extra stings'
# 要替换的内容包含原字符串本身 追加
# \1表示保留原始字符串 # \1表示保留原始字符串 r表追加 空格后面写要追加的内容
content = re.sub('(\d+)',r'\1 3333', content)
print(content)
运行结果如下:
Extra stings Hello 1234567 3333 World_This is a Regex Demo Extra stings
例四:
import re
html = ''''''
# | 表示或
html = re.sub('|' , '', html)
print(html) # a标签里的链接和歌手名都被替换掉了
results = re.findall('(.*?)' , html, re.S)
# print(results)
for result in results:
print(result.strip()) #.strip()去掉前后的空白字符
运行结果如下:
<div id="songs-list">
<h2 class="title">经典老歌</h2>
<p class="introduction">
经典老歌列表
</p>
<ul id="list" class="list-group">
<li data-view="2">一路上有你</li>
<li data-view="7">
沧海一声笑
</li>
<li data-view="4" class="active">
往事随风
</li>
<li data-view="6">光辉岁月</li>
<li data-view="5">记事本</li>
<li data-view="5">
但愿人长久
</li>
</ul>
</div>
一路上有你
沧海一声笑
往事随风
光辉岁月
记事本
但愿人长久
十. re.compile
将正则字符串编译成正则表达式对象
将一个正则表达式串编译成正则对象,以便于复用该匹配模式 相当于函数的意义,可以多次调用
import re
content = '''Hello 1234567 World_This
is a Regex Demo'''
pattern = re.compile('Hello.*Demo', re.S) # 正则表达式对象
# print(pattern) # 方便复用 如果需要多次用到这个正则表达式 那就可以这样写
result = re.match(pattern, content)
print(result)
运行结果如下:
<re.Match object; span=(0, 40), match='Hello 1234567 World_This\nis a Regex Demo'>
案例:豆瓣新书速递¶
import requests
import re
url = 'https://book.douban.com/latest?icn=index-latestbook-all'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36'
}
# 1.分析网页,发起请求
response = requests.get(url, headers=headers)
if response.status_code == 200:
# 获取响应内容
html = response.text
# print(html)
# print(response.status_code)
# print(response.text)
# 解析内容
z = '(.*?).*?(.*?)' \
'.*?(.*?).*? 运行结果如下:
由于结果太多,这里只展示五个书籍
由于爬取的是新书速递,所以每段时间爬取结果可能会不一样,请以实际为准
空空如也
https://book.douban.com/subject/35444393/
[日]松重丰 / 北京联合出版公司 / 2021-6-1
“这是身为演员的我,才能写出的故事。”《孤独的美食家》主演松重丰首部作品集。由半自传体、连作短篇小说集《愚者谵言》与随笔集《演者戏言》两部分构成。
------------------------------------------------------------
退稿图书馆
https://book.douban.com/subject/35218576/
[法] 大卫·冯金诺斯 / 上海译文出版社 / 2021-6-1
“退稿图书馆”专门收藏无法出版且放弃出版指望的书稿。编辑黛尔菲和小说家弗雷德里克偶然在此发现了一部杰作,作者名叫“亨利•彼克”。谁是“亨利•彼克”?
------------------------------------------------------------
气球人
https://book.douban.com/subject/35451204/
陈浩基 / 花城出版社 / 2021-5-31
主人公“气球人”无意中发现自己身怀异能,只要接触生命体的皮肤,就可令其在指定时间内像气球一样充气膨胀,“意外”死亡。从此,“气球人”成为了一名职业杀手……
------------------------------------------------------------
愤怒的玩偶
https://book.douban.com/subject/35286975/
[阿根廷] 罗伯特·阿尔特 / 四川文艺出版社 / 2021-6
主人公阿斯铁尔被学校开除,他不惜一切代价试图摆脱贫穷,但始终未能成功,越来越陷入悲观。小说反映了 20 世纪初布宜诺斯艾利斯的混乱局面。
------------------------------------------------------------
毁灭者亚巴顿
https://book.douban.com/subject/35430544/
[阿根廷]埃内斯托·萨瓦托 / 四川文艺出版社 / 2021-6
阿根廷经典作家萨瓦托长篇小说,是其“心理小说三部曲”之终章。作品具有典型的拉美文学魅力,又有独创之处。虽则阅读门槛较高,其文学价值、重要性却是毋庸置疑。
------------------------------------------------------------